k8s 网络之flannel
为什么要学习k8s网络?
k8s网络是k8s中比较复杂的知识,设计到的知识范围比较广,需要对网络有一定的知识积累才能更好的掌握,如果我们了解了k8s网络通信原理,我相信我们应用k8s的时候会更加的得心应手,对k8s的理解也会更加深刻。
什么是cni?
cni( Container Network Interface),容器网络接口,k8s容器间通信技术细节本身并未实现,而是定义了容器间网络通信的标准,这样各厂商根据协议规范可以灵活实现自己的cni,k8s是一个扁平的网络,各pod使用自己的IP地址直接通信,而无需nat,常见的 CNI 插件包括flannel、 Calico、Cilium等。
flannel 是coreOs实现的cni,它将已有的物理网络(Underlay网络)作为基础,在其上建立叠加的逻辑网络,Overlay网络有一定额外的封包和解包等网络开销,支持vxlan、ipip、udp等封装方式,特点是简单、无需太多的额外配置,但功能也比较基础、不支持网络策略等,适合小型集群。
Calico是一个纯三层的方案,基于 Etcd 维护网络准确性,它基于BPG 协议和Linux自身的路由转发机制,不依赖特殊硬件,容器通信也不依赖iptables NAT或Tunnel 等技术,性能很好,支持丰富的特性。
Cilium基于eBPF技术开发,是一个比价新的方案,也主要是纯三层的方案,注重网络安全, 提供了基于 service/pod/container 作为标识,而非传统的 IP 地址,来定义和加强容器和 Pod 之间网络层、应用层的安全策略。
市面上cni种类非常的多,使用的技术也都大同小异,无非是专攻于某个技术点,在其上进行了一些优化,上面列举了比较具有代表性的三种,本文也将采用flannel来分析下pod之间的通信流程。
一些名词概念:
1.网桥:linux上类似交换机交换功能的一种软件实现方式,上面有很多虚拟的接口,关联到接口上的设备彼此之间可以通信,可以利用brctl命令进行管理
2.命名空间(Linux namespace)是linux内核针对实现虚拟化引入的一个特性。创建的每个进程都有自己的命名空间,运行在其中的进程都像是在独立的操作系统中运行一样,命名空间保证了进程之间互不影响。可用ip netns命令进行管理。
3.veth pair:veth pair是成对出现的一种虚拟网络设备接口,一端连着网络协议栈,一端彼此相连,从一端发出的数据可以从另一端收到,相当与网线的功能,可用 ip link add <veth name> type veth peer name <peer name>进行添加,可用veth pair连接两个不同网络名称空间,实现两个空间之间的通讯。
4.VXLAN,Virtual Extensible LAN,顾名思义,是VLAN的扩展版本。VXLAN技术主要用来增强在云计算环境下网络的扩展能力。VXLAN使用UDP报文将Ethernet报文封装起来,从而实现跨IP的数据传输,其使用的UDP端口号为4789。VXLAN的端设备称为VTEP,负责VXLAN报文的封装与解封装。提供了跨三层的二层联通能力,通俗讲就是二层隧道
5.IP隧道技术:是路由器把一种网络层协议封装到另一个协议中以跨过网络传送到另一个路由器的处理过程。隧道技术是一种数据包封装技术,它是将原始IP包(其报头包含原始发送者和最终目的地)封装在另一个数据包(称为封装的IP包)的数据净荷中进行传输。
6.tap/tun设备:tap/tun 有些许的不同,tun 只操作三层的 IP包,tun是PPP点对点设备,没有MAC地址,其封装的外层是IP头。而 tap 操作二层的以太网帧,封装的外层是以太网帧(frame)头。tap/tun 设备文件就像一个管道,一端连接着用户空间,一端连接着内核空间。当用户程序向文件 /dev/net/tun 或/dev/tap0 写数据时,内核就可以从对应的 tunX 或 tapX 接口读到数据,反之,内核可以通过相反的方式向用户程序发送数据,tap/tun 是 Linux 内核 2.4.x 版本之后实现的虚拟网络设备,不同于物理网卡靠硬件板卡实现,tap/tun 虚拟网卡完全由软件实现,功能和硬件实现完全没差别,它们都属于网络设备,都可配置 IP,都归 Linux 网络设备管理模块统一管理。
实验环境:
host1:192.168.0.200
host2:192.168.0.201
ipip模式
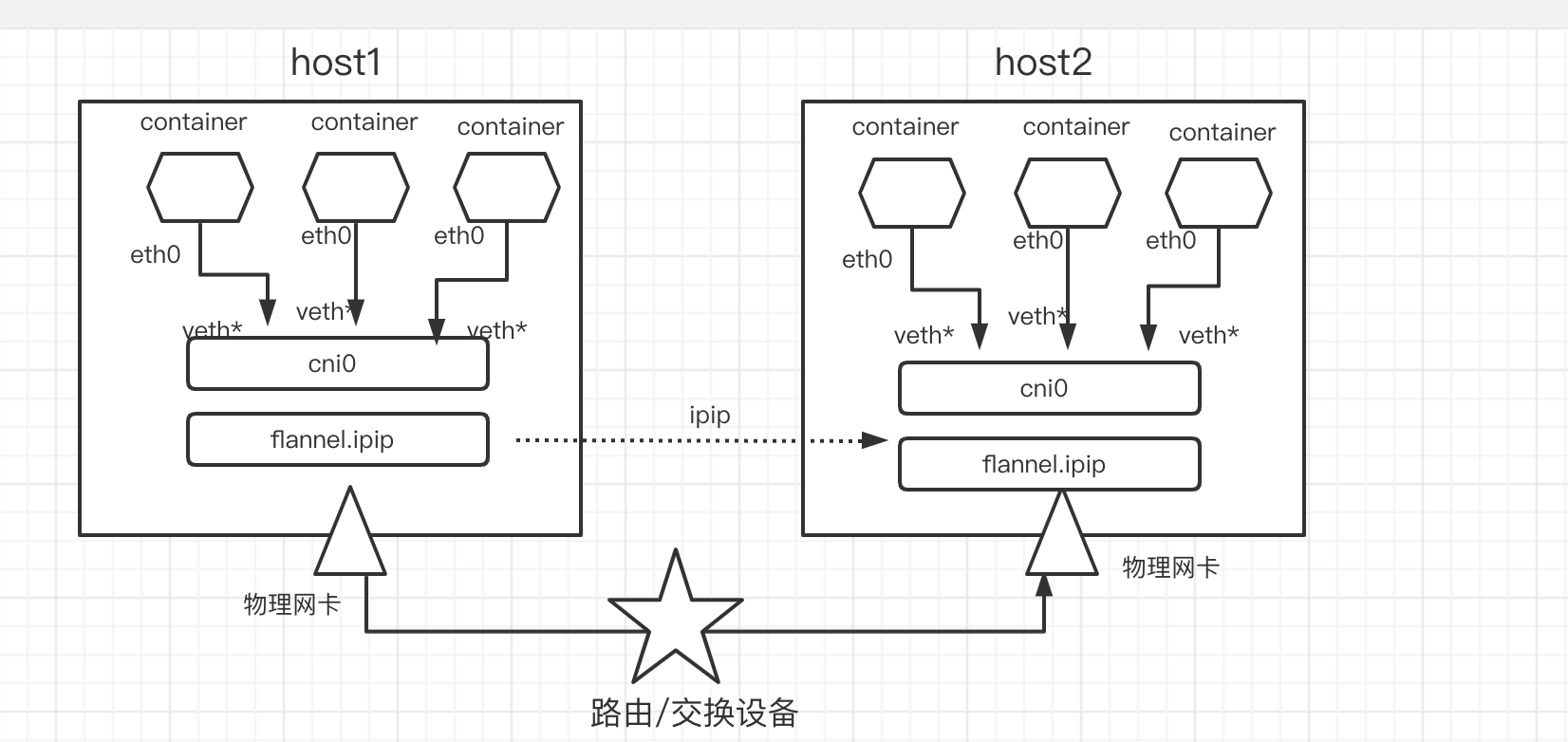
用ipip手动实现跨主机docker通信:
host1:
modprobe ipip #加载ipip模块 lsmod|grep ipip #确认模块加载成功 docker run --name c1 -td dufeixiang/nettool docker exec -it c1 ip a #得到容器ip为172.30.0.2 |
host2:
modprobe ipip #加载ipip模块 lsmod|grep ipip #确认模块加载成功 docker network create test docker run --name c2 -td --network test dufeixiang/nettool docker exec -it c2 ip a #得到容器ip为172.17.0.2 |
在c1 中ping c2,确认两容器之间不能通讯。
创建ipip隧道,并配置路由,使两个主机上的docker可以通信
host1:
ip tunnel add ipip mode ipip remote 192.168.0.201 local 192.168.0.200 ip link set ipip up ip add add dev ipip 172.30.0.0/32 ip route add 172.17.0.0/16 via 192.168.0.201 dev ipip onlink |
host2:
ip tunnel add ipip mode ipip remote 192.168.0.200 local 192.168.0.201 ip link set ipip up ip add add dev ipip 172.17.0.0/32 route del -net 172.30.0.0/16 #删除默认路由 ip link set docker0 down #禁用docker0,防止路由冲突,影响与host1通信 ip route add 172.30.0.0/16 via 192.168.0.200 dev ipip onlink |
c1 ping c2 通信正常
c2 ping c2 通信正常
flannel ipip模式通信原理:
配置flannel backend 为ipip
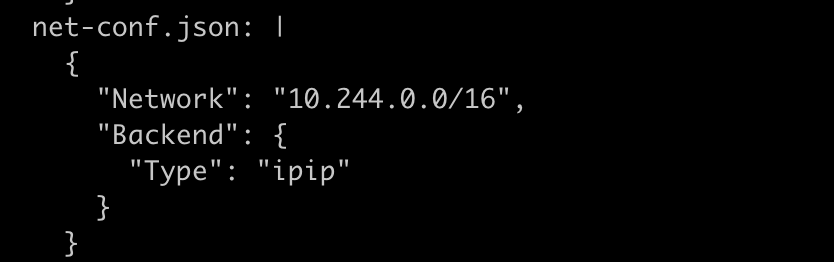

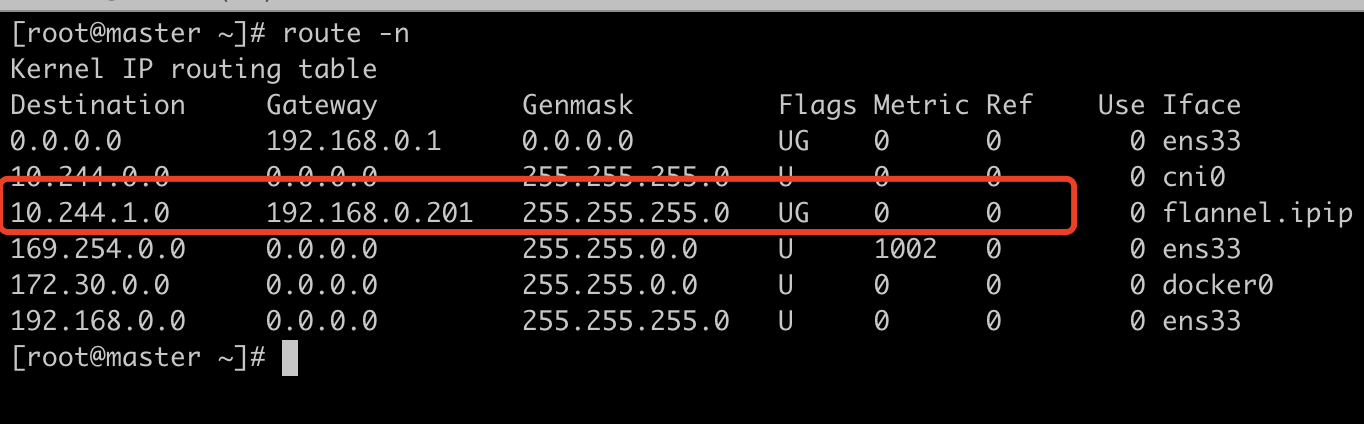
用10.244.0.6 ping 10.244.1.13(分析pod跨主机通信流程)
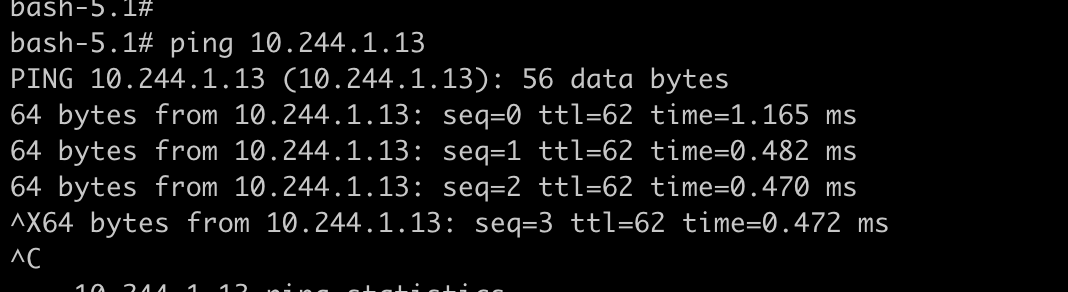
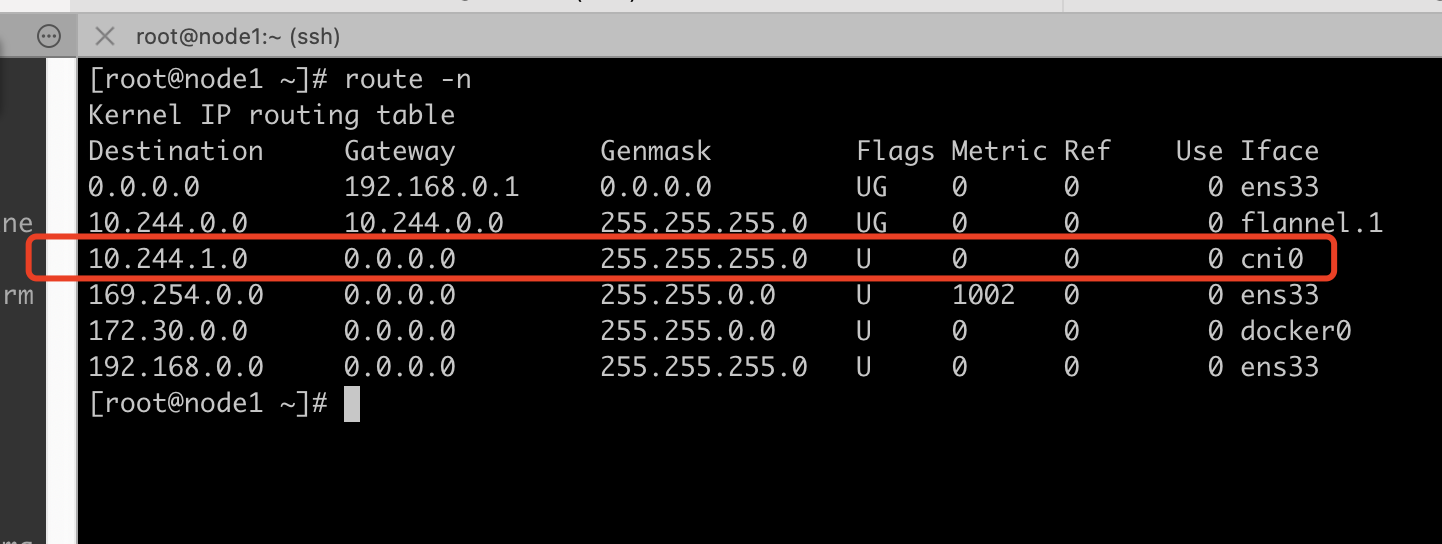
根据eth0的路由表可以看出,所有非本网段的包都会发往网关10.244.0.1,也就是物理机的cni0

查看10.244.0.6 eth0 的对端关联到哪个位置,下面获取eth0的index:ethtool -S eth0
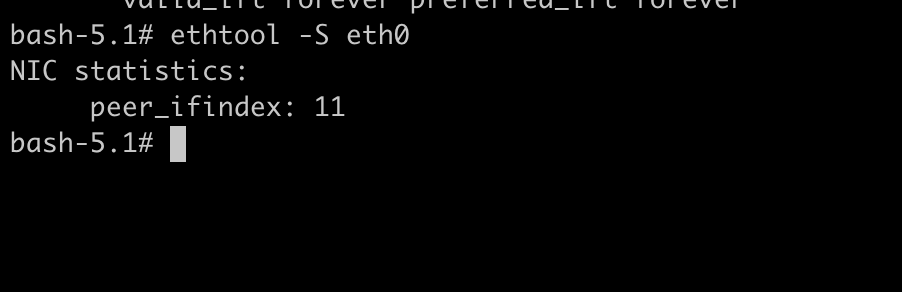
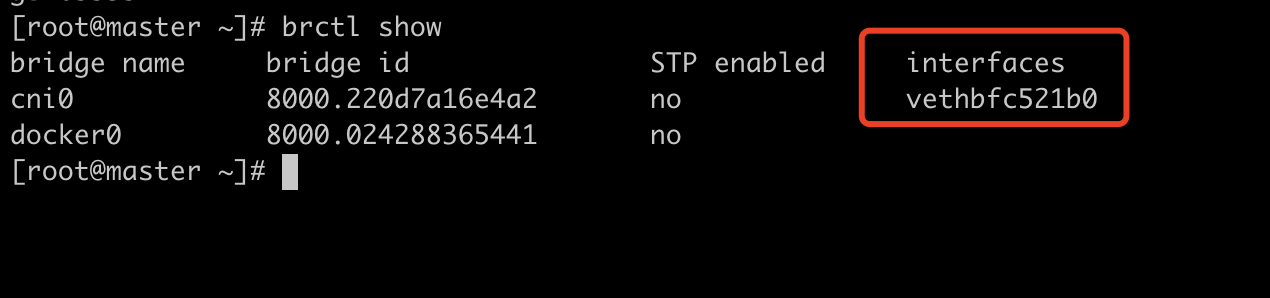
根据index 11,获取到另外一端在宿主机上的名称为:vethbfc521b0

查看vethbfc521b0的类型为veth,符合我们的预期,一头关联到容器,一头关联到cni网桥
数据包到达cni0后,会查找主机的路由表,可以看出发往10.244.1.0的包应该从名为flannel.ipip的接口发出去,flannel.ipip收到包后会进行ipip封装,并由外层网卡ens33发往下一跳192.168.0.201
下面开始在host2(192.168.0.20.1上分析)
在host2 ens33(物理网卡)抓包
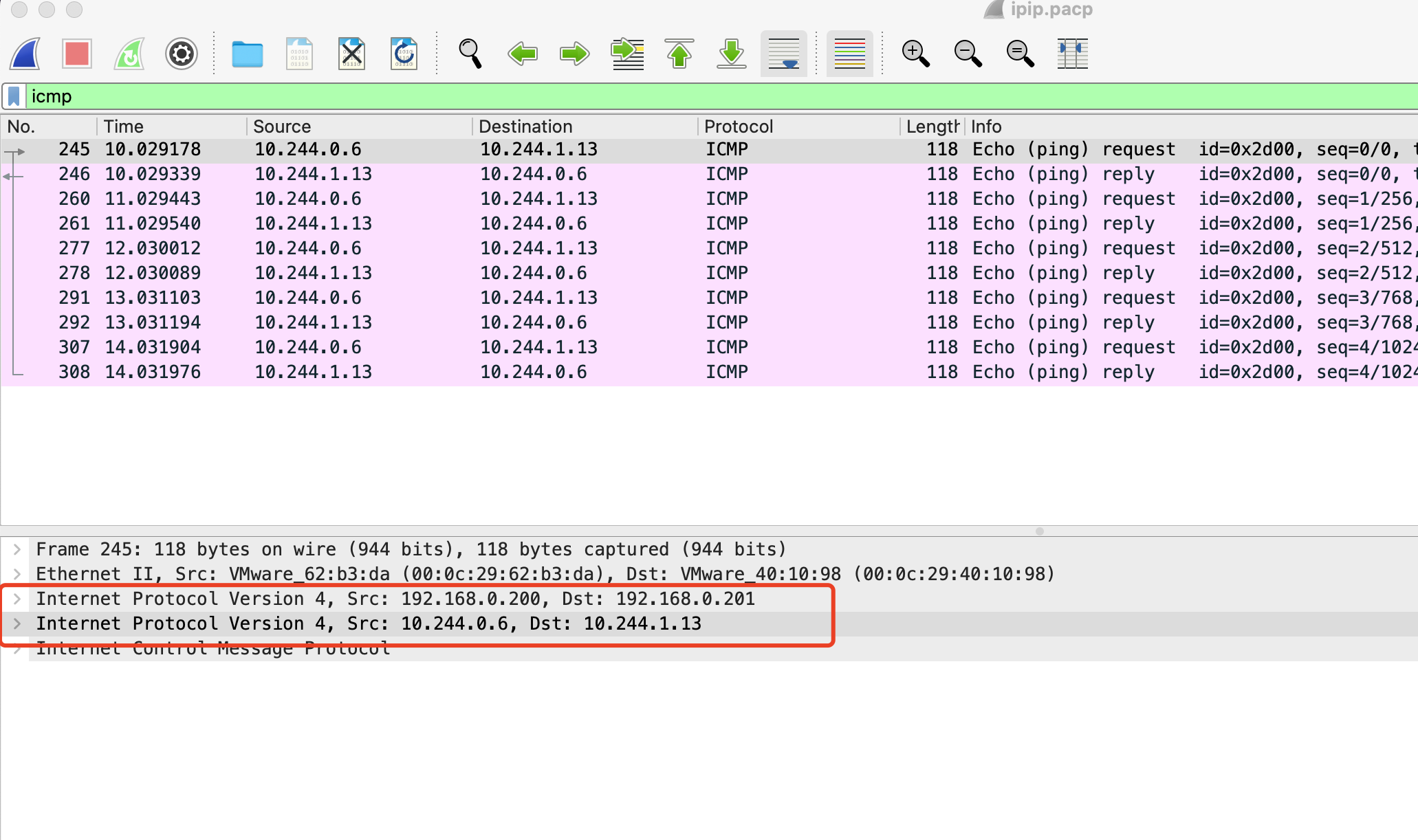
确认使用了ipip隧道封装,因为有两层ip头,最外层为主机通信包头,里层是RAW DATA,没有mac地址,ens33收到数据包后内核tcp协议栈解包得到里层的ip包头,于是开始接着处理src:10.244.0.6 ——————》 dst 10.244.1.13
看看主机路由表得知发往目的10.244.1.0网段的发往cni0接口
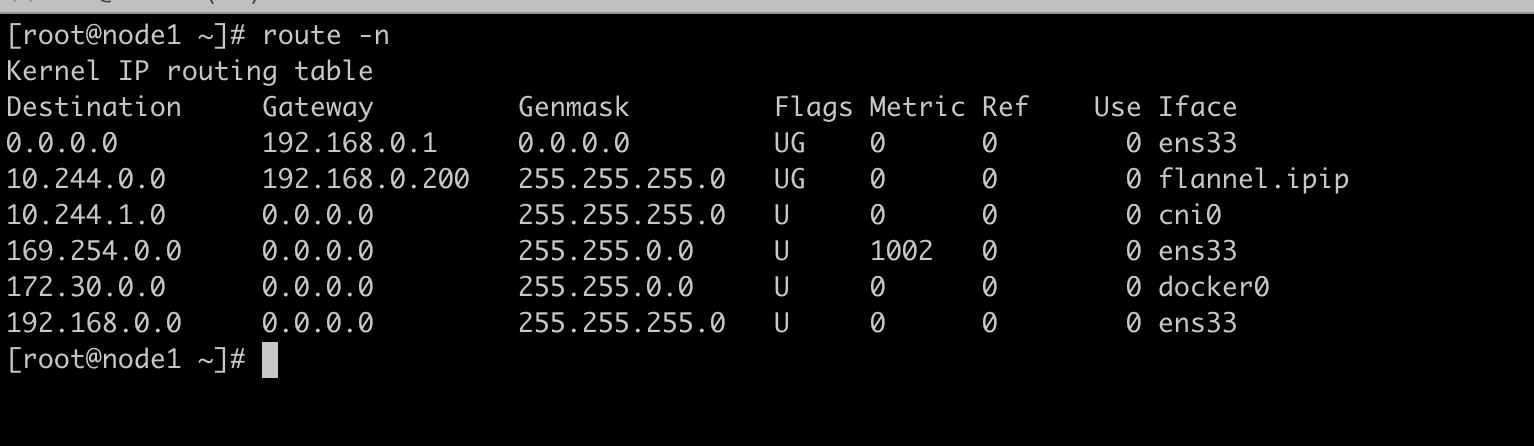
cni0收到包后会请求目的为10.244.1.13的mac地址,然后cni0根据mac 从对应的接口发出去,brctl showmacs cni0

brctl showstp cni0,从返回结果可以看到6号接口名称为veth64fc1063
ip a|grep -C 10 veth64fc1063 #可以看到对应的接口编号为32

在目标容器内查看veth的另一端在宿主机上的编号,ethtool -S eth0

可以得到在宿主机上的编号确实为32,符合上面的预期,于是icmp包成功接收到
vxlan模式
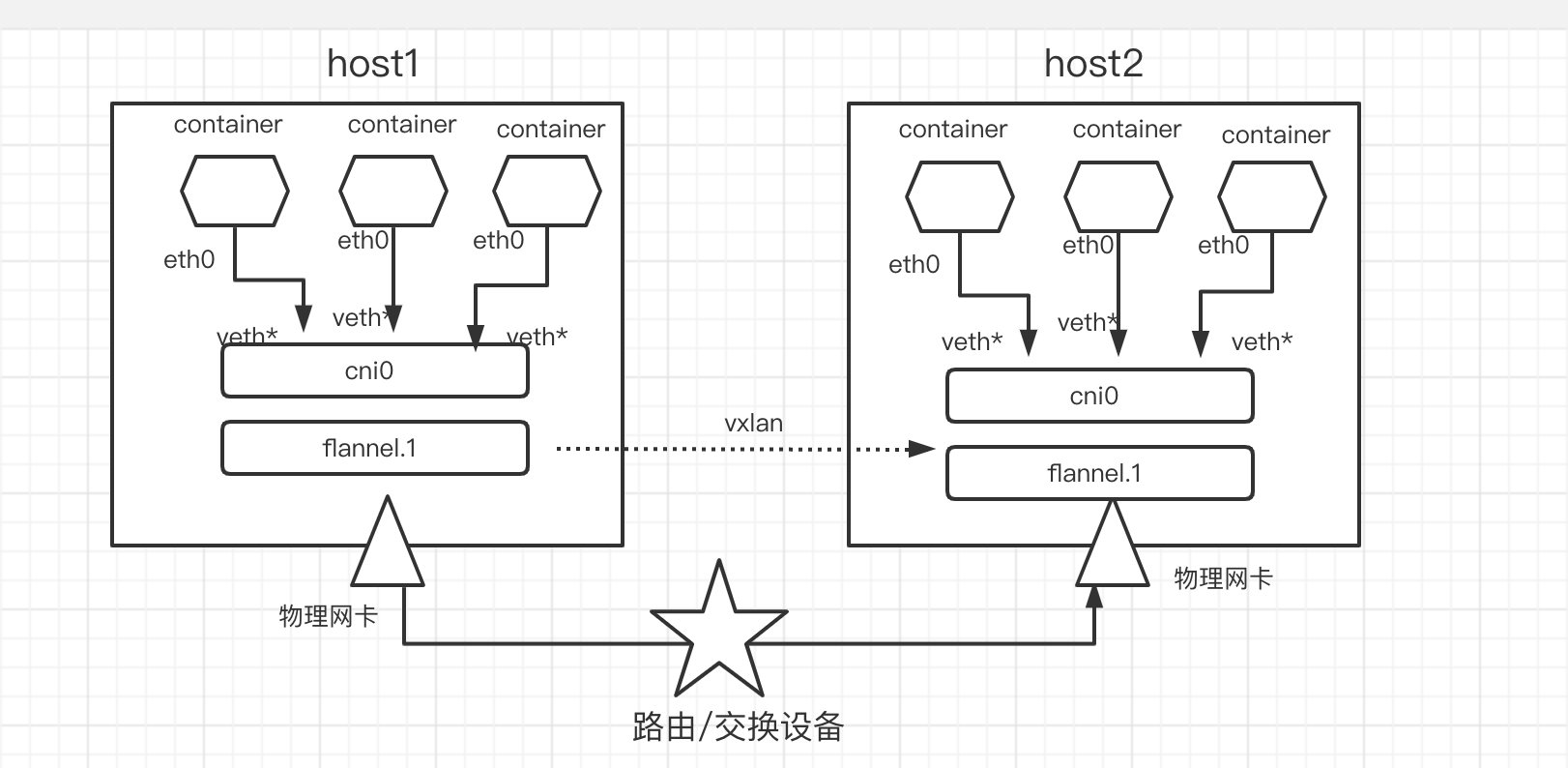
用vxlan手动实现跨主机docker通信:
host1:
docker run --name c1 -td dufeixiang/nettool //该容器的地址为:172.30.0.2 ip link add vxlan type vxlan id 100 remote 192.168.0.201 dstport 4789 dev ens33 ip link set vxlan up brctl addif docker0 vxlan |
host2:
docker run --name c1 -td dufeixiang/nettool //创建两个容器的目的为模拟大二层通信,两个主机网段地址都为172.30.0.0/16,该容器地址为172.30.0.2 docker run --name c2 -td dufeixiang/nettool //该容器地址为:172.30.0.3,用他来与host1上的172.30.0.2来通讯 ip link add vxlan type vxlan id 100 remote 192.168.0.200 dstport 4789 dev ens33 ip link set vxlan up brctl addif docker0 vxlan |
host1上c1 ping 172.30.0.3
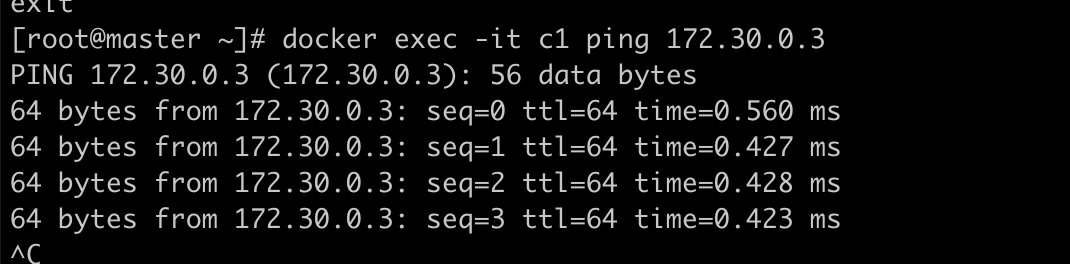
在host2 vxlan接口上抓包,看到用到了vxlan封装了数据包
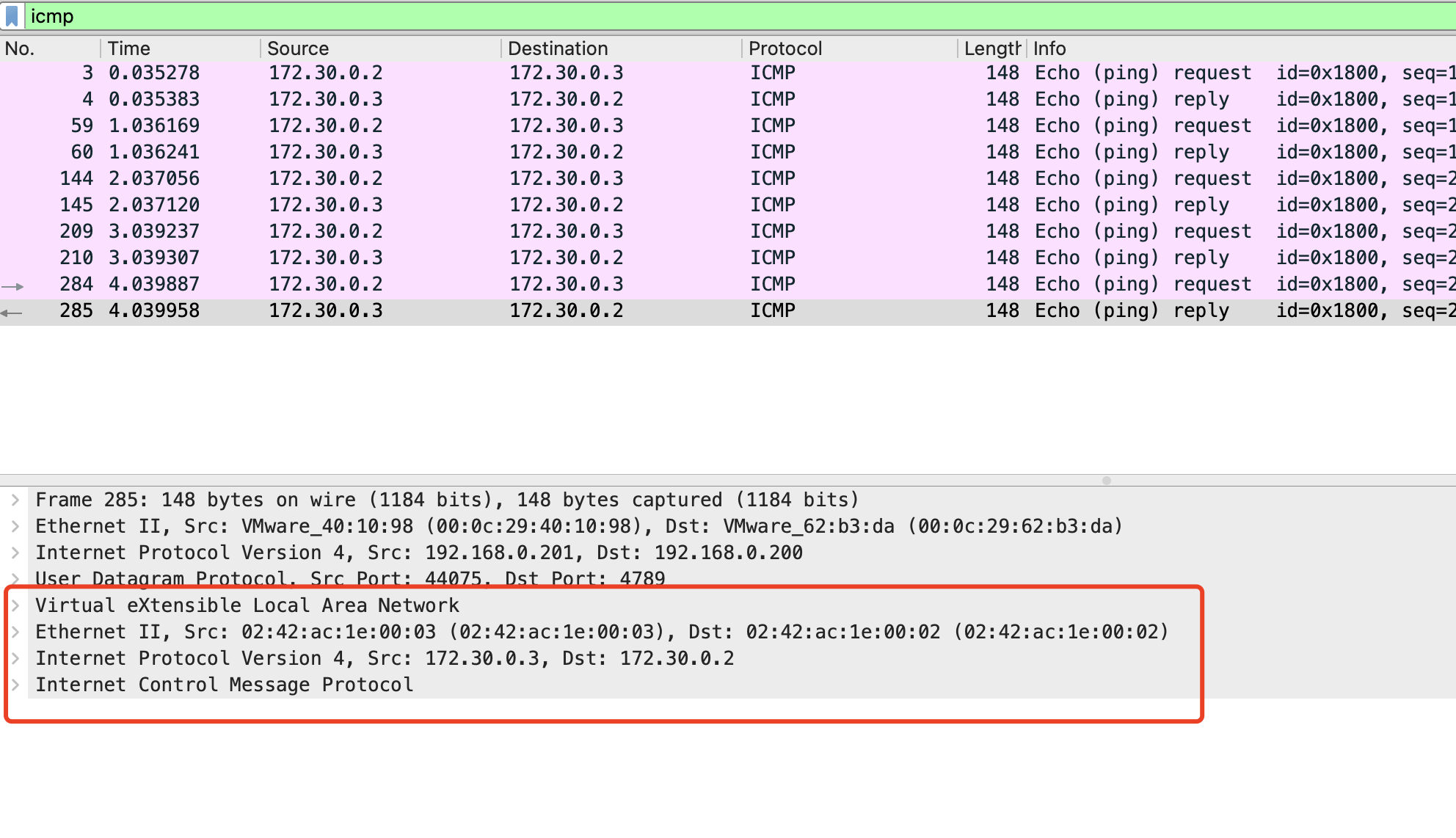
flannel vxlan模式通信原理:
配置flannel backend 为vxlan
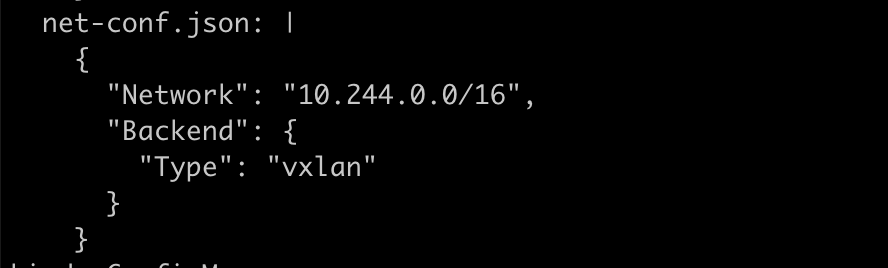

我们用10.244.0.4 去ping10.244.1.9,分析vxlan跨主机通信
查看10.244.0.4 容器路由表,发往10.244.1.9要发往网关10.244.0.1:
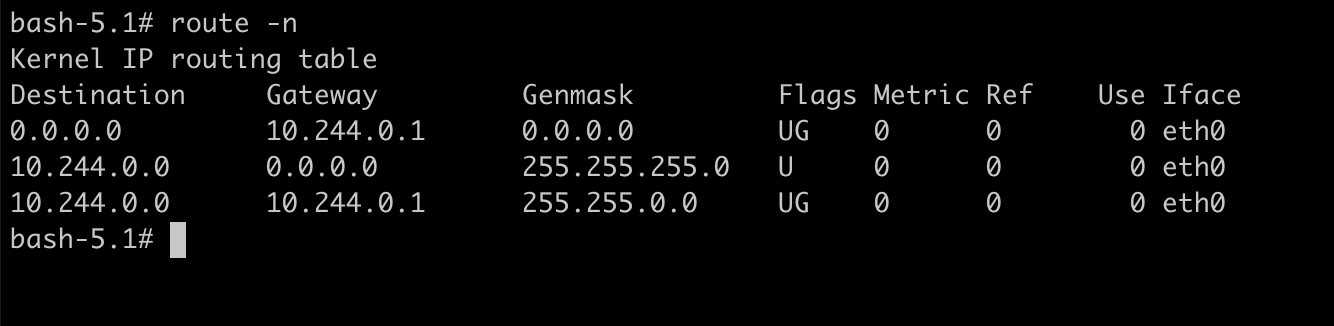
可以看到网关正好是root ns的cni0
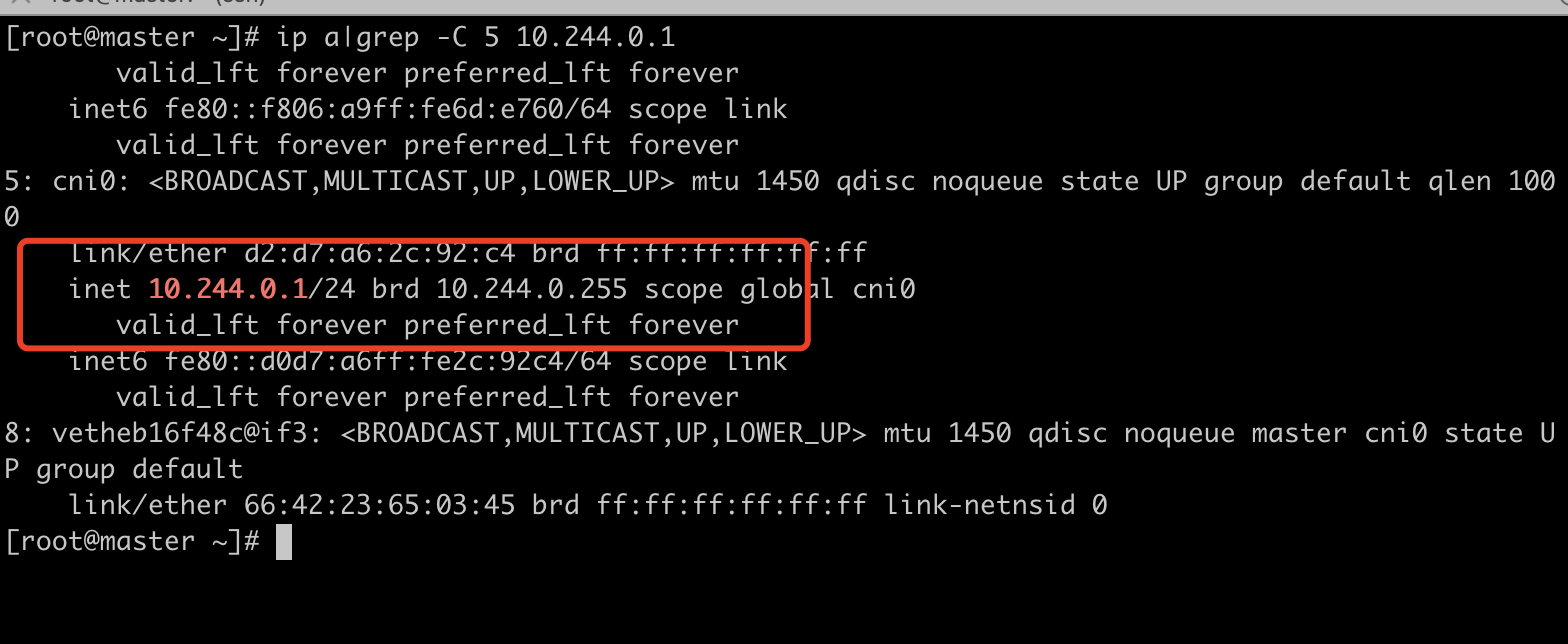
数据包到达cni0后,会查找主机的路由表,可以看出发往10.244.1.0的包应该从名为flannel.1的接口发出去,flannel.1收到包后会进行vxlan封装,并由外层网卡ens33发往下一跳10.244.1.0,而此地址为host2上的flannel.1网卡地址
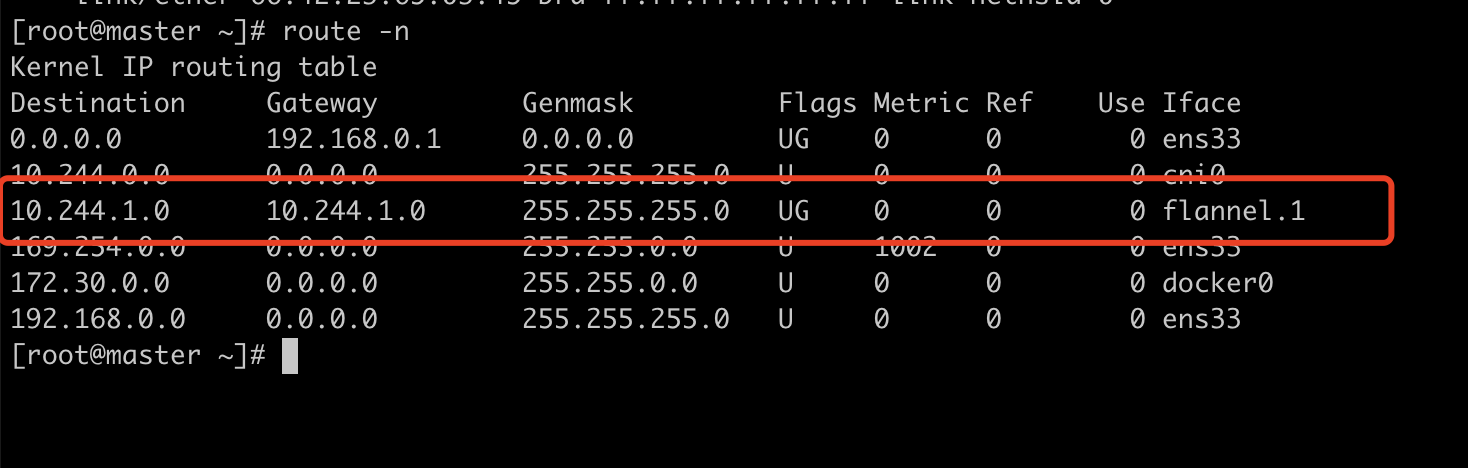
它现在知道它所在宿主机上的外层源ip和源mac。也知道内部的源ip和源mac 和 目的ip和目的mac,但是唯独不知道的是外层ip。也就是说不知道10.244.1.0这个地址下的flannel.1在哪一个节点上。此时他会查询fdb表(在Linux内核里面,网桥设备进行转发的依据来自FDB的转发数据库。这个flannel网桥对应的FDB信息,就是flannel进程维护的。),bridge fdb show
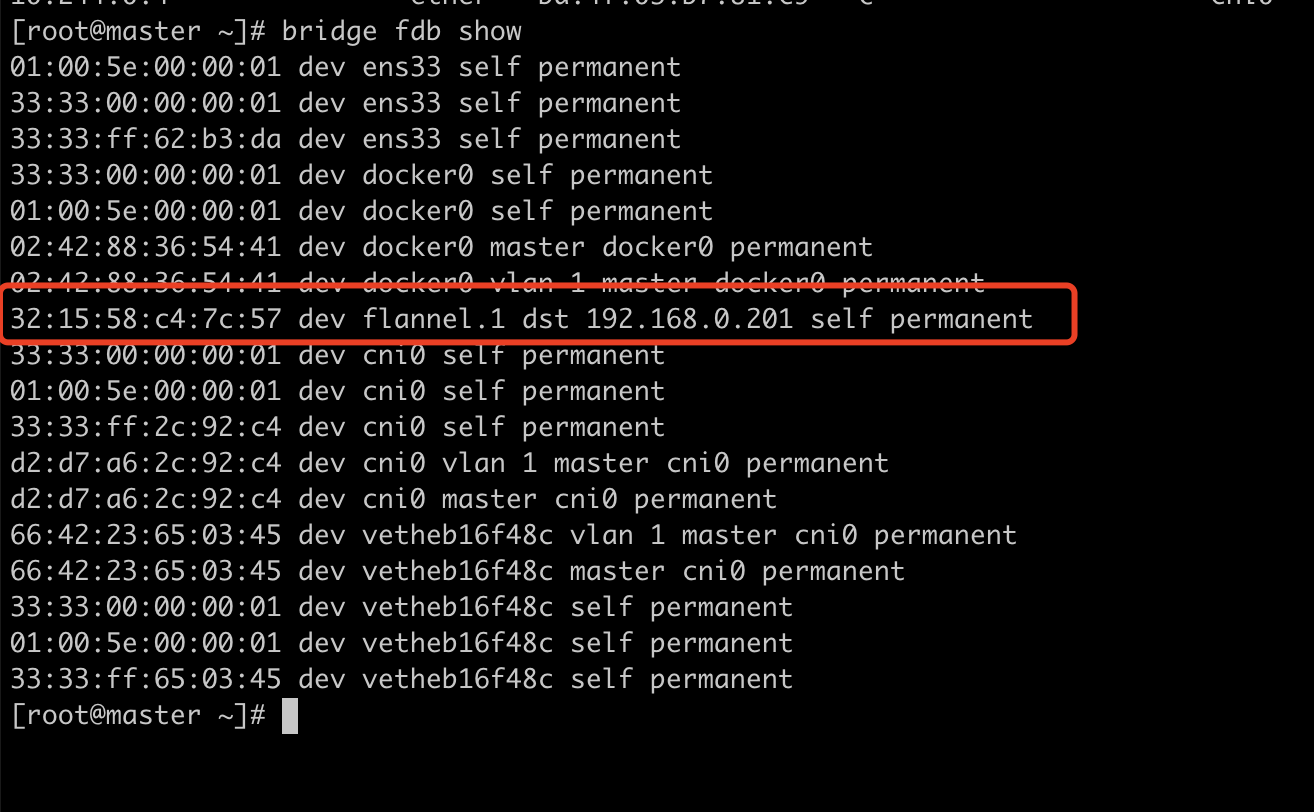
此时我们得到了以下信息用以封装vxlan包
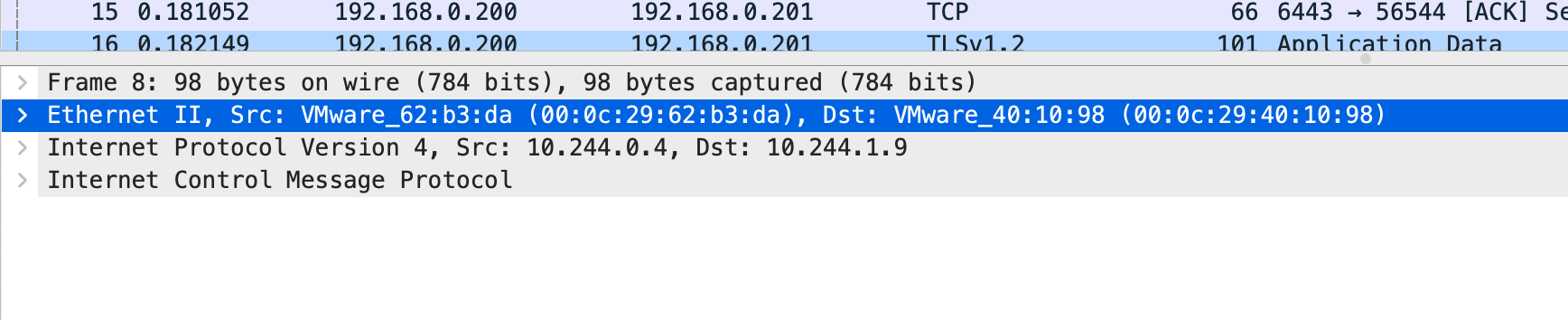
源外层ip: 192.168.0.200 源外层mac: 00:0c:29:62:b3:da (ens33的mac)
源里层ip:10.244.0.4 源里层mac:06:a9:6d:e7:60 (flannel.1 mac)
目的外层ip:192.168.0.201 目的外层mac: 00:0c:29:40:10:98 (192.168.0.201 ens33 mac)
目的里层ip:10.244.1.9 目的里层mac: 32:15:58:c4:7c:57 (192.168.0.201 flannel.1 mac,通过本地fdb转发表得到,是由flannld进程注入)
于是根据以上信息封装ip包发往目的地,我们在host2 的ens33抓包得到标准的vxlan包:

数据包到达host2后解开最外层包,得到最里层的vxlan包,查看本机路由表,发往10.244.1.0网段的包发往本机cni0
cni0网桥查看mac地址表得知要发往3号端口

brctl showstp cni0 可以看到三号接口对应的网卡是vethf755961b

在目标容器执行ethtool -S eth0,得到veth在一端的索引是27
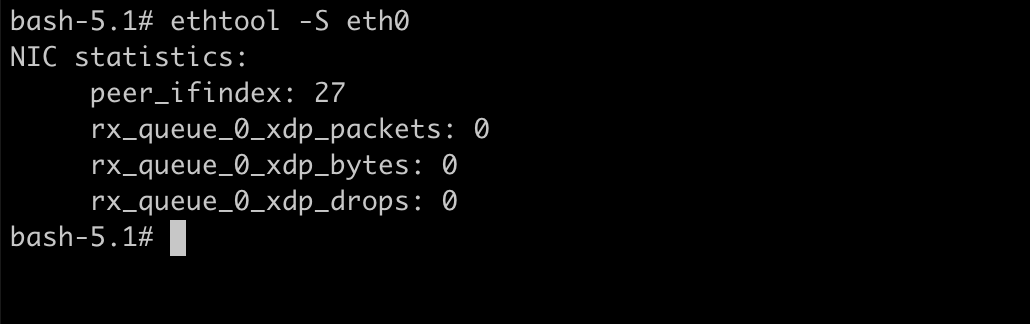
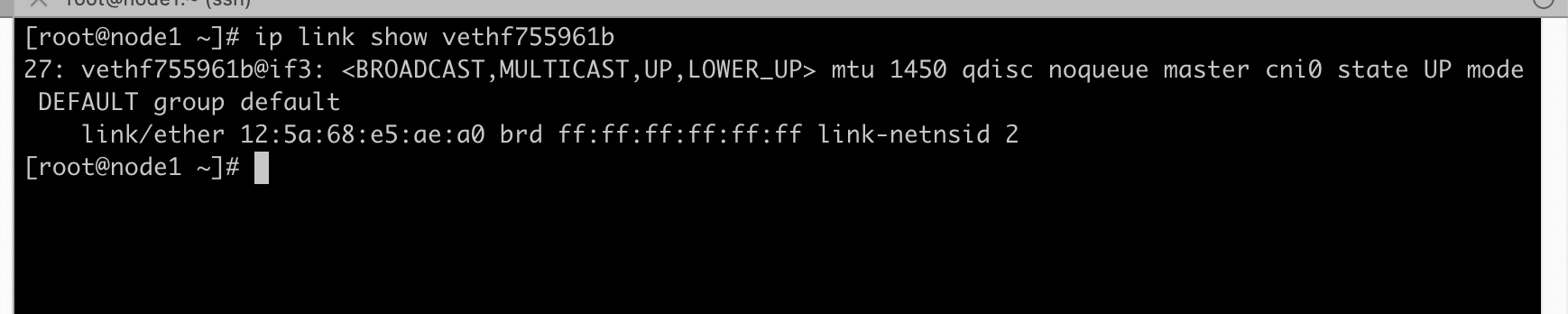
根据上面信息得知目标容器veth 另一端就是vethf755961b,发往vethf755961b的数据会被另一端的目标容器收到
host-gw模式
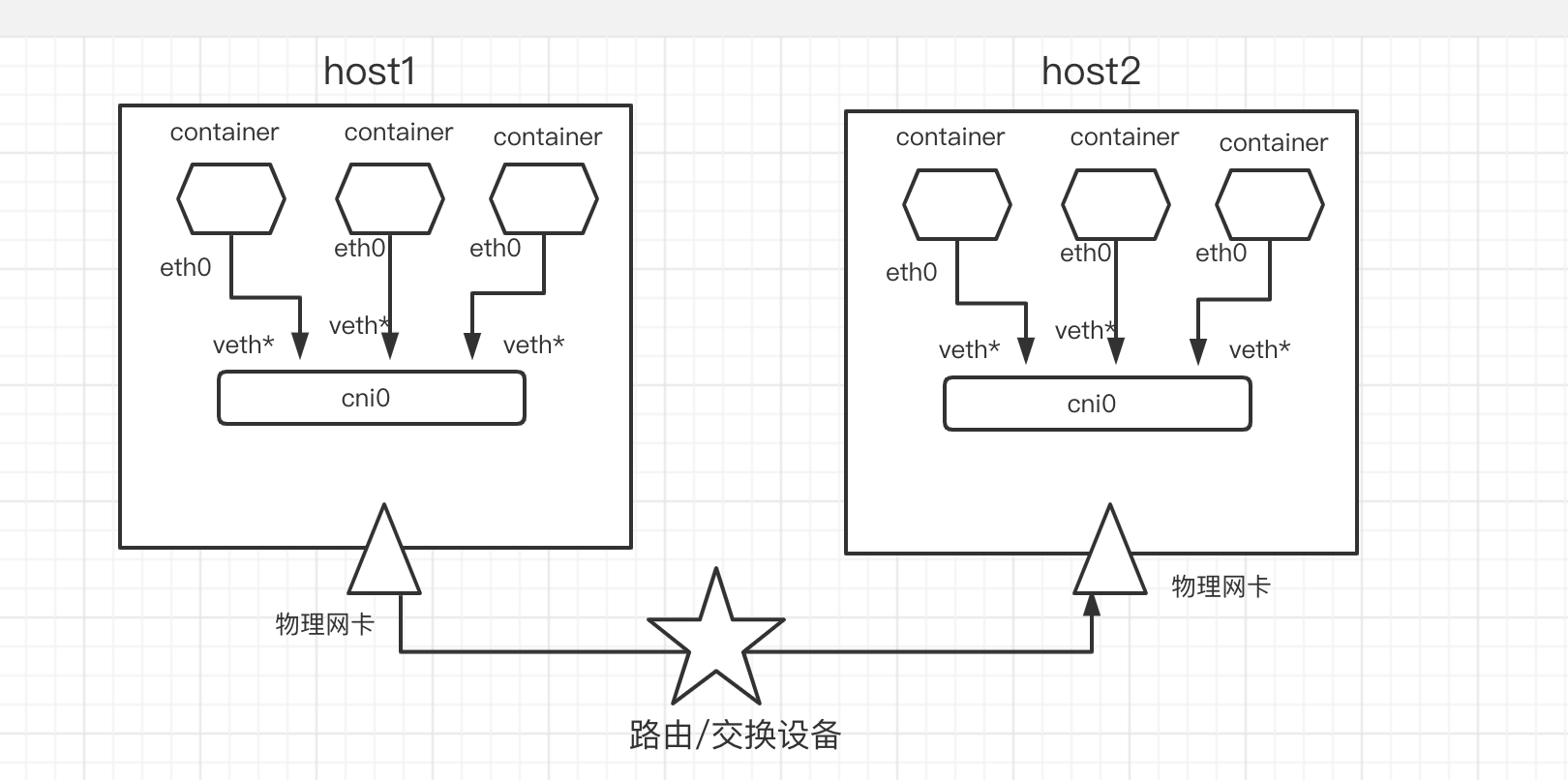
实验环境:
host1:192.168.0.200
host2:192.168.0.201
用主机路由表手动实现跨主机docker 三层通信通信:
host1:
docker run --name c1 -td dufeixiang/nettool docker exec -it c1 ip a #得到容器ip为172.30.0.2 |
host2:
docker network create --subnet 172.20.0.0/16 test docker run --name c1 -td --network test dufeixiang/nettool docker exec -it c2 ip a #得到容器ip为172.20.0.2 |
这时尝试用host1 c1 ping host2 c2,发现是ping不通的
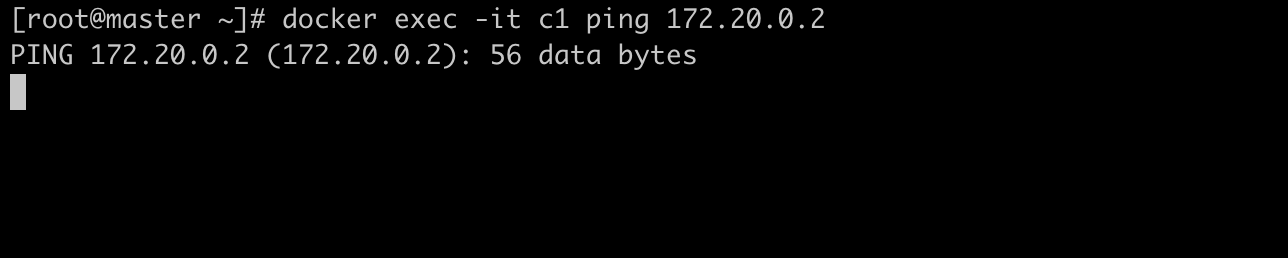
查看host1主机路由表,发现没有可达172.20.0.2的路由
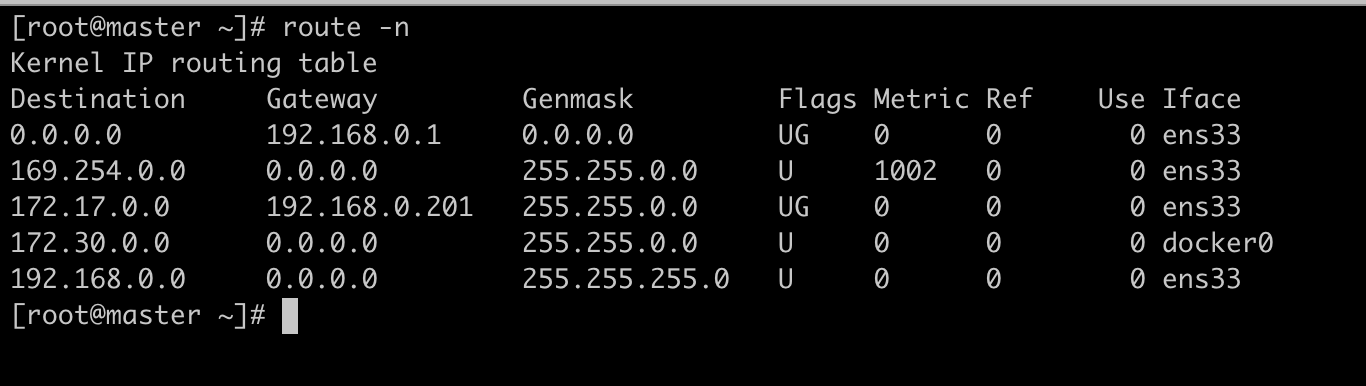
下面我们手动增加一条到达172.20.0.2 的路由:route add -net 172.20.0.0/16 gw 192.168.0.201
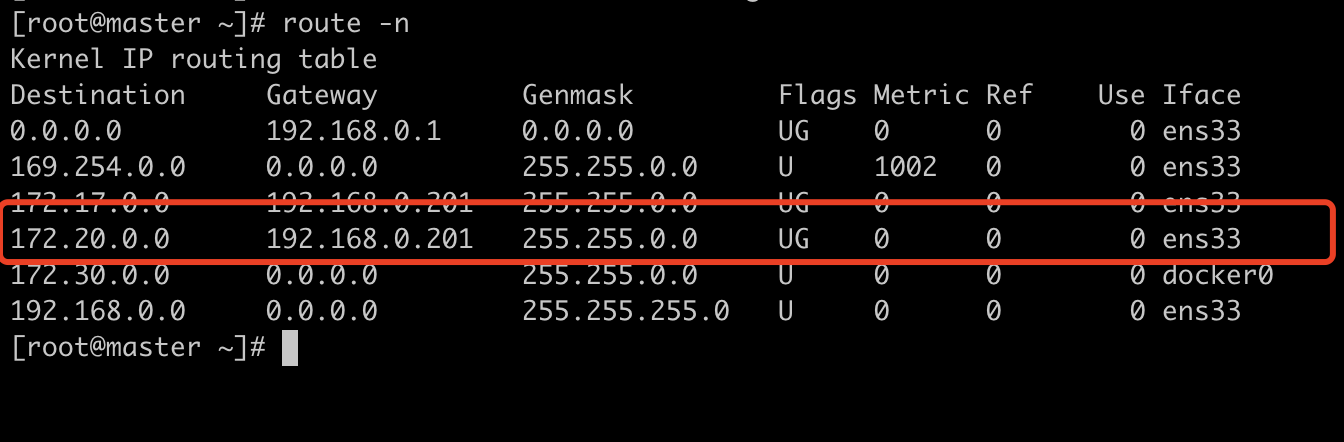
这是我们发现网络已经通了:
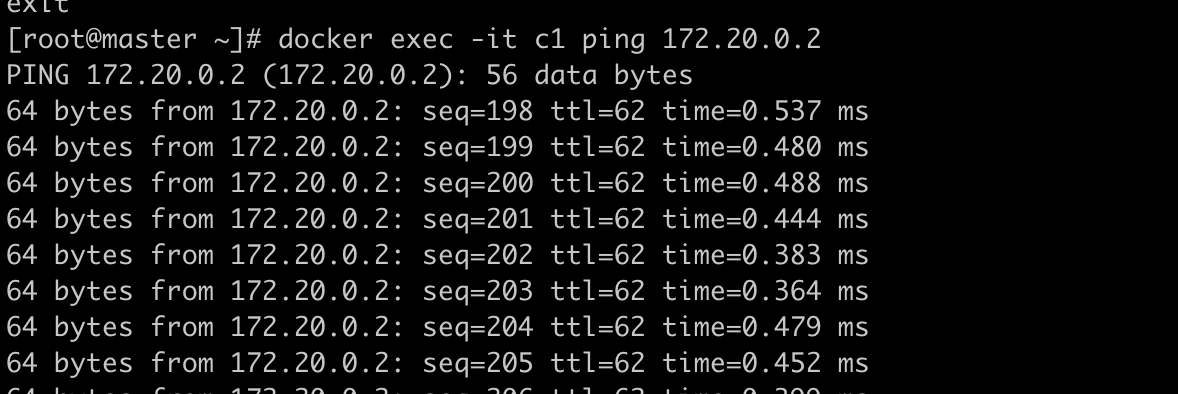
这里肯定有人有疑惑,路由不是要双向的吗?路由有来有回才行,为什么我们只是在源端指目的路由,而没有在目的端写一条回程路由呢?
我们在目的端host2抓包来看
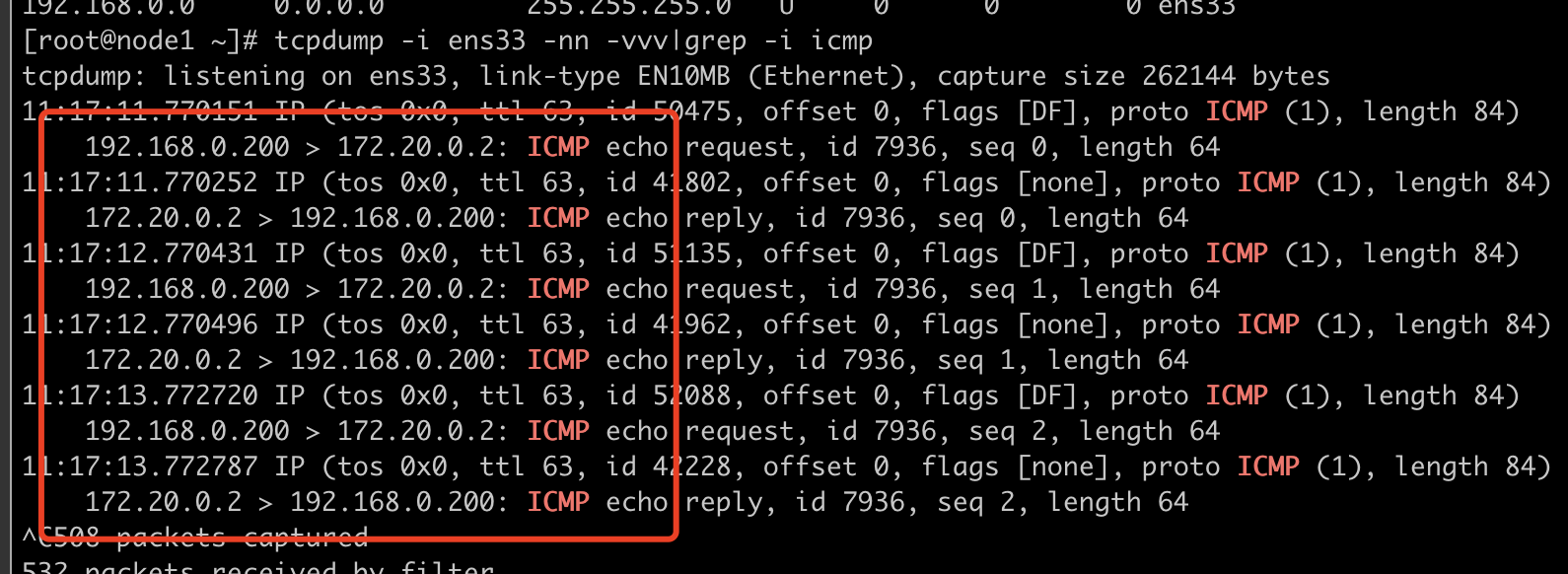
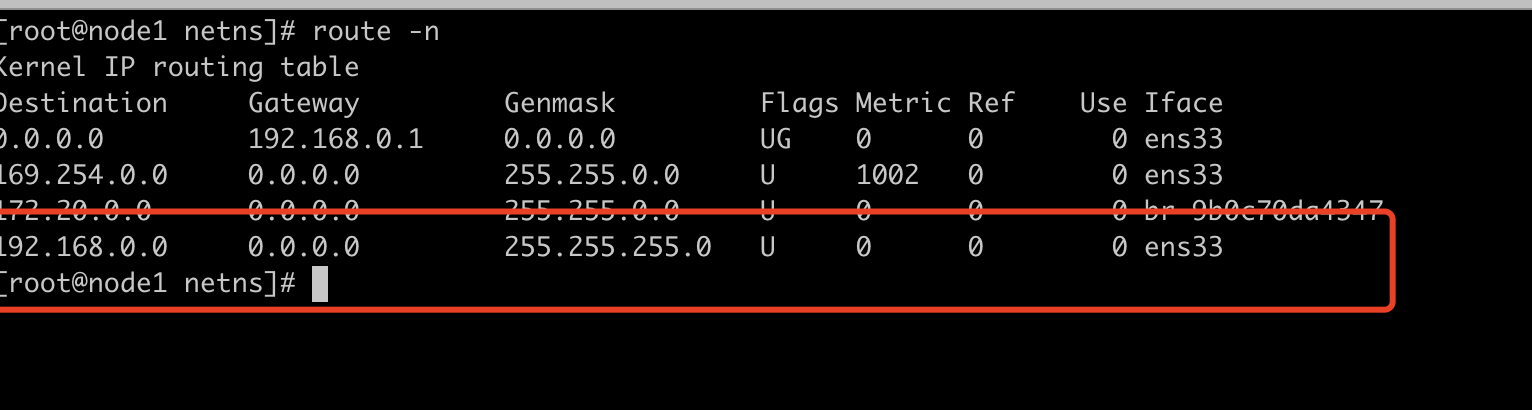
我们在host1 c1容器ping host2 c1容器,也就是172.30.0.1 ping 172.20.0.2,但是抓包为什么是192.168.0.200 ping 172.20.0.2,通过对比来看,我们会发现192.168.0.200 就是host1的出口物理网卡,我们使用的docker network 是brideg,给我们做了出口nat,所以出来的数据包会被转换为物理网卡的外网地址,这也就解释了为什么我们不用在host2上做回程路由链路也会ping通,因为host2 与host1是同一网段,直接走二层交换就行了,host2也就自然有通往host1的路由,我们查看host2的路由表:
我们来看下flannel的 host-gw模式:

我们用10.244.0.4 去ping10.244.1.9,分析host-gw模式跨主机通信

查看10.244.0.4 容器路由表,发往10.244.1.9要发往网关10.244.0.1:
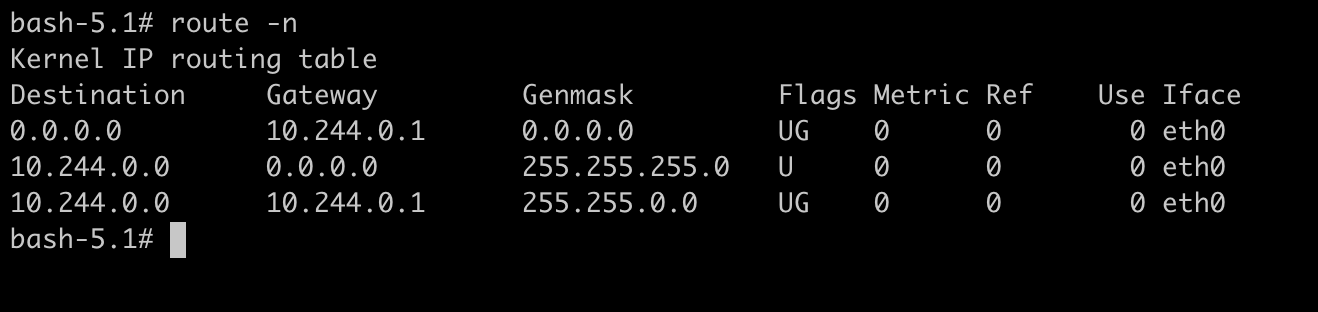
流量进入root namespace,这时候查看主机路由表,发现发往10.244.1.0 的数据发往下一跳192.168.0.201,也就是host2的物理网卡
查看host2 主机路由,发现发往10.244.1.0的流量是一个交换路由,于是将流量发往cni0,在k8s中所有容器都关联到了cni0,所以这时10.244.1.9容器就可以收到数据包了

在host2 ens33上抓包,可以看出host-gw模式跨主机通信走的纯三层转发,没有走overlay封装,所有性能也是最好的
posted on 2022-08-28 19:46 it_man_xiangge 阅读(779) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号