
微服务监控之三:Prometheus + Grafana Spring Boot 应用可视化监控
一、Springboot增加Prometheus
1、Spring Boot 应用暴露监控指标,添加如下依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <dependency> <groupId>io.prometheus</groupId> <artifactId>simpleclient_spring_boot</artifactId> <version>0.0.26</version> </dependency>
gradle配置:
compile 'org.springframework.boot:spring-boot-starter-actuator'
compile 'io.prometheus:simpleclient_spring_boot:0.0.26'
2、然后,在启动类 Application.java 添加如下注解:
@SpringBootApplication @EnablePrometheusEndpoint @EnableSpringBootMetricsCollector public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } }
3、配置文件设置
在application.xml里设置属性:spring.metrics.servo.enabled=false, 去掉重复的metrics,不然在prometheus的控制台的targets页签里,会一直显示此endpoint为down状态。
#应用可视化监控 management.security.enabled=false spring.metrics.servo.enabled=false
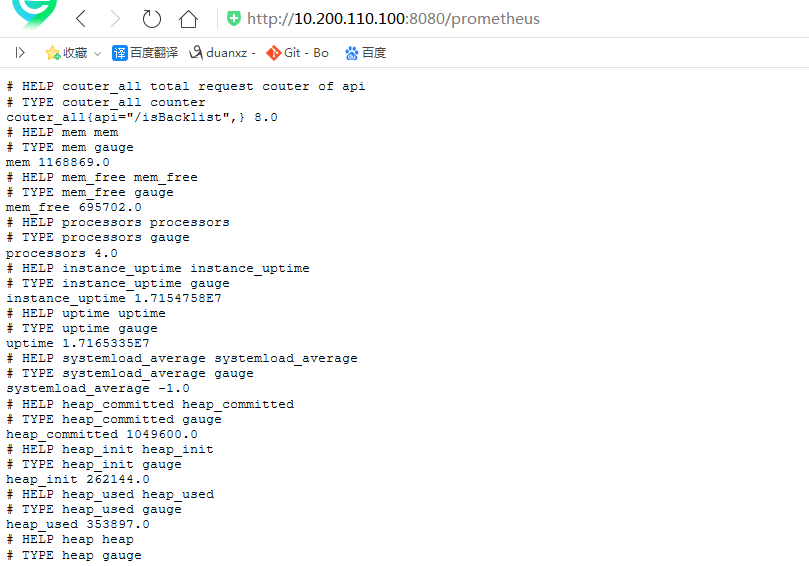
4、访问:http://192.168.10.213:6010/prometheus,可以看到 Prometheus 格式的指标数据
二、自定义prometheus注解
2.1、自定义prometheus注解
import java.lang.annotation.*; @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface PrometheusMetrics { /** * 默认为空,程序使用method signature作为Metric name 如果name有设置值,使用name作为Metric name * * @return */ String name() default ""; }
2.2、自定义prometheus切面
import io.prometheus.client.Counter; import io.prometheus.client.Histogram; import org.apache.commons.lang3.StringUtils; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Pointcut; import org.aspectj.lang.reflect.MethodSignature; import org.springframework.stereotype.Component; import org.springframework.web.context.request.RequestContextHolder; import org.springframework.web.context.request.ServletRequestAttributes; import javax.servlet.http.HttpServletRequest; @Aspect @Component public class PrometheusMetricsAspect { private static final Counter requestTotal = Counter.build().name("couter_all").labelNames("api") .help("total request couter of api").register(); private static final Counter requestError = Counter.build().name("couter_error").labelNames("api") .help("response Error couter of api").register(); private static final Histogram histogram = Histogram.build().name("histogram_consuming").labelNames("api") .help("response consuming of api").register(); // 自定义Prometheus注解的全路径 @Pointcut("@annotation(com....annotation.PrometheusMetrics)") public void pcMethod() { } @Around(value = "pcMethod() && @annotation(annotation)") public Object MetricsCollector(ProceedingJoinPoint joinPoint, PrometheusMetrics annotation) throws Throwable { MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature(); PrometheusMetrics prometheusMetrics = methodSignature.getMethod().getAnnotation(PrometheusMetrics.class); if (prometheusMetrics != null) { String name; if (StringUtils.isNotEmpty(prometheusMetrics.name())) { name = prometheusMetrics.name(); } else { HttpServletRequest request = ((ServletRequestAttributes) RequestContextHolder.getRequestAttributes()) .getRequest(); name = request.getRequestURI(); } requestTotal.labels(name).inc(); Histogram.Timer requestTimer = histogram.labels(name).startTimer(); Object object; try { object = joinPoint.proceed(); } catch (Exception e) { requestError.labels(name).inc(); throw e; } finally { requestTimer.observeDuration(); } return object; } else { return joinPoint.proceed(); } } }
2.3、被监控的方法上添加--自定义prometheus注解
@PrometheusMetrics @PostMapping(value = "isBacklist") @ApiOperation(value = "黑名单判断", notes = "是否在黑名单中,如果存在并且记录状态为2,则为黑名单,返回true,否则返回:false") @Log public RespResult<Boolean> isBacklist(@RequestBody BacklistReqDTO reqDTO) {
三、Prometheus 采集 Spring Boot 指标数据
首先,获取 Prometheus 的 Docker 镜像:
docker pull prom/prometheus
3.1、然后,编写配置文件 prometheus.yml :
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['10.200.110.100:8080'] #此处填写 Spring Boot 应用的 IP + 端口号
3.2、接着,启动 Prometheus :
docker run -d -p 9090:9090 \ -u root \ -v /opt/prometheus/tsdb:/etc/prometheus/tsdb \ -v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \ --privileged=true prom/prometheus \ --storage.tsdb.path=/etc/prometheus/tsdb \ --storage.tsdb.retention=7d \ --config.file=/etc/prometheus/prometheus.yml
非docker环境的启动方式:
./prometheus --config.file=prometheus2.yml
结果:
duanxz@ubuntu:~/Downloads/prometheus-2.0.0.linux-amd64$ ./prometheus --config.file=prometheus2.yml level=info ts=2018-06-19T08:27:47.222527495Z caller=main.go:215 msg="Starting Prometheus" version="(version=2.0.0, branch=HEAD, revision=0a74f98628a0463dddc90528220c94de5032d1a0)" level=info ts=2018-06-19T08:27:47.222895906Z caller=main.go:216 build_context="(go=go1.9.2, user=root@615b82cb36b6, date=20171108-07:11:59)" level=info ts=2018-06-19T08:27:47.223110655Z caller=main.go:217 host_details="(Linux 4.4.0-128-generic #154~14.04.1-Ubuntu SMP Fri May 25 14:58:51 UTC 2018 x86_64 ubuntu (none))" level=info ts=2018-06-19T08:27:47.227443134Z caller=web.go:380 component=web msg="Start listening for connections" address=0.0.0.0:9090 level=info ts=2018-06-19T08:27:47.234616341Z caller=main.go:314 msg="Starting TSDB" level=info ts=2018-06-19T08:27:47.244932582Z caller=targetmanager.go:71 component="target manager" msg="Starting target manager..." level=info ts=2018-06-19T08:27:47.24608357Z caller=main.go:326 msg="TSDB started" level=info ts=2018-06-19T08:27:47.246514727Z caller=main.go:394 msg="Loading configuration file" filename=prometheus2.yml level=info ts=2018-06-19T08:27:47.247799187Z caller=main.go:371 msg="Server is ready to receive requests."
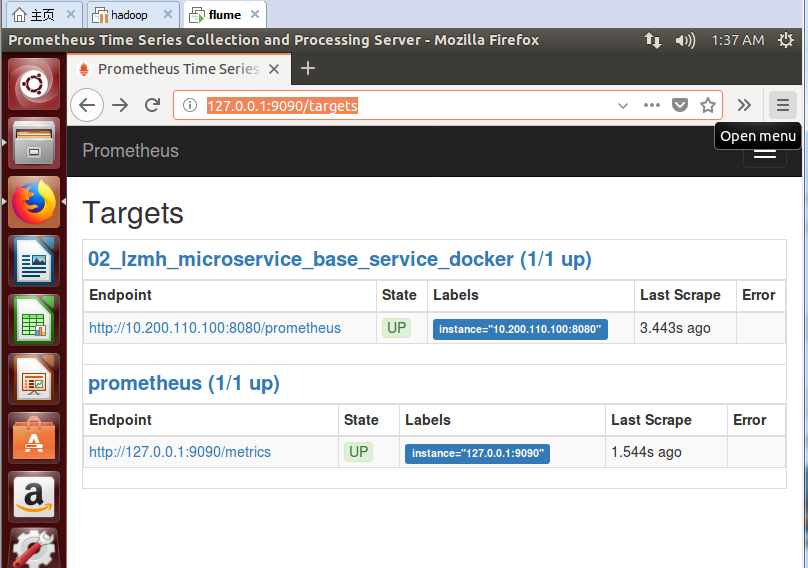
最后,访问 http://127.0.0.1:9090/targets , 检查 Spring Boot 采集状态是否正常。
四、Grafana 可视化监控数据
首先,获取 Grafana 的 Docker 镜像:
docker pull grafana/grafana
然后,启动 Grafana:
docker run -d -p 3000:3000 \
-v /opt/grafana:/var/lib/grafana \
-e "GF_SMTP_ENABLED=true" \
-e "GF_SMTP_HOST=smtp.139.com:25" \
-e "GF_SMTP_USER=13616052510@139.com" \
-e "GF_SMTP_PASSWORD=like110120" \
-e "GF_SMTP_FROM_ADDRESS=13616052510@139.com" \
--privileged=true grafana/grafana
接着,访问 http://localhost:3000/ 配置 Prometheus 数据源:
Grafana 登录账号 admin 密码 admin
五、常用Prometheus 表达式
QPS[5分钟]
rate(lz_http_requests_total{job="02_lzmh_microservice_base_service_docker"}[5m]) > 0
QPS[5分钟],根据handler分组
sum(rate(lz_http_requests_total{job="lzmh_microservice_weixin_applet_api"}[5m])) by (handler) > 0
平均响应时间[5分钟]
(
rate(lz_http_response_time_milliseconds_sum{job="02_lzmh_microservice_base_service_docker"}[5m])
/
rate(lz_http_response_time_milliseconds_count{job="02_lzmh_microservice_base_service_docker"}[5m])
) > 0
平均响应时间[5分钟],根据handler分组
sum(
rate(lz_http_response_time_milliseconds_sum{job="lzmh_microservice_weixin_applet_api"}[5m])
/
rate(lz_http_response_time_milliseconds_count{job="lzmh_microservice_weixin_applet_api"}[5m])
) by (handler) > 0


 浙公网安备 33010602011771号
浙公网安备 33010602011771号