log 日志处理(linux shell 脚本方式 or Python)
log 日志处理
我需要从log日志中取出部分数据,数据为Device ID内容,该数据所在的行有Device ID字符串行标记。
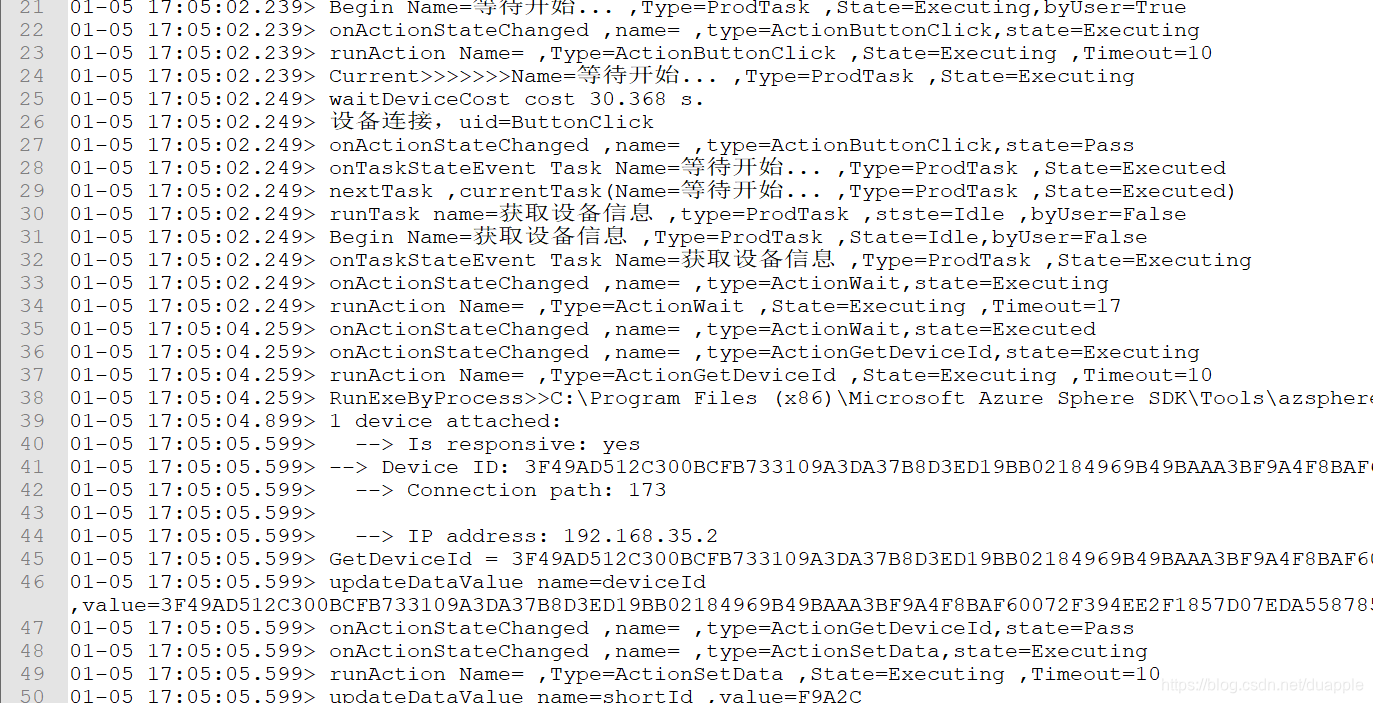
#获取所有含 “Device ID”字符串的行
cat log*.txt | grep "Device ID: " > tmp1.txt
这样就拿到了所有目标数据的行。但是有的行不含目标数据,但是含有Device ID标记。
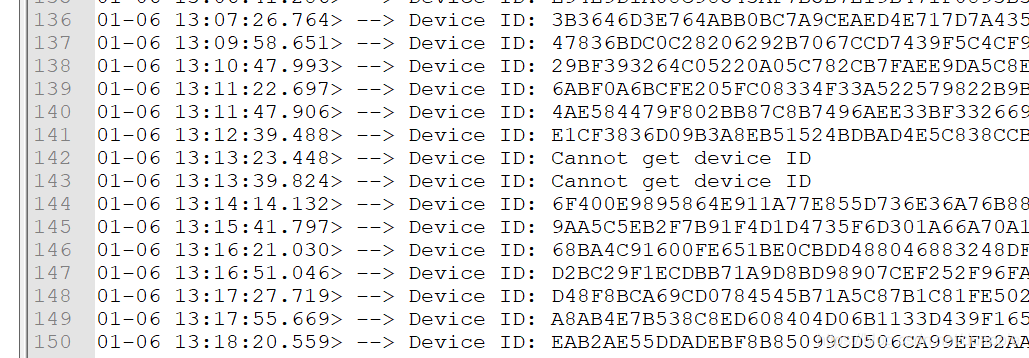
因此需要删除这些行。
#删除含 “Device ID”字符串但是没有正确数据的行
sed -i '/Cannot get device ID/d' tmp1.txt
删除掉不需要的行后,需要取出Device ID: 后面的数据内容。
#取出所有 Device ID 数据
cat tmp1.txt | cut -d ':' -f 4 > tmp2.txt
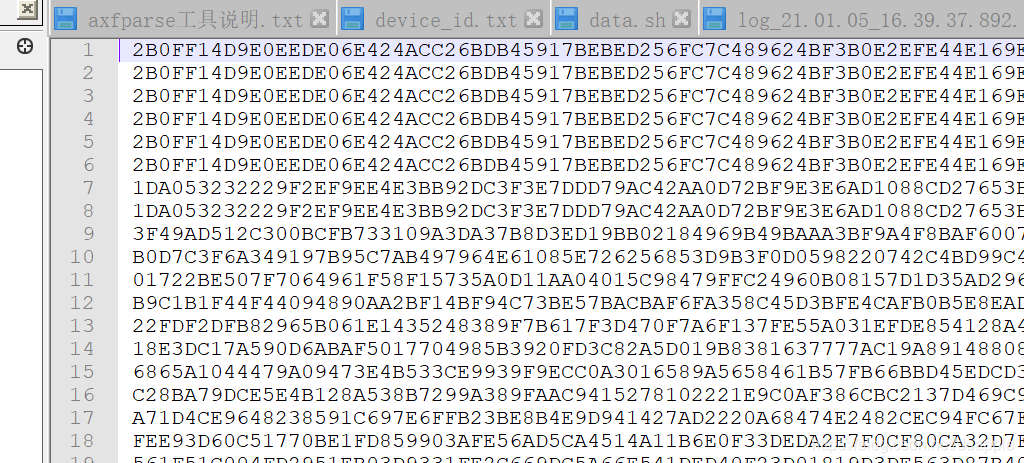
此时数据有重复的内容,并且前面带有一个空格,相同的数据只保留一行,并删除掉空格,最后删除掉对应的缓存文件。
#通过排序的方式 删除相同数据的行
sort -k2n tmp2.txt | uniq > tmp3.txt
#删除 Device ID 数据前的空格字符
cat tmp3.txt | cut -d ' ' -f 2 > DeviceID.txt
#删除暂存文件
rm tmp*.txt
写一个 Linux shell 脚本来完成整个任务 get_device_id.sh。
#!/bin/bash
#获取所有含 “Device ID”字符串的行
cat log*.txt | grep "Device ID: " > tmp1.txt
#删除含 “Device ID”字符串但是没有正确数据的行
sed -i '/Cannot get device ID/d' tmp1.txt
#取出所有 Device ID 数据
cat tmp1.txt | cut -d ':' -f 4 > tmp2.txt
#通过排序的方式 删除相同数据的行
sort -k2n tmp2.txt | uniq > tmp3.txt
#删除 Device ID 数据前的空格字符
cat tmp3.txt | cut -d ' ' -f 2 > DeviceID.txt
#删除暂存文件
rm tmp*.txt
因为我是在Windows上做这个任务,Linux 脚本调用起来还需要开Linux 命令行窗口,不是很方便。因此再写一个批处理脚本get_DeviceID.bat。
wsl ./get_device_id.sh
pause
不得不说,WSL真是一个非常棒的工具。
获取上述数据的Python处理方法。思路是一样的,python处理起来也是非常简单。
# coding:utf-8
import os
import re
paramStr = "Device ID: "
errorStr = "Cannot get device ID"
deviceID0 = []
root = os.getcwd()
i = 0
for root, dirs, files in os.walk(root):
#print(files)
for file in files:
t = file.find("log") #找到所有的log日志文件
#print(file)
if t != -1:
#print(file)
f1 = open(file, "r", encoding = 'utf-8')
data_buff = f1.readlines() #分别打开每一个文件,然后按行读处理
f1.close()
for line in data_buff:
t1 = line.find(paramStr) # 找到 Device ID关键字行
if t1 != -1:
targetStr = line[t1 + len(paramStr):] # 取出 Device ID 后的数据
if targetStr[:len(errorStr)] != errorStr[:] : #数据正确则保存 Device ID数据
deviceID0.append(targetStr)
print(deviceID0[i])
i = i+ 1
print(i)
deviceID = list(set(deviceID0)) # 将保存的Device ID数据去重
print(len(deviceID))
file = open("Device_ID_python.txt", "w") # 去重后的数据保存到文件中
for line in deviceID:
file.write(line)
file.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号