


flume-sink
-
概述
从Flume Agent移除数据并写入到另一个Agent或数据存储或一些其他存储系统的组件被称为sink。Sink不断的轮询channel中的事件且批量的移除它们。这些事件批量写入到存储或索引系统,或者被发送到另一个Flume Agent。Sink是完全事务性的。在从channel批量移除数据之前,每个sink用channel启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,sink就利用channel提交事务。事务一旦被提交,该channel从自己的内部缓冲区删除事件。
-
sink的生命周期
·每个sink至少有一个正确配置的channel连接它
·每个sink有一个定义的type参数
·sink是在Agent中sink活跃列表中的
Flume可以聚合线程到sink组,每个sink组可以包含一个或多个sink。如果一个sink没有定义分组,那么该sink可以被认为是在一个组内,且该sink是组内的唯一成员。
每个sink运行器运行一个sink组,sink运行器是一个针对sink组循环调用process方法的线程,依次转发调用到组里其中一个sink的process方法。
类似于其他所有的组件(除了Memory Channel),当Flume被重新配置,sink的实例是不会被重用的。因此,sink不应该缓冲任何已被读取和提交的事件。这是因为提交事务表明channel可以删除在事务的上下文中读取的事件。 -
优化sink的性能
当个别sink比写入到指定channel的速率要慢很多时,那就值得添加更多sink用来写入到相同目的地和从相同channel读取事件。当增加sink数量来提升性能时,必须确保的一点是资源不会因过度使用而结束,创建有太多上下文切换或网络的情况下将导致阻塞。
-
HDFS Sink
可以基于事件的报头、事件的时间戳等配置写入到不同的目录。HDFS Sink支持Hadoop1和Hadoop2,但是代码必须针对Hadoop的相关版本进行特定的编译,这是因为在Hadoop1和Hadoop2之间二进制不兼容性变化。
HDFS Sink将数据写到HDFS的bucket。实际上,一个bucket就是一个目录。一个HDFS Sink可以同时将数据写到多个bucket中,但是一个事件将只进入到一个bucket中。无论任何时候每个bucket最多只有一个文件打开,但每个sink在不同的bucket里可以打开若干文件。Flume允许用户基于配置文件中不同指定参数动态创建bucket。HDFS Sink批量处理事件,在一个批处理中刷新所有的事件到HDFS中。如果一个事件再次被写入到同一个bucket,那么sink将会创建一个新的文件。
-
理解bucket
HDFS Sink使用几个参数创建bucket路径。为了动态创建这些路径,配置文件必须指明路径为hdfs.path参数。该路径可以指定一个或多个sink将取代的转义序列,用来构造写事件的真实路径。

当HDFS Sink从channel读取一个事件,它读取主体报头的值,并利用配置参数,将路径的转义序列替换为指定主体报头的值。HDFS Sink提供了很强大的时间戳的转义。它支持几个使用时间戳事件报头值的转移序列。多个转移序列可以在相同的路径中使用:

这个例子对于每一个主题,将把所有时间戳为相同小时的事件写到相同目录内。

使用该配置,用户可以每10分钟就有一个bucket
-
使用序列化器控制数据格式
序列化类必须实现EventSerrializer接口。
Flume内置了三类序列化器:TEXT序列化器、HEADER_AND_TEXT序列化器、AVRO_EVENT序列化器。
TEXT序列化器以事件主体本身写入到文件,可以根据需要在事件之间插入新的一行。
HEADER_AND_TEXT序列化器也做相同的事情,但也包括“key=value”格式的事件报头。默认会在事件之间插入新的一行。这可以通过将appendNewline的值设置为false来禁用:
AVRO_EVENT序列化器使用下面所示的模式,将事件写出为Avro container文件:

-
HBase Sink
Flume有两类HBase Sink:HBase Sink和Async HBase Sink。HBase客户端API是阻塞的,所以HBase Sink逐个向HBase集群发送事件。Async HBase API是非阻塞的且使用多线程写数据到HBase。所以,大多数情况下,Async HBase Sink有可能给出更好的性能。但是HBase Sink支持安全HBase,Async HBase不支持。这两个HBase sink都是批量写事件

-
RPC Sink
如果从一个Flume Agent发送数据到另一个Agent,那么要使用RPC Sink。RPC Sink和对应的RPC Source使用相同的RPC协议。Flume支持两种RPC系统:Avro和Thrift,Avro被认为是Flume主要的RPC格式。
Avro Sink使用Avro的Netty-based RPC协议发送数据到Avro Source。Avro Sink可以批量发送事件到Avro Source。
Thrift Sink可以用来在FlumeAgent之间使用Thrift RPC进行通信。Thrift Sink跟Avro Sink很像,但它缺少压缩和SSL功能。在Flume Agent之间推荐使用Avro RPC通信。 -
Morphline Solr Sink
Morphlines是一个高度可扩展的ETL框架,几个命令可以连在一起,且使一个命令的输出作为下一个命令的输入,来执行数据的重量级转换。Morphline Solr Sink整合Morphline框架和提供Sink的Flume,可以从Flume管道传输数据到Morphline,最终加载事件到Solr索引。
Morphline库提供了一个称为loadSolr的命令,可以加载记录到solr。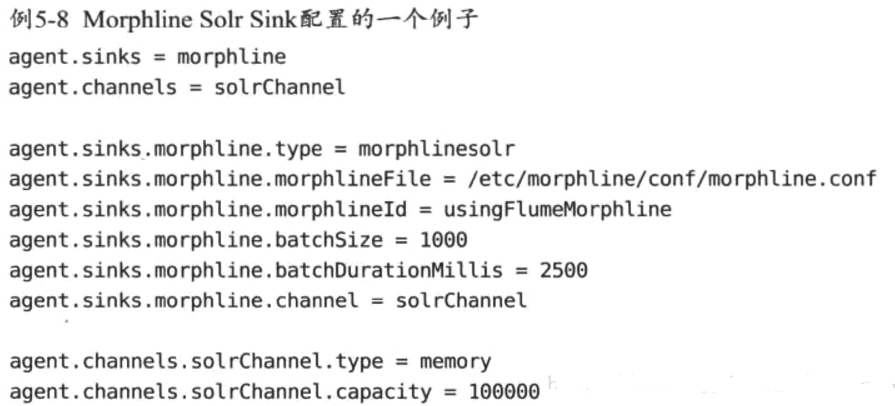
-
Elastic Search Sink
Flume可以使用Elastic Search Sink实时加载数据到Elastic Search来创建索引。

-
其他sink
①Null Sink
用于从channel读取事件并删除它们。这类sink的目的是检测其余agent的功能和特性。Null Sink批量地从channel移除事件并更新日志文件。
②Rolling File Sink
Rolling File Sink写事件到本地文件系统。
③Logger Sink
Logger Sink记录到log4j.properties文件中配置的Flume Agent的log4j日志文件。该Sink所有的配置都从log4j.properties文件中获取,且它不需要任何其他的参数。 -
编写自定义Sink
自定义Sink必须实现Sink接口,如果Sink需要接受来自配置系统的配置,那么可以选择实现Configurable接口。为了更好地理解如何编写一个Sink,很重的是要理解Flume框架如何与Sink交互。
当Agent 启动时,框架检查来确保每个Sink 有一个指定的type,且有一Channel 参数的值代表了Agent 中已经存在的配置合适的Channel.然后Sink 被实例化且配置传递给它的configure方法。如果configure方法失败且抛出异常,那么该Sink 会从Agent 中移除且删除它的实例。一且Sink 成功配置,它就连接到应该从其中读取事件的Channel.
从那时起,Sink由一个Sink 运行器管理。Sink 运行器只是一个负责运行该Sink的线程。框架通过调用start方法来启动Sink。如果start失败,该框架将反复重试启动Sink.
一旦Sink 启动,Sink运行器线程就循环调用process 方法。该方法负责从Channel 读取数据并写出到下一阶段或最终目的地。每个process 调用必须处理整个事务——启动事务,从Channel读取事件,提交或回滚事务,并最终关闭事务。如果Channel 不包含任何Sink可以移除的事件,process方法必须返回Status.BACKOFF,这使得Sink 运行器只在一个时间间隔后重试。如果Sink 成功,它必须返同Status.READY状态,且运行器将立即再次调用process 方法。
当从Channel读取数据或写入到目的地时,如果遇到一些异常,sink 必须返同status.BACKOFF状态或抛出异常以报告失败。这使Sink 运行器减慢速度,如果不能消除下流Agent或最终目的地的数据,这也是避免发送数据到下一阶段的调节机制。在Flume框架中,为了正确地运行,process方法必须是线程安全的。
1. Flume Sinks
1.1 HDFS Sink
该sink把events写进Hadoop分布式文件系统(HDFS)。它目前支持创建文本和序列文件。它支持在两种文件类型压缩。文件可以基于数据的经过时间或者大小或者事件的数量周期性地滚动。它还通过属性(如时间戳或发生事件的机器)把数据划分为桶或区。


agent a1的示例:

上述配置会将时间戳降到最后10分钟。例如,带有11:54:34 AM,June 12,2012时间戳的event将会造成hdfs路径变成/flume/events/2012-06-12/1150/00。
1.2 Hive Sink
该sink streams 将包含分割文本或者JSON数据的events直接传送到Hive表或分区中。使用Hive 事务写events。当一系列events提交到Hive时,它们马上可以被Hive查询到。


Hive table 示例:

agent a1示例:

上述配置将会把时间戳降到最后10分钟。例如,event时间戳 header设置为 11:54:34 AM, June 12,2012 ,和 ‘country’ header 设置 为 ‘india’ , 该event评估到partition(continent='asia', country='india', time='2012-06-12-11-50')。
1.3 Logger Sink
Logs event 在INFO 水平。典型用法是测试或者调试。

agent a1 示例:

1.4 Avro Sink
Flume events发送到sink,转换为Avro events,并发送到配置好的hostname/port。从配置好的channel按照配置好的批量大小批量获取events。


agent a1示例:

1.5 Thrift Sink
Flume events发送到sink,转换为Thrift events,并发送到配置好的hostname/port。从配置好的channel按照配置好的批量大小批量获取events。

agent a1示例:

1.5 IRC Sink
IRC sink从链接的channel获取消息和推送消息到配置的IRC目的地。

agent a1示例:

1.6 File Roll Sink
在本地文件系统存储events。


agent a1示例:

1.7 Null Sink
当接收到channel时丢弃所有events。

agent a1示例:

1.7 HBaseSinks
1.7.1 HBaseSink
该sink写数据到HBase。

agent a1 示例:

1.7.2 AsyncHBaseSink
该sink采用异步模式写数据到HBase。

agent a1示例:

1.8 MorphlineSolrSink
该sink从Flume events提取数据并转换,在Apache Solr 服务端实时加载,Apache Solr servers为最终用户或者搜索应用程序提供查询服务。


agent a1示例:

1.9 ElasticSearchSink
该sink写数据到elasticsearch集群。


agent a1示例:

1.10 Kite Dataset Sink
试验sink写event到Kite Dataset。

1.11 Kafka Sink
Flume Sink实现可以导出数据到一个Kafka topic。

Kafka sink配置例子:

1.11.1 Security and Kafka Sink
Flume和Kafka之间的联系channel支持安全认证和数据加密。
安全认证SASL/GSSAPI(Kerberos V5) 或者 SSL(TLS实现) 可以被用于Kafka 版本 0.9.0 。
数据加密由SSL/TLS提供。
设置kafka.producer.security.protocol为下面值:
- SASL_PLAINTEXT - Kerberos or plaintext authentication with no data encryption
- SASL_SSL - Kerberos or plaintext authentication with data encryption
- SSL - TLS based encryption with optional authentication.
TLS 和 Kafka Sink:
带有服务端认证和数据加密配置的例子:

注意:属性ssl.endpoint.identification.algorithm没有定义,因此没有hostname验证,为了是hostname验证,可以设置属性:

如果要求有客户端认证,在Flume agent配置中添加下述配置。每个Flume agent必须有它的客户端凭证,以便被Kafka brokers信任。

如果keystore和key使用不用的密码保护,那么ssl.key.password属性需要提供出来:

Kerberos and Kafka Sink:
kerberos配置文件可以在flume-env.sh通过JAVA_OPTS指定:

使用SASL_PLAINTEST的安全配置示例:

使用SASL_SSL的安全配置示例:

JAAS文件实例(暂时没看懂):

1.12 HTTP Sink
该sink将会从channel获取events,并使用HTTP POST请求发送这些events到远程服务。event 内容作为POST body发送。

agent a1示例:

1.13 Custom Sink(自定义Sink)
自定义sink是你实现Sink接口。当启动Flume agent时,一个自定义sink类和它依赖项必须在agent的classpath中。

agent a1 示例:

2. Flume Sink Processors
Sinks groups 允许用户把多个sinks分组汇入到一个实体中。Sink processors可以用于在组内所有sinks提供负载平衡,或者在暂时失败的情况下实现从一个sink到另一个sink的故障转移。

agent a1的示例:

2.1 Default Sink Processor
默认sink processor只接收一个简单sink。用户没有强制去为单个sinks创建processor(sink group)。相反,用户可以按照用户指南上解释的source - channel - sink 模式。
2.2 Failover Sink Processor
Failover Sink Processor 维护sinks的优先列表,保证当有可用的events将会被处理。

agent a1的示例:

2.3 Load balancing Sink Processor
Load balancing sink processor 提供了对多个sinks进行负载平衡的能力。

agent a1示例:

2.4 Custom Sink Processor
现在不支持自定义sink processors。
3. Event Serializers
file_roll sink和hdfs sink都支持EventSerializer接口。下面提供了Flume附带的EventSerializers的细节。
3.1 Body Text Serializer
别号:text。拦截器将event的主体写入输出流,而没进行任何的转换或者修改。event header被忽略。配置选项:

agent a1的示例:

3.2 "Flume Event" Avro Event Serializer
别名:avro_event。
拦截器将Flume events序列化成一个Avro容器文件。所使用的模式与Avro RPC机制中用于Flume events的模式相同。
该serializer继承自AbstractAvroEventSerializer类。

agent a1示例:

3.3 Avro Event Serializer
别名:该serializer没有别名,必须指定使用的类名。

agent a1示例:

参考资料:

