

一.把爬取的内容保存取MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
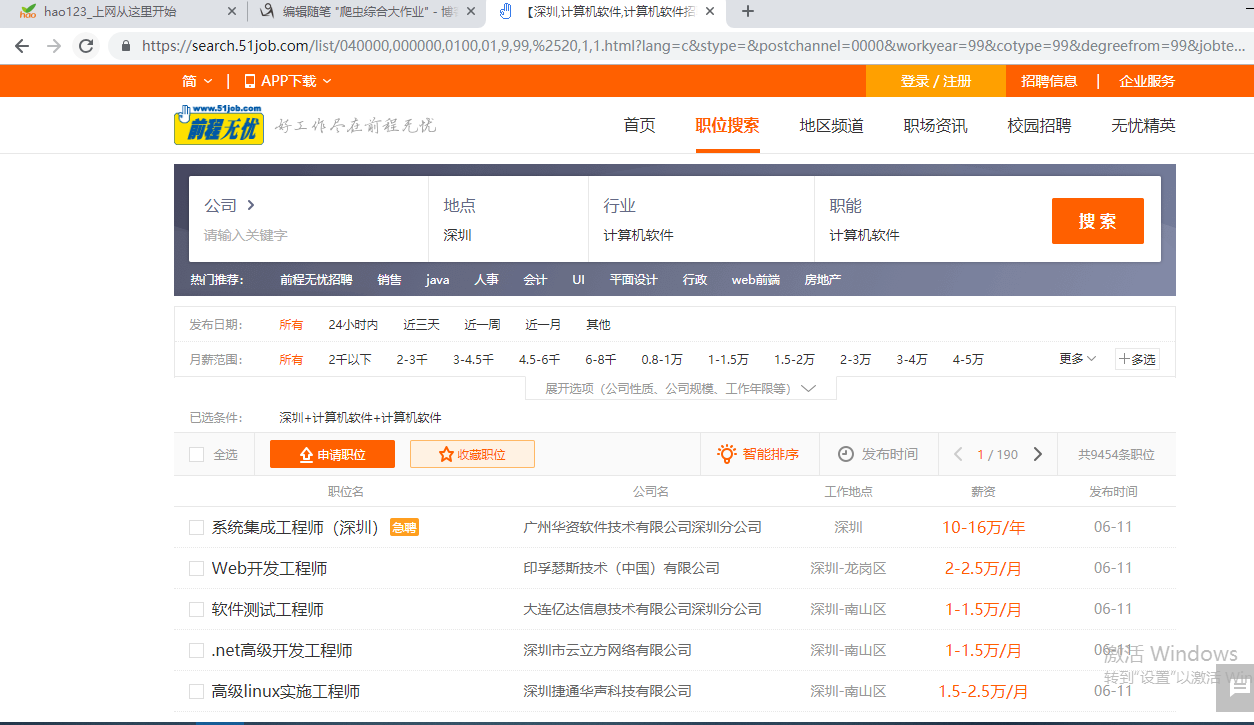
爬取目标:爬取前程无忧中深圳市计算机行业的招聘信息(网站链接:https://search.51job.com)
网页情况:
爬取代码:
from urllib import request
from bs4 import BeautifulSoup
import re
import pymysql
import time
import requests
import pandas as pd
import sqlite3
import time
import random
#获取数据
def get_data(i):
t = False
headers = {'User_Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}
url = "https://search.51job.com/list/040000,000000,0000,00,9,99,python,2,{}.html".format(i+1)
req = request.Request(url,headers=headers)
response = request.urlopen(req)
if response.getcode() == 200:
data = response.read() #读取响应的数据,byte类型
data = str(data,encoding='gbk')
with open('index.html',mode='w+',encoding='utf-8') as f:
f.write(data)
t = True
return t
#print(data)
#解析数据,提取数据
def parse_data():
with open('index.html', mode='r', encoding='utf-8') as f:
html = f.read()
bs =BeautifulSoup(html,'html.parser') #使用指定html解析器parser
divs = bs.select('#resultList .el') # 寻找id为resultList的控件里的类名为el的部分
result = [];
for div in divs[1:]:
title = div.select('.t1')[0].get_text(strip=True)
company = div.select('.t2')[0].get_text(strip=True)
addr = div.select('.t3')[0].get_text(strip=True)
salary = div.select('.t4')[0].get_text(strip=True)
pubdata = div.select('.t5')[0].get_text(strip=True)
row = {
'职位': str(title),
'公司': str(company),
'地址': str(addr),
'月薪': str(salary),
'发布日期': str(pubdata)
}
result.append(row)
print(result)
#print(type(result[1].values()))
return result
def setCSV(infoList):
newsdf = pd.DataFrame(infoList); #创建二维表格型数据结构。
newsdf.to_csv("jin.csv",encoding="utf-8");
print(newsdf);
with sqlite3.connect('newsdb.sqlite') as db: #保存到数据库
newsdf.to_sql('newsdb', db)
if __name__ == '__main__':
infoList=[]
for i in range(10):
get_data(i+1)
if get_data(i+1) == True:
info=parse_data();
infoList.extend(info);
time.sleep(random.random() * 5); #爬取网页时间间隔
setCSV(infoList);
运行结果:
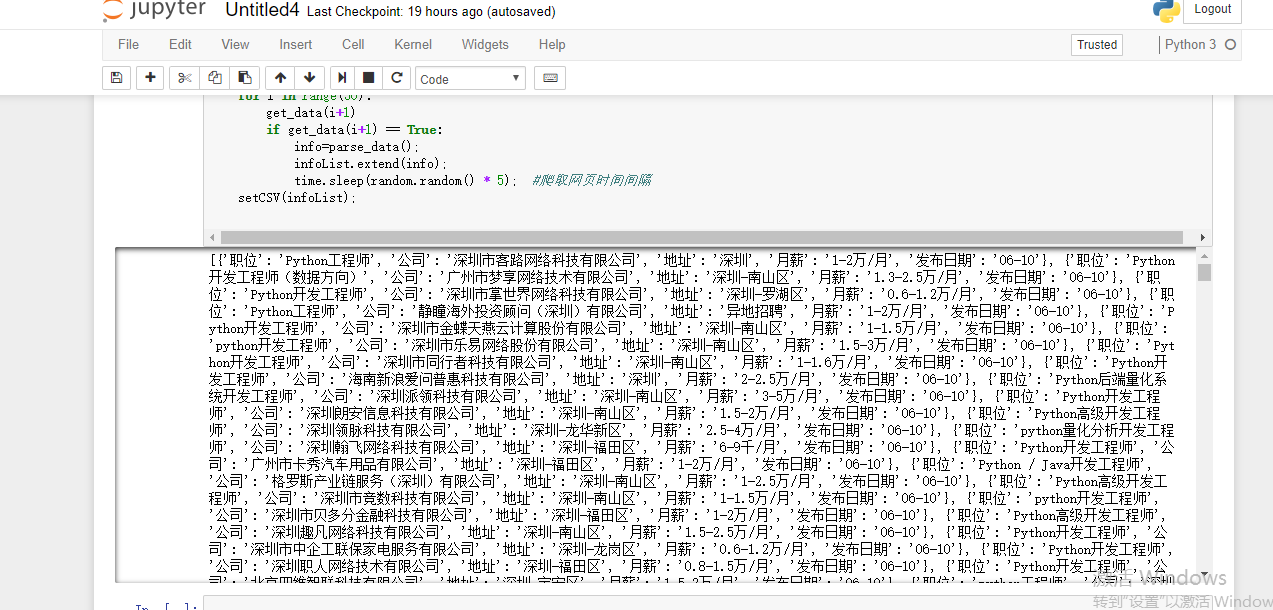
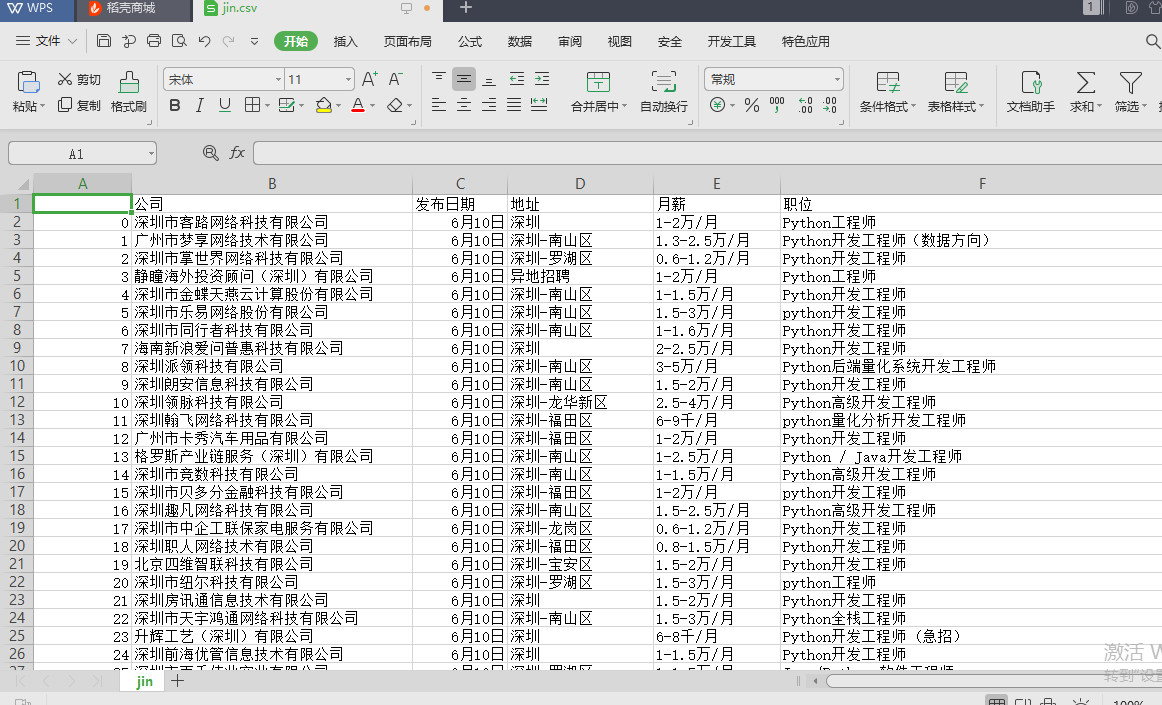
爬取生成的文件:

可以看出,已经爬取出了所想要的数据,并生成了表格(共2500条记录)。
1.分析职位类别并生成词云:

由上图可知,深圳对计算机行业人才的需求主要表现为工程师、运维、测试等人才。
2.分析工作地址并生成词云:
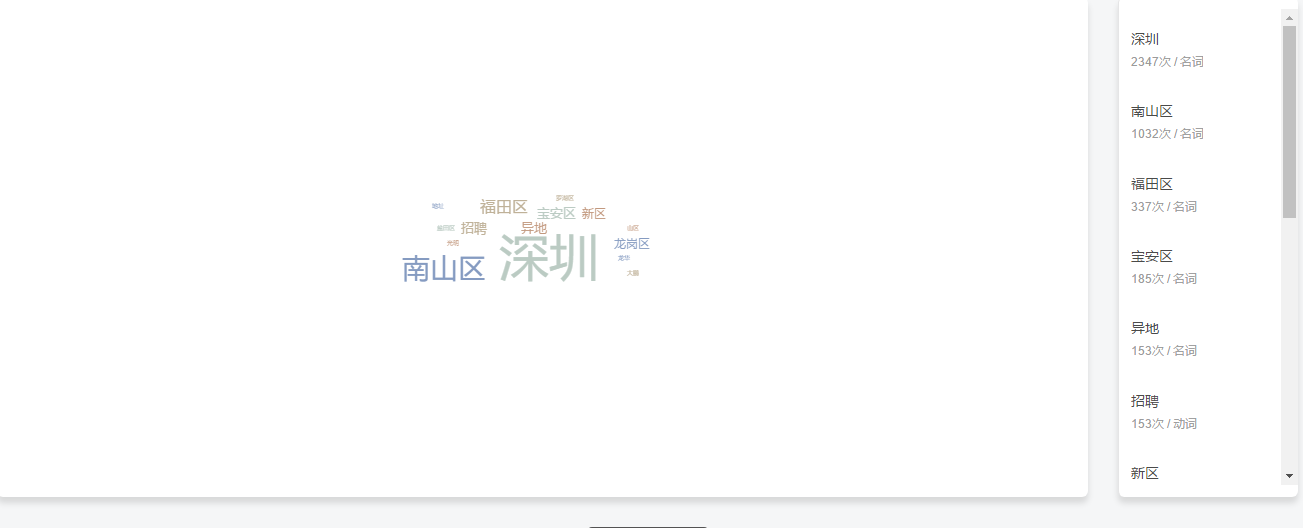
由上图可知,深圳计算机行业的工作地址主要分布在南山区、福田区和宝安区。
