
1、什么是LVS?
首先简单介绍一下LVS (Linux Virtual Server)到底是什么东西,其实它是一种集群(Cluster)技术,采用IP负载均衡技术和基于内容请求分发技术。调度器具有很好的吞吐率,将请求均衡地转移到不同的服务器上执行,且调度器自动屏蔽掉服务器的故障,从而将一组服务器构成一个高性能的、高可用的虚拟服务器。整个服务器集群的结构对客户是透明的,而且无需修改客户端和服务器端的程序。
为此,在设计时需要考虑系统的透明性、可伸缩性、高可用性和易管理性。一般来说,LVS集
群采用三层结构,其体系结构如图所示:
LVS集群的体系结构
2、LVS主要组成部分为:
负载调度器(load balancer/ Director),它是整个集群对外面的前端机,负责将客户的请求发送到一组服务器上执行,而客户认为服务是来自一个IP地址(我们可称之为虚拟IP地址)上的。
服务器池(server pool/ Realserver),是一组真正执行客户请求的服务器,执行的服务一般有WEB、MAIL、FTP和DNS等。
共享存储(shared storage),它为服务器池提供一个共享的存储区,这样很容易使得服务器池拥有相同的内容,提供相同的服务。
3、LVS负载均衡方式:
◆Virtual Server via Network Address Translation NAT(VS/NAT)
VS/NAT是一种最简单的方式,所有的RealServer只需要将自己的网关指向Director即可。客户端可以是任意操作系统,但此方式下,一个Director能够带动的RealServer比较有限。在VS/NAT的方式下,Director也可以兼为一台RealServer。VS/NAT的体系结构如图所示。
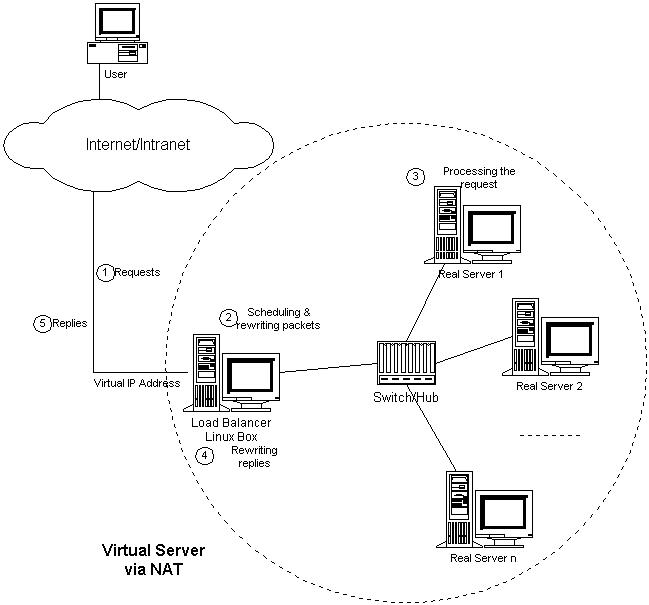
VS/NAT的体系结构
◆Virtual Server via IP Tunneling(VS/TUN)
IP隧道(IP tunneling)是将一个IP报文封装在另一个IP报文的技术,这可以使得目标为一个IP地址的数据报文能被封装和转发到另一个IP地址。IP隧道技术亦称为IP封装技术(IP encapsulation)。IP隧道主要用于移动主机和虚拟私有网络(Virtual Private Network),在其中隧道都是静态建立的,隧道一端有一个IP地址,另一端也有唯一的IP地址。
它的连接调度和管理与VS/NAT中的一样,只是它的报文转发方法不同。调度器根据各个服务器的负载情况,动态地选择一台服务器,将请求报文封装在另一个IP报文中,再将封装后的IP报文转发给选出的服务器;服务器收到报文后,先将报文解封获得原来目标地址为 VIP 的报文,服务器发现VIP地址被配置在本地的IP隧道设备上,所以就处理这个请求,然后根据路由表将响应报文直接返回给客户。

VS/TUN的体系结构
VS/TUN的工作流程:

◆Virtual Server via Direct Routing(VS/DR)
VS/DR方式是通过改写请求报文中的MAC地址部分来实现的。Director和RealServer必需在物理上有一个网卡通过不间断的局域网相连。 RealServer上绑定的VIP配置在各自Non-ARP的网络设备上(如lo或tunl),Director的VIP地址对外可见,而RealServer的VIP对外是不可见的。RealServer的地址即可以是内部地址,也可以是真实地址。
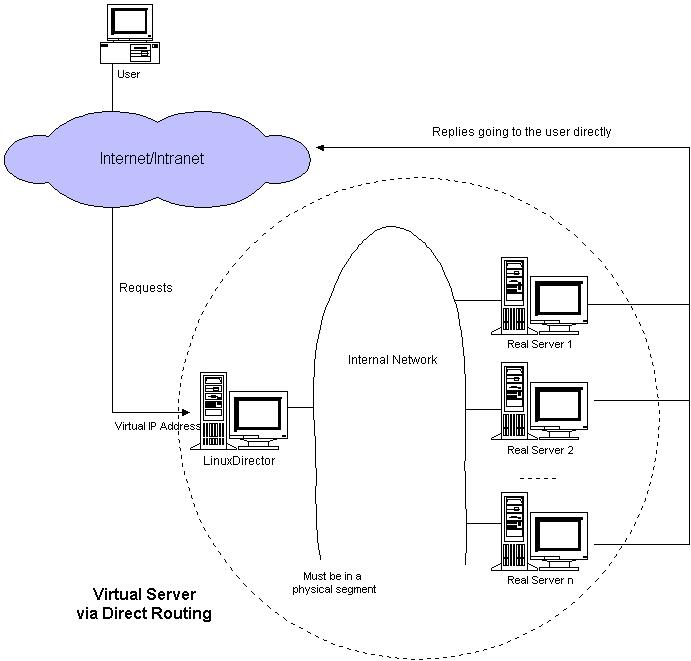
VS/DR的体系结构
VS/DR的工作流程
VS/DR的工作流程如图所示:它的连接调度和管理与VS/NAT和VS/TUN中的一样,它的报文转发方法又有不同,将报文直接路由给目标服务器。在VS/DR中,调度器根据各个服务器的负载情况,动态地选择一台服务器,不修改也不封装IP报文,而是将数据帧的MAC地址改为选出服务器的MAC地址,再将修改后的数据帧在与服务器组的局域网上发送。因为数据帧的MAC地址是选出的服务器,所以服务器肯定可以收到这个数据帧,从中可以获得该IP报文。当服务器发现报文的目标地址VIP是在本地的网络设备上,服务器处理这个报文,然后根据路由表将响应报文直接返回给客户。
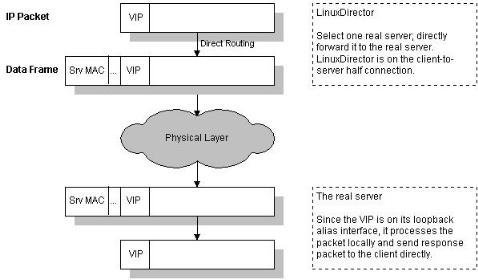
VS/DR的工作流程
4、三种负载均衡方式比较:
◆Virtual Server via NAT
VS/NAT 的优点是服务器可以运行任何支持TCP/IP的操作系统,它只需要一个IP地址配置在调度器上,服务器组可以用私有的IP地址。缺点是它的伸缩能力有限,当服务器结点数目升到20时,调度器本身有可能成为系统的新瓶颈,因为在VS/NAT中请求和响应报文都需要通过负载调度器。我们在Pentium166 处理器的主机上测得重写报文的平均延时为60us,性能更高的处理器上延时会短一些。假设TCP报文的平均长度为536 Bytes,则调度器的最大吞吐量为8.93 MBytes/s. 我们再假设每台服务器的吞吐量为800KBytes/s,这样一个调度器可以带动10台服务器。(注:这是很早以前测得的数据)
基于 VS/NAT的的集群系统可以适合许多服务器的性能要求。如果负载调度器成为系统新的瓶颈,可以有三种方法解决这个问题:混合方法、VS/TUN和 VS/DR。在DNS混合集群系统中,有若干个VS/NAT负调度器,每个负载调度器带自己的服务器集群,同时这些负载调度器又通过RR-DNS组成简单的域名。
但VS/TUN和VS/DR是提高系统吞吐量的更好方法。
对于那些将IP地址或者端口号在报文数据中传送的网络服务,需要编写相应的应用模块来转换报文数据中的IP地址或者端口号。这会带来实现的工作量,同时应用模块检查报文的开销会降低系统的吞吐率。
◆Virtual Server via IP Tunneling
在VS/TUN 的集群系统中,负载调度器只将请求调度到不同的后端服务器,后端服务器将应答的数据直接返回给用户。这样,负载调度器就可以处理大量的请求,它甚至可以调度百台以上的服务器(同等规模的服务器),而它不会成为系统的瓶颈。即使负载调度器只有100Mbps的全双工网卡,整个系统的最大吞吐量可超过 1Gbps。所以,VS/TUN可以极大地增加负载调度器调度的服务器数量。VS/TUN调度器可以调度上百台服务器,而它本身不会成为系统的瓶颈,可以用来构建高性能的超级服务器。VS/TUN技术对服务器有要求,即所有的服务器必须支持“IP Tunneling”或者“IP Encapsulation”协议。目前,VS/TUN的后端服务器主要运行Linux操作系统,我们没对其他操作系统进行测试。因为“IP Tunneling”正成为各个操作系统的标准协议,所以VS/TUN应该会适用运行其他操作系统的后端服务器。
◆Virtual Server via Direct Routing
跟VS/TUN方法一样,VS/DR调度器只处理客户到服务器端的连接,响应数据可以直接从独立的网络路由返回给客户。这可以极大地提高LVS集群系统的伸缩性。跟VS/TUN相比,这种方法没有IP隧道的开销,但是要求负载调度器与实际服务器都有一块网卡连在同一物理网段上,服务器网络设备(或者设备别名)不作ARP响应,或者能将报文重定向(Redirect)到本地的Socket端口上。
三种LVS负载均衡技术的优缺点归纳以下表:
| VS/NAT | VS/TUN | VS/DR | |
服务器操作系统 | 任意 | 支持隧道 | 多数(支持Non-arp) |
服务器网络 | 私有网络 | 局域网/广域网 | 局域网 |
服务器数目(100M网络) | 10~20 | 100 | 大于100 |
服务器网关 | 负载均衡器 | 自己的路由 | 自己的路由 |
| 效率 | 一般 | 高 | 最高 |
注:以上三种方法所能支持最大服务器数目的估计是假设调度器使用100M网卡,调度器的硬件配置与后端服务器的硬件配置相同,而且是对一般Web服务。使 用更高的硬件配置(如千兆网卡和更快的处理器)作为调度器,调度器所能调度的服务器数量会相应增加。当应用不同时,服务器的数目也会相应地改变。所以,以上数据估计主要是为三种方法的伸缩性进行量化比较。
5、lvs的负载调度算法 在内核中的连接调度算法上,IPVS已实现了以下八种调度算法:
◆一 轮叫调度(Round­Robin Schedul ing )
轮叫调度(Round Robin Scheduling)算法就是以轮叫的方式依次将请求调度不同的服务器,即每次调度执行i=(i+1)mod n,并选出第i台服务器。算法的优点是其简洁性,它无需记录当前所有连接的状态,所以它是一种无状态调度。
◆二 加权轮叫调度(Weighted Round­Robin Scheduling )
加权轮叫调度 (Weighted Round­Robin Scheduling)算法可以解决服务器间性能不一的情况,它用相应的权值表示服务器的处理性能,服务器的缺省权值为1。假设服务器A的权值为1,B的权值为2,则表示服务器B的处理性能是A的两倍。加权轮叫调度算法是按权值的高 低和轮叫方式分配请求到各服务器。权值高的服务器先收到的连接,权值高的服 务器比权值低的服务器处理更多的连接,相同权值的服务器处理相同数目的连接数。
◆三 最小连接调度(Least­Connect ion Schedul ing )
最小连接调度(Least­ Connect ion Scheduling)算法是把新的连接请求分配到当前连接数最小的服务器。最小连接调度是一种动态调度算法,它通过服务器当前所活跃的连接数来估计服务器的负载情况。调度器需要记录各个服务器已建立连接的数目,当一个请求被调度到某台服务器,其连接数加1;当连接中止或超时,其连接数减一。
◆四 加权最小连接调度(Weighted Least­Connectio n Scheduling)
加权最小连接调 度(Weighted Least­Connectio n Scheduling)算法是最小连接调度的超集,各个服务器用相应的权值表示其处理性能。服务器的缺省权值为1,系统管理员可以动态地设置服务器的权值。加权最小连接调度在调度新连接时尽可能使服务器的已建立连接数和其权值成比例。
◆五 基于局部性的最少链接(Locality­Based Least Connections Schedulin g )
基于局部性的最少链接调度(Locality­Based Least Connections Scheduling,以下简称为LBLC)算法是针对请求报文的目标IP地址的负载均衡调度,目前主要用于Cache集群系统,因为在Cache集群中客户请求报文的目标IP地址是变化的。这里假设任何后端服务器都可以处理任一请求,算法的设计目标是在服务器的负载基本平衡情况下,将相同目标IP地址的请求调度到同一台服务器,来提高各台服务器的访问局部性和主存Cache命中率,从而整个集群系统的处理能力。LBLC调度算法先根据请求的目标IP 地址 找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于其一半的工 作负载,则用“最少链接”的原则选出一个可用的服务器,将请求发送到该服务器。
◆六 带复制的基于局部性最少链接(Locality­Based Least Connectio ns with Replication Scheduling)
带复制的基于局部性最少链接调度(Locality­Based Least Connectio ns with Replication Scheduling,以下简称为LBLCR)算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。它与LBLC算法的不同之处是它要 维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。对于一个“热门”站点的服务请求,一台Cache 服务器可能会忙不过来处理这些请求。这时,LBLC调度算法会从所有的Cache服务器中按“最小连接”原则选出一台Cache服务器,映射该“热门”站点到这台Cache服务器,很快这台Cache服务器也会超载,就会重复上述过程选出新的Cache服务器。这样,可能会导致该“热门”站点的映像会出现 在所有的Cache服务器上,降低了Cache服务器的使用效率。LBLCR调度算法将“门站”点映射到一组Cache服务器(服务器集合),当该“热门”站点的请求负载增加时,会增加集合里的Cache服务器,来处理不断增长的负载;当该“热门”站点的请求负载降低时,会减少集合里的Cache服务器 数目。这样,该热门站点的映像不可能出现在所有的Cache服务器上,从而提供Cache集群系统的使用效率。LBLCR算法先根据请求的目标IP 地址找出该目标IP地址对应的服务器组;按“最小连接”原则从该服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载;则按“最小连接”原则从整个集群中选出一台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服 务器从服务器组中删除,以降低复制的程度。
◆七 目标地址散列调度(Destinat ion Hashing Scheduling )
目标地址散列调度 (Destinat ion Hashing Scheduling)算法也是针对目标IP地址的负载均衡,但它是一种静态映射算法,通过一个散列(Hash)函数将一个目标IP地址映射到一台服务器。目标地址散列调度算法先根据请求的目标IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
◆八 源地址散列调度(Source Hashing Scheduling)
源地址散列调度(Source Hashing Scheduling)算法正好与目标地址散列调度算法相反,它根据请求的源IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。它采用的散列函数与目标地址散列调度算法 的相同。它的算法流程与目标地址散列调度算法的基本相似,除了将请求的目标IP地址换成请求的源IP 地址,所以这里不一一叙述。在实际应用中,源地址散列 调度和目标地址散列调度可以结合使用在防火墙集群中,它们可以保证整个系统的唯一出入口。
--leeypp@gmail.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号