


Redis多个数据库
注意:Redis支持多个数据库,并且每个数据库的数据是隔离的不能共享,并且基于单机才有,如果是集群就没有数据库的概念。
Redis是一个字典结构的存储服务器,而实际上一个Redis实例提供了多个用来存储数据的字典,客户端可以指定将数据存储在哪个字典中。这与我们熟知的在一个关系数据库实例中可以创建多个数据库类似,所以可以将其中的每个字典都理解成一个独立的数据库。
每个数据库对外都是一个从0开始的递增数字命名,Redis默认支持16个数据库(可以通过配置文件支持更多,无上限),可以通过配置databases来修改这一数字。客户端与Redis建立连接后会自动选择0号数据库,不过可以随时使用SELECT命令更换数据库,如要选择1号数据库:
redis> SELECT 1 OK redis [1] > GET foo (nil)
然而这些以数字命名的数据库又与我们理解的数据库有所区别。首先Redis不支持自定义数据库的名字,每个数据库都以编号命名,开发者必须自己记录哪些数据库存储了哪些数据。另外Redis也不支持为每个数据库设置不同的访问密码,所以一个客户端要么可以访问全部数据库,要么连一个数据库也没有权限访问。最重要的一点是多个数据库之间并不是完全隔离的,比如FLUSHALL命令可以清空一个Redis实例中所有数据库中的数据。综上所述,这些数据库更像是一种命名空间,而不适宜存储不同应用程序的数据。比如可以使用0号数据库存储某个应用生产环境中的数据,使用1号数据库存储测试环境中的数据,但不适宜使用0号数据库存储A应用的数据而使用1号数据库B应用的数据,不同的应用应该使用不同的Redis实例存储数据。由于Redis非常轻量级,一个空Redis实例占用的内在只有1M左右,所以不用担心多个Redis实例会额外占用很多内存。
每个数据库都有属于自己的空间,不必担心之间的key冲突。
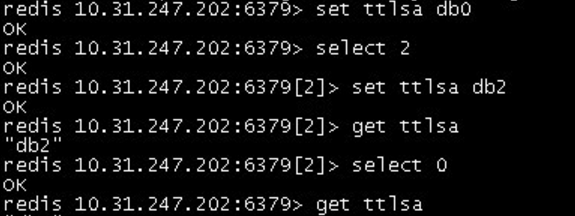
不同的数据库下,相同的key取到各自的值。
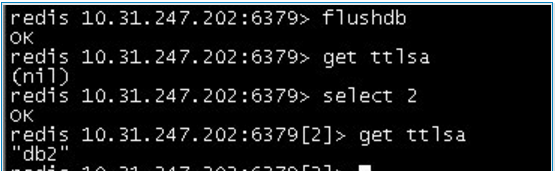
flushdb命令清除数据,只会清除当前的数据库下的数据,不会影响到其他数据库。

flushall命令会清除这个实例的数据。在执行这个命令前要格外小心。
数据库的数量是可以配置的,默认情况下是16个。修改redis.conf下的databases指令:
databases 64
redis没有提供任何方法来关联标识不同的数据库。因此,需要你来跟踪什么数据存储到哪个数据库下。
因此上面的快开启200个实例的场景,可以使用不同的数据库来存储,而不必开启如此那么多的实例。
redis多个数据库 内存怎么分配的
2、当redis 服务器初始化时,会预先分配 16 个数据库(该数量可以通过配置文件配置),所有数据库保存到结构 redisServer 的一个成员 redisServer.db 数组中。当我们选择数据库 select number 时,程序直接通过 redisServer.db[number] 来切换数据库。有时候当程序需要知道自己是在哪个数据库时,直接读取 redisDb.id 即可。
3、既然我们知道一个数据库的所有键值都存储在redisDb.dict中,那么我们要知道如果找到key的位置,就有必要了解一下dict 的结构了:
typedef struct dict {
// 特定于类型的处理函数
dictType *type;
// 类型处理函数的私有数据
void *privdata;
// 哈希表(2个)
dictht ht[2];
// 记录 rehash 进度的标志,值为-1 表示 rehash 未进行
int rehashidx;
// 当前正在运作的安全迭代器数量
int iterators;
} dict;
由上述的结构可以看出,redis 的字典使用哈希表作为其底层实现。dict 类型使用的两个指向哈希表的指针,其中 0 号哈希表(ht[0])主要用于存储数据库的所有键值,而1号哈希表主要用于程序对 0 号哈希表进行 rehash 时使用,rehash 一般是在添加新值时会触发,这里不做过多的赘述。所以redis 中查找一个key,其实就是对进行该dict 结构中的 ht[0] 进行查找操作。
4、既然是哈希,那么我们知道就会有哈希碰撞,那么当多个键哈希之后为同一个值怎么办呢?redis采取链表的方式来存储多个哈希碰撞的键。也就是说,当根据key的哈希值找到该列表后,如果列表的长度大于1,那么我们需要遍历该链表来找到我们所查找的key。当然,一般情况下链表长度都为是1,所以时间复杂度可看作o(1)。
二、当redis 拿到一个key 时,如果找到该key的位置。
了解了上述知识之后,我们就可以来分析redis如果在内存找到一个key了。
1、当拿到一个key后, redis 先判断当前库的0号哈希表是否为空,即:if (dict->ht[0].size == 0)。如果为true直接返回NULL。
2、判断该0号哈希表是否需要rehash,因为如果在进行rehash,那么两个表中者有可能存储该key。如果正在进行rehash,将调用一次_dictRehashStep方法,_dictRehashStep 用于对数据库字典、以及哈希键的字典进行被动 rehash,这里不作赘述。
3、计算哈希表,根据当前字典与key进行哈希值的计算。
4、根据哈希值与当前字典计算哈希表的索引值。
5、根据索引值在哈希表中取出链表,遍历该链表找到key的位置。一般情况,该链表长度为1。
6、当 ht[0] 查找完了之后,再进行了次rehash判断,如果未在rehashing,则直接结束,否则对ht[1]重复345步骤。
到此我们就找到了key在内存中的位置了。
转自:https://www.cnblogs.com/EasonJim/p/7818004.html

