

faster-rcnn原理及相应概念解释
R-CNN --> FAST-RCNN --> FASTER-RCNN
R-CNN:
(1)输入测试图像;
(2)利用selective search 算法在图像中从上到下提取2000个左右的Region Proposal;
(3)将每个Region Proposal缩放(warp)成227*227的大小并输入到CNN,将CNN的fc7层的输出作为特征;
(4)将每个Region Proposal提取的CNN特征输入到SVM进行分类;
(5)对于SVM分好类的Region Proposal做边框回归,用Bounding box回归值校正原来的建议窗口,生成预测窗口坐标.
缺陷:
(1) 训练分为多个阶段,步骤繁琐:微调网络+训练SVM+训练边框回归器;
(2) 训练耗时,占用磁盘空间大;5000张图像产生几百G的特征文件;
(3) 速度慢:使用GPU,VGG16模型处理一张图像需要47s;
(4) 测试速度慢:每个候选区域需要运行整个前向CNN计算;
(5) SVM和回归是事后操作,在SVM和回归过程中CNN特征没有被学习更新.
FAST-RCNN:
(1)输入测试图像;
(2)利用selective search 算法在图像中从上到下提取2000个左右的建议窗口(Region Proposal);
(3)将整张图片输入CNN,进行特征提取;
(4)把建议窗口映射到CNN的最后一层卷积feature map上;
(5)通过RoI pooling层使每个建议窗口生成固定尺寸的feature map;
(6)利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
相比R-CNN,主要两处不同:
(1)最后一层卷积层后加了一个ROI pooling layer;
(2)损失函数使用了多任务损失函数(multi-task loss),将边框回归直接加入到CNN网络中训练
改进:
(1) 测试时速度慢:R-CNN把一张图像分解成大量的建议框,每个建议框拉伸形成的图像都会单独通过CNN提取特征.实际上这些建议框之间大量重叠,特征值之间完全可以共享,造成了运算能力的浪费.
FAST-RCNN将整张图像归一化后直接送入CNN,在最后的卷积层输出的feature map上,加入建议框信息,使得在此之前的CNN运算得以共享.
(2) 训练时速度慢:R-CNN在训练时,是在采用SVM分类之前,把通过CNN提取的特征存储在硬盘上.这种方法造成了训练性能低下,因为在硬盘上大量的读写数据会造成训练速度缓慢.
FAST-RCNN在训练时,只需要将一张图像送入网络,每张图像一次性地提取CNN特征和建议区域,训练数据在GPU内存里直接进Loss层,这样候选区域的前几层特征不需要再重复计算且不再需要把大量数据存储在硬盘上.
(3) 训练所需空间大:R-CNN中独立的SVM分类器和回归器需要大量特征作为训练样本,需要大量的硬盘空间.FAST-RCNN把类别判断和位置回归统一用深度网络实现,不再需要额外存储.
FASTER -RCNN:
(1)输入测试图像;
(2)将整张图片输入CNN,进行特征提取;
(3)用RPN生成建议窗口(proposals),每张图片生成300个建议窗口;
(4)把建议窗口映射到CNN的最后一层卷积feature map上;
(5)通过RoI pooling层使每个RoI生成固定尺寸的feature map;
(6)利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
相比FASTER-RCNN,主要两处不同:
(1)使用RPN(Region Proposal Network)代替原来的Selective Search方法产生建议窗口;
(2)产生建议窗口的CNN和目标检测的CNN共享
改进:
(1) 如何高效快速产生建议框?
FASTER-RCNN创造性地采用卷积网络自行产生建议框,并且和目标检测网络共享卷积网络,使得建议框数目从原有的约2000个减少为300个,且建议框的质量也有本质的提高.
概念解释:
1、常用的Region Proposal有:
-Selective Search
-Edge Boxes
2、softmax-loss
softmax-loss 层和 softmax 层计算大致是相同的. softmax 是一个分类器,计算的是类别的概率(Likelihood),是
Logistic Regression 的一种推广. Logistic
Regression 只能用于二分类,
而 softmax 可以用于多分类.
softmax 与 softmax-loss 的区别:
softmax 计算公式:
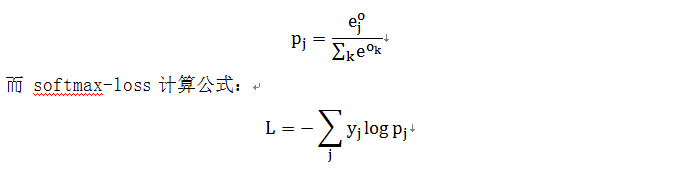
关于两者的区别更加具体的介绍,可参考: softmax vs. softmax-loss
用户可能最终目的就是得到各个类别的概率似然值,这个时候就只需要一个 Softmax 层,而不一定要进行
softmax-Loss 操作;或者是用户有通过其他什么方式已经得到了某种概率似然值,然后要做最大似然估计,此时则只需要后面的
softmax-Loss 而不需要前面的 Softmax操作.因此提供两个不同的 Layer 结构比只提供一个合在一起的 Softmax-Loss Layer 要灵活许多.不管是 softmax layer 还是 softmax-loss layer,都是没有参数的,只是层类型不同而已
softmax-loss layer:输出 loss 值
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip1"
bottom: "label"
top: "loss"
}
softmax layer: 输出似然值
layers {
bottom: "cls3_fc"
top: "prob"
name: "prob"
type: “Softmax"
}
3、Selective Search
这个策略其实是借助了层次聚类的思想(可以搜索了解一下"层次聚类算法"),将层次聚类的思想应用到区域的合并上面;
总体思路:
l 假设现在图像上有n个预分割的区域(Efficient Graph-Based Image Segmentation),表示为R={R1, R2, ..., Rn},
l 计算每个region与它相邻region(注意是相邻的区域)的相似度,这样会得到一个n*n的相似度矩阵(同一个区域之间和一个区域与不相邻区域之间的相似度可设为NaN),从矩阵中找出最大相似度值对应的两个区域,将这两个区域合二为一,这时候图像上还剩下n-1个区域;
l 重复上面的过程(只需要计算新的区域与它相邻区域的新相似度,其他的不用重复计算),重复一次,区域的总数目就少1,知道最后所有的区域都合并称为了同一个区域(即此过程进行了n-1次,区域总数目最后变成了1).算法的流程图如下图所示:


4、SPP-NET
SSP-Net:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
先看一下R-CNN为什么检测速度这么慢,一张图都需要47s!仔细看下R-CNN框架发现,对图像提完Region Proposal(2000个左右)之后将每个Proposal当成一张图像进行后续处理(CNN提特征+SVM分类),实际上对一张图像进行了2000次提特征和分类的过程!这2000个Region Proposal不都是图像的一部分吗,那么我们完全可以对图像提一次卷积层特征,然后只需要将Region Proposal在原图的位置映射到卷积层特征图上,这样对于一张图像我们只需要提一次卷积层特征,然后将每个Region Proposal的卷积层特征输入到全连接层做后续操作.(对于CNN来说,大部分运算都耗在卷积操作上,这样做可以节省大量时间).
现在的问题是每个Region Proposal的尺度不一样,直接这样输入全连接层肯定是不行的,因为全连接层输入必须是固定的长度.SPP-NET恰好可以解决这个问题.

由于传统的CNN限制了输入必须固定大小(比如AlexNet是224x224),所以在实际使用中往往需要对原图片进行crop或者warp的操作:
- crop:截取原图片的一个固定大小的patch
- warp:将原图片的ROI缩放到一个固定大小的patch
无论是crop还是warp,都无法保证在不失真的情况下将图片传入到CNN当中:
- crop:物体可能会产生截断,尤其是长宽比大的图片.
- warp:物体被拉伸,失去“原形”,尤其是长宽比大的图片
SPP为的就是解决上述的问题,做到的效果为:不管输入的图片是什么尺度,都能够正确的传入网络.
具体思路为:CNN的卷积层是可以处理任意尺度的输入的,只是在全连接层处有限制尺度——换句话说,如果找到一个方法,在全连接层之前将其输入限制到等长,那么就解决了这个问题.
具体方案如下图所示:
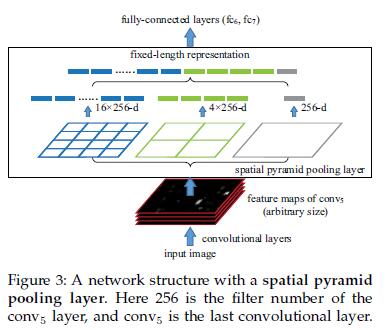
如果原图输入是224x224,对于conv5出来后的输出,是13x13x256的,可以理解成有256个这样的filter,每个filter对应一张13x13的activation map.如果像上图那样将activation map pooling成4x4 2x2 1x1三张子图,做max pooling后,出来的特征就是固定长度的(16+4+1)x256那么多的维度了.如果原图的输入不是224x224,出来的特征依然是(16+4+1)x256;直觉地说,可以理解成将原来固定大小为(3x3)窗口的pool5改成了自适应窗口大小,窗口的大小和activation map成比例,保证了经过pooling后出来的feature的长度是一致的.
5、Bounding box regression
R-CNN中的bounding box回归
下面先介绍R-CNN和Fast R-CNN中所用到的边框回归方法.
(1)
什么是IOU

(2)
为什么要做Bounding-box
regression?

如上图所示,绿色的框为飞机的Ground Truth,红色的框是提取的Region Proposal.那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准(IoU<0.5),那么这张图相当于没有正确的检测出飞机.如果我们能对红色的框进行微调,使得经过微调后的窗口跟Ground Truth更接近,这样岂不是定位会更准确.确实,Bounding-box regression 就是用来微调这个窗口的.
(3)
回归/微调的对象是什么?
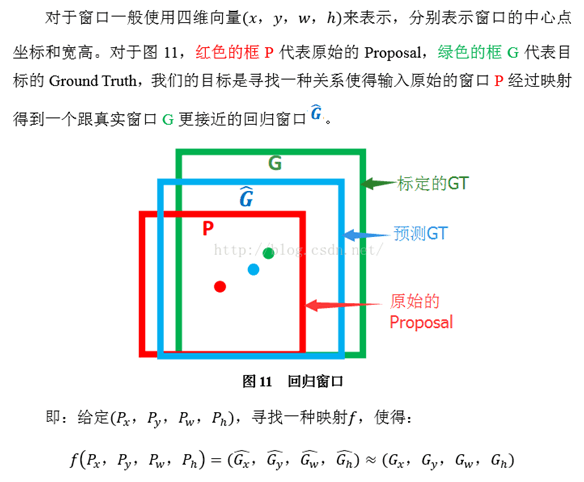
(4) Bounding-box regression(边框回归)
那么经过何种变换才能从图11中的窗口P变为窗口呢?比较简单的思路就是:
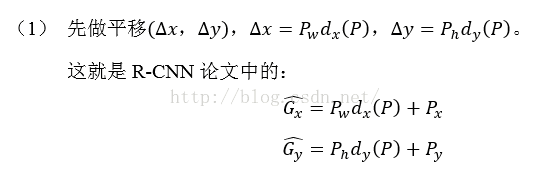

注意:只有当Proposal和Ground Truth比较接近时(线性问题),我们才能将其作为训练样本训练我们的线性回归模型,否则会导致训练的回归模型不work(当Proposal跟GT离得较远,就是复杂的非线性问题了,此时用线性回归建模显然不合理).这个也是G-CNN: an Iterative Grid Based Object
Detector多次迭代实现目标准确定位的关键.
线性回归就是给定输入的特征向量X,学习一组参数W,使得经过线性回归后的值跟真实值Y(Ground Truth)非常接近.即.那么Bounding-box中我们的输入以及输出分别是什么呢?


6、Region Proposal Network
RPN的实现方式:在conv5-3的卷积feature map上用一个n*n的滑窗(论文中作者选用了n=3,即3*3的滑窗)生成一个长度为256(对应于ZF网络)或512(对应于VGG网络)维长度的全连接特征.然后在这个256维或512维的特征后产生两个分支的全连接层:
(1)reg-layer,用于预测proposal的中心锚点对应的proposal的坐标x,y和宽高w,h;
(2)cls-layer,用于判定该proposal是前景还是背景.sliding window的处理方式保证reg-layer和cls-layer关联了conv5-3的全部特征空间.事实上,作者用全连接层实现方式介绍RPN层实现容易帮助我们理解这一过程,但在实现时作者选用了卷积层实现全连接层的功能.
(3)个人理解:全连接层本来就是特殊的卷积层,如果产生256或512维的fc特征,事实上可以用Num_out=256或512, kernel_size=3*3, stride=1的卷积层实现conv5-3到第一个全连接特征的映射.然后再用两个Num_out分别为2*9=18和4*9=36,kernel_size=1*1,stride=1的卷积层实现上一层特征到两个分支cls层和reg层的特征映射.
(4)注意:这里2*9中的2指cls层的分类结果包括前后背景两类,4*9的4表示一个Proposal的中心点坐标x,y和宽高w,h四个参数.采用卷积的方式实现全连接处理并不会减少参数的数量,但是使得输入图像的尺寸可以更加灵活.在RPN网络中,我们需要重点理解其中的anchors概念,Loss fucntions计算方式和RPN层训练数据生成的具体细节.
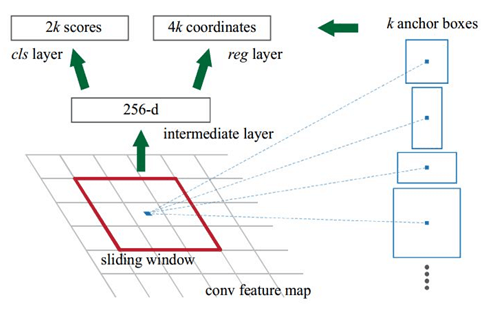
Anchors:字面上可以理解为锚点,位于之前提到的n*n的sliding window的中心处.对于一个sliding window,我们可以同时预测多个proposal,假定有k个.k个proposal即k个reference boxes,每一个reference box又可以用一个scale,一个aspect_ratio和sliding window中的锚点唯一确定.所以,我们在后面说一个anchor,你就理解成一个anchor box 或一个reference box.作者在论文中定义k=9,即3种scales和3种aspect_ratio确定出当前sliding window位置处对应的9个reference boxes, 4*k个reg-layer的输出和2*k个cls-layer的score输出.对于一幅W*H的feature map,对应W*H*k个锚点.所有的锚点都具有尺度不变性.
Loss functions:
在计算Loss值之前,作者设置了anchors的标定方法.正样本标定规则:
1) 如果Anchor对应的reference box与ground truth的IoU值最大,标记为正样本;
2) 如果Anchor对应的reference box与ground truth的IoU>0.7,标记为正样本.事实上,采用第2个规则基本上可以找到足够的正样本,但是对于一些极端情况,例如所有的Anchor对应的reference box与groud truth的IoU不大于0.7,可以采用第一种规则生成.
3) 负样本标定规则:如果Anchor对应的reference box与ground truth的IoU<0.3,标记为负样本.
4) 剩下的既不是正样本也不是负样本,不用于最终训练.
5) 训练RPN的Loss是有classification loss (即softmax loss)和regression loss (即L1 loss)按一定比重组成的.
计算softmax loss需要的是anchors对应的groundtruth标定结果和预测结果,计算regression loss需要三组信息:
i. 预测框,即RPN网络预测出的proposal的中心位置坐标x,y和宽高w,h;
ii. 锚点reference box:
之前的9个锚点对应9个不同scale和aspect_ratio的reference boxes,每一个reference boxes都有一个中心点位置坐标x_a,y_a和宽高w_a,h_a;
iii. ground truth:标定的框也对应一个中心点位置坐标x*,y*和宽高w*,h*.因此计算regression loss和总Loss方式如下:

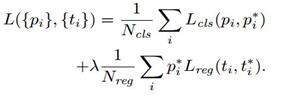
RPN训练设置:
(1)在训练RPN时,一个Mini-batch是由一幅图像中任意选取的256个proposal组成的,其中正负样本的比例为1:1.
(2)如果正样本不足128,则多用一些负样本以满足有256个Proposal可以用于训练,反之亦然.
(3)训练RPN时,与VGG共有的层参数可以直接拷贝经ImageNet训练得到的模型中的参数;剩下没有的层参数用标准差=0.01的高斯分布初始化.
7、RoI Pooling
ROI pooling layer实际上是SPP-NET的一个精简版,SPP-NET对每个proposal使用了不同大小的金字塔映射,而ROI pooling layer只需要下采样到一个7x7的特征图.对于VGG16网络conv5_3有512个特征图,这样所有region proposal对应了一个7*7*512维度的特征向量作为全连接层的输入.
RoI Pooling就是实现从原图区域映射到conv5区域最后pooling到固定大小的功能.
8、smooth L1 Loss
为了处理不可导的惩罚,Faster RCNN提出来的计算距离loss的smooth_L1_Loss.smooth L1近似理解见http://pages.cs.wisc.edu/~gfung/GeneralL1/L1_approx_bounds.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号