selenium的使用
下载selenium
pip install seleniumlinux
pip3 install selenium/usr/local/lib/python3.6/

下载webdriver
webDriver(驱动浏览器运行的工具)
版本号要和谷歌浏览器的版本号要一致
下载完成后放入谷歌浏览器的安装目录下,然后加到path里面

path的路径为上面路径即一直到Application
或者直接将驱动加到安装的selenium库下

或者直接指定
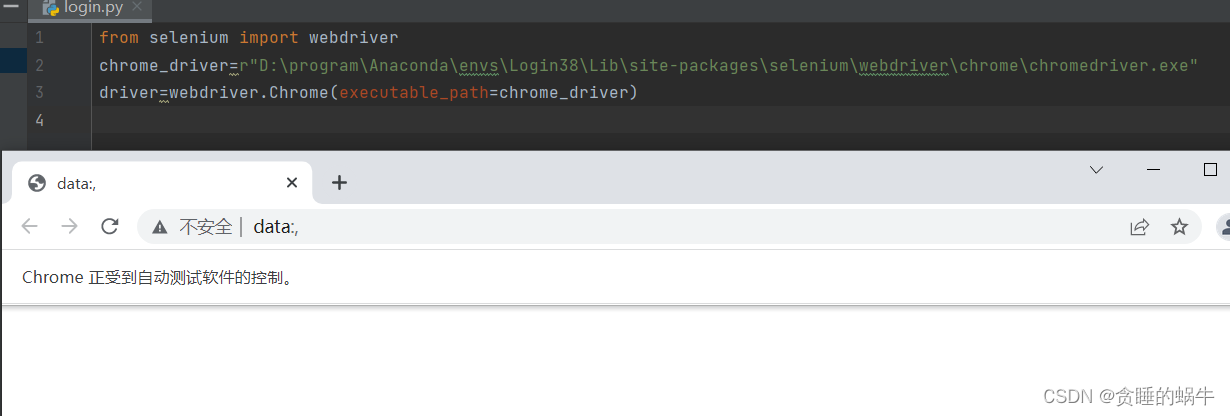
from selenium import webdriver
chrome_driver=r"D:\program\Anaconda\envs\Login38\Lib\site-packages\selenium\webdriver\chrome\chromedriver.exe"
driver=webdriver.Chrome(executable_path=chrome_driver)
linux版本放在/usr/bin目录下
基本操作
from selenium import webdriver
import time
chrome_driver=r"D:\program\Anaconda\envs\Login38\Lib\site-packages\selenium\webdriver\chrome\chromedriver.exe"
driver=webdriver.Chrome(executable_path=chrome_driver)
#打开百度新闻
driver.get("https//new.baidu.com");
#两秒后执行登录操作
time.sleep(2)
#后退
driver.back()
#前进
driver.forward();
#刷新
driver.refresh();
#退出
drvier.quit();
滑动窗口
ActionChains是一个用来模拟鼠标操作的库
from selenium import webdriver
import time
#导入ActionChains
from selenium.webdriver import ActionChains
chrome_driver=r"D:\program\Anaconda\envs\Login38\Lib\site-packages\selenium\webdriver\chrome\chromedriver.exe"
driver=webdriver.Chrome(executable_path=chrome_driver)
#http://rgyy.hrbeu.edu.cn/home/book/more/lib/12/type/4/day/2022-03-31
driver.get("https://www.toutiao.com/");
#两秒后执行登录操作
time.sleep(2)
driver.save_screenshot("save_1.png")
#定位元素,可以使用各种类型的,比如class的name 比如id 比如xpath
ac=driver.find_element_by_class_name("company-wrapper")
#移动到那个位置
ActionChains(driver).move_to_element(ac).perform()
cookies的调用
get_cookies() 获得所有cookies信息
delete_all_cookies() 删除所有cookies信息
get_cookie([name]) 返回字典的key为[name]的cookie
add_cookie(cookie_dict) 添加cookie,cookie_dict是一个字典,且必须有name和value两个值
delete_cookie([name],[optionsString]) 删除cookie信息,第一个是cookie的名称,第二个是cookie选项,现在有路径和域例子
from selenium import webdriver
import time
#导入ActionChains
from selenium.webdriver import ActionChains
chrome_driver=r"D:\program\Anaconda\envs\Login38\Lib\site-packages\selenium\webdriver\chrome\chromedriver.exe"
driver=webdriver.Chrome(executable_path=chrome_driver)
driver.get("https://www.baidu.com");
#两秒后执行登录操作
#time.sleep(2)
driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
#得到所有cookies
cookies=driver.get_cookies()
#得到单个cookie
cookie=driver.get_cookie("BAIDUID")
print(cookies)
print(cookie)
#删除所有cookie
driver.delete_all_cookies()
time.sleep(3)
#退出
driver.quit()
使用多个窗口
可以使用js
from selenium import webdriver
import time
#导入ActionChains
from selenium.webdriver import ActionChains
chrome_driver=r"D:\program\Anaconda\envs\Login38\Lib\site-packages\selenium\webdriver\chrome\chromedriver.exe"
driver=webdriver.Chrome(executable_path=chrome_driver)
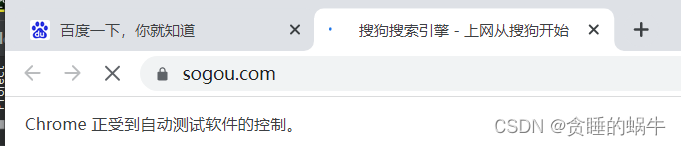
driver.get("https://www.baidu.com");
#两秒后执行登录操作
time.sleep(2)
js1='window.open("https://www.sogou.com")'
driver.execute_script(js1)
time.sleep(3)
#退出
#driver.quit()
如果想要控制页面可以获取句柄
all_handles=driver.window_handles
#跳转到最后一个句柄
driver.switch_to.window(all_handles[0])
print(all_handles)隐式等待和显式等待
隐式等待判断网页是否完全加载完。
driver.implicitly_wait(30)from selenium import webdriver
import time
#导入ActionChains
from selenium.webdriver import ActionChains
chrome_driver=r"D:\program\Anaconda\envs\Login38\Lib\site-packages\selenium\webdriver\chrome\chromedriver.exe"
driver=webdriver.Chrome(executable_path=chrome_driver)
driver.get("https://www.baidu.com");
#隐式等待
driver.implicitly_wait(30)
js1='window.open("https://www.sogou.com")'
driver.execute_script(js1)
time.sleep(3)
#退出
#driver.quit()
显式等待只需要判断某个特定的元素是否加载出来即可
需要导入下面三个
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By同样用到了隐式等待,这两个将取最大值。
from selenium import webdriver
import time
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
#导入ActionChains
from selenium.webdriver import ActionChains
chrome_driver=r"D:\program\Anaconda\envs\Login38\Lib\site-packages\selenium\webdriver\chrome\chromedriver.exe"
driver=webdriver.Chrome(executable_path=chrome_driver)
#http://rgyy.hrbeu.edu.cn/home/book/more/lib/12/type/4/day/2022-03-31
driver.get("https://www.csdn.net");
#隐式等待
driver.implicitly_wait(30)
#定位条件
locator=(By.LINK_TEXT,u'问答')
#使用显示等待
try:
WebDriverWait(driver,20,0.5).until(EC.presence_of_element_located(locator))
finally:
print(driver.find_element_by_link_text('问答').get_attribute('href'))
js1='window.open("https://www.sogou.com")'
driver.execute_script(js1)
time.sleep(3)
#退出
#driver.quit()
鼠标操作方法

action = ActionChains(self.driver)
click(on_element=None) ——单击鼠标左键
click_and_hold(on_element=None) ——点击鼠标左键,不松开
context_click(on_element=None) ——点击鼠标右键
double_click(on_element=None) ——双击鼠标左键
drag_and_drop(source, target) ——拖拽到某个元素然后松开
drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某个坐标然后松开
key_down(value, element=None) ——按下某个键盘上的键
key_up(value, element=None) ——松开某个键
move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动到某个坐标,注意这里的位移是指从鼠标当前坐标移动的大小移动多少加减多少就行
move_to_element(to_element) ——鼠标移动到某个元素
move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置
perform() ——执行链中的所有动作
release(on_element=None) ——在某个元素位置松开鼠标左键
send_keys(*keys_to_send) ——发送某个键到当前焦点的元素
send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素
向下按鼠标
for i in range(2000):
ActionChains(driver).key_down(Keys.DOWN).key_up(Keys.DOWN).perform()
print(i)from selenium import webdriver
import time
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
#导入ActionChains
from selenium.webdriver import ActionChains
chrome_driver=r"D:\program\Anaconda\envs\Login38\Lib\site-packages\selenium\webdriver\chrome\chromedriver.exe"
driver=webdriver.Chrome(executable_path=chrome_driver)
driver.implicitly_wait(2)
driver.get("https://so.toutiao.com/search?dvpf=pc&source=trending_card&keyword=MSI")
for i in range(2000):
ActionChains(driver).key_down(Keys.DOWN).key_up(Keys.DOWN).perform()
print(i)
time.sleep(3)
#退出
#driver.quit()
对于有些网页不行,因为你自己在那网页上按下键都不行,可能是有隐式弹窗
保存到csv文件中
from selenium import webdriver
import time
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
#导入ActionChains
from selenium.webdriver import ActionChains
import csv
#把数据写入csv文件中
def write(item):
with open(r"jrtt.csv","a") as f:
writer=csv.writer(f)
try:
writer.writerow(item)
except:
print("error")
#获取信息函数
def getinfo():
id_=driver.find_element_by_xpath('//*/div[@class="article-sub"]/span[1]')
time_=driver.find_element_by_xpath('//*/div[@class="article-sub"]/span[2]')
title_=driver.find_element_by_xpath('//*/h1[@class="article-title"]')
text_=driver.find_element_by_xpath('//*/div[@class="article-content"]')
item=[id_.text,time_.text,title_.text,text_.text]
return item
chrome_driver=r"D:\program\Anaconda\envs\Login38\Lib\site-packages\selenium\webdriver\chrome\chromedriver.exe"
driver=webdriver.Chrome(executable_path=chrome_driver)
driver.implicitly_wait(2)
url="https://www.toutiao.com/search/?keyword=selenium"
driver.get(url)
time.sleep(1)
for i in range(2000):
ActionChains(driver).key_down(Keys.DOWN).key_up(Keys.DOWN).perform()
print(i)
time.sleep(1)
url_=driver.find_element_by_css_selector('.title')
print(url_)
#链接列表
url_list=[]
for i in url_:
url_list.append(i.get_attribute('href'))
print(url_list)
#考虑部分可能出错,我们使用try来处理异常
for i in url_list:
try:
driver.get(i)
time.sleep(0.5)
write(getinfo())
driver.get(url)
print("已经写入")
except:
print("error")
time.sleep(3)
#退出
#driver.quit()
PhantomJS
无界面但可以通过脚本编程的WebKit浏览器引擎(高版本selenium不支持,被chrome无头化替代)
windows安装PhantomJS
1、直接下载phantomjs-2.1.1-windows.zip并解压
2、将bin文件夹下的可执行文件phantomjs.exe的路径加入到path中(重启机器后起效)
如果老版本时遇到bug可以通过升级最新版试试
linux安装PhantomJS
1、官网下载phantomjs-2-1-3-linux-x86_64.tar.bz2
2、解压二进制文件
cd /usr/local
tar zxvf phantomjs-2-1-3-linux-x86_64.tar.bz23、创建软链接mysql指向解压出来的文件夹,或将解压出来的文件重命名为PhantomJS
4、执行命令(赋给PhantomJS权限)
ln -sf phantomjs-2-1-3-linux-x86_64/bin/PhantomJS校验安装
PhantomJS -v
chrome无头
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
#chrome_options.add_argument('--headless')
chrome_driver = r"D:\program\Anaconda\envs\Login38\Lib\site-packages\selenium\webdriver\chrome\chromedriver.exe"
driver = webdriver.Chrome(chrome_options=chrome_options,executable_path=chrome_driver)
driver.get("http://www.baidu.com")
发送邮件
去qq邮箱中开启pop3码和授权码

import smtplib,time
from email.message import Message
from time import sleep
import email.utils
smtpserver='smtp.qq.com'
username='xxxx@qq.com'
passsword='这是授权码'
time =email.utils.formatdate(time.time(), True)
def Sendmail(from_addr,to_addr,msg):
message=Message()
message['Subject']=msg['subject']
message['From']=from_addr
message['To']=to_addr
message.set_payload(msg['content']+'\n'+time)
m=message.as_string()
sm=smtplib.SMTP(smtpserver,port=587,timeout=20)
sm.ehlo()
sm.starttls()
sm.ehlo()
sm.login(username,passsword)
sleep(2)
sm.sendmail(from_addr,to_addr,m.encode('utf-8'))
sleep(2)
sm.quit()
return True
if __name__ == '__main__':
from_addr='上面填的账号@qq.com'
to_addr='要发送的账号@qq.com'
msg={'subject':'这是测试','content':'测试'}
Sendmail(from_addr,to_addr,msg)
print("done")
python多线程爬虫
布鲁过滤器
是一个随机映射函数,可用于快速检验一个元素是否在一个集合中,
缺什么库就往https://www.lfd.uci.edu/~gohlke/pythonlibs/ 找
下载https://www.lfd.uci.edu/~gohlke/pythonlibs/
搜索bitarray,

pip insatll 上面的whl
使用伪代码
from pybloom_live import BloomFilter
//读取文件,并返回文件句柄
bf=BloomFilter.fromfile(open("test.blm",'rb'))
//文件不存在则创建文件 容量为20000,错误率为0.001
bf=BloomFilter(20000,0.001)
判断值是否在文件中 if i in bf:
ip代理
ip请求头
待补充

 浙公网安备 33010602011771号
浙公网安备 33010602011771号