Redis系列二:redis常用命令及功能
在redis的介绍中,介绍redis的使用时,示例中就展示了部分的访问jedis的方法,即对应着redis中的命令,以下着重介绍下redis命令。
一、全局命令
keys * 查看所有键,*匹配任意字符多个字符,考虑到是单线程, 在生产环境不建议使用,如果键多可能会阻塞,采用以下渐进式遍历,如果键少,可以
keys *y //以结尾的键
keys n*e //以n开头以e结尾,返回name
keys n?me // ?问号代表只匹配一个字符 返回name,全局匹配
keys n?m* //返回name
keys [j,l]* //返回以j l开头的所有键
dbsize 查看的是当前所在redis数据库的键总数,若量存在大量键,应禁止使用此指令
exists key 检查键是否存在, 存在返回1,否则返回0
del key 删除键,返回删除键的个数,删除不存在的键则返回0
expire key seconds 设置键过期时间,单位是秒
ttl key 查看键剩余的过期时间,和expire配合使用
type key 查看键的数据类型,键不存在则返回none
渐进式遍历示例:
mset a a b b c c d d e e f f g g h h i i j j k k l l m m n n o o p p q q r r s s t t u u v v w w x x y y z z //初始化26个字母键值对
字符串类型:
scan 0 match n* count 20 //匹配以n开头的键,取20条,第一次scan 0开始

第二次从游标10开始取20个以n开头的键,相当于一页一页的取,当最后返回0时,键被取完
注:渐进式遍历可有效地解决keys命令可能产生的阻塞问题
除scan字符串外:还有以下
SCAN 命令用于迭代当前数据库中的数据库键。
SSCAN 命令用于迭代集合键中的元素。
HSCAN 命令用于迭代哈希键中的键值对。
ZSCAN 命令用于迭代有序集合中的元素(包括元素成员和元素分值)。
用法和scan一样
二、Redis键管理
1、键重命名
rename oldKey newKey
rename oldKey newKey //若oldKey之前存在则被覆盖
set name zhangsan;set name1 lisi//初始化数据
renamenx name name1//重命名失效,只有当name1不存在才能改名
2、返回随机键
randomkey
3、键过期
expire name:03 20//键name:03 在10秒后过期
ttl name:03 //查看过期按秒倒计时,当返回-2说明已删除
pttl name:03//查看过期按毫秒倒计时
set name:05 zhangsan
pexpire name:05 20000//20000毫秒(20s)后过期
expire name:06 -2 //直接过期,和del一样
设置键在某个时间点过期,使用的是时间戳
expireat name:04 1566008420//设置在2019/8/17 10:20:20过期
时间转时间戳:网址http://tool.chinaz.com/Tools/unixtime.aspx
hset user:01 name zhangsan //初始化数据
expire user:01 60 //设置60S后过期
ttl user:01 //查看过期剩余时间
persist user:01 //去掉过期
ttl user:1 //返回-1 可以永久查询不失效
注意:对于字符串重设值后,expire无效,
set name zhangsan
expire name 50
ttl name
set name zhangsan1 //此时expire取消
ttl name //返回-1, 长期有效
4、键的迁移
把部分数据迁移到另一台redis服务器
1, move key db //reids有16个库, 编号为0-15
set name james1; move name 5 //迁移到第6个库
select 5 ;//数据库切换到第6个库, get name 可以取到james1
这种模式不建议在生产环境使用,在同一个reids里可以玩
2, dump key;
restore key ttl value//实现不同redis实例的键迁移,ttl=0代表没有过期时间
例子:在A服务器上 192.168.1.111
set name james;
dump name; // 得到"\x00\x05james\b\x001\x82;f\"DhJ"
在B服务器上:192.168.1.118
restore name 0 "\x00\x05james\b\x001\x82;f\"DhJ"
get name //返回james
3,migrate指令迁移到其它实例redis,在1.111服务器上将test移到118
|
migrate |
192.168.1.118 |
6379 |
test |
0 |
1000 |
copy |
replace |
keys |
|
指令 |
要迁移的目标IP |
端口 |
迁移键值 |
目标库 |
超时时间 |
迁移后不删除原键 |
不管目标库是不存在test键都迁移成功 |
迁移多个键 |
三、设置和获取键值的命令
set key value
get key
hset key field value [field value..]
hmget key field [field..]
lpush key value [value..]
rpush key value [value...]
lpop key
rpop key
sadd key member [member...]
srem key member [member...]
zadd key score member [score member...]
zscore key member 获取分数
四、命令执行的顺序
单线程执行:
执行过程:发送指令->执行命令->返回结果
执行命令:单线程执行,所有命令进入队列,按顺序执行,使用I/O多路复用解决I/O问题
单线程快原因:纯内存访问,非阻塞I/O(使用多路复用),单线程避免线程切换和竞争产生资源消耗
五、Redis数据库管理
select 0 //共16个库, 0 --15, select切换数据库
set name james
select 1
get name //隔离了,取不到,和mysql不同库一样
其中redis3.0以后的版本慢慢弱化了这个功能,如在redis cluster中只允许0数据库
原因:
- redis单线程,如果用多个库,这些库使用同一个CPU,彼此会有影响
- 多数据库,调试与运维麻烦,若有一个慢查询,会影响其它库查询速度
- 来回切换,容易混乱
flushdb: 只清空当前数据库的键值对 dbsiz 0
flushall: 清空所有库的键值对 (这两个指令慎用!!!!)
六、Redis查询分析
与mysql一样:当执行时间超过阀值,会将发生时间耗时的命令记录

redis命令生命周期:发送 排队 执行 返回
若redis出现慢查询,正常只会在执行阶段出现,所以嘛查询只统计第3个执行步骤的时间
预设阀值:两种方式,默认为10毫秒
1,动态设置6379:> config set slowlog-log-slower-than 10000 //10毫秒10000微秒
使用config set完后,若想将配置持久化保存到redis.conf,要执行config rewrite
2,redis.conf修改:找到slowlog-log-slower-than 10000 ,修改保存即可
注意:slowlog-log-slower-than =0记录所有命令 -1命令都不记录
原理:慢查询记录也是存在队列里的,slow-max-len 存放的记录最大条数,比如设置的slow-max-len=10,当有第11条慢查询命令插入时,队列的第一条命令就会出列,第11条入列到慢查询队列中, 可以config set动态设置,也可以修改redis.conf完成配置。
2 命令:
获取队列里慢查询的命令:slowlog get 查询返回的结构如下
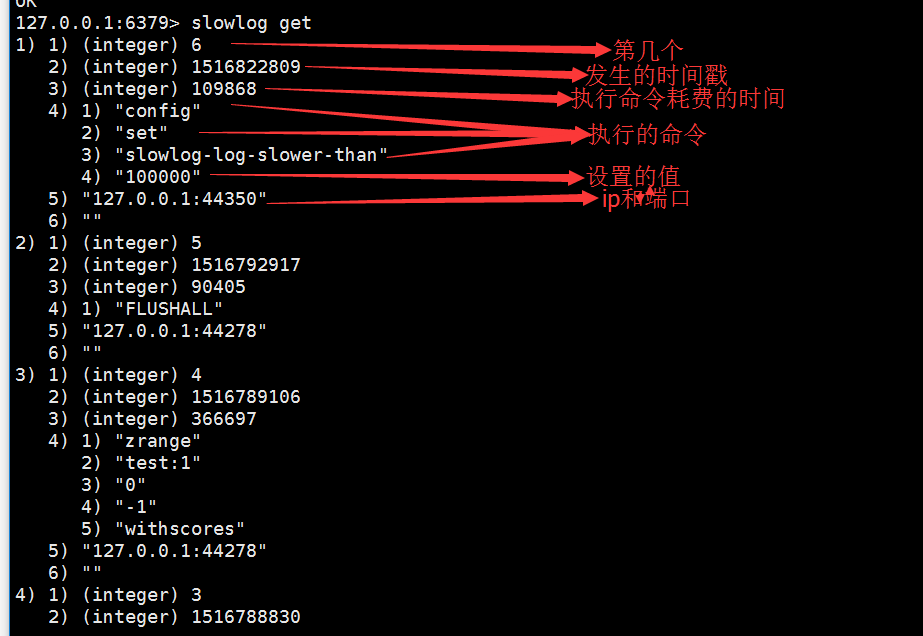
获取慢查询列表当前的长度:slowlog len //返回7

对慢查询列表清理(重置):slowlog reset //再查slowlog len 此时返回0 清空
对于线上slow-max-len配置的建议:线上可加大slow-max-len的值,记录慢查询存长命令时redis会做截断,不会占用大量内存,线上可设置1000以上
对于线上slowlog-log-slower-than配置的建议:默认为10毫秒,根据redis并发量来调整,对于高并发比建议为1毫秒
注意:
1,慢查询只记录命令在redis的执行时间,不包括排队、网络传输时间
2,慢查询是先进先出的队列,访问日志记录出列丢失,需定期执行slow get,将结果存储到其它设备中(如mysql)
六、管道
1.背景:
没有pipeline之前,一般的redis命令的执行过程都是:发送命令-〉命令排队-〉命令执行-〉返回结果。
多条命令的时候就会产生更多的网络开销
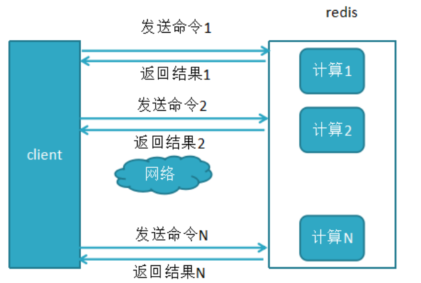
这个时候需要pipeline来解决这个问题:使用pipeline来打包执行N条命令,这样的话就只需简历一次网络连接,网络开销就少了

2. 使用pipeline和未使用pipeline的性能对比:
使用Pipeline执行速度与逐条执行要快,特别是客户端与服务端的网络延迟越大,性能体能越明显
3.原生批命令(mset, mget)与Pipeline对比
1) 原生批命令是原子性,pipeline是非原子性, (原子性概念:一个事务是一个不可分割的最小工作单位,要么都成功要么都失败。原子操作是指你的一个业务逻辑必须是不可拆分的. 处理一件事情要么都成功要么都失败,其实也引用了生物里概念,分子-〉原子,原子不可拆分)
2) 原生批命令一命令多个key, 但pipeline支持多命令(存在事务),非原子性
3) 原生批命令是服务端实现,而pipeline需要服务端与客户端共同完成
4. pipeline正确使用方式:
使用pipeline组装的命令个数不能太多,不然数据量过大,增加客户端的等待时间,还可能造成网络阻塞,可以将大量命令的拆分多个小的pipeline命令完成
如:有300个命令需要执行,可以拆分成每30个一个pipeline执行
七、Redis事务
pipeline是多条命令的组合,为了保证它的原子性,redis提供了简单的事务;redis的事物与mysql事物的最大区别是redis事物不支持事物回滚
事务:事务是指一组动作的执行,这一组动作要么都成功,要么都失败。
1. redis的简单事务,将一组需要一起执行的命令放到multi和exec两个命令之间,其中multi代表事务开始,exec代表事务结束

2.停止事务discard

3. 命令错误,语法不正确,导致事务不能正常执行,即事物的原子性

4. watch命令:使用watch后, multi失效,事务失效,其他的线程任然可以对值进行修改

在客户端1设置值使用watch监听key并使用multi开启事物,在客户端2追加完c之后再来客户端1追加redis,然后执行事物,可以看到在客户端1追加的redis没有起效果:
客户端1:

客户端2:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号