


Elements里的结构如下,需要拿到text文案,首先要拿到tr的循环列表,然后取出每一个tr里的第二个td,再去定位文案
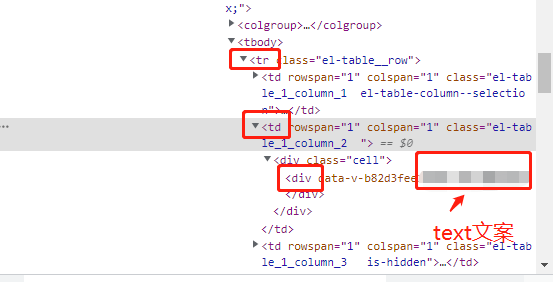
//先定位到tr的上一步 WebElement name = driver.findElement(By.xpath("//xxxx//tbody")); //根据标签名称tr获取到tr的列表 List<WebElement> names = name.findElements(By.tagName("tr")); //循环每一个tr for(WebElement name1 : names) { //拿到每一个tr里的td列表 List<WebElement>na=name1.findElements(By.tagName("td")); //这一步实验了很多方法,不用定位到td后再去想办法定位div,直接从td去获取text即可 String message = na.get(1).getText(); //试验后,确实可以获取到text,但是有问题,只能获取到当前页面显示的td的文案,被页面遮挡需要滑动鼠标才能显示的数据的文案获取不到 System.out.println(message); }
