


垃圾收集器之:CMS收集器
HotSpot JVM的并发标记清理收集器(CMS收集器)的主要目标就是:低应用停顿时间。该目标对于大多数交互式应用很重要,比如web应用。在我们看一下有关JVM的参数之前,让我们简要回顾CMS收集器的操作和使用它时可能出现的主要挑战。
CMS收集器有3种基本的操作,分别是:
- CMS收集器会对新生代的对象进行回收(所有的应用线程都会被暂停);
- CMS收集器会启动一个并发的线程对老年代空间的垃圾进行回收;
- 默认情况下CMS不会对永久代进行垃圾回收,如果有必要,CMS会发起Full GC。
就像吞吐量收集器,CMS收集器处理老年代的对象,然而其操作要复杂得多。吞吐量收集器总是暂停应用程序线程,并且可能是相当长的一段时间,然而这能够使该算法安全地忽略应用程序。相比之下,CMS收集器被设计成在大多数时间能与应用程序线程并行执行,仅仅会有一点(短暂的)停顿时间。GC与应用程序并行的缺点就是,可能会出现各种同步和数据不一致的问题。为了实现安全且正确的并发执行,CMS收集器的GC周期被分为了好几个连续的阶段。
CMS收集器的过程
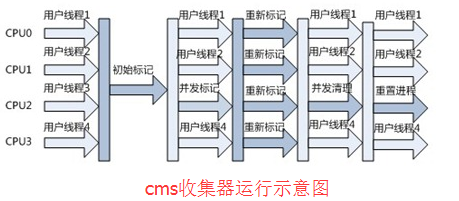
CMS收集器的GC周期由6个阶段组成。其中4个阶段(名字以Concurrent开始的)与实际的应用程序是并发执行的,而其他2个阶段需要暂停应用程序线程。
- 初始标记(CMS Initial Mark,STW):为了收集应用程序的对象引用需要暂停应用程序线程,该阶段完成后,应用程序线程再次启动。(第一次暂停应用程序)
- 并发标记(CMS-concurrent-mark-start、CMS-concurrent-mark):从第1阶段收集到的对象引用开始,遍历所有其他的对象引用。(第一次并发收集操作)
- 并发预清理(CMS-concurrent-preclean-start、CMS-concurrent-preclean):改变当运行第2阶段时,由应用程序线程产生的对象引用,以更新第2阶段的结果。(第二次并发收集操作)
- 重新标记(CMS-concurrent-abortable-preclean-start、CMS-concurrent-abortable-preclean,STW):由于第3阶段是并发的,对象引用可能会发生进一步改变。因此,应用程序线程会再一次被暂停以更新这些变化,并且在进行实际的清理之前确保一个正确的对象引用视图。这一阶段十分重要,因为必须避免收集到仍被引用的对象。(第二次暂停应用程序)
这个阶段又涵盖多个阶段:
可中断预清理(abortable-preclean):使用可中断预清理是由于标记阶段(最后输出项)不是并发的,所有应用线程都会被暂停。如果新生代收集刚刚结束,紧接着就是一个标记阶段的话,应用遭遇2次暂停操作,CMS收集器希望避免这样的情况发生。使用可中断预清理阶段的目的就是希望尽量缩短停顿时长,避免连续停顿。
因此,可中断预清理阶段会在新生代空间收集到50%左右开始(理论离下次新生代收集还有半程距离),这样的启动设置给了CMS收集器最好的避开连续停顿的概率。
- 并发清理(CMS-concurrent-sweep-start、CMS-concurrent-sweep):所有不再被应用的对象将从堆里清除掉。(第三次并发收集操作)
- 并发重置(CMS-concurrent-reset-start、CMS-concurrent-reset):收集器做一些收尾的工作,以便下一次GC周期能有一个干净的状态。(第四次并发收集操作)
一个常见的误解是,CMS收集器运行是完全与应用程序并发的。我们已经看到,事实并非如此,即使“stop-the-world”阶段相对于并发阶段的时间很短。
应该指出,尽管CMS收集器为老年代垃圾回收提供了几乎完全并发的解决方案,然而年轻代仍然通过“stop-the-world”方法来进行收集。对于交互式应用,停顿也是可接受的,背后的原理是年轻带的垃圾回收时间通常是相当短的。
通过一个示例过程可以从gc日志中对比观察:
package com.dxz.jvm; public class OOMPermTest { public static int M = 1024 << 10; public static void main(String[] args) { for(int i =0; i<60; i++) { oom(); } } private static void oom() { Object[] array = new Object[10000000]; for (int i = 0; i < 10000000; i++) { String d = String.valueOf(i).intern(); array[i] = d; //System.out.println(i); } try { Thread.sleep(1); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
启动时加如下JVM参数:
-XX:MaxMetaspaceSize=8m -XX:CompressedClassSpaceSize=8m -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails
结果:GC日志片段
[GC (CMS Initial Mark) [1 CMS-initial-mark: 68797K(87424K)] 73848K(126720K), 0.0009629 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [CMS-concurrent-mark-start] [CMS-concurrent-mark: 0.049/0.049 secs] [Times: user=0.08 sys=0.01, real=0.05 secs] [CMS-concurrent-preclean-start] [CMS-concurrent-preclean: 0.001/0.001 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [CMS-concurrent-abortable-preclean-start] [GC (Allocation Failure) [ParNew: 39296K->4352K(39296K), 0.0585854 secs] 108093K->108083K(143616K), 0.0586158 secs] [Times: user=0.17 sys=0.02, real=0.06 secs] [CMS-concurrent-abortable-preclean: 0.433/0.492 secs] [Times: user=1.05 sys=0.02, real=0.49 secs] [GC (CMS Final Remark) [YG occupancy: 22523 K (39296 K)][Rescan (parallel) , 0.0020975 secs][weak refs processing, 0.0000055 secs][class unloading, 0.0001655 secs][scrub symbol table, 0.0002662 secs][scrub string table, 0.0135212 secs][1 CMS-remark: 103731K(104320K)] 126254K(143616K), 0.0161686 secs] [Times: user=0.02 sys=0.00, real=0.02 secs] [CMS-concurrent-sweep-start] [CMS-concurrent-sweep: 0.019/0.019 secs] [Times: user=0.03 sys=0.00, real=0.02 secs] [CMS-concurrent-reset-start] [CMS-concurrent-reset: 0.001/0.001 secs] [Times: user=0.03 sys=0.00, real=0.00 secs] [GC (Allocation Failure) [ParNew: 39296K->4352K(39296K), 0.0562231 secs] 143025K->143024K(212180K), 0.0562504 secs] [Times: user=0.19 sys=0.00, real=0.06 secs] [GC (CMS Initial Mark) [1 CMS-in
挑战
当我们在真实的应用中使用CMS收集器时,我们会面临两个主要的挑战,可能需要进行调优:
- 堆碎片
- 对象分配率高
堆碎片是有可能的,不像吞吐量收集器,CMS收集器并没有任何碎片整理的机制。因此,应用程序有可能出现这样的情形,即使总的堆大小远没有耗尽,但却不能分配对象——仅仅是因为没有足够连续的空间完全容纳对象。当这种事发生后,并发算法不会帮上任何忙,因此,万不得已JVM会触发Full GC。回想一下,Full GC 将运行吞吐量收集器的算法,从而解决碎片问题——但却暂停了应用程序线程。因此尽管CMS收集器带来完全的并发性,但仍然有可能发生长时间的“stop-the-world”的风险。这是“设计”,而不能避免的——我们只能通过调优收集器来它的可能性。想要100%保证避免”stop-the-world”,对于交互式应用是有问题的。
第二个挑战就是应用的对象分配率高。如果获取对象实例的频率高于收集器清除堆里死对象的频率,并发算法将再次失败。从某种程度上说,老年代将没有足够的可用空间来容纳一个从年轻代提升过来的对象。这种情况被称为“并发模式失败”,并且JVM会执行堆碎片整理:触发Full GC。
当这些情形之一出现在实践中时(经常会出现在生产系统中),经常被证实是老年代有大量不必要的对象。一个可行的办法就是增加年轻代的堆大小,以防止年轻代短生命的对象提前进入老年代。另一个办法就似乎利用分析器,快照运行系统的堆转储,并且分析过度的对象分配,找出这些对象,最终减少这些对象的申请。
CMS 晋升失败(promotion failed)和并发模式失效(concurrent mode failure)产生的原因以及解决的方案
第一个问题promotion failed是在进行Minor GC时,Survivor Space放不下,对象只能放入老年代,而此时老年代也放不下造成的,多数是由于老年带有足够的空闲空间,但是由于碎片较多,这时如果新生代要转移到老年带的对象比较大,所以,必须尽可能提早触发老年代的CMS回收来避免这个问题(promotion failed时老年代CMS还没有机会进行回收,又放不下转移到老年带的对象,因此会出现下一个问题concurrent mode failure,需要stop-the-wold GC- Serail Old)。
下面是一个promotion failed的一条gc日志:
106.641: [GC 106.641: [ParNew (promotion failed): 14784K->14784K(14784K), 0.0370328 secs]106.678: [CMS106.715: [CMS-concurrent-mark: 0.065/0.103 secs] [Times: user=0.17 sys=0.00, real=0.11 secs] (concurrent mode failure): 41568K->27787K(49152K), 0.2128504 secs] 52402K->27787K(63936K), [CMS Perm : 2086K->2086K(12288K)], 0.2499776 secs] [Times: user=0.28 sys=0.00, real=0.25 secs]
第二个问题concurrent mode failure是在执行CMS GC的过程中同时业务线程将对象放入老年代,而此时老年代空间不足,这时CMS还没有机会回收老年带产生的,或者在做Minor GC的时候,新生代救助空间放不下,需要放入老年代,而老年代也放不下而产生的。
尽管CMS使用一个叫做分配担保的机制,每次Minor GC之后要保证新生代的空间survivor + eden > 老年带的空闲时间,但是对象分配是不可预测的,总会有写对象分配在老年带是满足不了的。
下面是一个concurrent mode failure的一条gc日志:
0.195: [GC 0.195: [ParNew: 2986K->2986K(8128K), 0.0000083 secs]0.195: [CMS0.212: [CMS-concurrent-preclean: 0.011/0.031 secs] [Times: user=0.03 sys=0.02, real=0.03 secs]
(concurrent mode failure): 56046K->138K(57344K), 0.0271519 secs] 59032K->138K(65472K), [CMS Perm : 2079K->2078K(12288K)], 0.0273119 secs] [Times: user=0.03 sys=0.00, real=0.03 secs]
下面我们详细的分析这两个问题产生的原因以及如何进行解决。
首先我们经常遇到promotion failed问题,这也确实是个很头痛的问题,一般是进行Minor GC的时候,发现救助空间不够,所以,需要移动一些新生带的对象到老年带,然而,有些时候尽管老年带有足够的空间,但是由于CMS采用标记清除算法,默认并不使用标记整理算法,可能会产生很多碎片,因此,这些碎片无法完成大对象向老年带转移,因此需要进行CMS在老年带的Full GC来合并碎片。
这个问题的直接影响就是它会导致提前进行CMS Full GC, 尽管这个时候CMS的老年带并没有填满,只不过有过多的碎片而已,但是Full GC导致的stop-the-wold是难以接受的。
解决这个问题的办法就是可以让CMS在进行一定次数的Full GC(标记清除)的时候进行一次标记整理算法,CMS提供了以下参数来控制:
-XX:UseCMSCompactAtFullCollection -XX:CMSFullGCBeforeCompaction=5
也就是CMS在进行5次Full GC(标记清除)之后进行一次标记整理算法,从而可以控制老年带的碎片在一定的数量以内,甚至可以配置CMS在每次Full GC的时候都进行内存的整理。
另外,有些应用存在比较大的对象朝生熄灭,这些对象在救助空间无法容纳,因此,会提早进入老年带,老年带如果有碎片,也会产生promotion failed, 因此我们应该控制这样的对象在新生代,然后在下次Minor GC的时候就被回收掉,这样避免了过早的进行CMS Full GC操作,下面的一个配置样例就通过增加救助空间的大小来解决这个问题:
-Xmx4000M -Xms4000M -Xmn600M -XXmSize=500M -XX:MaxPermSize=500M -Xss256K -XX:+DisableExplicitGC -XX:SurvivorRatio=1 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled eCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:LargePageSizeInBytes=128M -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:log/gc.log上面讨论了promotion failed引起的原因以及解决方案,除了promotion failed还有一个情况会引起CMS回收失败,从而退回到Serial Old收集器进行回收,我们在线上尤其要注意的是concurrent mode failure出现的频率,这可以通过-XX:+PrintGCDetails来观察,当出现concurrent mode failure的现象时,就意味着此时JVM将继续采用Stop-The-World的方式来进行Full GC,这种情况下,CMS就没什么意义了,造成concurrent mode failure的原因是当minor GC进行时,旧生代所剩下的空间小于Eden区域+From区域的空间,或者在CMS执行老年带的回收时有业务线程试图将大的对象放入老年带,导致CMS在老年带的回收慢于业务对象对老年带内存的分配。
解决这个问题的通用方法是调低触发CMS GC执行的阀值,CMS GC触发主要由CMSInitiatingOccupancyFraction值决定,默认情况是当旧生代已用空间为68%时,即触发CMS GC,在出现concurrent mode failure的情况下,可考虑调小这个值,提前CMS GC的触发,以保证旧生代有足够的空间。
总结:
1. promotion failed – concurrent mode failure
Minor GC后, 救助空间容纳不了剩余对象,将要放入老年带,老年带有碎片或者不能容纳这些对象,就产生了concurrent mode failure, 然后进行stop-the-world的Serial Old收集器。
解决办法:-XX:UseCMSCompactAtFullCollection -XX:CMSFullGCBeforeCompaction=5 或者 调大新生代或者救助空间
2. concurrent mode failure
CMS是和业务线程并发运行的,在执行CMS的过程中有业务对象需要在老年带直接分配,例如大对象,但是老年带没有足够的空间来分配,所以导致concurrent mode failure, 然后需要进行stop-the-world的Serial Old收集器。
解决办法:+XX:CMSInitiatingOccupancyFraction,调大老年带的空间,+XX:CMSMaxAbortablePrecleanTime
初始老年代空间中的对象是连续的,也就是没有碎片。当老年代空间占用到达70%时,并发回收就开始了。一个CMS后台线程开始扫描老年代空间,寻找无用的垃圾对象时,竞争就开始了:CMS收集器必须在老年代剩余的空间30%用尽之前,完成老年代空间的扫描及回收工作。如果并发回收再这场速度的比赛中失利,CMS收集器就会发生并发模式失效。
有以下途径可以避免发生这种失效:
- 想办法增大老年代空间,要么只移动部分的新生代对象到老年代,要么增加更多的堆空间。
- 以更高的频率运行后台回收线程(提早进行CMS操作)。
- 使用更多的后台回收线程。
- 使用标记整理清除碎片(让CMS在进行一定次数的Full GC(标记清除)的时候进行一次标记整理算法)。
自适应调优和CMS垃圾搜集
CMS可以使用这些标志可以设置相应的性能指标:-XX:MaxGCPauseMillis=N和-XX:GCTimeRatio=N来确定使用多大的堆和多大的代空间。
CMS收集器和其他的垃圾收集算法一个显著不同是除非发生Full GC,否则CMS的新生代大小不会作调整。由于CMS的目标是尽量避免Full GC,这意味着使用精细调优的CMS收集器的应用程序永远不会调整它的新生代大小。
1、给后台线程更多的运行机会
为了让CMS收集器赢得这场比赛,方法之一是更早地启动并发收集周期。如果在老年代空间占用60%时启动并发周期,这和老年代空间占用到70%时才启动相比,前者完成垃圾收集的几率更大。通过设置:-XX:CMSInitiatingOccupancyFraction=N和-XX:+UseCMSInitiatingOccupancyOnly帮助CMS更容易进行决策:如果同时设置这两个标志,那么CMS就只依据设置的老年代空间占用率来决定何时启动后台线程。效果可以从gc日志中的初始标记(CMS Initial Mark)信息的一行包含了CMS周期启动时,老年代空间占用情况:

如上的示例中,老年代空间大小为1398MB,其中702MB被占用。这样需要XX:CMSInitiatingOccupancyFraction(默认值为70)设置为小于50的某个值。
CPU取舍
如果CPU资源相对于应用来说不是很盈余,CMS后台线程可能没有线程运行,因此,应用程序线程和CMS线程会竞争CPU资源,而这很可能会导致CMS线程的“失速”(lose its race)。
应用程序的停顿取舍
CMS会再特定阶段会暂停所有的应用线程,使用CMS收集器的主要目的就是要限制GC停顿的影响,因此频繁地运行更多无效的CMS周期只能适得其反。CMS停顿的时间与新生代的停顿时间比较起来短的多,应用线程可能感受不到这些额外的停顿--这是一种取舍,我们是要避免额外的停顿还是要减少发送并发模式失败的几率。
2、调整CMS后台线程
每个CMS后台线程都会100%地占用一颗CPU。如果应用程序发送并发模式失效,同时又有额外的CPU周期可用,可以设置 -XX:ConcGCThreads=N,增加后台线程的数量。
CMS收集器的永久代调优
从CMS垃圾收集日志中发现,如果永久代需要进行垃圾收集,就会发生Full GC(如果元空间大小需要调整也会发生同样的情况)。
java7默认情况下,CMS的线程不会处理永久代的垃圾,如果永久代用尽,CMS会发起一次Full GC来回收其中的垃圾对象。除此之外,还可以开启-XX:+CMSPermGenSweepingEnabled(默认是false),开启后,永久代中的垃圾使用与老年代同样的方式进行垃圾收集:通过一组后台线程并发地回收永久代中的垃圾对象。注意,除非永久代垃圾回收的指标与老年代的指标是相互独立的。使用-XX:CMSInitiatingOccupancyFraction=N参数可以指定CMS收集器在永久代空间占用比达到设定值时启动永久代垃圾回收线程,这个参数的默认值为80%。
开启永久代垃圾收集只是整个流程中的一步,为了真正释放不再被引用的类,我们还需要设置-XX:+CMSClassUnloadingEnabled,否则,即使启用永久代垃圾回收也只能释放少量的无效对象,类的元数据并不会被释放。由于永久代中有大量的类的元数据信息,因此,CMS永久代垃圾收集开启时,不要忘了对元数据收集的开启。
java8中,CMS默认就会收集元空间中不再载入的类。如果某种原因想关闭这一功能,可以通过-XX:+CMSClassUnloadingEnabled进行关闭(java8中默认开启)。
增量式CMS收集器(iCMS)
CMS垃圾收集,需要消耗额外的CPU处理资源。如果你只有一个单CPU的机器,或者你有多个非常忙碌的CPU,但是希望使用低延时垃圾收集器,可以使用CMS收集器进行增量式的垃圾收集。增量式CMS是单线程中间断性的暂停和收集,有助于整个系统吞吐量。通过-XX:+CMSIncrementalMode开启。
提醒一点,java8不建议使用了iCMS了,可能在java9中删除。
CMS收集器调优相关的JVM标志参数
下面我看看大多数与CMS收集器调优相关的JVM标志参数。
-XX:+UseConcMarkSweepGC
该标志首先是激活CMS收集器。默认HotSpot JVM使用的是并行收集器。
-XX:UseParNewGC
当使用CMS收集器时,该标志激活年轻代使用多线程并行执行垃圾回收。这令人很惊讶,我们不能简单在并行收集器中重用-XX:UserParNewGC标志,因为概念上年轻代用的算法是一样的。然而,对于CMS收集器,年轻代GC算法和老年代GC算法是不同的,因此年轻代GC有两种不同的实现,并且是两个不同的标志。
注意最新的JVM版本,当使用-XX:+UseConcMarkSweepGC时,-XX:UseParNewGC会自动开启。因此,如果年轻代的并行GC不想开启,可以通过设置-XX:-UseParNewGC来关掉。
-XX:+CMSConcurrentMTEnabled
当该标志被启用时,并发的CMS阶段将以多线程执行(因此,多个GC线程会与所有的应用程序线程并行工作)。该标志已经默认开启,如果顺序执行更好,这取决于所使用的硬件,多线程执行可以通过-XX:-CMSConcurremntMTEnabled禁用。
-XX:ConcGCThreads
标志-XX:ConcGCThreads=<value>(早期JVM版本也叫-XX:ParallelCMSThreads)定义并发CMS过程运行时的线程数。比如value=4意味着CMS周期的所有阶段都以4个线程来执行。尽管更多的线程会加快并发CMS过程,但其也会带来额外的同步开销。因此,对于特定的应用程序,应该通过测试来判断增加CMS线程数是否真的能够带来性能的提升。
如果还标志未设置,JVM会根据并行收集器中的-XX:ParallelGCThreads参数的值来计算出默认的并行CMS线程数。该公式是ConcGCThreads = (ParallelGCThreads + 3)/4。因此,对于CMS收集器, -XX:ParallelGCThreads标志不仅影响“stop-the-world”垃圾收集阶段,还影响并发阶段。
总之,有不少方法可以配置CMS收集器的多线程执行。正是由于这个原因,建议第一次运行CMS收集器时使用其默认设置, 然后如果需要调优再进行测试。只有在生产系统中测量(或类生产测试系统)发现应用程序的暂停时间的目标没有达到 , 就可以通过这些标志应该进行GC调优。
-XX:CMSInitiatingOccupancyFraction
当堆满之后,并行收集器便开始进行垃圾收集,例如,当没有足够的空间来容纳新分配或提升的对象。对于CMS收集器,长时间等待是不可取的,因为在并发垃圾收集期间应用持续在运行(并且分配对象)。因此,为了在应用程序使用完内存之前完成垃圾收集周期,CMS收集器要比并行收集器更先启动。
因为不同的应用会有不同对象分配模式,JVM会收集实际的对象分配(和释放)的运行时数据,并且分析这些数据,来决定什么时候启动一次CMS垃圾收集周期。为了引导这一过程, JVM会在一开始执行CMS周期前作一些线索查找。该线索由 -XX:CMSInitiatingOccupancyFraction=<value>来设置,该值代表老年代堆空间的使用率。比如,value=75意味着第一次CMS垃圾收集会在老年代被占用75%时被触发。通常CMSInitiatingOccupancyFraction的默认值为68(之前很长时间的经历来决定的)。
-XX:+UseCMSInitiatingOccupancyOnly
我们用-XX+UseCMSInitiatingOccupancyOnly标志来命令JVM不基于运行时收集的数据来启动CMS垃圾收集周期。而是,当该标志被开启时,JVM通过CMSInitiatingOccupancyFraction的值进行每一次CMS收集,而不仅仅是第一次。然而,请记住大多数情况下,JVM比我们自己能作出更好的垃圾收集决策。因此,只有当我们充足的理由(比如测试)并且对应用程序产生的对象的生命周期有深刻的认知时,才应该使用该标志。
-XX:+CMSClassUnloadingEnabled
相对于并行收集器,CMS收集器默认不会对永久代进行垃圾回收。如果希望对永久代进行垃圾回收,可用设置标志-XX:+CMSClassUnloadingEnabled。在早期JVM版本中,要求设置额外的标志-XX:+CMSPermGenSweepingEnabled。注意,即使没有设置这个标志,一旦永久代耗尽空间也会尝试进行垃圾回收,但是收集不会是并行的,而再一次进行Full GC。
-XX:+CMSIncrementalMode
该标志将开启CMS收集器的增量模式。增量模式经常暂停CMS过程,以便对应用程序线程作出完全的让步。因此,收集器将花更长的时间完成整个收集周期。因此,只有通过测试后发现正常CMS周期对应用程序线程干扰太大时,才应该使用增量模式。由于现代服务器有足够的处理器来适应并发的垃圾收集,所以这种情况发生得很少。
-XX:+ExplicitGCInvokesConcurrent and -XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses
如今,被广泛接受的最佳实践是避免显式地调用GC(所谓的“系统GC”),即在应用程序中调用system.gc()。然而,这个建议是不管使用的GC算法的,值得一提的是,当使用CMS收集器时,系统GC将是一件很不幸的事,因为它默认会触发一次Full GC。幸运的是,有一种方式可以改变默认设置。标志-XX:+ExplicitGCInvokesConcurrent命令JVM无论什么时候调用系统GC,都执行CMS GC,而不是Full GC。第二个标志-XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses保证当有系统GC调用时,永久代也被包括进CMS垃圾回收的范围内。因此,通过使用这些标志,我们可以防止出现意料之外的”stop-the-world”的系统GC。
-XX:+DisableExplicitGC
然而在这个问题上…这是一个很好提到- XX:+ DisableExplicitGC标志的机会,该标志将告诉JVM完全忽略系统的GC调用(不管使用的收集器是什么类型)。对于我而言,该标志属于默认的标志集合中,可以安全地定义在每个JVM上运行,而不需要进一步思考。

