
美的支付-对账系统实现
对账,可以发现渠道方与我方交易中的差异。根据差异的不同,再做具体的操作。随着美的支付接入的渠道增多,日交易量逐渐增大的情况下,人工对账已经不能满足财务的要求,系统对账提上日程
待解决的问题
01
替代人工对账,解放人工对账的工作量,提升对账效率,实现系统自动化
02
对账差异可自动进行对应处理,输出对账结果
1人工对账
2对账系统V1.01
★
系统自动从渠道下载对账单
查询系统交易流水
以渠道对账单为准,对比美的支付交易流水
以美的支付交易流水为准,对比渠道对账单
获得对账差异、对账结果
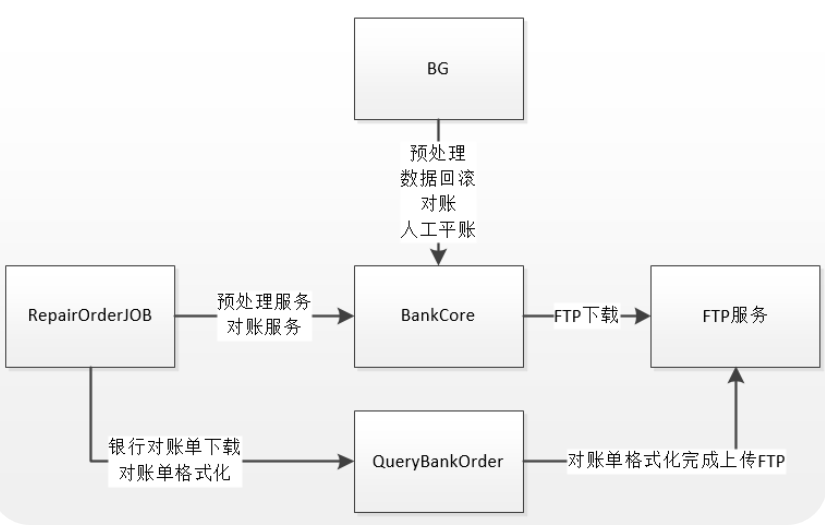
系统架构
★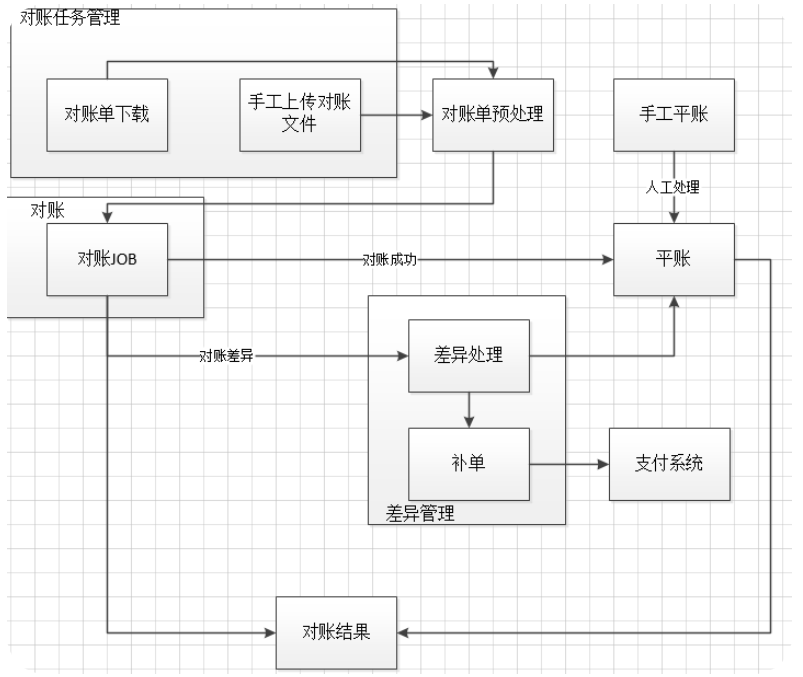
对账流程

明细对账
弊端
单线程分页查询渠道账单数据库中数据、分页查询银行流水数据、分页查询支付流水数据;对账速度慢,对账5000笔交易需要耗时5小时以上;对账不准确,漏单
3、对账系统V1.02★
引入Redis,使用Redis的交集特性,可快速完成对账处理
引入多线程
将所有历史差异都查询出来重新对账,避免漏单
只需要查询一次渠道账单数据和我司交易流水
速度快,对账2W笔,耗时15分钟
★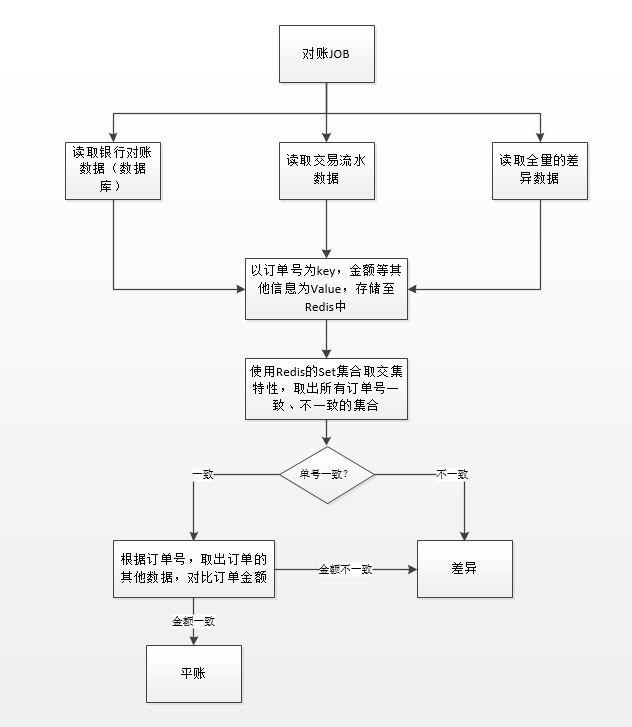
优化之后的对账流程
弊端
对账过程中所有链路都是同步调用,数据量过大的情况下导致RPC调用超时;渠道对账单中的数据存储至数据库中,量大的情况下,会导致数据插入耗时较长,且有大量RPC调用;人工对账时,需要回滚删除历史对账数据,做一次回滚操作
4、对账系统V2.0★
系统拆分
引入MQ
异步化
账单数据不入库
★

拆分之后的架构
对账前置系统
渠道账单下载配置:按照下载配置,IT自动按时到各自渠道下载原始账单
渠道账单与标准账单映射:按照映射关系,系统自动将渠道原始账单,转换为预先定义的标准账单
内部转换系统
对账单下载配置:按照下载配置,系统自动执行SQL映射中的SQL语句,组织为原始账单
对账单SQL映射:获取内部账单的SQL语句映射,根据SQL语句,查询数据库
内部账单与标准账单映射:若配置的SQL映射非标准账单,则配置与标准账单的映射关系。系统自动按照映射关系,转换为标准账单
对账核心系统
对账主流程:
1:加载对账左方的标准账单,以订单号为key,订单金额等其他信息为value,存储至Redis的Map对象中;加载所有订单号存储至Redis的Set对象中
2:加载对账右方的标准账单,以订单号为key,订单金额等其他信息为value,存储至Redis的Map对象中;加载所有订单号存储至Redis的Set对象中
3:加载历史差异数据,以订单号为key,订单金额等其他信息为value,存储至Redis的Map对象中;加载所有订单号存储至Redis的Set对象中
4:对比对账左方和对账右方的订单总金额、总笔数
5:获得对账结果,插入对账结果
6:异步调用明细对账流程
7:主流程结束
明细对账流程:
1:利用Redis的Set集合对象,取交集;获得订单号一致的数据集合
2:利用Redis的Set集合对象,取差集;获得订单号不一致的数据集合
3:订单号一致的数据集合,取Redis中对应的Map对象中的订单信息,对比订单的金额是否一致。若一致,则账平;否则为差异,差异类型:金额不一致
4:订单号不一致的数据集合,与历史差异数据集合再次进行取交集操作,获得订单号一致的数据集合和订单号不一致的数据集合
5:订单号一致的数据集合,取Redis中对应的Map对象中的订单信息,对比订单的金额是否一致。若一致,则账平,类型为日切差账平;否则为差异,不做更新操作
6:订单号不一致的数据集合,判断是否新增差异。若为新增差异,则差异类型为:左有右无、左无右有
7:根据明细对账的最终结果,更新对账结果数据
8:将差异数据信息发送MQ消息,进入差错处理流程
对账差异处理流程:
对账差异数据发送至MQ之后,由对账核心消费,将对账差异数据存储至数据库
差错处理系统(V2.0未实现)
对账差异数据发送至MQ之后,由对账核心消费,将对账差异数据存储至数据库
成果
每日对账流水近30w数据,对账核心流程耗时不超过20秒
发薪日对账流水近50w数据,对账核心流程耗时不超过30秒
5、对账系统V3.0(进行中)★
实现差错处理
账平数据不入库
实现其他优化
★
6、结语★
经过对账系统的逐步优化,对账完全实现系统自动化
对账的效率大幅提升
7、其它
将格式化后的记录(id,status,amount)保持到两个大文件,两个大文件的对比:
方案1:(仅学院派,不实用)
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url
主体思路:分治+hash
- 遍历文件A,对每个url使用hash(url) % 1000,根据所得的取值将url存储到1000个小文件中(a1,a2,…,a1000)(根据内存大小设定hash函数)
- 遍历文件B,使用同样的hash函数将B中的url存储到1000个小文件中(b1,b2,…,b1000)(这样相同的url就会被映射到下标相同的小文件中)
- 读取文件a1,简历hash表,再读取文件b1,遍历其中的url,若url在hash表中出现,说明为两文件共有,存入结果中。
方案2:通过redshift的serverless的方式(超大量数据时)
格式后的2个份文件,加载到redshift中,运行sql,结果输出到文件。
源文件-->glue-->离线数仓-->执行join sql找出差异-->结果生成文件-->glue--结果写回业务库。
转载:https://mp.weixin.qq.com/s/orSKCephD7qynp5tn32cKA

 浙公网安备 33010602011771号
浙公网安备 33010602011771号