JUC自定义线程池练习
JUC自定义线程池练习
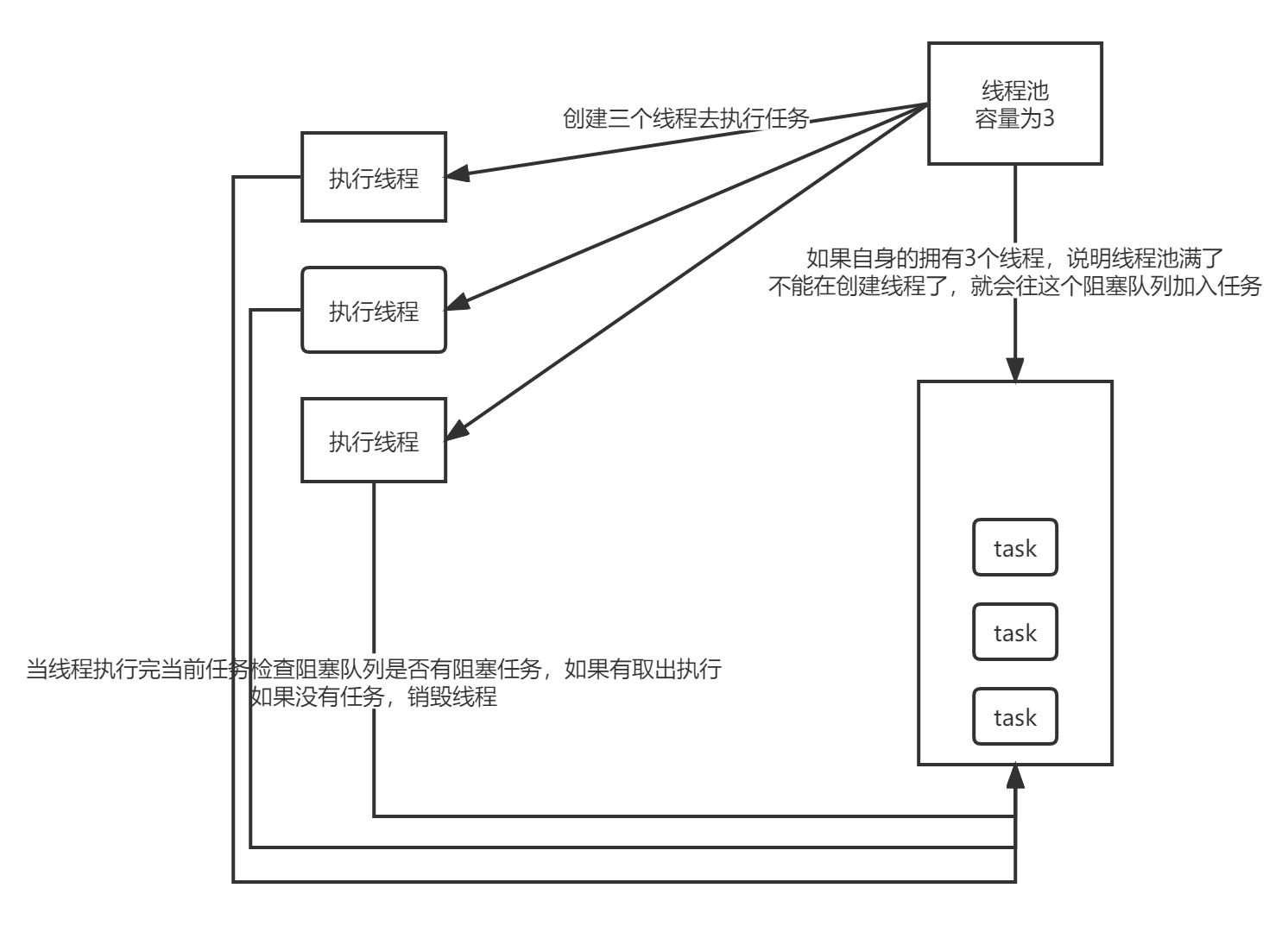
首先上面该线程池的大致流程
自定义阻塞队列
- 首先定义一个双向的队列和锁一定两个等待的condition
- 本类用lock来控制多线程下的流程执行
- take和push方法就是死等,调用await就是等,后面优化为限时等待
- take调用后取出阻塞队列的task后会调用fullWaitSet的signal方法来唤醒因为阻塞队列满了的线程将task放入阻塞队列。
@Slf4j
class TaskQueue<T> {
// 双向的阻塞队列
private Deque<T> deque;
// 队列最大容量
private int capacity;
// 锁
private ReentrantLock lock = new ReentrantLock();
// 消费者任务池空的等待队列
private Condition emptyWaitSet = lock.newCondition();
// 生产者任务池满的等待队列
private Condition fullWaitSet = lock.newCondition();
public TaskQueue(int capacity) {
this.capacity = capacity;
deque = new ArrayDeque<>(capacity);
}
// 死等take,即从阻塞队列取出任务
public T take() {
lock.lock();
try {
while (deque.isEmpty()) {
try {
emptyWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("取走任务");
T task = deque.pollFirst();
fullWaitSet.signal();
return task;
} finally {
lock.unlock();
}
}
// 线程添加任务,属于是死等添加
public void push(T task) {
lock.lock();
try {
while (deque.size() >= capacity) {
try {
fullWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("添加任务");
deque.offerLast(task);
emptyWaitSet.signal();
} finally {
lock.unlock();
}
}
public int getSize() {
lock.lock();
try {
return deque.size();
}finally {
lock.unlock();
}
}
}
优化,死等优化为超时等
- awaitNanos方法返回的是等待的剩余时间,如果已经等了base时间就会返回0,如果没有就会返回大于0即还没有等待的时间,防止虚假唤醒导致重新等待时间加长。当然在本题的设计中不会出现虚假唤醒的情况。
public T poll(Long timeout,TimeUnit unit) {
lock.lock();
try {
long base = unit.toNanos(timeout);
while (deque.isEmpty()) {
try {
if (base <= 0){
return null;
}
base = emptyWaitSet.awaitNanos(base); // 返回还剩下的时间
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("取走任务");
T task = deque.pollFirst();
fullWaitSet.signal();
return task;
} finally {
lock.unlock();
}
}
线程池类
- 成员变量如下,对于Worker就工作线程
@Slf4j
class ThreadPool {
// 阻塞队列大小
private int capacity;
// 阻塞队列
private TaskQueue<Runnable> taskQueue;
// 工作线程
private HashSet<Worker> workerSet = new HashSet<>();
// 核心数
private int coreNum;
// 超时等待时间
private long timeout;
// 超时等待单位
private TimeUnit unit;
// 拒绝策略
private RejectPolicy rejectPolicy;
// 线程对象
class Worker extends Thread {
private Runnable task;
public Worker(Runnable runnable) {
this.task = runnable;
}
@Override
public void run() {
// 就是线程把当前分配的任务做完,然后还要去阻塞队列找活干,没活就退出
// taks 如果不为空就执行然后讲其置为空,后续再次进入循环后会从阻塞队列中再次取出task,
// 如果不为空就继续执行,但是因为take死等,会导致无法结束
// 使用了这个超时等的方法,当无法取出时就会退出程序
while (task != null || (task = taskQueue.poll(timeout,unit)) != null) {
try {
log.debug("开始执行任务");
Thread.sleep(1000);
task.run();
} catch (Exception e) {
e.printStackTrace();
} finally {
task = null;
}
}
// 当没有任务可执行,线程自动销毁,由于这是根据对象来销毁,且hashset无序,所以这里无需保证其的线程安全。
workerSet.remove(this);
}
}
public ThreadPool(int capacity, int coreNum, long timeout, TimeUnit unit,RejectPolicy rejectPolicy) {
this.capacity = capacity;
this.coreNum = coreNum;
this.timeout = timeout;
this.unit = unit;
this.taskQueue = new TaskQueue<>(capacity);
this.rejectPolicy = rejectPolicy;
}
/**
* 当线程数大于核心数,就将任务放入阻塞队列
* 否则创建线程进行处理
*
* @param runnable
*/
public void execute(Runnable runnable) {
// 需要synchronized关键字控制多线程下对执行方法的执行,保证共享变量workerSet安全。
synchronized (workerSet) {
// 如果已经存在的工作线程已经大于核心数,就不适合在进行创建线程了,创太多线程对于执行并不会加快,反而会因为线程不断切换而拖累CPU的执行。
if (workerSet.size() >= coreNum) {
taskQueue.push(runnable);
} else {
// 如果工作线程小于核心数就可创建一个worker线程来工作
Worker worker = new Worker(runnable);
workerSet.add(worker);
worker.start();
}
}
}
}
测试类
@Slf4j
public class MyThreadPool {
public static void main(String[] args) {
ThreadPool threadPool = new ThreadPool(3,2,1,TimeUnit.SECONDS,(taskQueue,task)->{
taskQueue.push(task);
});
for (int i = 0; i < 10; i++) {
int j = i;
threadPool.execute(() -> {
log.debug("任务{}", j);
});
}
}
}
优化---拒绝策略
我们没有进行优化的就是当任务太多导致阻塞线程也满了,此时任务线程就会进行阻塞,直到等到有人在线程池中取走任务。也就是push方法,我们在旧的方法中仍采用的是死等的方法。
但是方法中有很多死等,超时等,放弃任务,抛出异常,让调用者自己执行任务等等方法。
我们就可用讲其进行抽象,把操作交给调用者。
定义了如下的函数式接口,即为拒绝策略。
@FunctionalInterface
interface RejectPolicy<T>{
void reject(TaskQueue<T> taskQueue,T task);
}
将在TaskQueue任务队列中定义不同的策略,我们只要传入这个函数式接口的实现对象就可用实现定制拒绝的策略。
在TaskQueue类添加一个方法,用来调用拒绝策略
public void tryAndAdd(T task,RejectPolicy rejectPolicy){
lock.lock();
try {
if (deque.size() >= capacity) {
rejectPolicy.reject(this,task);
}else{
log.debug("添加任务");
deque.offerLast(task);
emptyWaitSet.signal();
}
} finally {
lock.unlock();
}
}
更改了构造方法的线程池类,这样就可用传入一个自定义的拒绝策略。
@Slf4j
class ThreadPool {
// 阻塞队列大小
private int capacity;
// 阻塞队列
private TaskQueue<Runnable> taskQueue;
// 工作线程
private HashSet<Worker> workerSet = new HashSet<>();
// 核心数
private int coreNum;
// 超时等待时间
private long timeout;
// 超时等待单位
private TimeUnit unit;
// 拒绝策略
private RejectPolicy rejectPolicy;
// 线程对象
class Worker extends Thread {
private Runnable task;
public Worker(Runnable runnable) {
this.task = runnable;
}
@Override
public void run() {
while (task != null || (task = taskQueue.poll(timeout,unit)) != null) {
try {
log.debug("开始执行任务");
Thread.sleep(1000);
task.run();
} catch (Exception e) {
e.printStackTrace();
} finally {
task = null;
}
}
workerSet.remove(this);
}
}
public ThreadPool(int capacity, int coreNum, long timeout, TimeUnit unit,RejectPolicy rejectPolicy) {
this.capacity = capacity;
this.coreNum = coreNum;
this.timeout = timeout;
this.unit = unit;
this.taskQueue = new TaskQueue<>(capacity);
this.rejectPolicy = rejectPolicy;
}
/**
* 当线程数大于核心数,就将任务放入阻塞队列
* 否则创建线程进行处理
*
* @param runnable
*/
public void execute(Runnable runnable) {
synchronized (workerSet) {
if (workerSet.size() >= coreNum) {
taskQueue.tryAndAdd(runnable,rejectPolicy);
} else {
Worker worker = new Worker(runnable);
workerSet.add(worker);
worker.start();
}
}
}
}
将启动类修改如下
@Slf4j
public class MyThreadPool {
public static void main(String[] args) {
ThreadPool threadPool = new ThreadPool(3,2,1,TimeUnit.SECONDS,(taskQueue,task)->{
// 采用死等的方法,当然我们可用在taskQueue中定义更多的方法让调用者选择
taskQueue.push(task);
});
for (int i = 0; i < 10; i++) {
int j = i;
threadPool.execute(() -> {
log.debug("任务{}", j);
});
}
}
}
这样我们就完成了自定义的线程池。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY