
无限级分类实现思路 (组织树的分级管理)
关于该问题,暂时自己还没有深入研究,在网上找到几种解决方案,各有优缺点。
使用递归算法,也是使用频率最多的,大部分开源程序也是这么处理,不过一般都只用到四级分类。这种算法的数据库结构设计最为简单。category表中一个字段id,一个字段fid(父id)。这样可以根据WHERE id = fid来判断上一级内容,运用递归至最顶层。
分析:通过这种数据库设计出的无限级,可以说读取的时候相当费劲,所以大部分的程序最多3-4级分类,这就足以满足需求,从而一次性读出所有的数据,再对得到数组或者对象进行递归。本身负荷还是没太大问题。但是如果分类到更多级,那是不可取的办法。
这样看来这种分类有个好处,就是增删改的时候轻松了…然而就二级分类而言,采用这种算法就应该算最优先了。
在Oracle 中我们知道有一个 Hierarchical Queries 通过CONNECT BY 我们可以方便的查了所有当前节点下的所有子节点。但很遗憾,在MySQL的目前版本中还没有对应的功能。
在MySQL中如果是有限的层次,比如我们事先如果可以确定这个树的最大深度是4, 那么所有节点为根的树的深度均不会超过4,则我们可以直接通过left join 来实现。
但很多时候我们无法控制树的深度。这时就需要在MySQL中用存储过程来实现或在你的程序中来实现这个递归。本文讨论一下几种实现的方法。
样例数据:
CREATE TABLE treeNodes
(
id INT PRIMARY KEY,
nodename VARCHAR(20),
pid INT
);
mysql> select * from treenodes;
+----+----------+------+
| id | nodename | pid |
+----+----------+------+
| 1 | A | 0 |
| 2 | B | 1 |
| 3 | C | 1 |
| 4 | D | 2 |
| 5 | E | 2 |
| 6 | F | 3 |
| 7 | G | 6 |
| 8 | H | 0 |
| 9 | I | 8 |
| 10 | J | 8 |
| 11 | K | 8 |
| 12 | L | 9 |
| 13 | M | 9 |
| 14 | N | 12 |
| 15 | O | 12 |
| 16 | P | 15 |
| 17 | Q | 15 |
+----+----------+------+
17 rows in set (0.00 sec)
树形图如下
1:A
+-- 2:B
| +-- 4:D
| +-- 5:E
+-- 3:C
+-- 6:F
+-- 7:G
8:H
+-- 9:I
| +-- 12:L
| | +--14:N
| | +--15:O
| | +--16:P
| | +--17:Q
| +-- 13:M
+-- 10:J
+-- 11:K
实现方法示例:
方法一:利用函数来得到所有子节点号。
创建一个function getChildLst, 得到一个由所有子节点号组成的字符串.

delimiter //
CREATE FUNCTION `getChildList`(rootId INT)
RETURNS varchar(1000)
BEGIN
DECLARE sTemp VARCHAR(1000);
DECLARE sTempChd VARCHAR(1000);
SET sTemp = '$';
SET sTempChd =cast(rootId as CHAR);
WHILE sTempChd is not null DO
SET sTemp = concat(sTemp,',',sTempChd);
SELECT group_concat(id) INTO sTempChd FROM treeNodes where FIND_IN_SET(pid,sTempChd)>0;
END WHILE;
RETURN sTemp;
END
//
delimiter ;
获取所有父节点:
delimiter // CREATE FUNCTION `getParentList`(rootId INT) RETURNS varchar(1000) BEGIN DECLARE sParentList varchar(1000); DECLARE sParentTemp varchar(1000); SET sParentTemp =cast(rootId as CHAR); WHILE sParentTemp is not null DO IF (sParentList is not null) THEN SET sParentList = concat(sParentTemp,',',sParentList); ELSE SET sParentList = concat(sParentTemp); END IF; SELECT group_concat(pid) INTO sParentTemp FROM treeNodes where FIND_IN_SET(id,sParentTemp)>0; END WHILE; RETURN sParentList; END // delimiter ; /*获取父节点*/ /*调用: 1、select getParentList(6) id; 2、select * From user_role where FIND_IN_SET(id, getParentList(2));*/
select getParentList(4);

使用我们直接利用find_in_set函数配合这个getChildlst来查找
mysql> select getChildList(1);
+-----------------+
| getChildLst(1) |
+-----------------+
| $,1,2,3,4,5,6,7 |
+-----------------+
1 row in set (0.00 sec)
mysql> select * from treeNodes
-> where FIND_IN_SET(id, getChildList(1));
+----+----------+------+
| id | nodename | pid |
+----+----------+------+
| 1 | A | 0 |
| 2 | B | 1 |
| 3 | C | 1 |
| 4 | D | 2 |
| 5 | E | 2 |
| 6 | F | 3 |
| 7 | G | 6 |
+----+----------+------+
7 rows in set (0.01 sec)
mysql> select * from treeNodes
-> where FIND_IN_SET(id, getChildList(3));
+----+----------+------+
| id | nodename | pid |
+----+----------+------+
| 3 | C | 1 |
| 6 | F | 3 |
| 7 | G | 6 |
+----+----------+------+
3 rows in set (0.01 sec)
优点: 简单,方便,没有递归调用层次深度的限制 (max_sp_recursion_depth,最大255) ;
缺点:长度受限,虽然可以扩大 RETURNS varchar(1000),但总是有最大限制的。
MySQL目前版本( 5.1.33-community)中还不支持function 的递归调用。
方法二:利用临时表和过程递归
创建存储过程如下。createChildLst 为递归过程,showChildLst为调用入口过程,准备临时表及初始化。
DELIMITER // # 入口过程 CREATE PROCEDURE showChildLst (IN rootId INT) BEGIN CREATE TEMPORARY TABLE IF NOT EXISTS tmpLst (sno INT PRIMARY KEY AUTO_INCREMENT,id INT,depth INT); DELETE FROM tmpLst; CALL createChildLst(rootId,0); SELECT tmpLst.*,treeNodes.* FROM tmpLst,treeNodes WHERE tmpLst.id=treeNodes.id ORDER BY tmpLst.sno; END; // DELIMITER ;
DELIMITER //
# 递归过程
CREATE PROCEDURE createChildLst (IN rootId INT,IN nDepth INT)
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE b INT;
DECLARE cur1 CURSOR FOR SELECT id FROM treeNodes WHERE pid=rootId;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1;
INSERT INTO tmpLst VALUES (NULL,rootId,nDepth);
OPEN cur1;
FETCH cur1 INTO b;
WHILE done=0 DO
CALL createChildLst(b,nDepth+1);
FETCH cur1 INTO b;
END WHILE;
CLOSE cur1;
END;
//
DELIMITER ;
调用时传入结点
mysql> call showChildLst(1);
+-----+------+-------+----+----------+------+
| sno | id | depth | id | nodename | pid |
+-----+------+-------+----+----------+------+
| 4 | 1 | 0 | 1 | A | 0 |
| 5 | 2 | 1 | 2 | B | 1 |
| 6 | 4 | 2 | 4 | D | 2 |
| 7 | 5 | 2 | 5 | E | 2 |
| 8 | 3 | 1 | 3 | C | 1 |
| 9 | 6 | 2 | 6 | F | 3 |
| 10 | 7 | 3 | 7 | G | 6 |
+-----+------+-------+----+----------+------+
7 rows in set (0.13 sec)
Query OK, 0 rows affected, 1 warning (0.14 sec)
mysql>
mysql> call showChildLst(3);
+-----+------+-------+----+----------+------+
| sno | id | depth | id | nodename | pid |
+-----+------+-------+----+----------+------+
| 1 | 3 | 0 | 3 | C | 1 |
| 2 | 6 | 1 | 6 | F | 3 |
| 3 | 7 | 2 | 7 | G | 6 |
+-----+------+-------+----+----------+------+
3 rows in set (0.11 sec)
Query OK, 0 rows affected, 1 warning (0.11 sec)
depth 为深度,这样可以在程序进行一些显示上的格式化处理。类似于oracle中的 level 伪列。sno 仅供排序控制。这样你还可以通过临时表tmpLst与数据库中其它表进行联接查询。
MySQL中你可以利用系统参数 max_sp_recursion_depth 来控制递归调用的层数上限。如下例设为12.
mysql> set max_sp_recursion_depth=12;
Query OK, 0 rows affected (0.00 sec)
优点 : 可以更灵活处理,及层数的显示。并且可以按照树的遍历顺序得到结果。
缺点 : 递归有255的限制。
方法三:利用中间表和过程
(本方法由yongyupost2000提供样子改编)
创建存储过程如下。由于MySQL中不允许在同一语句中对临时表多次引用,只以使用普通表tmpLst来实现了。当然你的程序中负责在用完后清除这个表。
DELIMITER //
DROP PROCEDURE IF EXISTS showTreeNodes_yongyupost2000//
CREATE PROCEDURE showTreeNodes_yongyupost2000 (IN rootid INT)
BEGIN
DECLARE LEVEL INT ;
DROP TABLE IF EXISTS tmpLst;
CREATE TABLE tmpLst (
id INT,
nLevel INT,
sCort VARCHAR(8000)
);
SET LEVEL=0 ;
INSERT INTO tmpLst SELECT id,LEVEL,ID FROM treeNodes WHERE PID=rootid;
WHILE ROW_COUNT()>0 DO
SET LEVEL=LEVEL+1 ;
INSERT INTO tmpLst
SELECT A.ID,LEVEL,CONCAT(B.sCort,A.ID) FROM treeNodes A,tmpLst B
WHERE A.PID=B.ID AND B.nLevel=LEVEL-1 ;
END WHILE;
SELECT tmpLst.*,treeNodes.* FROM tmpLst,treeNodes WHERE tmpLst.id=treeNodes.id ORDER BY tmpLst.id;
END;
//
DELIMITER ;
CALL showTreeNodes_yongyupost2000(1);
执行完后会产生一个tmpLst表,nLevel 为节点深度,sCort 为排序字段。
使用方法
SELECT concat(SPACE(B.nLevel*2),'+--',A.nodename)
FROM treeNodes A,tmpLst B
WHERE A.ID=B.ID
ORDER BY B.sCort;
+--------------------------------------------+
| concat(SPACE(B.nLevel*2),'+--',A.nodename) |
+--------------------------------------------+
| +--A |
| +--B |
| +--D |
| +--E |
| +--C |
| +--F |
| +--G |
| +--H |
| +--J |
| +--K |
| +--I |
| +--L |
| +--N |
| +--O |
| +--P |
| +--Q |
| +--M |
+--------------------------------------------+
17 rows in set (0.00 sec)
优点 : 层数的显示。并且可以按照树的遍历顺序得到结果。没有递归限制。
缺点 : MySQL中对临时表的限制,只能使用普通表,需做事后清理。
以上是几个在MySQL中用存储过程比较简单的实现方法。
第二种方案:
设置fid字段类型为varchar,将父类id都集中在这个字段里,用符号隔开,比如:1,3,6
这样可以比较容易得到各上级分类的ID,而且在查询分类下的信息的时候,
可以使用:SELECT * FROM category WHERE pid LIKE “1,3%”。
分析:相比于递归算法,在读取数据方面优势非常大,但是若查找该分类的所有 父分类 或者 子分类 查询的效率也不是很高,至少也要二次query,从某种意义看上,个人觉得不太符合数据库范式的设计。倘若递增到无限级,还需考虑字段是否达到要求,而且在修改分类和转移分类的时候操作将非常麻烦。
暂时,在自己项目中用的就是类似第二种方案的解决办法。就该方案在我的项目中存在这样的问题, 如果当所有数据记录达到上万甚至10W以上后,一次性将所以分类,有序分级的现实出来,效率很低。极有可能是项目处理数据代码效率低带来的。现在正在改良。
第三种方案:
无限级分类----改进前序遍历树
那么理想中的树型结构应具备哪些特点呢?数据存储冗余小、直观性强;方便返回整个树型结构数据;可以很轻松的返回某一子树(方便分层加载);快整获以某节点的祖谱路径;插入、删除、移动节点效率高等等。带着这些需求我查找了很多资料,发现了一种理想的树型结构数据存储及操作算法,改进的前序遍历树模型(The Nested Set Model)。
原理:
我们先把树按照水平方式摆开。从根节点开始(“Food”),然后他的左边写上1。然后按照树的顺序(从上到下)给“Fruit”的左边写上2。这样,你沿着树的边界走啊走(这就是“遍历”),然后同时在每个节点的左边和右边写上数字。最后,我们回到了根节点“Food”在右边写上18。下面是标上了数字的树,同时把遍历的顺序用箭头标出来了。
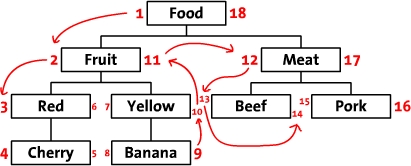
我们称这些数字为左值和右值(如,“Food”的左值是1,右值是18)。正如你所见,这些数字按时了每个节点之间的关系。因为“Red”有3和6两个值,所以,它是有拥有1-18值的“Food”节点的后续。同样的,我们可以推断所有左值大于2并且右值小于11的节点,都是有2-11的“Fruit” 节点的后续。这样,树的结构就通过左值和右值储存下来了。这种数遍整棵树算节点的方法叫做“改进前序遍历树”算法。
表结构设计:
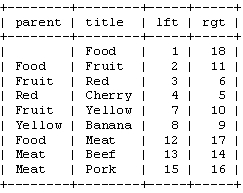
表结构:
--
-- 表的结构 `category`
--
CREATE TABLE IF NOT EXISTS `category` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`type` int(11) NOT NULL COMMENT '1为文章类型2为产品类型3为下载类型',
`title` varchar(50) NOT NULL,
`lft` int(11) NOT NULL,
`rgt` int(11) NOT NULL,
`lorder` int(11) NOT NULL COMMENT '排序',
`create_time` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=10 ;
--
-- 导出表中的数据 `category`
--
INSERT INTO `category` (`id`, `type`, `title`, `lft`, `rgt`, `lorder`, `create_time`) VALUES
(1, 1, '顶级栏目', 1, 18, 1, 1261964806),
(2, 1, '公司简介', 14, 17, 50, 1264586212),
(3, 1, '新闻', 12, 13, 50, 1264586226),
(4, 2, '公司产品', 10, 11, 50, 1264586249),
(5, 1, '荣誉资质', 8, 9, 50, 1264586270),
(6, 3, '资料下载', 6, 7, 50, 1264586295),
(7, 1, '人才招聘', 4, 5, 50, 1264586314),
(8, 1, '留言板', 2, 3, 50, 1264586884),
(9, 1, '总裁', 15, 16, 50, 1267771951);
/**
* 显示树,把所有的节点都显示出来。
* 1、先得到根结点的左右值(默认根节点的title为“顶级目录”)。
* 2、查询左右值在根节点的左右值范围内的记录,并且根据左值排序。
* 3、如果本次记录右值大于前次记录的右值则为子分类,输出时候加空格。
* @return array
**/
function display_tree(){
//获得root左边和右边的值
$arr_lr = $this->category->where("title = '顶级栏目'")->find();
//print_r($arr_lr);
if($arr_lr){
$right = array();
$arr_tree = $this->category->query("SELECT id, type, title, rgt FROM category WHERE lft >= ". $arr_lr['lft'] ." AND lft <=".$arr_lr['rgt']." ORDER BY lft");
foreach($arr_tree as $v){
if(count($right)){
while ($right[count($right) -1] < $v['rgt']){
array_pop($right);
}
}
$title = $v['title'];
if(count($right)){
$title = '|-'.$title;
}
$arr_list[] = array('id' => $v['id'], 'type' => $type, 'title' => str_repeat(' ', count($right)).$title, 'name' =>$v['title']);
$right[] = $v['rgt'];
}
return $arr_list;
}
}
好了 只要这样所有的分类都可以一次性查询出来了,而不用通过递归了。
下面的问题是怎样进行插入、删除和修改操作
插入:插入操作很简单找到其父节点,之后把左值和右值大于父节点左值的节点的左右值加上2,之后再插入本节点,左右值分别为父节点左值加一和加二,可以用一个存储过程来操作:
CREATE PROCEDURE `category_insert_by_parent`(IN pid INT,IN title VARCHAR(20), IN type INT, IN l_order INT, IN pubtime INT)
BEGIN
DECLARE myLeft INT;
SELECT lft into myLeft FROM category WHERE id= pid;
UPDATE qy_category SET rgt = rgt + 2 WHERE rgt > myLeft;
UPDATE qy_category SET lft = lft + 2 WHERE lft > myLeft;
INSERT INTO qy_category(type, title, lft, rgt, lorder, create_time) VALUES(type ,title, myLeft + 1, myLeft + 2, l_order, pubtime);
commit;
END
删除操作:
删除的原理:1.得到要删除节点的左右值,并得到他们的差再加一,@mywidth = @rgt - @lft + 1;
2.删除左右值在本节点之间的节点
3.修改条件为大于本节点右值的所有节点,操作为把他们的左右值都减去@mywidth
存储过程如下:
CREATE PROCEDURE `category_delete_by_key`(IN id INT)
BEGIN
SELECT @myLeft := lft, @myRight := rgt, @myWidth := rgt - lft + 1
FROM category
WHERE id = id;
DELETE FROM category WHERE lft BETWEEN @myLeft AND @myRight;
UPDATE nested_category SET rgt = rgt - @myWidth WHERE rgt > @myRight;
UPDATE nested_category SET lft = lft - @myWidth WHERE lft > @myRight;
修改:
要命的修改操作,本人看了很久也没有看出什么规律出来,只要出此下策,先删除再插入,只要调用上面2个存储过程就可以了!
总结:查询方便,但是增删改操作有点繁琐,但是一般分类此类操作不是很多,还是查询用的多,再说弄个存储过程也方便!
上面第三种方案具体讲解类容是从http://home.phpchina.com/space.php?uid=45095&do=blog&id=184675拷贝过来,方便以后自己查看。 暂时从各方面及理论上考虑 偏向于第三方案。不过还没有做过测试,到底效率怎么样。
期待更好的解决方案!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号