NodeJS实现简单的HTTP文件断点续传下载功能
1.简述HTTP的断点续传原理
1.1.检查是否支持范围请求
我举下载nginx为例,打开http://nginx.org/en/download.html后点击对应的下载在浏览器network可以看到有 Accept-Ranges:bytes 标识
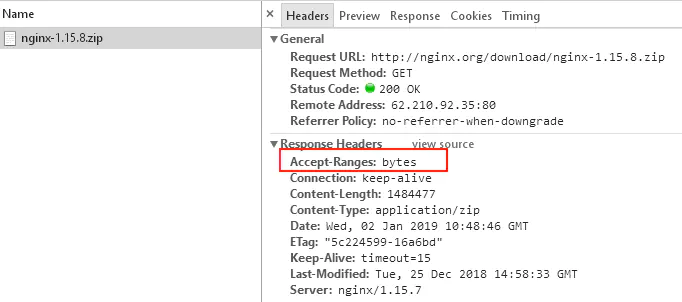
没错通过Accept-Ranges:bytes可标识当前资源是支持范围请求的。
1.2.获取与发送范围请求
在HTTP/1.1中定义了一个Ranges的请求头来指定请求的实体的范围,它的范围取值是在 0 - 总Content-Length 之间,使用 - 进行分割。
当然还有种方式可以获取总的Content-Length,同样举下载nginx为例子
在http://nginx.org/下运行一下代码
fetch("http://nginx.org/download/nginx-1.15.8.zip", {
method: "GET", //请求方式
mode: 'cors',
headers: { //请求头
"Cache-Control": "no-cache",
Connection: "keep-alive",
Pragma: "no-cache",
Range: "bytes=0-1"
}
}).then(r => {
r.headers.forEach(function(v, i, a) {
console.log(i + " : " + v);
})
})
响应结果如图:
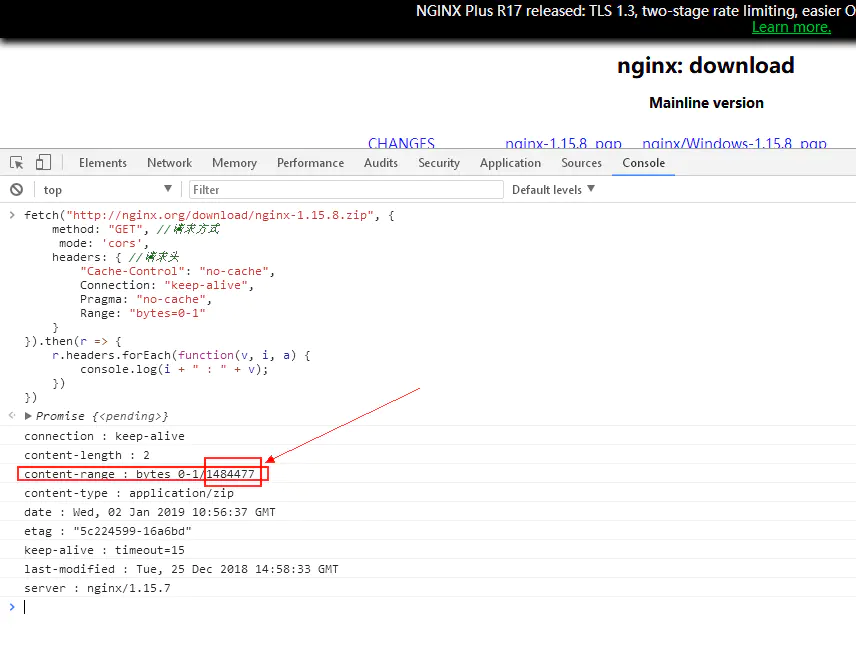
通过图片我们可以看到,通过指定Range: bytes=0-1发送请求后会有一个Content-Range响应头,而在值的格式是Range请求头的类型与范围值 / 总Content-Length
1.3.检查资源变化
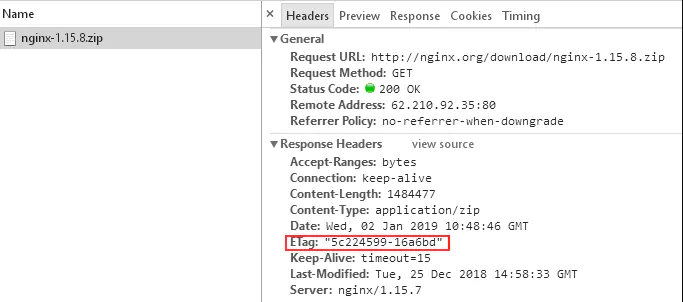
检查资源变化最简单的方式是通过判断响应头的ETag的值,ETag是当前请求的文件的一个验证令牌指纹,用于标识文件的唯一性。
ETag的生成规则有很多,比如Nginx官方的ETag计算出的值为文件最后修改时间16进制-文件长度16进制。例:ETag: “5c224599-16a6bd” 。
如图
2. 简单实现分段下载文件
我们根据HTTP的断点续传原理就可以简单的实现一个分块下载的功能。
原理就是先判断服务器是否支持分块,切分块的大小是否小于文件大小,如果小于则根据分块大小计算请求头中的Range的范围值去请求切割的块,最后如果所有分块都请求成功之后将其合并保存成文件。
代码如下:
const fetch = require("node-fetch");
var fs = require('fs'); // 引入fs模块
//获取响应头信息
function getResHeaders(u) {
return new Promise(function (resolve, reject) {
fetch(u, {
method: "GET", //请求方式
// mode: 'cors',
headers: { //请求头
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Cache-Control": "no-cache",
Connection: "keep-alive",
Pragma: "no-cache",
Range: "bytes=0-1"
}
}).then(r => {
let h = {};
r.headers.forEach(function (v, i, a) {
h[i.toLowerCase()] = v;
});
return resolve(h);
}).catch(reject);
});
}
//下载块
function downloadBlock(u, o) {
let option = {
'Content-Type': 'application/octet-stream',
"Cache-Control": "no-cache",
Connection: "keep-alive",
Pragma: "no-cache"
};
if (typeof o == "string") {
option["Range"] = "bytes=" + o;
} else if (typeof o == "object") {
option = Object.assign(option, o);
}
return fetch(u, {
method: 'GET',
headers: option,
}).then(res => res.buffer());
}
(async function () {
// let url = "http://cdn.npm.taobao.org/dist/node/v10.14.2/node-v10.14.2-x64.msi";
let url = "https://www.python.org/ftp/python/3.7.2/python-3.7.2-amd64.exe";
let fileName = url.split("/").reverse()[0].split("?")[0];
let fileBuffer = null;
//获取请求头信息
let h = await getResHeaders(url);
let contentRange = h["content-range"];
//分块大小
let blockSize = 1024 * 1024 * 4;//b
//判断是否支持分段下载
if (contentRange) {
//获取文件大小
let contentLength = Number(contentRange.split("/").reverse()[0]);
//判断是否后需要分块下载
if (contentLength >= blockSize) {
let etag = h.etag;
let contentType = h["content-type"];
let blockLen = Math.ceil(contentLength / blockSize);
let blist = [];
//计算分块
for (let i = 0, strat, end; i < blockLen; i++) {
strat = i * blockSize;
end = (i + 1) * blockSize - 1;
end = end > contentLength ? contentLength : end;
console.log("download:",strat, end);
let b = await downloadBlock(url, {
etag: etag,
'Content-Type': contentType,
"Range": "bytes=" + strat + "-" + end
});
blist.push(b);
}
fileBuffer = Buffer.concat(blist);
}
}
if (!fileBuffer) {
//直接下载
fileBuffer = await downloadBlock(url, {});
}
if (fileBuffer) {
//保存文件
fs.writeFile(fileName, fileBuffer, function (err) {
if (err) throw err;
console.log('Saved.');
});
}
})();
效果图片
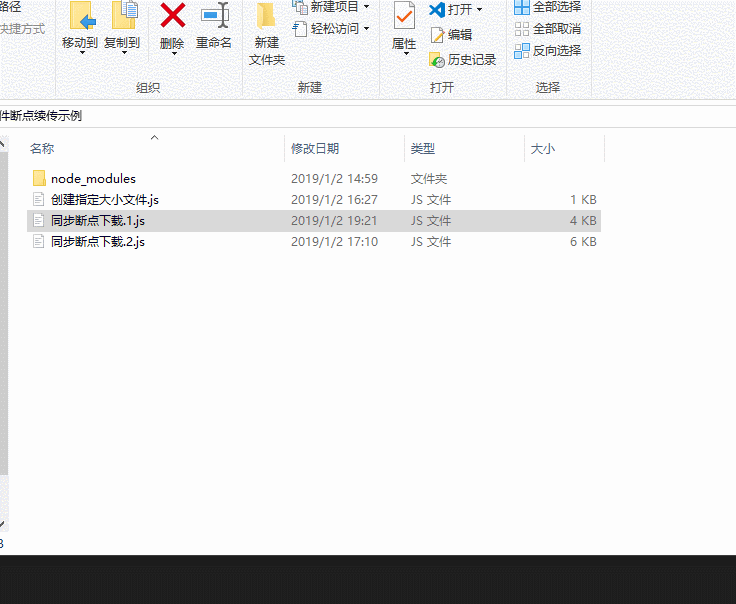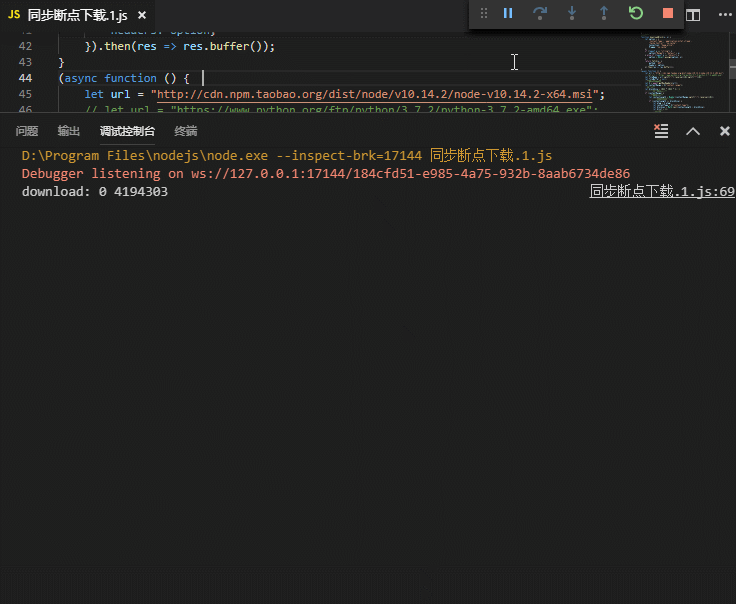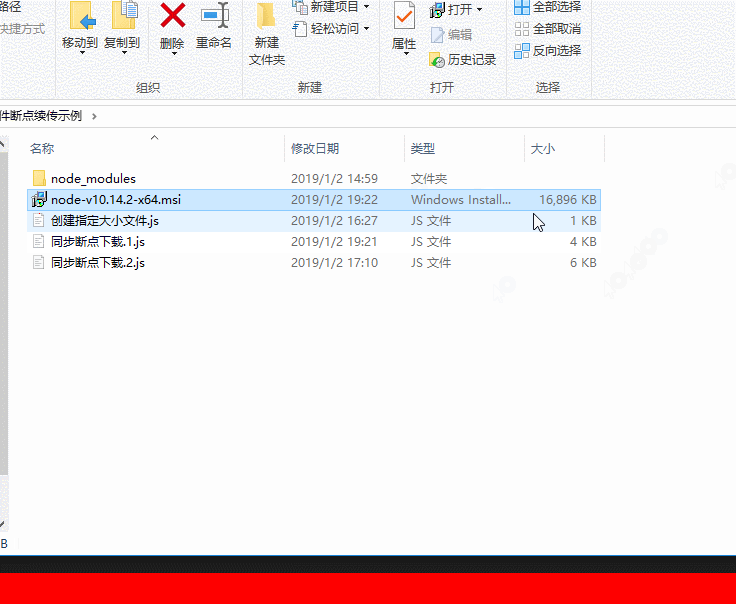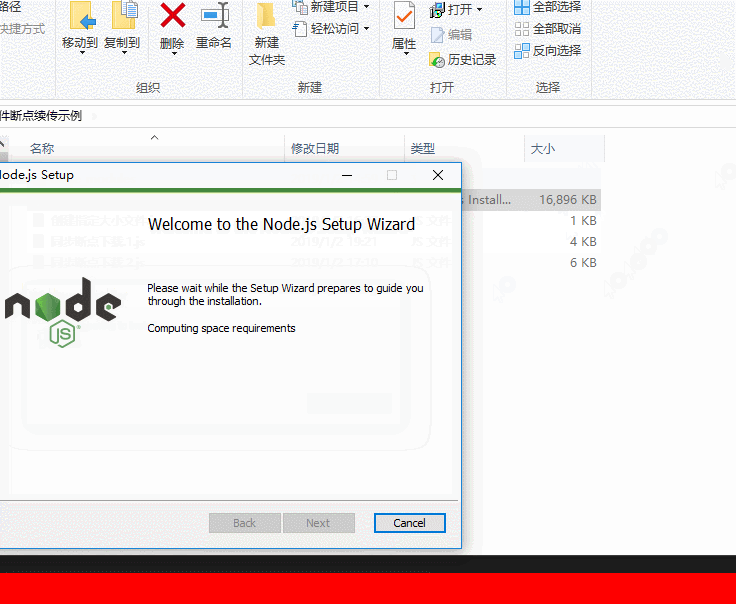
3.实现简单的HTTP文件断点下载功能
实现了上面的分块请求下载数据后,接下去只要稍微修改下就行了。
修改的话就是将请求的信息记录下来,在中断后重新读取记录,然后从记录点开始请求数据,并且将数据追加到文件中就行了。
const fetch = require("node-fetch");
const fs = require('fs'); // 引入fs模块
function readJSON(p) { return JSON.parse(fs.readFileSync(p)); };//读取json
function writeJSON(p, d) { fs.writeFileSync(p, JSON.stringify(d)); };//保存json
//读取响应头
function getResHeaders(u) {
return new Promise(function (resolve, reject) {
fetch(u, {
method: "GET", //请求方式
// mode: 'cors',
headers: { //请求头
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Cache-Control": "no-cache",
Connection: "keep-alive",
Pragma: "no-cache",
Range: "bytes=0-1"
}
}).then(r => {
let h = {};
r.headers.forEach(function (v, i, a) {
h[i.toLowerCase()] = v;
})
return resolve(h);
}).catch(reject);
});
}
//下载块
function downloadBlock(u, o) {
let option = {
'Content-Type': 'application/octet-stream',
"Cache-Control": "no-cache",
Connection: "keep-alive",
Pragma: "no-cache"
};
if (typeof o == "string") {
option["Range"] = "bytes=" + o;
} else if (typeof o == "object") {
option = Object.assign(option, o);
}
return fetch(u, {
method: 'GET',
headers: option,
}).then(res => res.buffer());
}
//切割大小
function cutSize(contentLength, blockSize) {
//向后取整
let blockLen = Math.ceil(contentLength / blockSize);
let blist = [];
for (let i = 0, strat, end; i < blockLen; i++) {
strat = i * blockSize;
end = (i + 1) * blockSize - 1;
end = end > contentLength ? contentLength : end;
blist.push({ strat: strat, end: end });
}
return blist;
}
(async function () {
// let url = "http://cdn.npm.taobao.org/dist/node/v10.14.2/node-v10.14.2-x64.msi";
let url = "https://dldir1.qq.com/qqfile/qq/QQ9.0.8/24209/QQ9.0.8.24209.exe";
// let url = "https://www.python.org/ftp/python/3.7.2/python-3.7.2-amd64.exe";
let fileName = url.split("/").reverse()[0].split("?")[0];
//获取请求头信息
let h = await getResHeaders(url);
let contentRange = h["content-range"];
//分块大小
let blockSize = 1024 * 1024 * 4;//b
let etag = h.etag || null;
//记录文件当前下载状态的文件
let logFileName = fileName + ".info";//这个可自定义
let logContent;
//如果日志文件存在
if (fs.existsSync(logFileName)) {
//读取数据
logContent = readJSON(logFileName);
//比较etag来判断文件是否发生变动
if (etag != logContent.etag) {
logContent = null;
}
}
//判断是否支持分段下载
if (contentRange) {
if (!logContent) {
//获取文件大小
let contentLength = Number(contentRange.split("/").reverse()[0]);
//判断是否后需要分块下载
if (contentLength >= blockSize) {
let contentType = h["content-type"];
//计算分块
let blist = cutSize(contentLength, blockSize);
//日志记录内容根据需要添加
logContent = {
url: url,
etag: etag,
fileName: fileName,
contentLength: contentLength,
contentType: contentType,
blocks: blist,
pointer: 0
};
//创建记录文件
writeJSON(logFileName, logContent);
} else {
contentRange = false;
}
}
if (logContent) {
//遍历并下载
for (let i = logContent.pointer; i < logContent.blocks.length; i++) {
let block = logContent.blocks[i];
let b = await downloadBlock(url, {
etag: logContent.etag,
'Content-Type': logContent.contentType,
"Range": "bytes=" + block.strat + "-" + block.end
});
//追加内容
fs.appendFileSync(logContent.fileName, b);
//记录日志
logContent.pointer++;
console.log(logContent.fileName, logContent.pointer / logContent.blocks.length * 100 + "%");
writeJSON(logFileName, logContent);
}
//如果需要删除日志文件的话
// fs.unlink(logFileName, function(err){});
}
} else {
contentRange = false;
}
//使用 contentRange = false 来标识 直接下载
if (contentRange == false) {
//直接下载
let fileBuffer = await downloadBlock(url, {});
//保存文件
fs.writeFile(fileName, fileBuffer, function (err) {
if (err) throw err;
console.log('Saved.');
});
}
})();
4.关于多线程下载
既然针对单个文件的断点续传功能已经实现了,那么多线程下载也不难,当然多线程下载一般有两种方式,一种指的是单文件多线程下载(也就是下载单个文件多个分块使用多线程的方式下载),另外一种是多文件多线程下载。这里的话我就不详细说明了,如果需要了解,可以在文章下留言。ヾ(◍°∇°◍)ノ゙
转自:https://www.jianshu.com/p/934d3e8d371e
关于断下续传,分片下载等,可以参考下面的文章
2:https://jelly.jd.com/article/5e734631affa8301490877f1
3:https://juejin.cn/post/6855638966243835912
4:https://segmentfault.com/a/1190000023434864

 浙公网安备 33010602011771号
浙公网安备 33010602011771号