服务编排
2021-06-23 11:47 熬夜的虫子 阅读(10787) 评论(0) 收藏 举报一. 背景
- 应用系统的架构演变随着业务的越来越复杂,需要更多的思考、更高维度的抽象。
- 将组织逻辑与业务实现分离,使业务应用更关注自身的领域内容。
二. 目标
将业务流程可视化、最终展现出全局业务视图,并可以动态调整业务链路。结尾附上示例代码。
大部分现行的系统都是通过繁荣的代码来实现业务逻辑的拼装,当业务变得极其复杂的时候会变得可读性极差,可维护性降低。
服务编排的理想目标是开发人员只注重简单接口(行为)的开发,业务人员可以通过编排系统实现应用及系统的组装和运维。简单一点理解的话就是讲服务化衍进为工具化(理想状态,现实很难)。
三. 产出
- 一个中心化的流程配置站点,效果如图(引用zeebe的系统图)

- 一个轻量级的编排网关,使用网关模式(中心化)、业务接口将不直接暴露服务,所有请求由网关组织,类似总线模式。优点在于对于新的应用,开发者只需关注自己的原子功能实现,缺点在于对于旧的应用,部分业务接口需要拆解改造。
- 一个客户端代理,使用代理模式(非中心化)、中心化的配置站点根据版本下发规则文件,需要在各自应用系统中引用代理组件,可以自动/按需进行服务组织调用与上下文适配。
ps:对于网关模式和代理模式一般只需要采取1种,具体根据自己的实际场景选择。
四. 与工作流区别
- 从实现方向上来说,工作流引擎的核心实现是一种状态机、可以理解成一套中心化的服务;服务编排的核心是一套开发框架,它依赖接入应用的具体场景。
- 从业务方向来说,工作流引擎侧重构建定义执行过程,强调规范、快速开发;服务编排侧重业务建模、组装、部署及管理。
- 从使用场景来说,工作流引擎一室现在最大的使用场景为办公自动化;服务编排可以理解成SOA的产物。
五. 应用场景分析
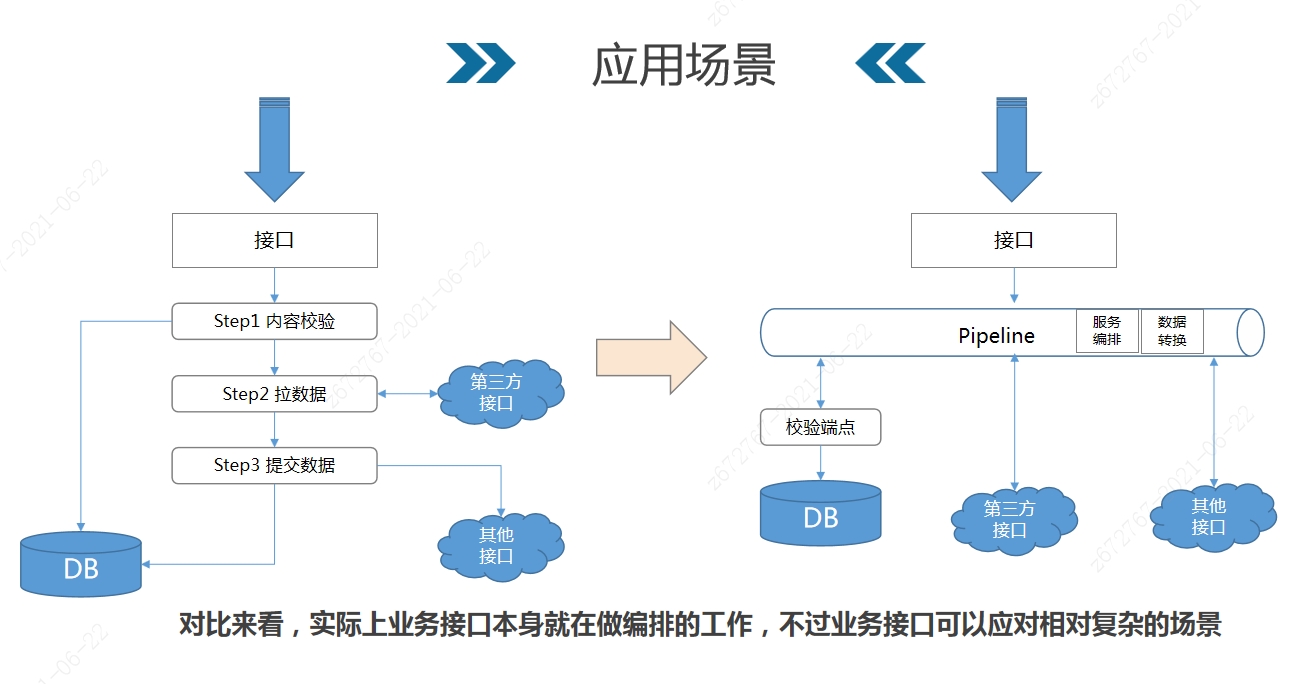
简单的来说,这种场景对应网关模式,无需代码侵入,由编排网关统筹管理服务调度,粒度可以足够的细,一次db操作,一次文件操作,一次接口调用都可以作为调度的基本单元。端点的概念在后面实现里会讲。
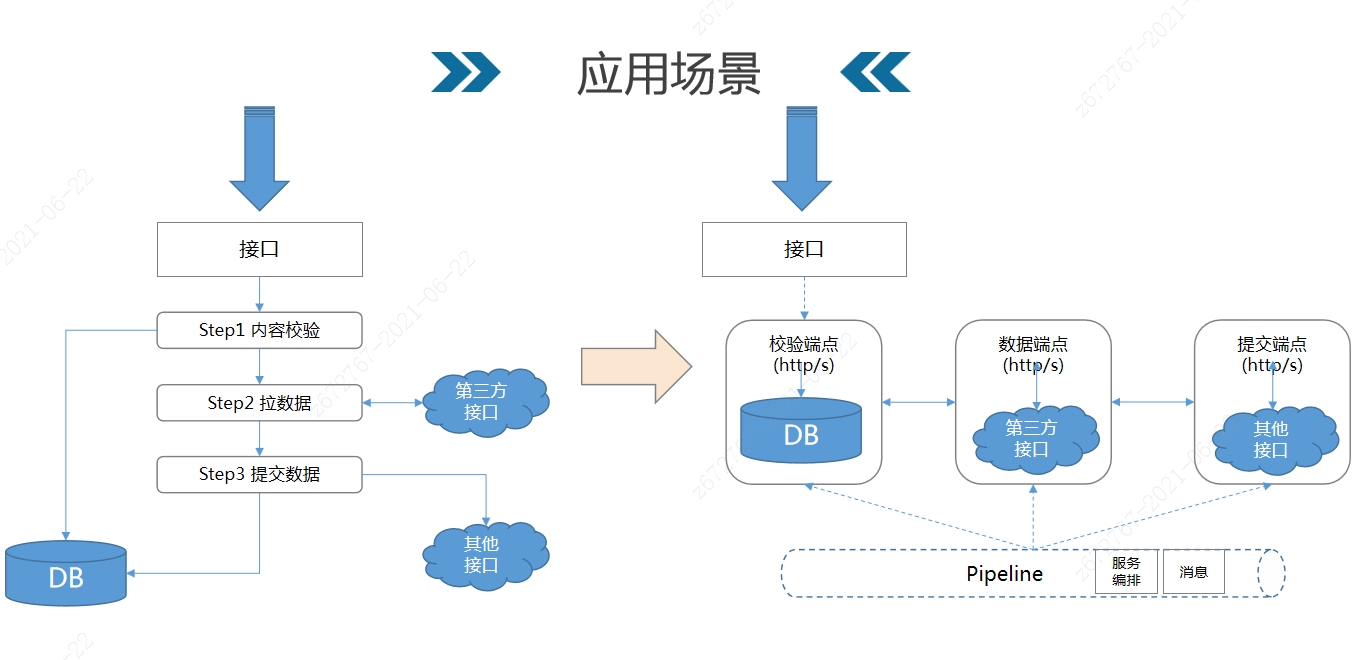
这种场景为代理模式,需要少量的代码侵入,侵入部分为编排的组件代理,这种模式可以解决中心化的问题,各自应用自己治理。

宏观的概念为企业应用模式,通过编排引擎将应用系统、数据资源和互联网资源组成一个统一的整体。看起来是不是和ESB有点像,很快我们会总结和ESB的差异。

核心模块参考Netflix conductor 、Zeebe、Apache Camel等成熟产品 结合我们自己业务特性,目标为轻量级、可扩展、组件化的设计模式。
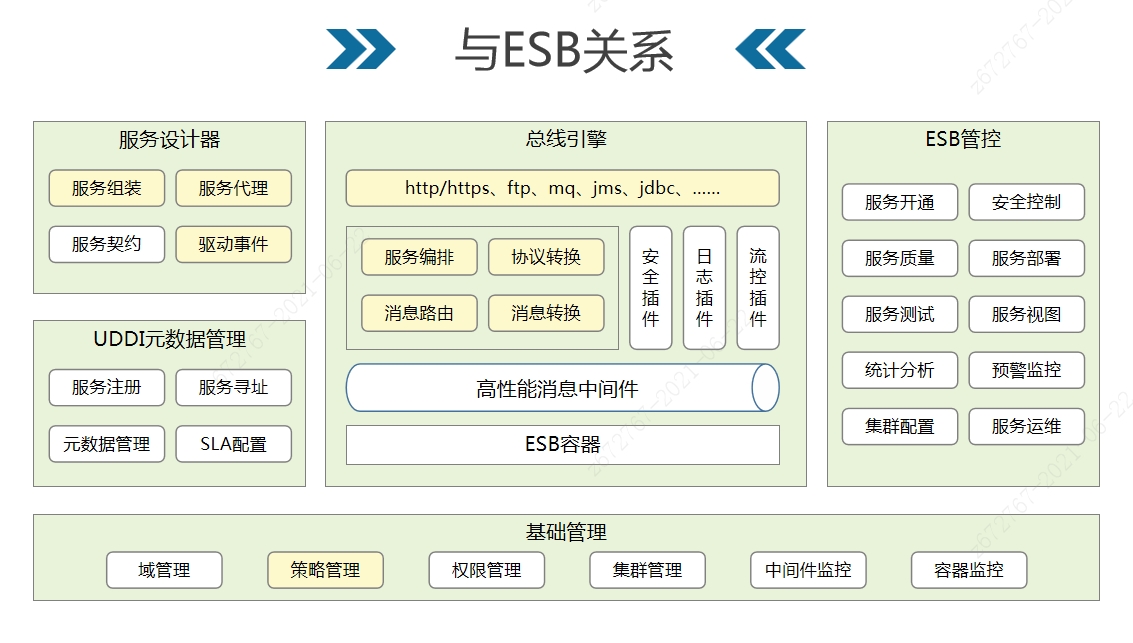
黄色的部分就是服务编排组件和ESB产品重叠的内容,服务编排组件相当于是ESB产品成熟架构之上的一些功能拆解,并逐渐衍生为更贴合互联网主流技术(例如微服务)的替代方案。

上面我们聊了2种模式,我们通过管道与业务域的关系来解释部署方案的差异
管道是消息传递的载体。由于编排引擎的核心为组件化的实现方式,其部署的方式相对灵活。
1. 管道的范围决定了业务域的大小 高纬度能以整个团队业务为维度,低纬度能以个别应用为维度。
2. 中心化部署 好处是可以避免下层应用代码的侵入并集中管理
3.非中心化部署 非中心化部署有2种方式
i)第一种为代码植入,这种方式不依赖管道作为消息载体,每一个植入应用都属于消息载体,并直接管理上下文。
ii)第二种为ServiceMesh的边车模式,将控制与业务分离。好处是无需进行代码侵入,缺点是当前环境该模式并不成熟,容易带入运维成本。
除了路由可视化,还可以利用JMX实现扩展管理,Mbean中包含了所有可更新对象。 消息管道中按每笔事件定义通信ID,通信ID在一次传递过程中不会变化,其中包含版本信息。 新版本的产生不会影响到旧的事件。
六. 核心组件实现
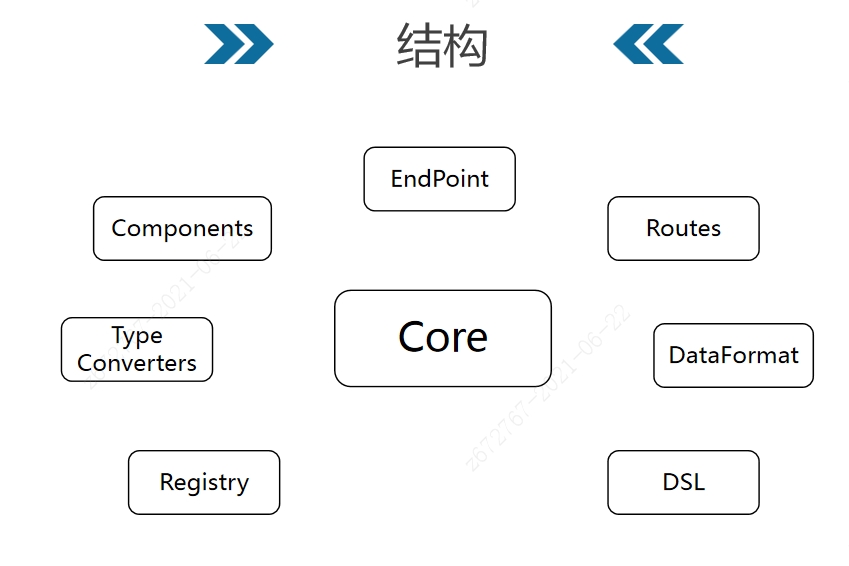
重点参考开源产品Apache Camel。最核心的是DSL语言、端点、组件、路由、注册表、格式转化。

DSL 其实是 Domain Specific Language 的缩写,相对DSL的定义就是 GPL(General Purpose Language)
常见的DSL有SQL、Regex ,常见的GPL有Objective-C、Python...
DSL 最大的设计原则就是简单,通过简化语言中的元素,降低使用者的负担设计语法和语义。Camel组件中设计DSL语法和语义,定义 DSL 中的元素并实现 parser,对 DSL 解析,最终通过解释器来执行。目前支持Java DSL和XML DSL。其核心定义就是描述了一次路由行为的上下文、内容、类型、依赖、逻辑等等。运行时编排系统就会载入实现定义的DSL文件,会按照DSL文件中定义的路由行为来执行。
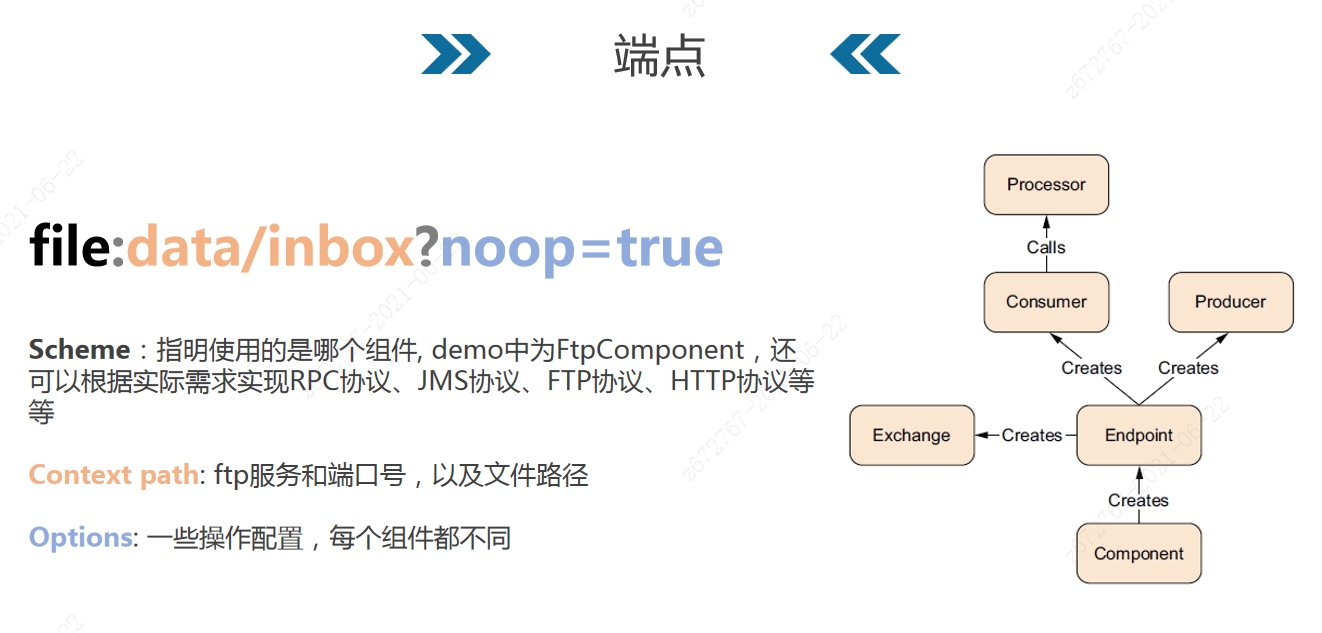
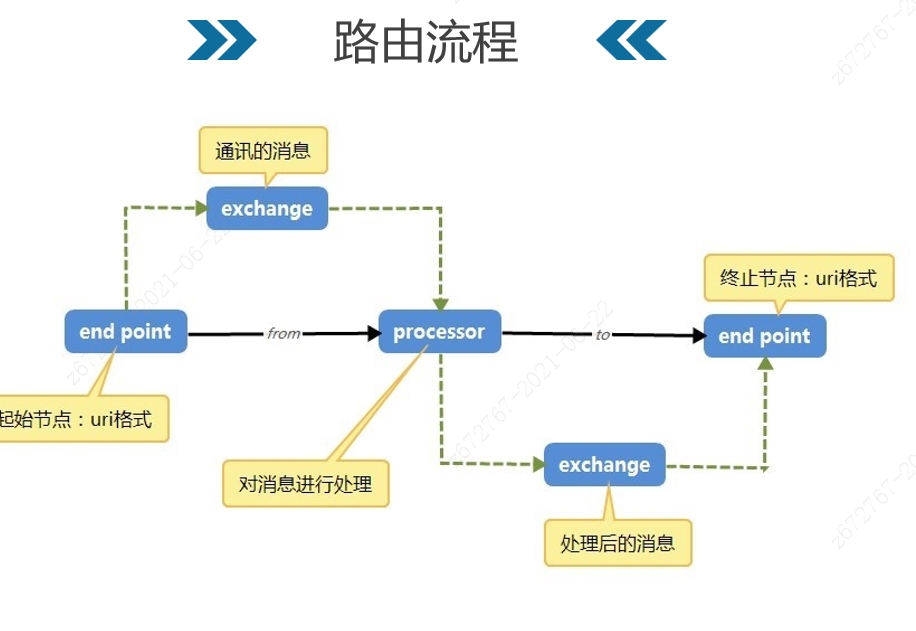
回到上面提出的问题,什么是端点(Endpoint)。端点是camel的抽象概念。可以理解成信道末端模型,系统可以利用信道收发消息。更通俗一点来讲,你可以将端点理解成一次通信行为的支撑/目标支点。这个支点可以支持非常多的协议,例如http、ftp、rpc等等等等。这从基础上就决定了我们的通信信道不仅仅可以支撑现在常用的服务/微服务场景,更能从更多底层元素来运作编排行为。
但是端点需要满足一定的规则要求,首先是路由Url,示例中的file代表Scheme,定义了端点的协议类型。Context path定义通信的路径及端口等。Options定外额外的一些扩展信息,根据协议和场景的特殊性可以自定义逻辑和内容。
端点还关联着生产者、消费者、交换机等概念,这些内容的设计和实现和RabbitMq同源,RabbitMq的底层设计就是使用了Camel的框架。
关于这些概念可以参与我之前的文章 https://www.cnblogs.com/dubing/p/4017613.html
组件的概念如下图
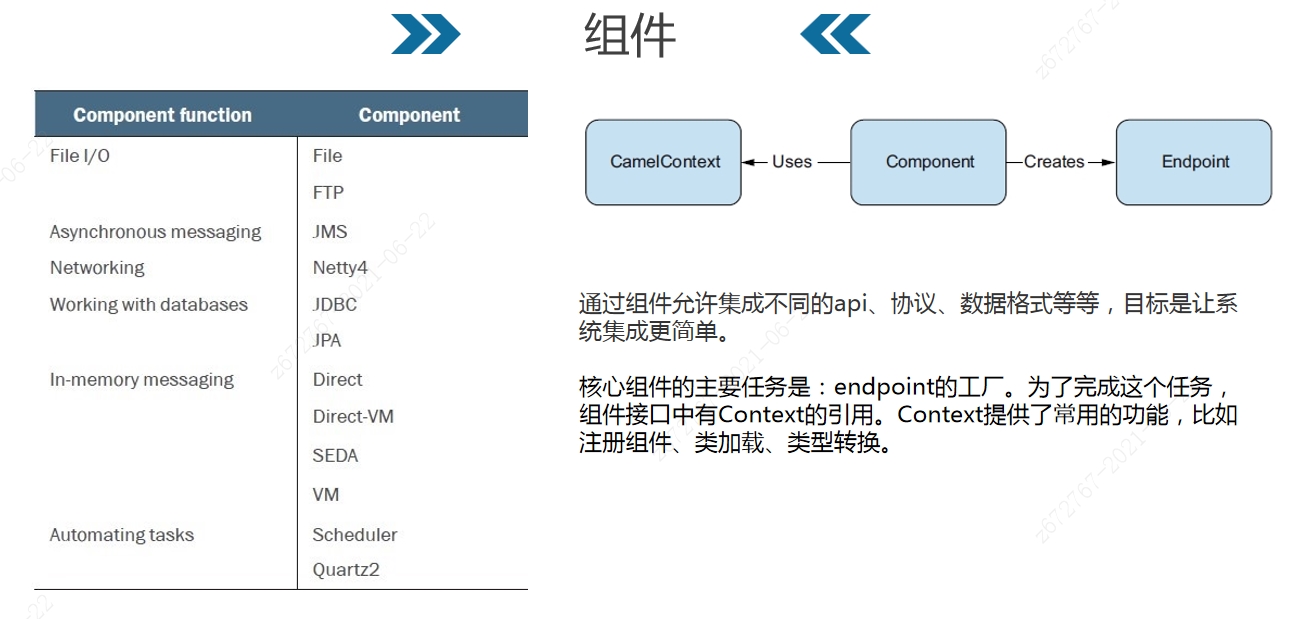
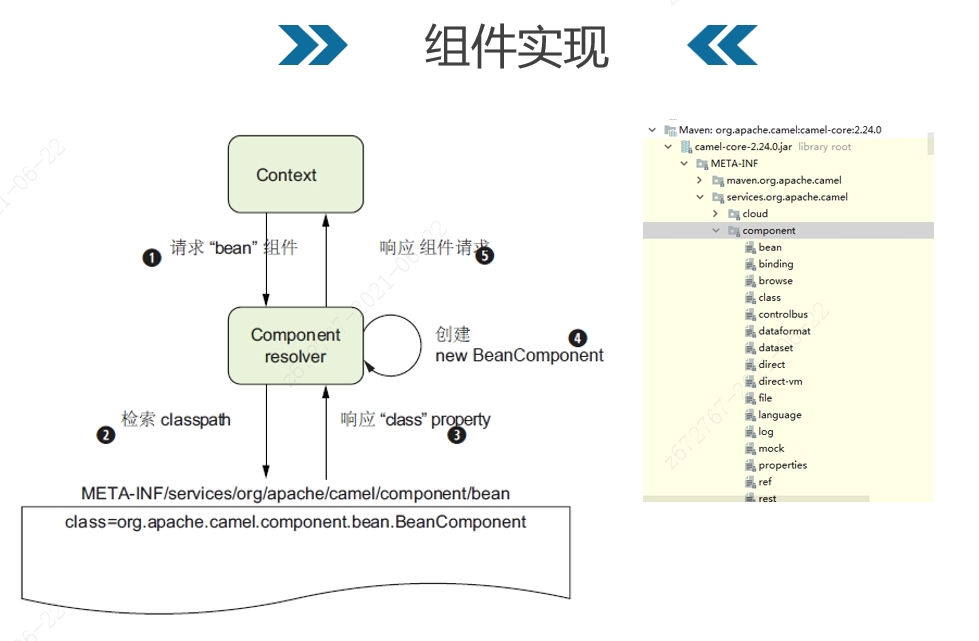
组件的实现方式为监控指定目录中的文件。此目录中的文件描述了组件的名称、组件类的全路径名。 大部分组件的java代码模块都与模块核心模块做了分离,因为他们常常依赖第三方的包,如果不分离,将会使核心包过度膨胀。
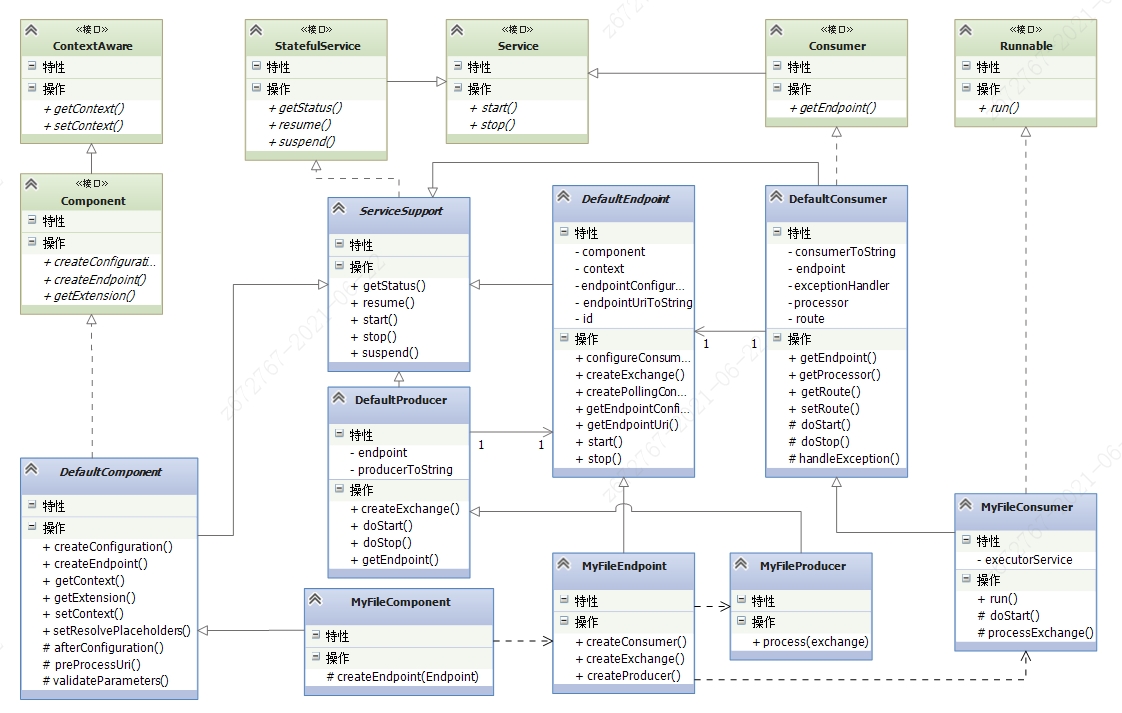
整个端点实现的类图可以参考下图
下面我们接着讲路由


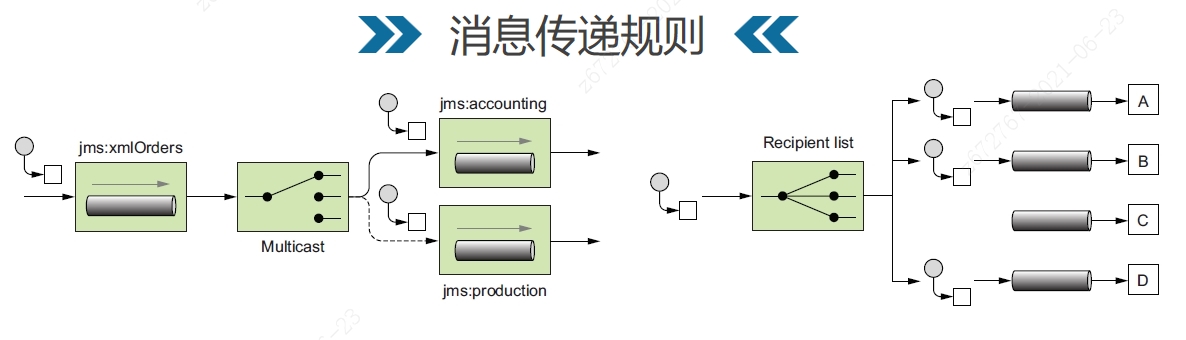
Multicast表示将消息复制多份串行/并行分开给所有消费通道。
RecipientList区别于多播模式,解决消费通道优先级问题。收件人列表可以动态维护。
routeSliping是将消息依次传入后面的节点进行处理,不会负责,后面的节点修改的是同一个消息。
此外还有多种传递类型,例如SPLIT将一份消息分离成不同部分传递给不同消息通道,Aggregator将不同消息来源合并给下游消息通道。
如果组件支持的模式不足以满足我们项目的特性需求还可以自定义规则

示例中根据choice-when 自定义路由规则。
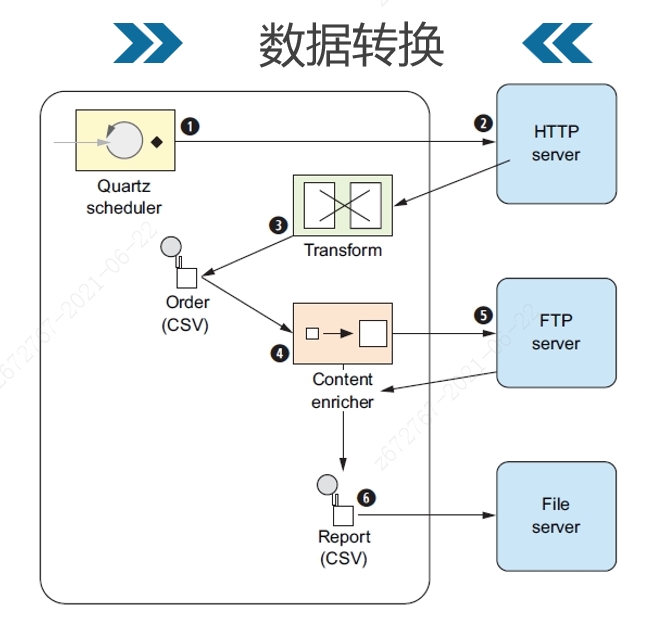
代码示例

本章总览了服务编排的设计,内容较多每一块的细节都可以单独拿出来详细解读,最后附上组件示例代码(示例代码为完全demo环境,如发现任何企业或者版权相关信息请联系我删除)
 |
原创作品允许转载,转载时请务必以超链接形式标明文章原始出处以及作者信息。 作者:熬夜的虫子 点击查看:博文索引 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号