istio 503处理
istio上线一段时间后发现部分高并发的业务会频繁告警503,于是开始排查:
业务架构:
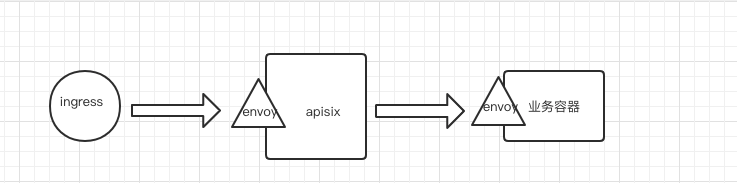
在我们的环境中istio只拦截inbound的流量,不拦截outbound的流量
1.查看apisix 端的envoy日志发现日志中有大量response_code:503 ,response_flags: UC
2.查看业务容器的envoy 日志并未发现503日志,由此猜测是apisix 到业务容器中间链路发生503,请求未到达业务容器
3.在业务容器中tcpdump抓包,发现业务端口大量业务返回的 reset包,waht?业务主动断开了连接?
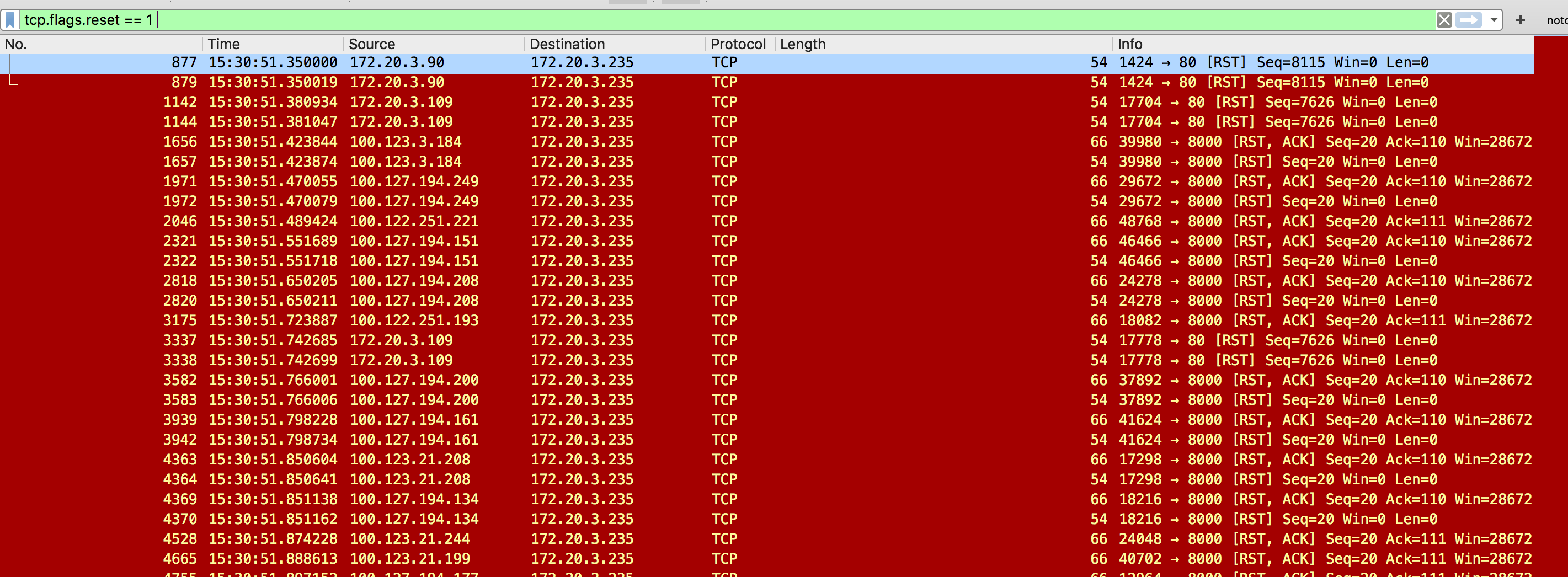
于是让业务梳理了业务场景,检查了相关代码逻辑,确定是否有主动关闭tcp连接的操作,业务给出了否定答案,确定没有相关逻辑,gogle了相关问题,发现有很多人遇到了类似的问题,按照网上的方法设置了一下参数:
1.istio 增加503 retry
2.禁用业务容器envoy的keepalive
3.设置envoy连接池空闲缓存时间(让envoy主动断开空闲连接,而不是让业务容器断开envoy的长链接)
apiVersion: networking.istio.io/v1beta1 kind: VirtualService metadata: name: xthk-live-api-pub-vs namespace: prod-main spec: hosts: - xthk-live-api-pub http: - match: - port: 80 retries: attempts: 3 perTryTimeout: 2s retryOn: 'gateway-error,connect-failure,refused-stream,503' route: - destination: host: xthk-live-api-pub port: number: 80 subset: v1 - match: - port: 443 route: - destination: host: xthk-live-api-pub port: number: 443 subset: v1 --- apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: xthk-live-api-pub-dr namespace: prod-main spec: host: xthk-live-api-pub subsets: - labels: version: v1 name: v1 trafficPolicy: connectionPool: http: idleTimeout: 1s maxRequestsPerConnection: 1 tls: mode: ISTIO_MUTUAL
经过一段时间的操作,发现然并卵,错误依旧
再次仔细查看envoy日志,发现了异常

upstream_cluster为PassthroughCluster,调用k8s集群内的服务,为什么upstream_cluster不是服务名称的cluster呢?(当cluster为PassthroughCluster,证明istio没有通过k8s发现该服务,这样的话就不会走istio的路由,而是通过k8s的svc转发,就会多走一层kube-proxy转发)
为了排查 upstream_cluster为PassthroughCluster的问题,将apisix envoy的日志设置为debug,有两种设置方式:
1.直接在进入envoy 调用envoy接口配置,这种方式实时生效,且不重启envoy,envoy重启后失效 curl -X POST localhost:15000/logging?level=debug
2.设置pod annoations: sidecar.istio.io/logLevel: debug,这种方式pod会重建,但是重启后debug模式依旧生效
查看envoy 日志:
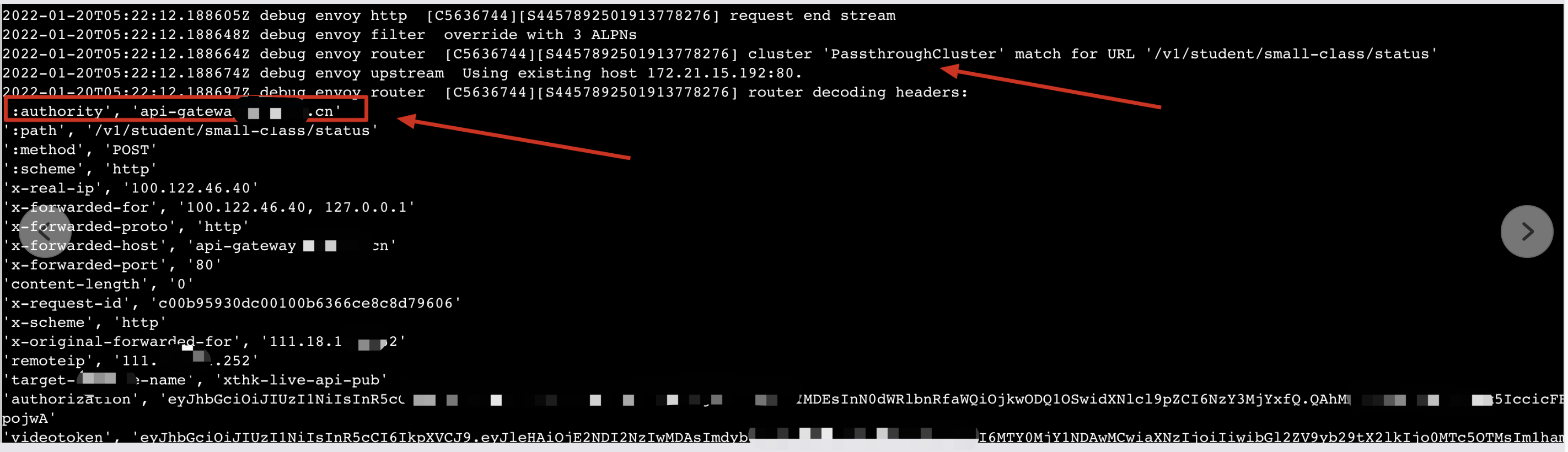
通过日志我们发现authority 为一个外网域名,即istio向后转发时使用的host 是一个外网域名而不是集群内的service name,而istio中的VirtualService以及DestinationRule都是靠其中的host字段来匹配的,所以导致istio向pod转发流量时走的istio的passthroughCluster,而不是对应集群内服务(Outbound Cluster),所以没有走istio的路由直接转发给pod(istio的转发是不经过kube-proxy),而是走了k8s 的service ip,通过kube-proxy转发到pod,这中间相当于就多了一层转发,那为什么会造成这个原因呢,看了apisix的配置,发现了问题
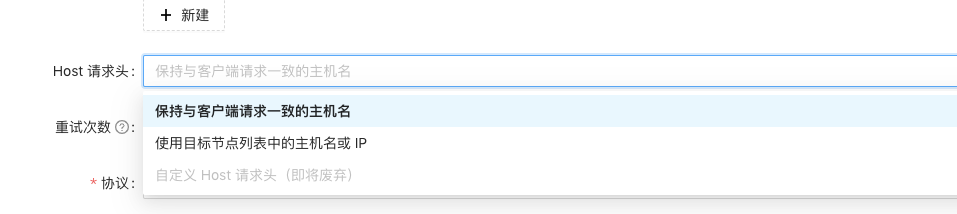
apisix 向后转发时可以配置转发到后端时主机名的保持,有三种方式:
1.保持与客户端请求一致的主机名:他的意思是客户端请求的是什么域名,转发到k8s pod时 host 就是客户端请求的域名,如:客户端请求的是 www.baidu.com,这时候转发到集群时,hostName 就是 www.baidul.com,就会导致本次访问的host 与istio vs以及dr规则匹配不到,就会当成不是集群内的服务,会走passthroughCluster,不会走istio的路由,而是通过k8s的kube-proxy最终转发到pod
2.使用目标节点列表中的主机名或IP,这个选项的意思是无论客户端通过什么域名来请求,apisix转发到k8s集群时都是用我们自己配置的主机名,如上游主机我们配置的是k8s的svc name,这时转发到后端时就会使用k8s的svc name而不是客户端访问的域名
3.自定义Host请求头:这个的意思和第二个选项类似,只不过我们可以自定义向后携带的hostName
我把apisix修改成了上述第二个选项使用目标节点列表中的主机名或IP,再次查看apisix 的envoy日志:
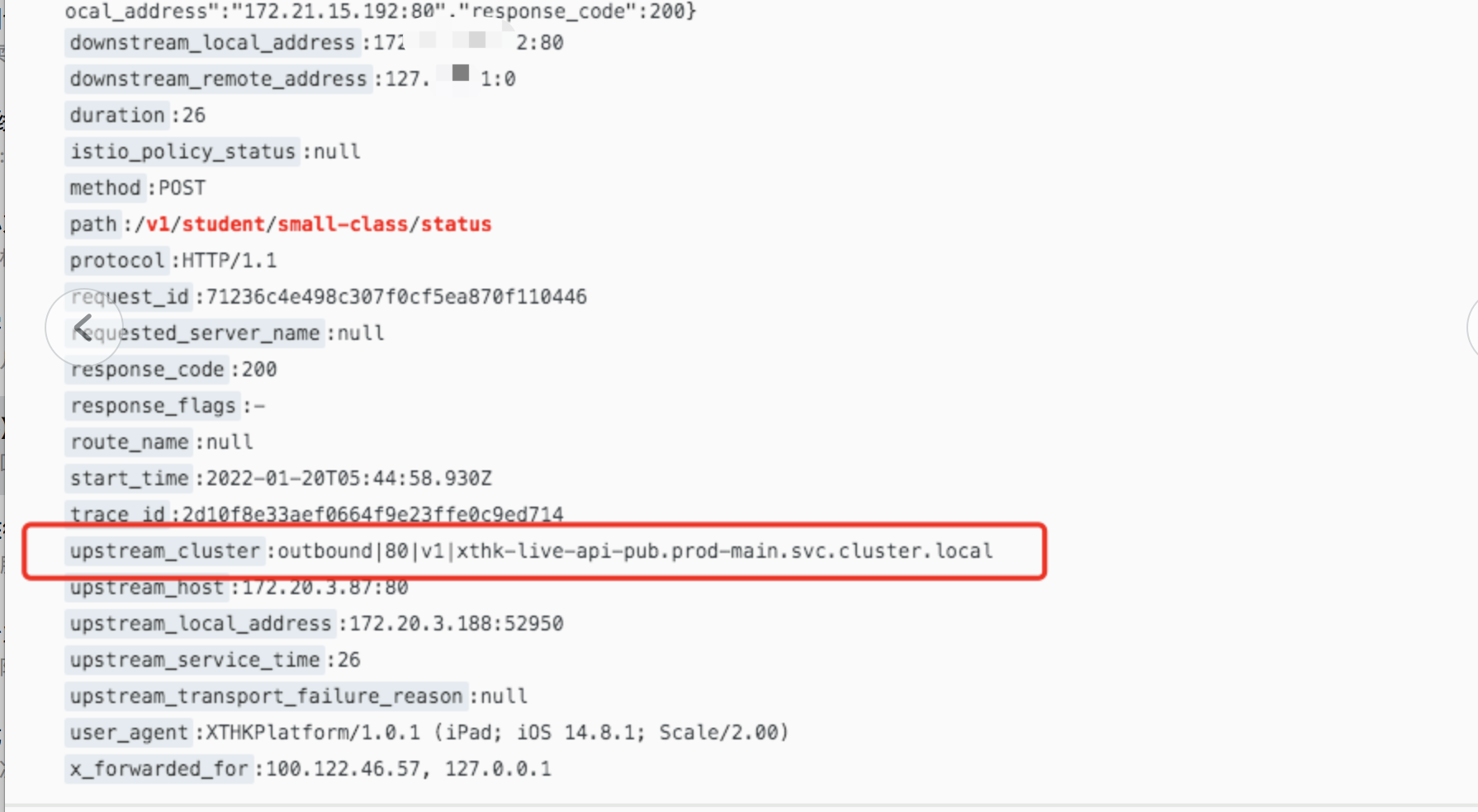
这时发现upstream_cluster变成了对一个k8s服务的outbond,说明istio已经识别了目标服务为k8s集群内的服务,这时候就会走istio自己的路由,不走kube-proxy.
一天后查看对应业务的访问日志
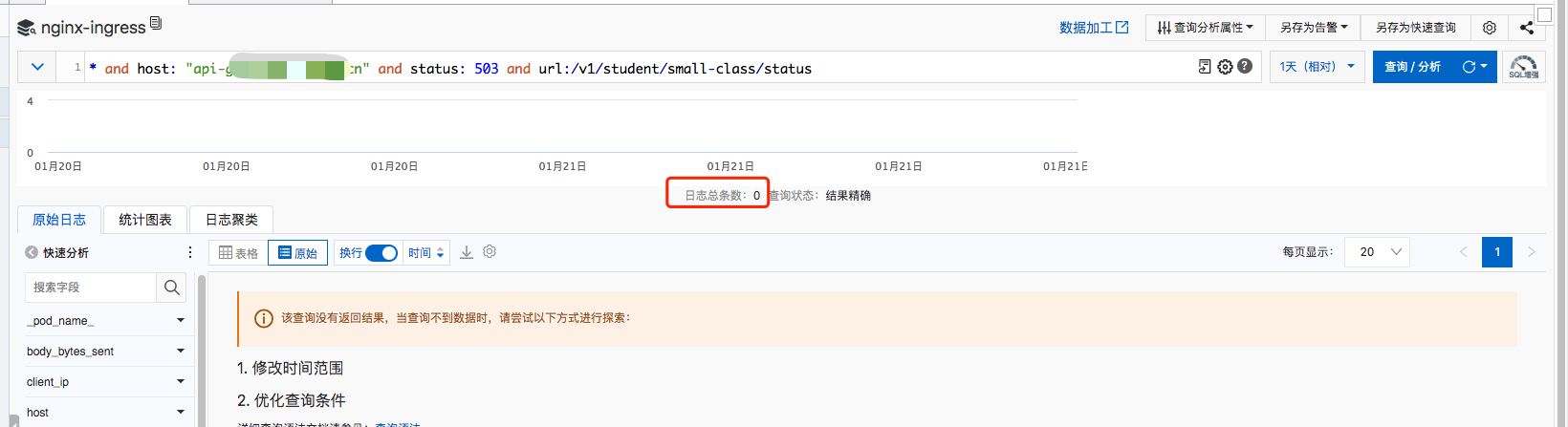
查看了一天的日志,发现503消失
相关参考链接:
https://blog.csdn.net/luo15242208310/article/details/96480095
https://zhuanlan.zhihu.com/p/412262801
https://jishuin.proginn.com/p/763bfbd310c3
posted on 2022-01-21 14:17 it_man_xiangge 阅读(1804) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号