
Hadoop学习之TextInputFormat分片逻辑探究
期望
顺着上一篇文章《Hadoop学习之第一个MapReduce程序》中遗留的分片疑惑,探究TextInputFormat的分片逻辑。
第一步
上Apache官网下载实验所使用的Hadoop3.2.0版本源码,导入IntelliJ Idea中,不赘述了。下载链接:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.0/hadoop-3.2.0-src.tar.gz
第二步
TextInputFormat
定位到我们疑惑的起端TextInputFormat类,可以看到他的代码非常简单,只有两个方法,且都是重载/实现的父类/接口中的方法,其中有一个与分片有关系,叫isSplitable,他根据一个输入的路径,判断该文件是否可以切分。做法也比较浅显,根据文件后缀名得出其对应的压缩方式,若其压缩编码类实现了SplittableCompressionCodec接口,即认为文件时可切分的。代码如下:
protected boolean isSplitable(JobContext context, Path file) { final CompressionCodec codec = new CompressionCodecFactory(context.getConfiguration()).getCodec(file); if (null == codec) { return true; } return codec instanceof SplittableCompressionCodec; }
FileInputFormat
TextInputFormat中比没有看到最关键的代码,只得接着往他的父类中寻找。打开父类FileInputFormat,看到跟分片有关的方法有如下图所示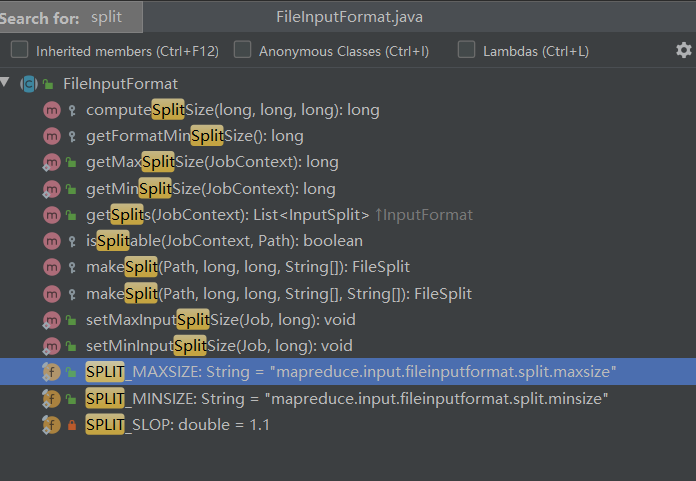
通过方法名、输入输出类型,可以很自然的发现,最接近我们想法的就是 getSplits方法了,返回一个输入分片的集合,我们直接找到该方法,其代码如下:
1 /** 2 * Generate the list of files and make them into FileSplits. 3 * @param job the job context 4 * @throws IOException 5 */ 6 public List<InputSplit> getSplits(JobContext job) throws IOException { 7 StopWatch sw = new StopWatch().start(); 8 long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job)); 9 long maxSize = getMaxSplitSize(job); 10 11 // generate splits 12 List<InputSplit> splits = new ArrayList<InputSplit>(); 13 List<FileStatus> files = listStatus(job); 14 15 boolean ignoreDirs = !getInputDirRecursive(job) 16 && job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false); 17 for (FileStatus file: files) { 18 if (ignoreDirs && file.isDirectory()) { 19 continue; 20 } 21 Path path = file.getPath(); 22 long length = file.getLen(); 23 if (length != 0) { 24 BlockLocation[] blkLocations; 25 if (file instanceof LocatedFileStatus) { 26 blkLocations = ((LocatedFileStatus) file).getBlockLocations(); 27 } else { 28 FileSystem fs = path.getFileSystem(job.getConfiguration()); 29 blkLocations = fs.getFileBlockLocations(file, 0, length); 30 } 31 if (isSplitable(job, path)) { 32 long blockSize = file.getBlockSize(); 33 long splitSize = computeSplitSize(blockSize, minSize, maxSize); 34 35 long bytesRemaining = length; 36 while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { 37 int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); 38 splits.add(makeSplit(path, length-bytesRemaining, splitSize, 39 blkLocations[blkIndex].getHosts(), 40 blkLocations[blkIndex].getCachedHosts())); 41 bytesRemaining -= splitSize; 42 } 43 44 if (bytesRemaining != 0) { 45 int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); 46 splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining, 47 blkLocations[blkIndex].getHosts(), 48 blkLocations[blkIndex].getCachedHosts())); 49 } 50 } else { // not splitable 51 if (LOG.isDebugEnabled()) { 52 // Log only if the file is big enough to be splitted 53 if (length > Math.min(file.getBlockSize(), minSize)) { 54 LOG.debug("File is not splittable so no parallelization " 55 + "is possible: " + file.getPath()); 56 } 57 } 58 splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(), 59 blkLocations[0].getCachedHosts())); 60 } 61 } else { 62 //Create empty hosts array for zero length files 63 splits.add(makeSplit(path, 0, length, new String[0])); 64 } 65 } 66 // Save the number of input files for metrics/loadgen 67 job.getConfiguration().setLong(NUM_INPUT_FILES, files.size()); 68 sw.stop(); 69 if (LOG.isDebugEnabled()) { 70 LOG.debug("Total # of splits generated by getSplits: " + splits.size() 71 + ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS)); 72 } 73 return splits; 74 }
(emmm,方法注释更加证实了他就是要找的东西!)
研读以上代码,可以发现,分片逻辑的关键在于得到blockSize、splitSize,得到这两个值后,做的事就是循环“切割”文件了,要弄清的关键点有以下几个:
- blockSize是多少?
- splitSize是多少?
- “切割”判断依据
Q1很明了,由于我们的实验环境并未在配置中指定块大小,所以blockSize为默认值128M。
Q2可以看到splitSize由computeSplitSize方法计算得出,为了方便观看,我把computeSplitSize方法及相关的几个值获取的方法放到一起,如下所示:
public static final String SPLIT_MAXSIZE = "mapreduce.input.fileinputformat.split.maxsize"; public static final String SPLIT_MINSIZE = "mapreduce.input.fileinputformat.split.minsize"; public static long getMinSplitSize(JobContext job) { return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L); } protected long getFormatMinSplitSize() { return 1; } public static long getMaxSplitSize(JobContext context) { return context.getConfiguration().getLong(SPLIT_MAXSIZE, Long.MAX_VALUE); } protected long computeSplitSize(long blockSize, long minSize, long maxSize) { return Math.max(minSize, Math.min(maxSize, blockSize)); }
由于我并未配置mapreduce.input.fileinputformat.split.maxsize和mapreduce.input.fileinputformat.split.minsize,Configuration中他俩的值即为默认值空和0,所以getMinSplitSize值为1,getMaxSplitSize值为Long.MAX_VALUE,故
splitSize=Math.max(minSize, Math.min(maxSize, blockSize)) =Math.max(1, Math.min(Long.MAX_VALUE, 128 * 1024 * 1024)) =Math.max(1, 128 * 1024 * 1024) =128 * 1024 * 1024 =blockSize
Q3 “切割”依据即getSplits方法中的循环判断 while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) ,可知常量SPLIT_SLOP值为1.1。
结论
综上所述,TextInputFormat的分片逻辑为:
将文件按块切割,直到文件剩余大小 小于等于 块大小的1.1倍时,将剩余部分(理论上时2个块的数据)作为一个输入分片。
回过头来看《Hadoop学习之第一个MapReduce程序》中的分片问题,文件数为44、块数为61,但是分片数为58,就是因为有三个文件的分块有“小尾巴”,这三个小于等于1.1倍块大小的块与对应文件的上一个块共同组成了一个输入分片。
