1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
HDFS:
(1)功能:
NameNode:负责管理文件系统的 namespace 以及客户端对文件的访问;
DataNode:用于管理它所在节点上的存储;
FailoverController:故障切换控制器,负责监控与切换 Namenode 服务;
JournalNode:用于存储 EditLog;
Balancer:用于平衡集群之间各节点的磁盘利用率;
HttpFS:提供 HTTP 方式访问 HDFS 的功能。
(2)工作原理:
HDFS组成:
- NameNode:Master节点(也称元数据节点),是系统唯一的管理者。负责元数据的管理(名称空间和数据块映射信息);配置副本策略;处理客户端请求
- DataNode:数据存储节点(也称Slave节点),存储实际的数据;执行数据块的读写;汇报存储信息给NameNode
- Sencondary NameNode:分担namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。注意:在hadoop 2.x 版本,当启用 hdfs ha 时,将没有这一角色
- client:系统使用者,调用HDFS API操作文件;与NameNode交互获取文件元数据;与DataNode交互进行数据读写。注意:写数据时文件切分由Client完成
HDFS架构原则:
- 元数据与数据分离:文件本身的属性(即元数据)与文件所持有的数据分离
- 主/从架构:一个HDFS集群是由一个NameNode和一定数目的DataNode组成
- 一次写入多次读取:HDFS中的文件在任何时间只能有一个Writer。当文件被创建,接着写入数据,最后,一旦文件被关闭,就不能再修改
- 移动计算比移动数据更划算:数据运算,越靠近数据,执行运算的性能就越好,由于hdfs数据分布在不同机器上,要让网络的消耗最低,并提高系统的吞吐量,最佳方式是将运算的执行移到离它要处理的数据更近的地方,而不是移动数据
(3)工作过程:
写操作
1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
读操作
1、跟namenode通信查询元数据,找到文件块所在的datanode服务器
2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件
MapReduce:
(1)功能:
MapReduce提供了以下的主要功能:
1)数据划分和计算任务调度:
系统自动将一个作业(Job)待处理的大数据划分为很多个数据块,每个数据块对应于一个计算任务(Task),并自动 调度计算节点来处理相应的数据块。作业和任务调度功能主要负责分配和调度计算节点(Map节点或Reduce节点),同时负责监控这些节点的执行状态,并 负责Map节点执行的同步控制。
2)数据/代码互定位:
为了减少数据通信,一个基本原则是本地化数据处理,即一个计算节点尽可能处理其本地磁盘上所分布存储的数据,这实现了代码向 数据的迁移;当无法进行这种本地化数据处理时,再寻找其他可用节点并将数据从网络上传送给该节点(数据向代码迁移),但将尽可能从数据所在的本地机架上寻 找可用节点以减少通信延迟。
3)系统优化:
为了减少数据通信开销,中间结果数据进入Reduce节点前会进行一定的合并处理;一个Reduce节点所处理的数据可能会来自多个 Map节点,为了避免Reduce计算阶段发生数据相关性,Map节点输出的中间结果需使用一定的策略进行适当的划分处理,保证相关性数据发送到同一个 Reduce节点;此外,系统还进行一些计算性能优化处理,如对最慢的计算任务采用多备份执行、选最快完成者作为结果。
4)出错检测和恢复:
以低端商用服务器构成的大规模MapReduce计算集群中,节点硬件(主机、磁盘、内存等)出错和软件出错是常态,因此 MapReduce需要能检测并隔离出错节点,并调度分配新的节点接管出错节点的计算任务。同时,系统还将维护数据存储的可靠性,用多备份冗余存储机制提 高数据存储的可靠性,并能及时检测和恢复出错的数据。
(2)工作原理:
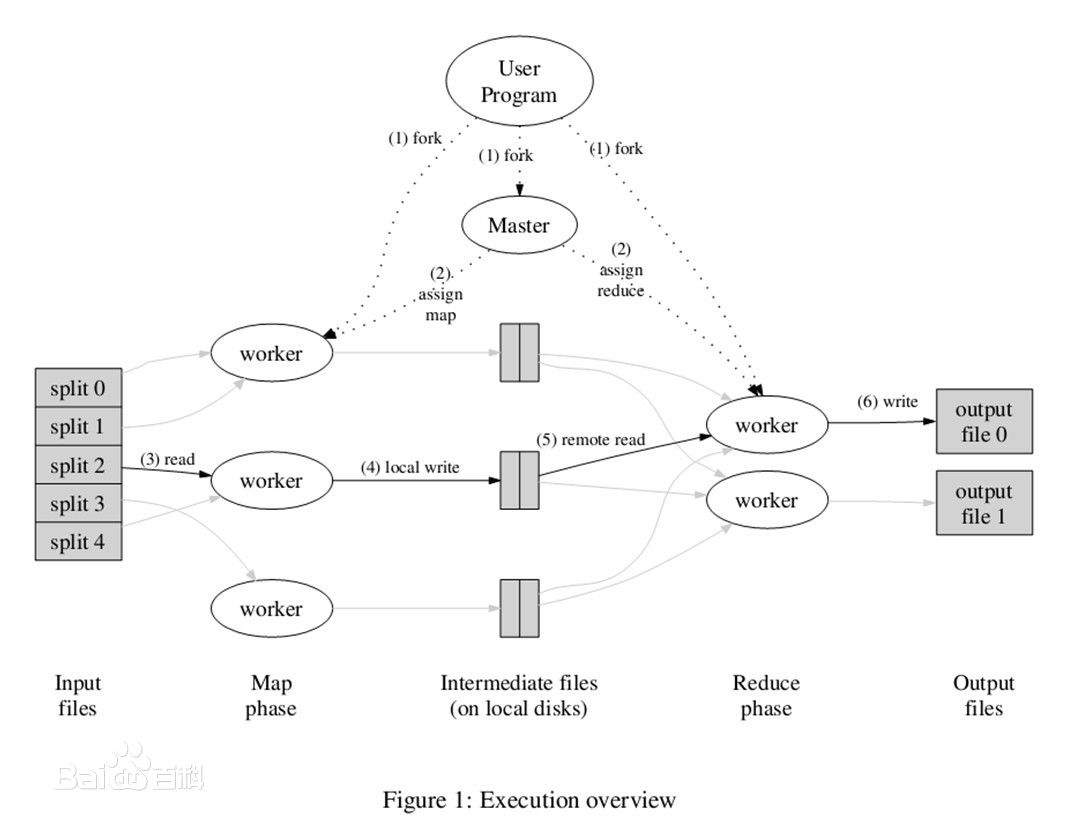
下图是论文里给出的流程图。一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。图中执行的顺序都用数字标记了。
1.MapReduce库先把user program的输入文件划分为M份(M为用户定义),每一份通常有16MB到64MB,如图左方所示分成了split0~4;然后使用fork将用户进程拷贝到集群内其它机器上。
2.user program的副本中有一个称为master,其余称为worker,master是负责调度的,为空闲worker分配作业(Map作业或者Reduce作业),worker的数量也是可以由用户指定的。
3.被分配了Map作业的worker,开始读取对应分片的输入数据,Map作业数量是由M决定的,和split一一对应;Map作业从输入数据中抽取出键值对,每一个键值对都作为
参数传递给map函数,map函数产生的中间键值对被
缓存在内存中。
4.缓存的中间键值对会被定期写入
本地磁盘,而且被分为R个区,R的大小是由用户定义的,将来每个区会对应一个Reduce作业;这些中间键值对的位置会被通报给master,master负责将信息转发给Reduce worker。
5.master通知分配了Reduce作业的worker它负责的分区在什么位置(肯定不止一个地方,每个Map作业产生的中间键值对都可能映射到所有R个不同分区),当Reduce worker把所有它负责的中间键值对都读过来后,先对它们进行排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个Reduce作业(谁让分区少呢),所以排序是必须的。
6.reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个分区的输出文件中。
7.当所有的Map和Reduce作业都完成了,master唤醒正版的user program,MapReduce
函数调用返回user program的代码。
所有执行完毕后,MapReduce输出放在了R个分区的输出文件中(分别对应一个Reduce作业)。用户通常并不需要合并这R个文件,而是将其作为输入交给另一个MapReduce程序处理。整个过程中,输入数据是来自底层
分布式文件系统(GFS)的,中间数据是放在本地文件系统的,最终输出数据是写入底层分布式文件系统(GFS)的。而且我们要注意Map/Reduce作业和map/reduce函数的区别:Map作业处理一个输入数据的分片,可能需要调用多次map函数来处理每个输入键值对;Reduce作业处理一个分区的中间键值对,期间要对每个不同的键调用一次reduce函数,Reduce作业最终也对应一个输出文件。
(3)工作过程:
MapReduce的工作过程分为两个步骤:map和reduce。每个阶段的输入输出都是key-value的形式,key和value的类型可以自行指定。map阶段对切分好的数据进行并行处理,处理结果传输给reduce,由reduce函数完成最后的汇总。
2.HDFS上运行MapReduce
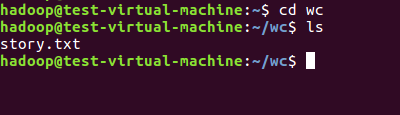
1)准备文本文件,放在本地/home/hadoop/wc
![]()
![]()
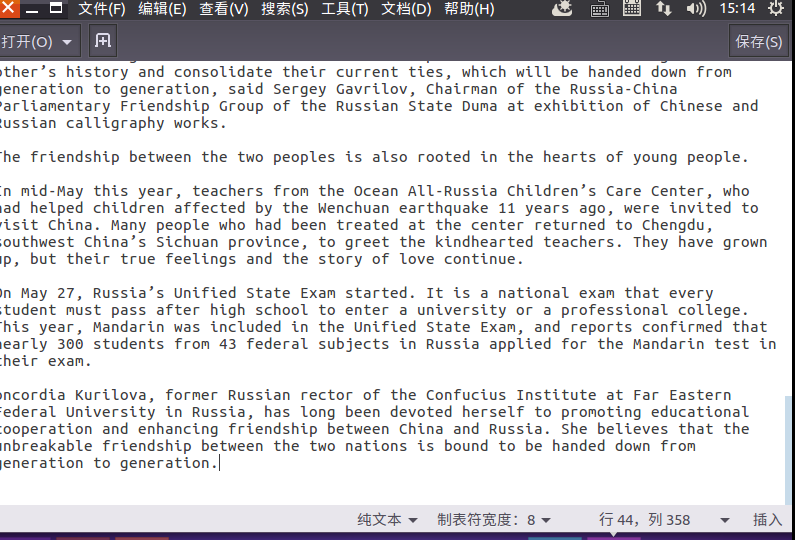
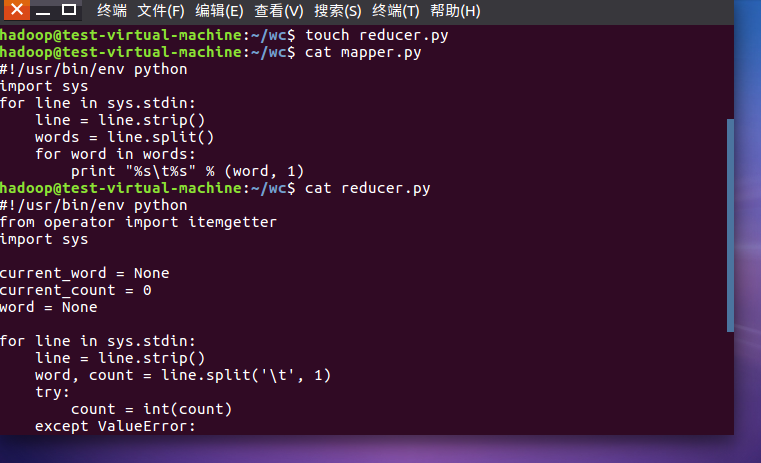
2)编写map函数和reduce函数,在本地运行测试通过
![]()
![]()
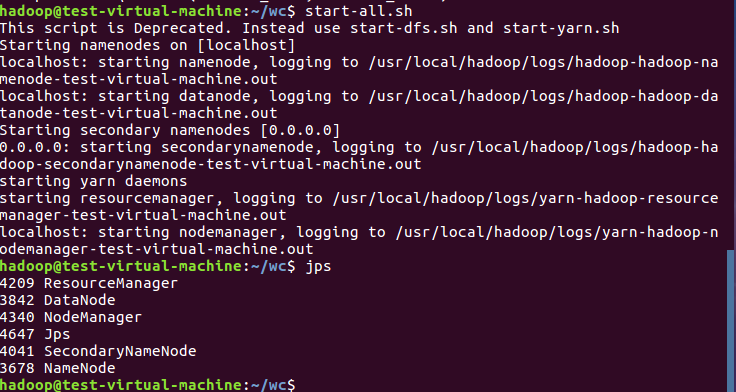
3)启动Hadoop:HDFS, JobTracker, TaskTracker
![]()
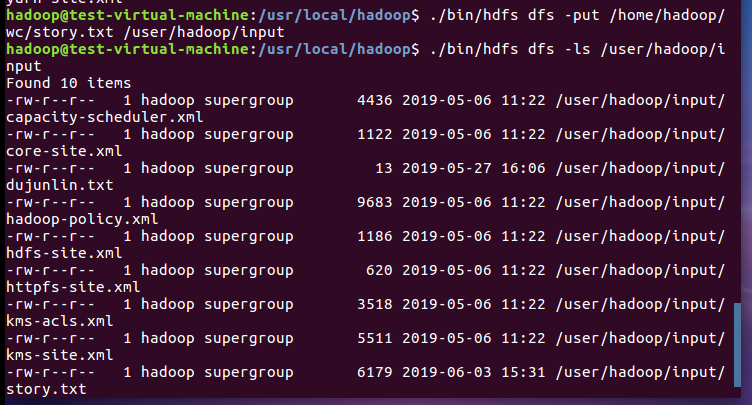
4)把文本文件上传到hdfs文件系统上 user/hadoop/input
![]()
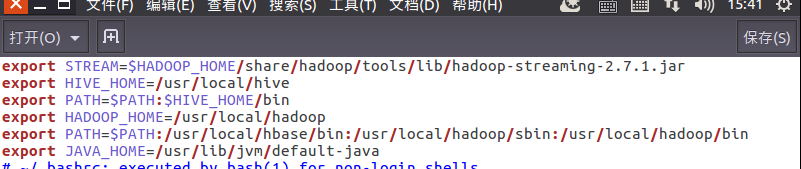
5)streaming的jar文件的路径写入环境变量,让环境变量生效
![]()
![]()
6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh
![]()
![]()
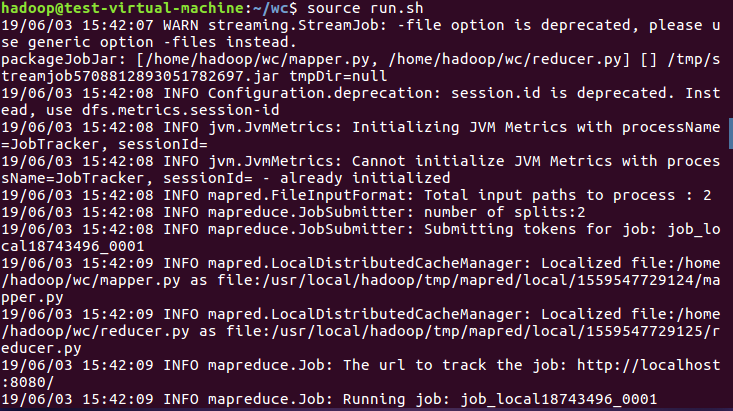
7)source run.sh来执行mapreduce
![]()
![]()
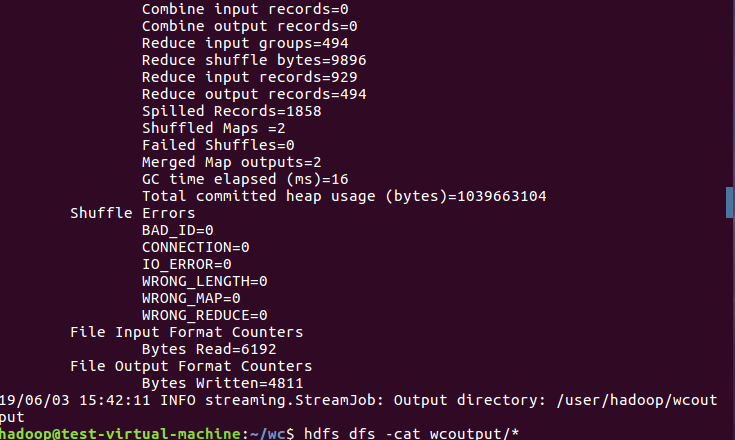
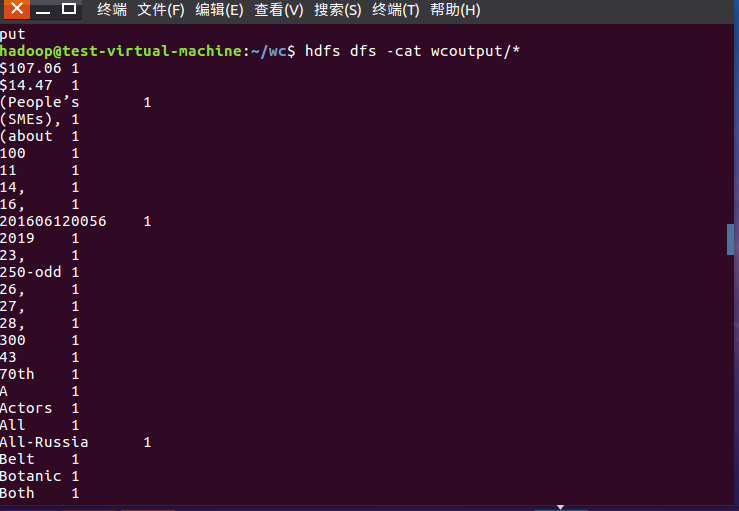
8)查看运行结果
![]()