

作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2646
1.字符串操作:
- 解析身份证号:生日、性别、出生地等。
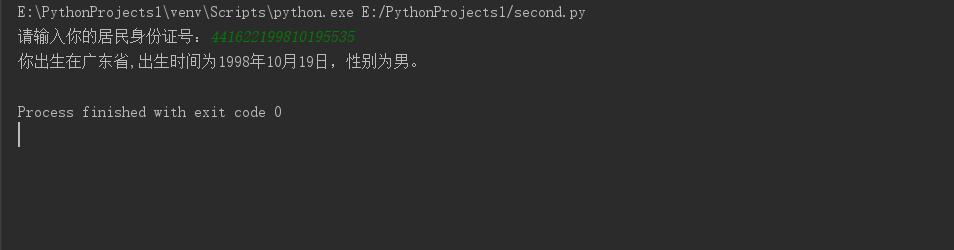
number=input("请输入你的居民身份证号:") year=number[6:10] #出生年 month=number[10:12] #出生月 day=number[12:14] #出生日 sex=number[14:17] #性别 j=0 if len(number) != 18:#验证身份证长度是否正确 print('你的身份证号码有误! ') else: num = {'44': '广东省', '11': '北京市', '12': '天津市', '13': '河北省', '14': '山西省', '15': '内蒙古', '21': '辽宁省', '31': '上海市', '35': '福建省', '42': '湖北省', '43': '湖南省', '45': '广西省', '51': '四川省', '63': '青海省', '36': '江西省', '37': '山东省', '33': '浙江省', '34': '安徽省'} if int(sex) % 2 == 0:#验证性别 xingbie='女' else: xingbie='男' print('你出生在{},出生时间为{}年{}月{}日,性别为{}。'.format(num[number[0:2]],year,month,day,xingbie))
结果如图:
- 凯撒密码编码与解码
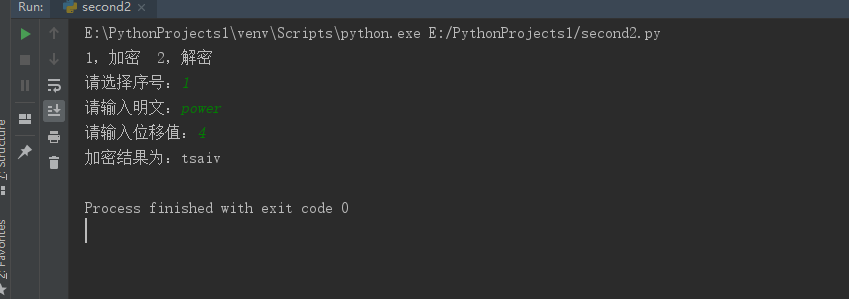
print("1,加密 2,解密") choose=input("请选择序号:") if choose == "1": str_raw = input("请输入明文:") k = int(input("请输入位移值:")) str_change = str_raw.lower() str_list = list(str_change) str_list_encry = str_list i = 0 while i < len(str_list): if ord(str_list[i]) < 123 - k: str_list_encry[i] = chr(ord(str_list[i]) + k) else: str_list_encry[i] = chr(ord(str_list[i]) + k - 26) i = i + 1 print("加密结果为:" + "".join(str_list_encry)) elif choose == "2": str_raw = input("请输入密文:") k = int(input("请输入位移值:")) str_change = str_raw.lower() str_list = list(str_change) str_list_decry = str_list i = 0 while i < len(str_list): if ord(str_list[i]) >= 97 + k: str_list_decry[i] = chr(ord(str_list[i]) - k) else: str_list_decry[i] = chr(ord(str_list[i]) + 26 - k) i = i + 1 print("解密结果为:" + "".join(str_list_decry)) else: print("你的输入有误!")
结果如下图:

- 网址观察与批量生成
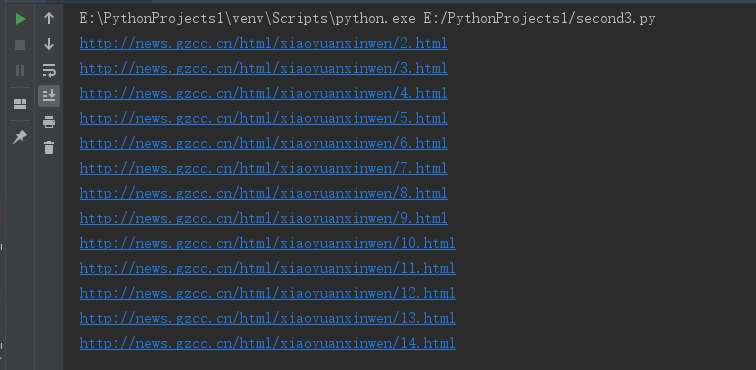
for i in range(2,15): url='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) print(url)
结果如图:
2.英文词频统计预处理
- 下载一首英文的歌词或文章或小说,保存为utf8文件。
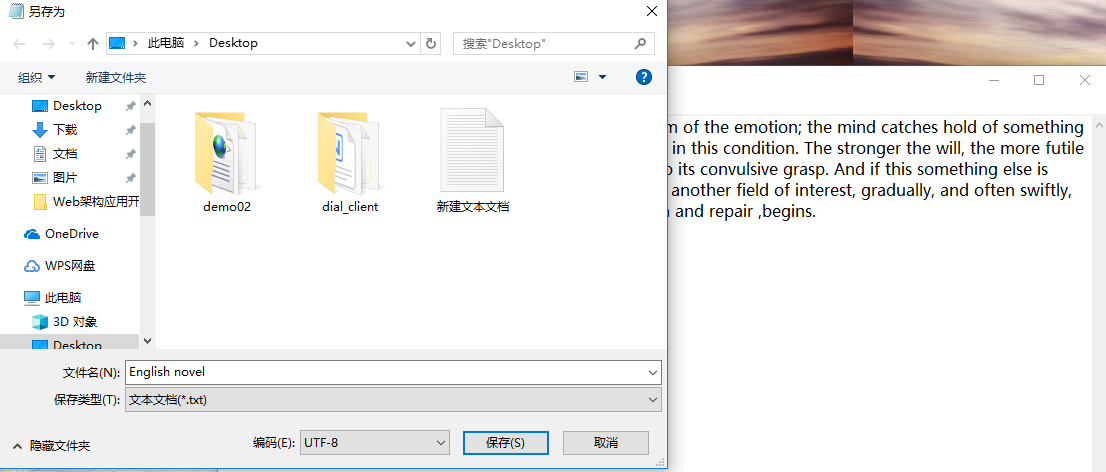
- 从文件读出字符串。
fo=open('English novel.txt','r',encoding='utf8') text=fo.read() print(text)

- 将所有大写转换为小写
fo=open('English novel.txt','r',encoding='utf8') text=fo.read() texts=text.lower() print(texts)

- 将所有其他做分隔符(,.?!)替换为空格
fo=open('English novel.txt','r',encoding='utf8') text=fo.read() sep = ',.?!;:_' for s in sep: text = text.replace(s,' ') print(text)

- 分隔出一个一个的单词
fo=open('English novel.txt','r',encoding='utf8') text=fo.read() print(text.split())

- 并统计单词出现的次数。
fo=open('English novel.txt','r',encoding='utf8') text=fo.read() print(text.count("is"))


