

《Maximum Classifier Discrepancy for Unsupervisied Domain Adapation》 论文研读
摘要
MCD for DA是2018年CVPR的一篇oral文章,提出了一种非常新颖的UDA方法。很多UDA方法采用一个feature generator来接收源域和目标域输入样本,生成的特征被discriminator和task-specific classifier共享。discriminator依据给定的特征来给出域标签,task-specific classifier用来对特征进行分类。这样的UDA方法基于的假设是:由于generator对源域和目标域的分布进行了匹配,由于task-specific classifier对源域的特征可以正确分类,那么对目标域的特征也能做到正确分类。但这样的假设显然是不成立的。
一. Motivation
当前的很多基于对抗学习的UDA方法可用下图进行总结:
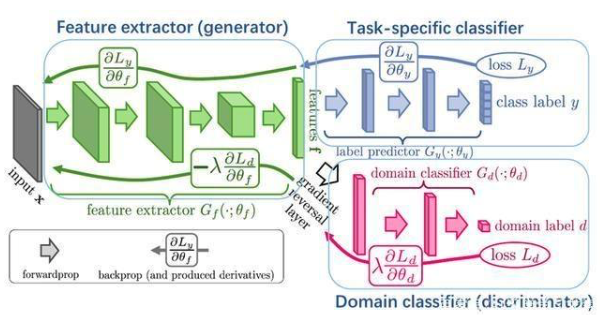
feature generator既接收源域的样本,也接受目标域的样本,提取/生成特征,discriminator依据feature generator提供的特征来给出域标签,feature generator尝试提取能够欺骗discriminator的特征,使其无法判断该特征来自哪个域,而discriminator的目标是分类正确。这样的对抗学习方法,实现了源域和目标域样本特征分布的对齐。当前的方法认为,只要源域和目标域的特征分布是一样的,那么用源域样本训练的分类器,同样也能实现目标域样本的正确分类。
但作者认为这样的假设是存在问题的:
1.虽然利用对抗学习对齐了源域和目标域的样本分布,但由于task-specific classifier是由源域样本训练得到,因此这样的方法没有考虑目标域样本的决策边界,也没有考虑目标域样本之间的关系,因此可能生成较多在决策边界附近的特征,这样的特征是类别模糊的。
2.源域和目标域的特性不相同,难以实现完全对齐。

二. Proposed Method
2.1 目标
对齐源域与目标域样本分布时,能够考虑目标域决策边界以及目标域样本之间的关系。获得一个在目标域上分类分歧最小化的feature generator。
2.2 一些假设
为了实现这一目标,需要检测出目标域中无法得到源域支持的样本。
作者假定:
1.两个不同的分类器对于源域不支持的目标域样本的分类往往不同,也就是说这样的样本容易出现在决策边界附近,从而是类别模糊的。
2.如果feature generator生成的特征可以尽可能减小两个分类器的输出分歧,那么这样的generator就能够防止生成源域不支持的目标域特征。
2.3 损失函数
作者直接采用两个分类器softmax输出概率之差的绝对值作为discrepancy loss:
2.4 实现方法
宗旨:训练两个不同的分类器,使其接收feature generator的特征,并且最大化分类差异: \(d(p_1(y|x_t), p_2(y|x_t))\),其中\(x_t\)指目标域\(\mathcal{T}\)的样本,\(p(·|·)\)是分类器的softmax概率输出。然后再训练特征生成器,最小化分类差异,以生成源域支持的目标域特征。
三个关键步骤:
stepA:
同时训练分类器和生成器,使得分类器能够对源域的样本分类正确。在训练过程中最小化softmax交叉熵:
stepB:
固定特征生成器的模型参数,训练两个分类器来使得增加分类差异。如果缺少这一步,两个分类器会十分相似,无法根据分类差异找到源域不支持的目标域样本,作者在损失函数中增加了在源域上的分类误差来进行约束,否则模型表现会显著降低。这样的损失函数设计,既可以一定程度上保证分类的准确性,又能突出分类模糊的目标域特征。
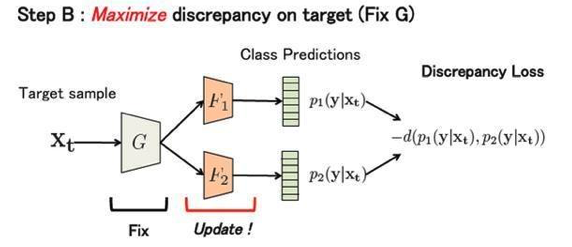
该步的损失函数由如下定义:
stepC:
固定两个分类器的模型参数,改变特征生成器的参数,最小化分类器的分类差异,从而使得特征生成器生成的目标域特征尽可能是在源域的支持范围之内的。
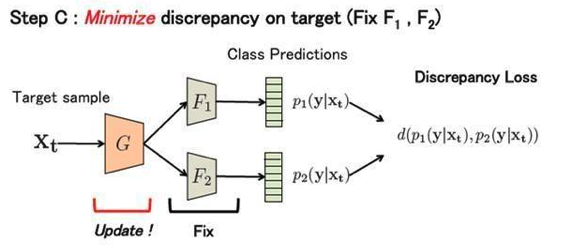
损失函数:
通过迭代重复以上三个步骤来训练模型,stepA的作用在于训练得到的特征生成器和分类器必须是基于能够对源域样本分类正确的大前提下的。
论文所提出模型的设计理念可用下图表示:
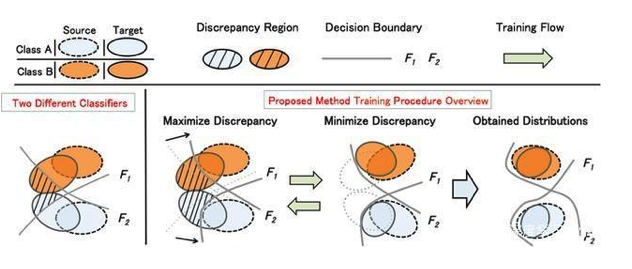
阴影部分是两分类器存在分类差异的部分,也就是分类模糊的样本,也即目标域中源域不支持的样本。然后解决一个minmax问题:首先训练分类器来最大化分类差异,突出分类模糊的样本;然后再训练生成器,最小化分类差异,使得生成器生成的特征在源域的支持范围以内。


