
【机器学习】逻辑回归(logistics regression)
一、逻辑回归的概念
逻辑回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,经济预测等领域。逻辑回归从本质来说属于二分类问题,是基于Sigmoid函数(又叫“S型函数”)的有监督二类分类模型。
二、Sigmoid函数
Sigmoid函数公式为:

其导数形式为:(注意,导数形式在后期会被用到)
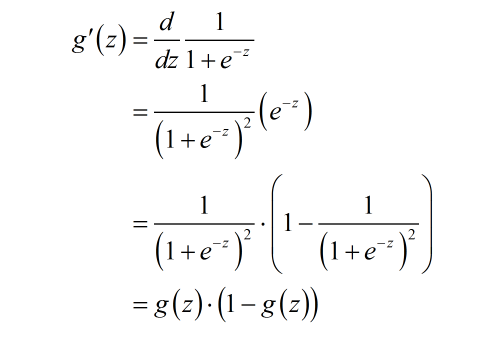
Sigmoid函数其图像如下所示,其取值范围被压缩到0到1之间。

我们知道有监督分类问题需要有带类别标记的训练样本,中的 z 就对应训练集中某个样本的信息。 而样本信息通常用一系列特征的线性组合来表示,即
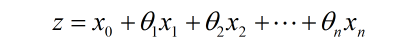
其中 表示 n 个特征,
 是每个特征的权重,代表对应特征的重要程度,
是每个特征的权重,代表对应特征的重要程度, 是偏移,上式通常被写成向量形式:
是偏移,上式通常被写成向量形式: (
 对应的
对应的 等于1)。那么Sigmoid函数就可以相应地写为如下的形式:
等于1)。那么Sigmoid函数就可以相应地写为如下的形式:
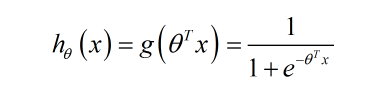
假设我们知道了某个样本对应的特征取值和权重参数,那么只要将其带入上式即可得到一个0到1之间的数,通常认为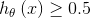 则属于正类别,反之属于负类别,即这个数其实反映了该样本属于正类别的概率。现在的问题是,我们手上有了训练集,即样本的都是已知的,而模型参数是未知的。我们需要通过训练集来确定未知的值。一旦被确定,每当面临新样本时,我们就可以将其对应的
则属于正类别,反之属于负类别,即这个数其实反映了该样本属于正类别的概率。现在的问题是,我们手上有了训练集,即样本的都是已知的,而模型参数是未知的。我们需要通过训练集来确定未知的值。一旦被确定,每当面临新样本时,我们就可以将其对应的 扔到
扔到 中,根据结果是否大于0.5,轻松加愉快地得出新样本的类别了。
中,根据结果是否大于0.5,轻松加愉快地得出新样本的类别了。
三、逻辑回归为什么要用sigmoid函数而不是用其他呢?
首先需要了解几个知识点:A.指数族分布 B.广义线性模型
A.指数族分布
指数族分布下面的公式,即:

其中,η为自然参数,T(y)为充分统计量,通常T(y)=y,α(η)为正则化项。
B.广义线性模型
满足下面三个假设的模型成为广义线性模型:
①![]() 满足一个以η为参数的指数族分布
满足一个以η为参数的指数族分布
②给定x,我们目标是预测y的期望值,即![]()
③![]()
因为逻辑回归假设数据服从伯努利分布,我们用一个简单例子来介绍伯努利分布:抛硬币,一枚硬币抛中正面的概率为p,那么反面的概率则为1-p。
伯努利分布的概率质量函数(PMF)为:

分段函数比较简单易懂,但是对于后面的推导比较麻烦,于是有:

对上式进行log操作:

其中,令
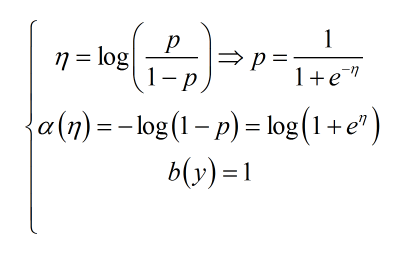
所以可以得出伯努利分布属于指数族分布。
即伯努利分布满足广义线性模型的第一个假设,下面利用广义线性模型后面两个假设得到:

四、目标函数
假设训练集中有 m 个样本,每个样本属于正类别的概率为 ,属于负类别的概率就是
,在训练过程中,我们应该尽可能地使整个训练集的分类结果与这 m 个样本的类别标记尽可能地一致。换句话说,我们要使训练样本集分类正确的似然函数最大(每个样本相互独立),而我们可以很容易地写出如下的似然函数:

其中是训练集中第 i 个样本已经被标记好的类别,若
为1.则上式的前半部分起作用,反之后半部分起作用。由于对
整体求
,其极值点保持不变,因此
可以简化为:
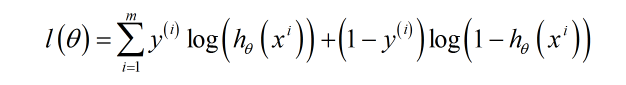
接下来的任务是求相应  的值,使得
的值,使得取最大值。如果对
整体取负号即为Logistic回归的损失函数(loss function),相应地,应该求使
取最小值的
 。
。
五、求解过程与正则化
一般采用梯度下降法对进行求解,这里不再细说。
在实际应用中,为了防止过拟合,使得模型具有较强的泛化能力,往往还需要在目标函数中加入正则项。在逻辑回归的实际应用中,L1正则应用较为广泛,原因是在面临诸如广告系统等实际应用的场景,特征的维度往往达到百万级甚至上亿,而L1正则会产生稀疏模型,在避免过拟合的同时起到了特征选择的作用。
六、总结
优点:
简单易于实现。
逻辑回归可以输出一个[0,1]之间的浮点数,也就是不仅可以产生分类的类别,同时产生属于该类别的概率。
逻辑回归是连续可导的,易于最优化求解。
缺点:
容易过拟合
原始的逻辑回归只能处理两分类问题,且必须线性可分。
七、拓展
为什么逻辑回归使用交叉熵损失函数而不用均方误差?参考https://blog.csdn.net/dpengwang/article/details/96597606
