
如何解决大批量数据保存的性能问题
2020-01-21 10:53 .net小跟班(杜) 阅读(945) 评论(0) 编辑 收藏 举报一、背景
明源云ERP开放平台提供了强大的基于实体的ORM框架:“实体服务”,它可以让开发人员只需专注于业务逻辑代码的编写,不用关心数据库相关的操作,大大提高了开发效率。
在行业中所有基于实体的ORM框架,均存在同一个问题:在批量操作数据时,性能表现乏力。因为在批量保存数据时,可能既包含新增的记录,又包含更新或删除的记录,一般的ORM框架必须为每一条记录生成一条SQL语句,然后一条一条的执行,这样执行的性能非常差,而通常的优化方案是将数据分批保存,但在数据量特别大时,保存的性能表现依然无法接受。在ERP的业务中,存在很多这种批量操作大量数据的场景,例如通过Excel批量导入大量数据,而且这类功能基本都出现在核心的业务模块,所以我们必须要攻克这个问题。
二、初步优化
如前所述,ORM框架之所以在大批量数据保存时性能差,主要原因是它必须一条一条的执行SQL,熟悉数据库技术的同学应该清楚,每次SQL执行都会用到数据库连接,而频繁开启连接会给数据库造成巨大压力。所以我们一开始想到的优化方案,就是将这批SQL一次性发给数据库执行,只开一次数据库连接。
我们将SQL一次性发给数据库执行,确实大幅减少了开启数据库连接的次数,但依然存在性能问题。经过技术分析,我们发现原因在于发给数据库执行的SQL语句太大,造成了网络传输延迟过大。比如本次要批量保存的数据行数有10万,字段超过50个,需执行的SQL语句就有10万条,虽然是一次性执行,但SQL本身可能有几兆。
为了解决这个问题,我们需要将10万条SQL语句合并起来,变成几条SQL去执行。
三、第二轮优化
我们实现合并SQL语句方案时,遇到的第一个问题是:批量保存的数据,其中每一行的状态是不一样的,有些行可能是新增,有些行可能是更新,有些可能是删除,不同类型的数据如何合并SQL?
解决方案:将新增、更新、删除三种类型的数据,分别合并成三条不同形式的SQL语句进行执行。
我们紧接着遇到了第二个问题:要更新的每一行数据中,更新的字段也不一样,可能第一行要更新A字段,第二行要更新B字段,每一行的Update语句都不一样,如何合并成一条SQL?
解决方案:不管每一行要更新哪些字段,我们合并后的SQL都更新所有字段,然后再使用一个标识字段表示该字段是否需要插入或更新,这样就能用同一条SQL更新所有行。
1、新增场景
核心思路:通过参数化和“Insert...Select”的SQL语句,一次性将要新增的记录插入MyUser表(如果没有值,则使用字段的默认值代替)。
合并后的SQL语句如下:

2、更新场景
核心思路:通过判断字段值是否更新,动态拼接Set语句的右值。
合并后的SQL语句如下:

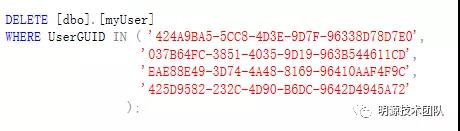
3、删除场景
核心思路:通过In子查询,根据ID批量删除记录。
合并后的SQL语句如下:
通过上述优化方法,SQL语句本身大幅缩减,但依然存在两个问题:
-
合并后的SQL用到参数化,但数据库限制参数最多2100个,如果待保存的数据行数过多时,会超出参数个数限制;
-
由于子查询的语句长度会随着记录增大而增加,数据量特别大时,产生的SQL语句依然很大,依然会存在性能隐患。
四、第三轮优化
为了解决这两个问题,我们通过SqlBulkCopy机制,快速的将待保存数据一次性插入到数据库的临时表,SQL语句通过关联临时表进行批量新增、修改、删除,这样SQL语句本身可以变得更加简短,而且因为去掉了参数化查询,也规避了参数个数限制的问题。(Microsoft SQL Server中提供了大容量复制程序实用工具 (bcp),用于快速将大型文件批量复制到SQL Server数据库中的表或视图中。在ADO.Net中,SqlBulkCopy类提供了托管代码的解决方案,支持类似的功能。)
我们的具体做法如下:
-
在数据库中创建与子查询同结构的临时表,比如用户表,可以创建对应的临时表#temp_myUser;
-
使用SqlBulkCopy将所有待保存的数据一次性插入到临时表中;
-
合并后的SQL通过关联临时表,将数据保存到业务表中;
-
删除临时表,完成数据批量操作。
通过关联临时表合并成的最终SQL语句如下:
1、新增场景:

2、更新场景:

3、删除场景:


