

2019面向对象程序设计第三单元总结
写在前面
OO第三单元是对规格化设计的考验,规格化编程的核心是抽象,只体现“需求”而把具体的实现细节隐藏。三次作业层层递进,最终实现一个较为完善的地铁查询系统。在这一单元中,由于模块较多,所以学会利用JMLUnit单元测试有着重要的意义。
一.JML语言理论基础与应用工具链情况
JML有两种主要的用法:
-
开展规格化设计,交给代码实现人员以逻辑严格的规格,利于实现对接。
-
根据已有代码,书写对应的规格,从而提高代码的可维护性,对代码维护人员有重要意义。
1.语言理论基础知识梳理
\result:表示方法执行所获得的结果,即方法执行后的返回值。
\old(expr):表示执行相应方法前表达式expr的取值。
requires: 该子句定义了方法的前置条件。
assignable:,方法修改的类成员属性。\nothing则表示为该方法为pure的。
ensure:后置条件,如返回的结果或方法运行后的逻辑结果。
public normal_behavior:方法的正常功能部分。
public exceptional_behavior:方法的异常处理部分。
signals:后加表达式,抛出某异常以及抛出异常的条件语句为该表达式,当表达式为真时抛出异常。
signals_only:强调满足前置条件时候抛出相应异常。
invariant:定义一个方法的不变的属性。
2.JML表达式分类
1)原子表达式:\result表达式、\old(expr)表达式、\not_assigned(x,y,...)表达式、\not_modified(x,y,...)表达式、\nonnullelements( container )表达式、\type(type)表达式、\typeof(expr)表达式。
2)量化表达式:\forall表达式、\exists表达式、\sum表达式、\product表达式、\max表达式、\min表达式、\num_of表达式
3)集合表达式:。集合构造表达式的一般形式为:new ST {T x|R(x)&&P(x)},其中的R(x)对应集合中x的范围,通常是来自于某个既有集合中的元素,如s.has(x),P(x)对应x取值的约束。
4)操作符:子类型关系操作符: E1<:E2.
等价关系操作符: b_expr1<==>b_expr2 或者b_expr1<=!=>b_expr2.
推理操作符:b_expr1 ==> b_expr2 或者 b_expr2 < == b_expr1.
变量引用操作符:\nothing指示一个空集;\everything指示一个全集.
3.方法规格
1)前置条件(pre-condition):通过requires子句来表示,是对方法输入参数的限制,如果不满足前置条件,方法执行结果不可预测,方法规格中可以有多个requires子句,是并列关系。
2)后置条件(post-condition):通过ensures子句来表示,是对方法执行结果的限制,如果执行结果满足后置条件,则表示方法执行正确,方法规格中可以有多个ensures子句,为并列关系,实现者必须同时满足有所并列ensures子句的要求。
**3)副作用范围限定(side-effects): **使用关键词assignable或者modifiable,副作用指方法在执行过程中会修改对象的属性数据或者类的静态成员数据,从而给后续方法的执行带来影响,必须要明确给出副作用范围。
4.类型规格
类型规格主要有不变式限制和约束限制两种。
1)不变式(invariant):是要求在所有可见状态下都必须满足的特性。
2)状态变化约束(constraint):用constraint对前序可见状态和当前可见状态的关系约束,invariant和constraint可以直接被子类继承获得。
5.应用工具链
1)OpenJML: 能进行JML语法检测、静态检查等一系列工作。
2)JMLUnitNG:主要用于单元化测试,可以自动生成测试数据检测方法是否符合规格。
二.部署SMT Solver
SMT Solver即为定理证明器,部署好OpenJML后,对MyPath.java进行规格检查:
java -jar openjml.jar -check MyPath.java
运行结果如下:

可见调用了非pure的函数size(),导致报错
再利用-esc 进行静态检查:
java -jar openjml.jar -esc MyPath.java
运行结果如下:

去掉this后即不报错。
使用体验:
使用OpenGML的体验不佳,这个软件仍然不太成熟,IDEA上也没有支持的插件,可见不太主流。
三.部署JMLUnitNG/JMLUnit
JMLUnitNG是是一个用于JML注释的Java代码的自动化单元测试生成工具,继承于TestNG。比如生成MyRailWaySystem的测试用例
java -jar jmlunitng.jar -cp .;specs-homework-3-1.3-raw-jar-with-dependencies.jar MyRailWaySystem.java
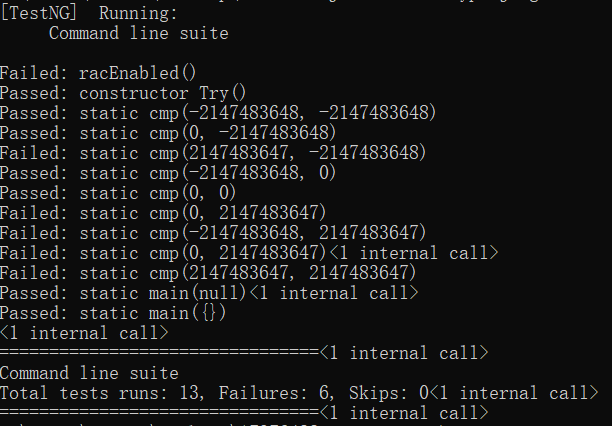
自动化测试:
以下是我的测试代码:
public class Try {
/* @ public normal_behavior
@ requires (a < 1000 && b < 1000);
@ ensures (\result = (a < b));
@ also
@ public exceptional_behavior
@ requires (a >= 1000 || b >= 1000);
@ signal_only Exception;
*/
public static boolean cmp(int a, int b) throws Exception {
if (a >= 1000 || b >= 1000) {
throw new Exception();
}
return a < b;
}
public static void main(String[] args) {
try {
cmp(99, 100);
cmp(122, 88);
cmp(1000, 99);
cmp(99, 10000);
cmp(1000, 10002);
} catch (Exception e) {
e.printStackTrace();
}
}
使用JMLUnitNG生成测试文件:
#!/bin/bash
java -jar jmlunitng.jar "$@"
javac编译后文件目录如下:

运行结果如下:
四.三次作业的设计思路
Ⅰ.第一次作业设计(MyPathContainer的实现)
思路:1.将数目较多的路径查询指令的时间复杂度分散到路径增删指令中。
2.使用HashMap与HashSet将查询复杂度降至O(1)附近,只在路径增删时维护容器
我的实现:在PathContainer中,用以下三个容器记录路径、路径id已经节点信息
private HashMap<Path, Integer> pmap = new HashMap<>();
private HashMap<Integer, Path> pidMap = new HashMap<>();
private HashMap<Integer, Integer> nodeMap = new HashMap<>();
其中pmap存储的是Path与PathId的键值对,nodeMap中存储着节点在所有路径中的总出现次数。这三个容器只需要在增删路径时进行维护。而在查询时,时间复杂度接近O(1).
例如,在查询path对应的路径ID时,利用pidMap中存储path->pathId键值对,可以直接利用HashMap的get方法直接获取路径对应的PathId。
public int getPathId(Path path) throws PathNotFoundException {
if (path == null || !path.isValid() || !containsPath(path)) {
throw new PathNotFoundException(path);
} else {
return plist.get(path);
}
}
在查询不同节点的总数目时,只需要返回nodeMap中key的数目即可。
public int getDistinctNodeCount() {
return nodeMap.size();
}
而对于Path类,我们可以认为其是静态的,所以在初始化时用一个HashSet来储存不同节点,在查询路径所含不同节点数目时,则可以之间返回其大小,查询复杂度为O(1).
private HashSet<Integer> set;
初始化时:
set = new HashSet<>(nodes);
查询:
public int getDistinctNodeCount() {
return set.size();
}
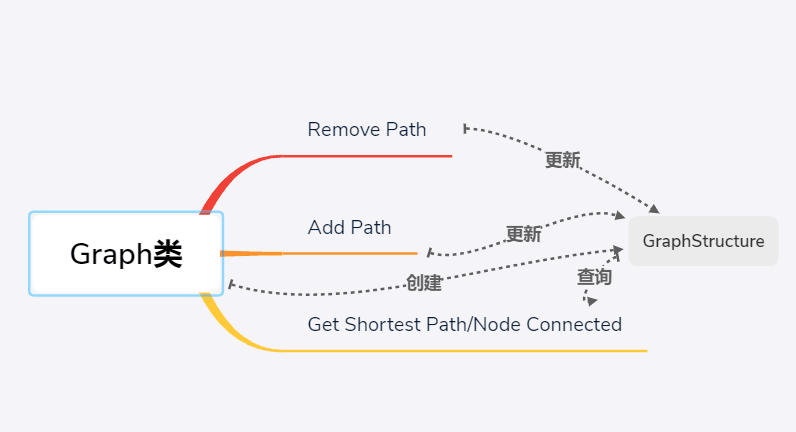
Ⅱ.第二次作业设计(MyGraph的实现)
在第二次作业中,核心设计为 isConnected与getShortestPathLength这两个函数的设计。
对于最短路径的查询,我使用了广度优先搜索的方法一次性把全部节点之间的最短路径全部算出。这样只需要在增删路径时进行一次更新,而查询的时间复杂度依然接近O(1).
思路:将数目较多的最短路径查询指令的时间复杂度分散到路径增删指令中,将时间复杂度分散到本就无法降低复杂度的写指令以及线性复杂度指令中,记录中间结果。
我的设计思路大体如下:
其中本次作业的核心在于最短路径的求法,根据我们所学的数据结构,主流方法有以下三种:
1.基于优先队列或堆优化的Dijkstra(推荐)
2.Floyd/SPFA
3.BFS
其中对经过满规模数据测试,基于优先队列或堆优化的Dijkstra是最快的,但为了测试最坏时间复杂度,我使用了BFS的方法,在每次路径增删时记录任意两个节点的最短路径,实现如下:
void bfs() {
Set<Integer> nodeSet = map.keySet();
Iterator<Integer> nodeIt = nodeSet.iterator();
while (nodeIt.hasNext()) {
int depth = 1;
Integer node = nodeIt.next();
Queue<Integer> queue = new LinkedList<>();
Queue<Integer> nextQueue = new LinkedList<>();
queue.add(node);
while (!queue.isEmpty()) {
int nextNode = queue.poll();
HashMap<Integer, Integer> keyMap = map.get(nextNode);
Set<Integer> set = keyMap.keySet();
Iterator<Integer> it = set.iterator();
while (it.hasNext()) {
int endNode = it.next();
if (endNode != node) {
Relation newKey = new Relation(node, endNode);
if (!distance.containsKey(newKey)) {
distance.put(newKey, depth);
nextQueue.offer(endNode);
}
}
}
if (queue.isEmpty()) {
queue = nextQueue;
nextQueue = new LinkedList<>();
depth += 1;
}
}
}
}
III.第三次作业设计(MyRailwaySystem的实现)
这次作业对数据结构的要求比较高,新增的查询连通块个数、查询最少换乘、查找最小不满意度、查找最小票价的功能,用到了BFS、DFS、Dijkstra等多个算法。
利用优先队列或堆对Dijkstra进行优化,如果使用拆点,避免使用O(n3)的Floyd,注意记录中间结果,这样能在后期的查询中不断进行加速。将查询指令的时间复杂度分散到50条路径增删指令中。
以下是我的大体实现思路:
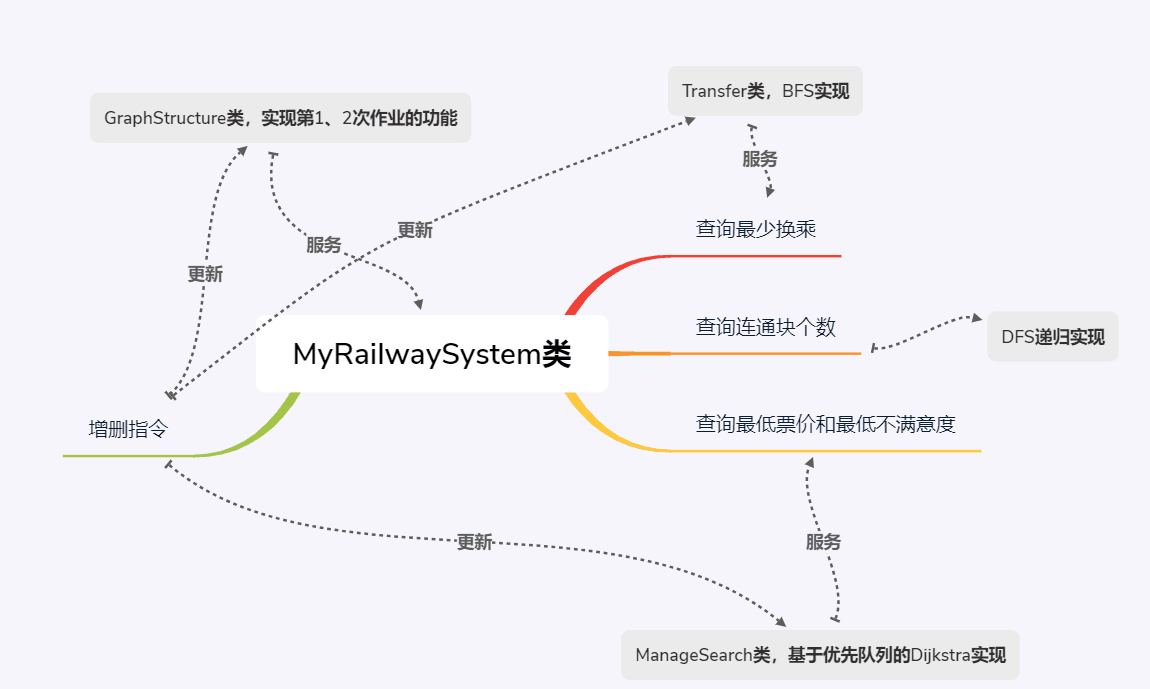
本次作业的核心难点在于最低票价和最小不满意度的计算,我们之前用到的数据结构不进行微调无法直接使用,我使用了Dijkstra拆点的方法。
对于每条路径,在增删时要特别维护换乘站的连通状况,对于换乘站,其节点Id相同,但路径Id不同,对于这样的节点,视其为不同节点,所以可以认为,不存在相同节点。
故需要新建节点类如下。Node类保存着节点Id信息、路径Id信息以及节点满意度信息。
public class Node {
private int nodeId;
private int pathId;
private int satisfy;
......
}
对于两条路径上的换乘节点,这两个具有相同nodeId的节点,其票价边权为2,不满意度边权为32,这样我们就可以通过Dijkstra进行最低票价和最小不满意度的计算,并保存计算结果。
利用优先队列进行Dijkstra的优化:
需要使用Comparable接口
public class MyEdge implements Comparable<MyEdge> {
private Node toNode;
private int cost;
MyEdge(Node toNode, int cost) {
this.cost = cost;
this.toNode = toNode;
}
@Override
public int compareTo(MyEdge o) {
if (cost < o.cost()) {
return -1;
} else if (cost == o.cost()) {
return 0;
} else {
return 1;
}
}
int cost() {
return this.cost;
}
Node getToNode() {
return this.toNode;
}
}
重写完compareTo方法后,便可以直接使用优先队列,利用具有O(logn)时间复杂度的优先队列进行优化,可以降低CPU时间。
Queue<MyEdge> queue = new PriorityQueue<>();
本次作业我并没有使用静态数组,静态数组的修改查询会非常快,但在工程上是不建议大量使用静态数组的,其可维护性较差,而且在互测中的WA很多是由于静态数组没有处理好造成的。
五.基于类图、基于度量的分析
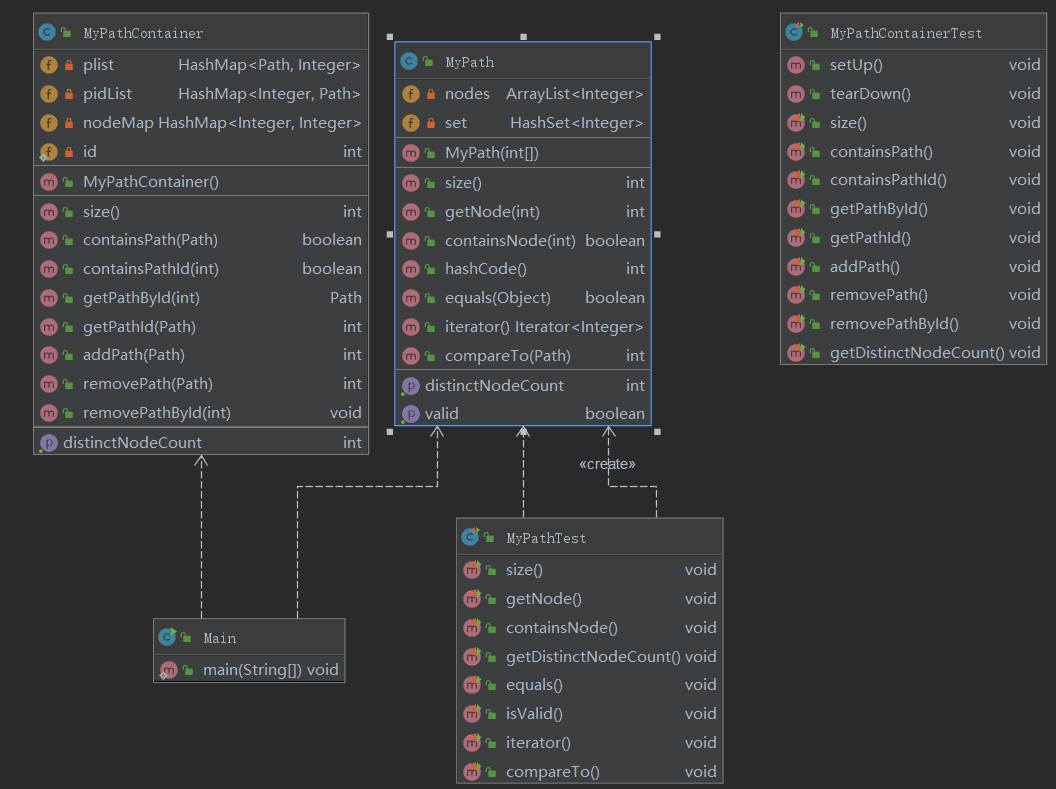
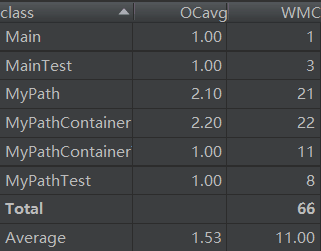
Ⅰ.第一次作业
类图:
度量分析:
注:
ev(G)为Essentail Complexity,表示一个方法的结构化程度
iv(G)为Design Complexity,表示一个方法和他所调用的其他方法的紧密程度
v(G)为循环复杂度
OCavg为平均循环复杂度
WMC为总循环复杂度

Ⅱ.第二次作业
类图:
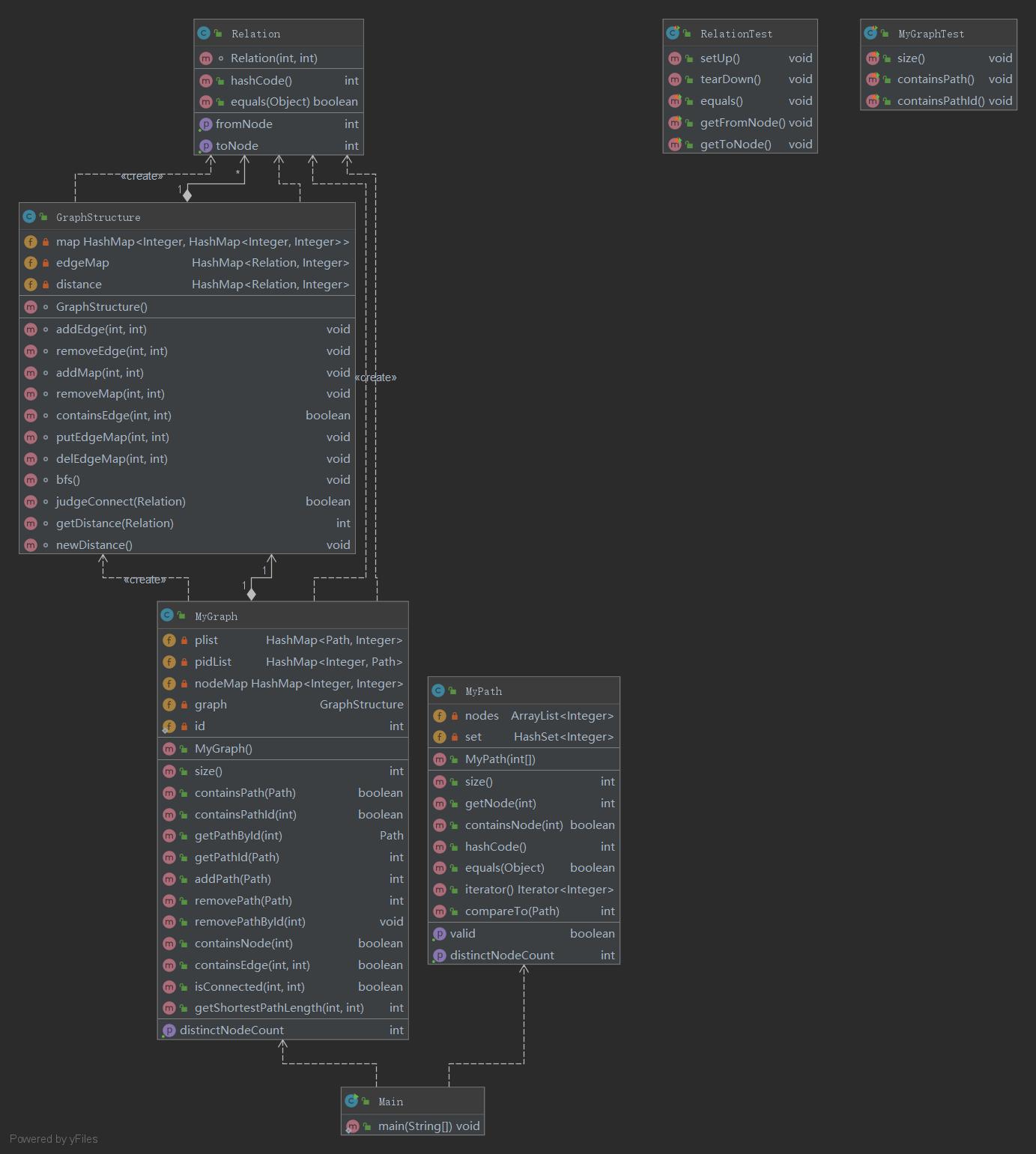
度量分析:
注:
ev(G)为Essentail Complexity,表示一个方法的结构化程度
iv(G)为Design Complexity,表示一个方法和他所调用的其他方法的紧密程度
v(G)为循环复杂度
OCavg为平均循环复杂度
WMC为总循环复杂度
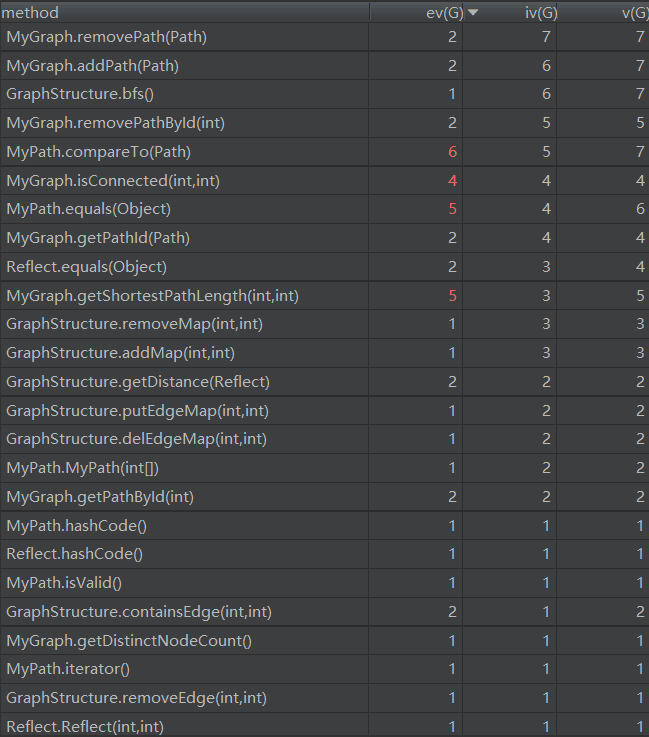
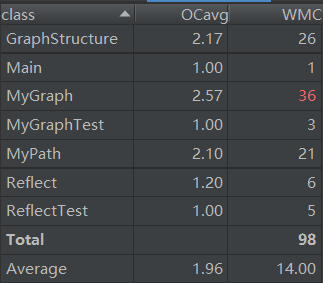
III.第三次作业
类图:
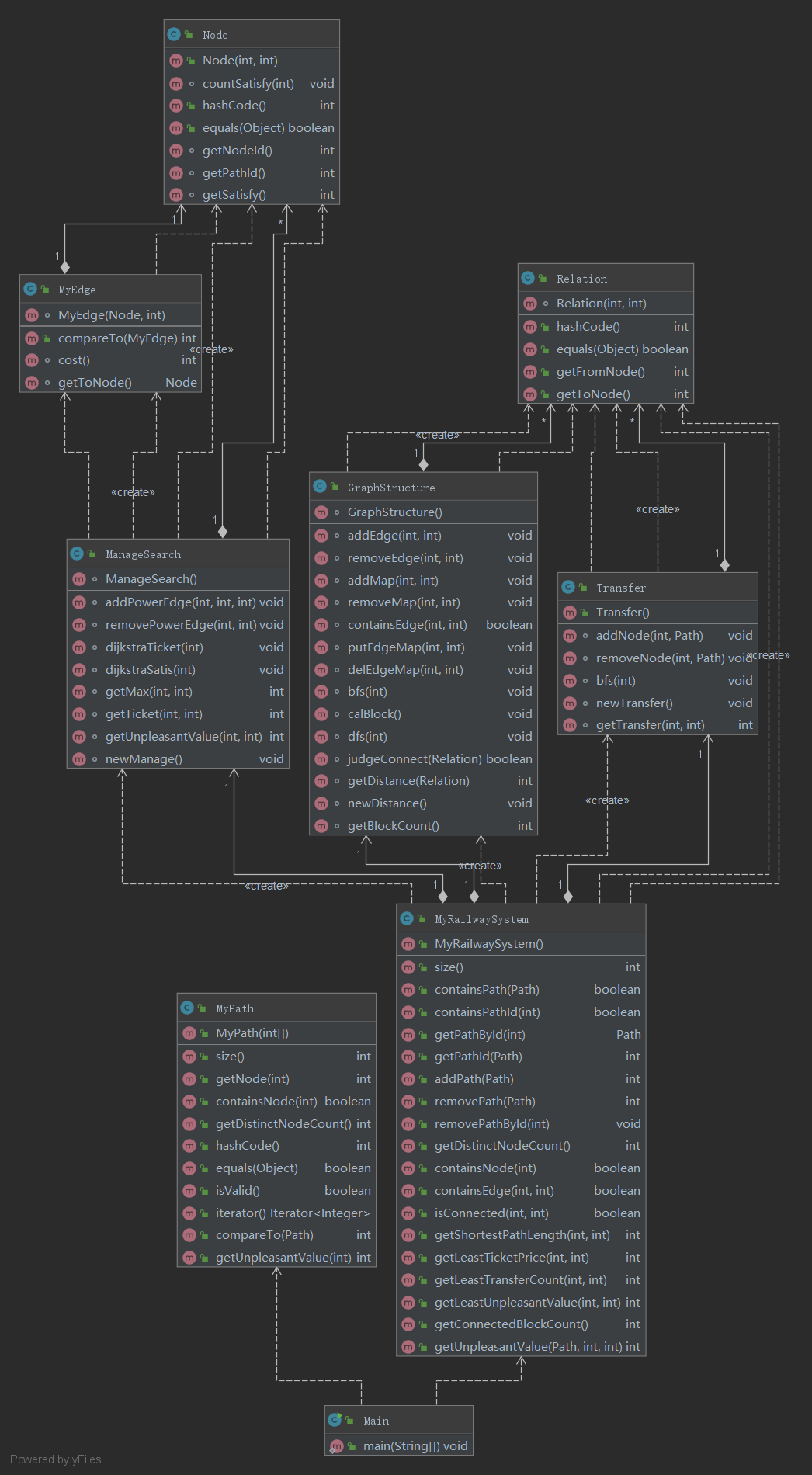
度量分析:
注:
ev(G)为Essentail Complexity,表示一个方法的结构化程度
iv(G)为Design Complexity,表示一个方法和他所调用的其他方法的紧密程度
v(G)为循环复杂度
OCavg为平均循环复杂度
WMC为总循环复杂度
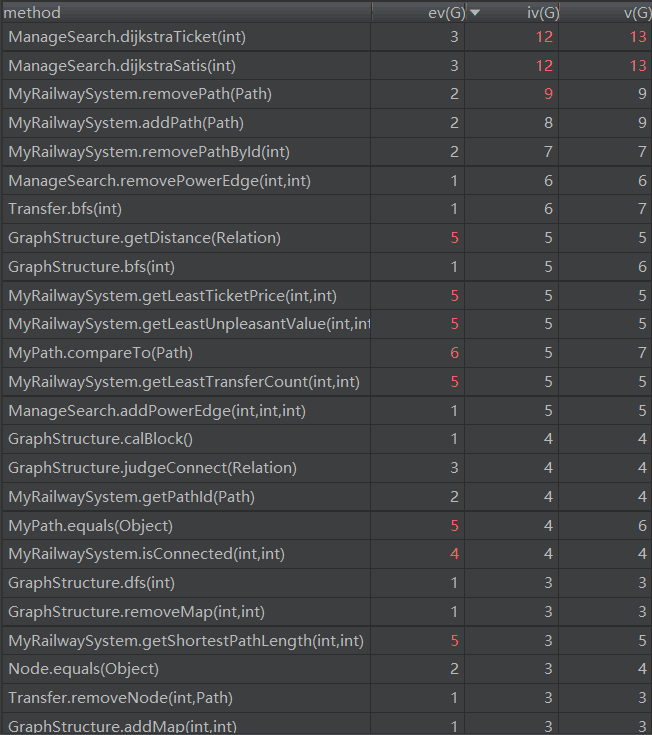
六.基于Solid原则的评价
1.SRP(Single Responsibility Principle):
我的程序设计每个类与方法各司其职,与单一功能原则相符。按照JML对各个方法的规范,以及各个类功能的明确性,使得在规格化设计单元中,我对SRP原则进行了较好的实现。
2.OCP(Open Close Principle):
开闭原则:类,模块,函数等应该对于扩展是开放的,但是对于修改是封闭的。
本单元我没有重构,而是每次作业在上次作业的基础上进行拓展,每次作业的系统功能只增不减,因此我进行了相应的继承,对一些类进行了微调。本单元三次作业我的设计可拓展性是比较好的。
3.LSP(Liskov Substitution Principle), ISP(Interface Segregation Principle)and DIP(Dependency Inversion Principle):
本单元我用的继承与接口不多,这也是我需要进一步改进的地方,我的个别类较为庞大,应该设置一个抽象类,将一部分基础功能放在抽象类下,然后后面的作业进行继承或维护。在第三次作业中,我在第二次作业基础上,新建了一个类来实现新的功能,而没有进行相应拓展,这是我需要进一步思考的地方。
总结:
本单元我的设计较好的符合SRP和OCP原则,但使用的继承与接口不多,在之后的作业中,这是我在设计层面上需要进一步思考的部分。
七.BUG分析
在本单元三次作业中,我强测和互测均未出现bug或被hack。
但在第三次作业公测结束之前的自主测试中,通过数据轰炸,我找到了自己的一处最少换乘的bug。其由于我在BFS实现时,在某节点记录最短路径信息后、入队之前没有标记为已访问,而在出队时才标记为已访问,导致在该节点出队前,若其他节点的出链中含有这一节点,则会更改其最少换乘信息,导致最少换乘数可能会偏大。可见自主测试是非常重要的。
另外,我在互拍过程中也发现了朋友们的几处bug,例如静态数组在数据轰炸时越界抛异常、以及没有按照JML要求实现函数功能导致错误。
八.互测中的hack策略
1.自动评测
1).数据自动生成--分级生成法
1°进行指令分类
instructions1 = [
"PATH_ADD", # 节点序列
"PATH_REMOVE", # 节点序列
"PATH_REMOVE_BY_ID", # id
]
nodes_graph = {}
distance = {}
instructions2 = [
"PATH_GET_ID",
"PATH_GET_BY_ID",
"CONTAINS_PATH",
"COMPARE_PATHS"
]
instructions3 = [
"PATH_COUNT", # 空
"PATH_SIZE", # id
"PATH_DISTINCT_NODE_COUNT", # id
"CONNECTED_BLOCK_COUNT", # 空
"CONTAINS_PATH_ID", # id
"PATH_CONTAINS_NODE", # id 节点
"CONTAINS_NODE", # id 节点
"LEAST_TRANSFER_COUNT", # 节点 节点
"LEAST_TICKET_PRICE", # 节点 节点
"LEAST_UNPLEASANT_VALUE", # 节点 节点
"SHORTEST_PATH_LENGTH",
"DISTINCT_NODE_COUNT"
]
2°指令与节点序列拼接
def make_instruction():
for instr in instruction_list:
count, lst = instr[0], instr[1]
if count == 311:
string = instructions3[10] + " "
for item in lst:
string = string + str(item) + " "
input_list.append(string)
elif count == 312:
string = instructions3[11] + " "
input_list.append(string)
else:
count1 = count // 10
count2 = count % 10
if count1 == 1:
string = instructions1[count2 - 1] + " "
elif count1 == 2:
string = instructions2[count2 - 1] + " "
else:
if count2 == 0:
count2 += 10
string = instructions3[count2 - 1] + " "
for item in lst:
string = string + str(item) + " "
input_list.append(string)
3°数据生成总控
def gen_data():
while instr1 + instr2 + instr3 != 7000:
# instruction type1
if instr1 == 20:
if instr3 != 6500:
random3()
continue
else:
random2()
continue
# instruction type2
if instr2 == 480:
if instr1 != 20:
random1()
continue
else:
random2()
continue
if instr3 == 6500:
if instr1 != 20:
random1()
continue
else:
random2()
continue
num = random.random()
if num < 0.03:
random1()
elif num < 0.1:
random2()
else:
random3()
4°下级数据生成控制:以图变更指令为例
def random1():
num = random.randint(-10, 3)
# PATH_ADD
if num <= 1:
judge, result = random1_1()
# PATH_REMOVE
elif num == 2:
judge, result = random1_1()
# PATH_REMOVE_BY_ID
else:
judge, result = random1_1()
if judge is False:
pass
else:
global instr1
instr1 += 1
instruction_list.append(result)
5)底层数据生成:以PATH_ADD为例
# PATH_ADD
def random1_1():
lst = []
for i in range(node_length):
num = random.randint(0, 115)
lst.append(num)
if lst in nodes_list:
output_list.append("Ok, path id is {}.".format(nodes_list.index(lst) + 1))
return True, [11, lst]
else:
nodes_list.append(lst)
global id
id += 1
id_list.append(id)
output_list.append("Ok, path id is {}.".format(id))
for i in range(0, len(lst) - 1):
add_edge(lst[i], lst[i + 1])
add_edge(lst[i + 1], lst[i])
bfs()
return True, [11, lst]
2).正确性检查
1°标准化检查(1、2次作业):
使用python正确实现一遍作业,然后利用程序输出进行正确性检查。
f = open("standard.txt", "w")
for line in output_list:
f.write(line + "\n")
f.close()
2°互拍:
将每个人的输出导入文件中,然后进行逐行比较。
f = open(r'C:\Users\Lenovo\PycharmProjects\OO评测机JML\Assassin11\Assassin_output.txt', "r")
lines_out = f.readlines()
f.close()
len1 = len(lines_standard)
len2 = len(lines_out)
if len1 != len2:
print("Assassin lines number dismatch")
break
else:
flag = 1
for i in range(len1):
line1 = lines_standard[i].strip()
line2 = lines_out[i].strip()
if line1 != line2:
print("Assassin in the line {}, different!!!".format(i + 1))
flag = 0
break
if flag == 1:
print("You are the same with wyb")
else:
break
支持CTLE的检查:
2.精心构造测试数据
1°利用Junit进行单元评测
2°针对性构造数据
使用静态数组且架构不好程序容易被多个PATH_ADD与PATH_REMOVE的0查询序列卡爆,多次add path与remove path后再进行查询容易出问题。
提供一个简单但有针对性测试样例如下:
PATH_ADD 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 20 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80
PATH_ADD 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 20 30 31 32 33 34 35 36 37 38 39 40 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120
PATH_REMOVE 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 20 30 31 32 33 34 35 36 37 38 39 40 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120
PATH_ADD 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 20 30 31 32 33 34 35 36 37 38 39 40 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159
PATH_REMOVE 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 20 30 31 32 33 34 35 36 37 38 39 40 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159
PATH_ADD 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 20 30 31 32 33 34 35 36 37 38 39 40 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199
PATH_REMOVE 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 20 30 31 32 33 34 35 36 37 38 39 40 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199
PATH_ADD 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 20 30 31 32 33 34 35 36 37 38 39 40 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239
PATH_REMOVE 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 20 30 31 32 33 34 35 36 37 38 39 40 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239
SHORTEST_PATH_LENGTH 1 11
LEAST_TRANSFER_COUNT 1 15
LEAST_TICKET_PRICE 5 10
LEAST_UNPLEASANT_VALUE 2 16
九.心得体会
在规格化设计这一单元中我收获很多,尤其是学习了JML契约式设计的思想,JML规格隐藏了具体实现,同时让方法的编写者有了一个明确的目标。尤其在多人协作的过程中,使用JML来消除二义性并进行逻辑上的规范是必要的。但是在第三次作业中,部分方法复杂度过高,因此对于一些方法,我首先按照函数名和指导书的描述产生对函数自己的理解,然后根据自己的理解再读JML验证自己理解的正确性,而不是直接阅读JML产生思路。
我个人认为,JML和自然语言各有优势,对于实现非常简单的函数,使用自然语言描述简单明了;对于功能复杂的函数,使用JML描述可以避免自然语言的二义性。本单元中只对给出的代码写简单的JML,或者完全根据JML补充方法代码,并没有撰写大项目的代码规格。但未来参加大型项目需要分工完成时,学习好JML的重要性就体现出来了。JML没有束缚算法的具体实现,因此在第三次作业中,除了Dijkstra、Floyd这些算法,讨论区还出现了许多很棒的算法思路。编写一个能满足OpenJML运行环境的规格,比按照规格编写程序更为复杂,以后甚至可以在第9次作业设置一个OpenJML的附加测试。
本单元中,自主测试比前两个单元更为重要,在本单元中,我利用了OpenJML、Junit、脚本轰炸性测试等多种测试方式对作业进行评测,极大程度上保证了正确性和性能。这一单元的体验比上两个单元的体验更好,每次作业都保留了前面作业的功能,引发大家对如何保证程序架构可拓展性的思考。
文末感谢老师和助教们的辛勤付出,祝北航OO越来越好。


