


redis中的批量处理:批量命令或pipeline
一、传统的批量处理和pipeline对比
二、pipeline 的优缺点
三、pipeline的示例
1、jredis客户端使用pipeline
2、springboot中redisTemplate使用pipeline
一、传统的批量处理和pipeline对比
redis是一个cs模式的tcp server,使用和http类似的请求响应协议。一个client可以通过一个socket连接发起多个请求命令。每个请求命令发出后client通常 会阻塞并等待redis服务处理,redis处理完后请求命令后会将结果通过响应报文返回给client。
1、批量处理基本的通信过程如下:
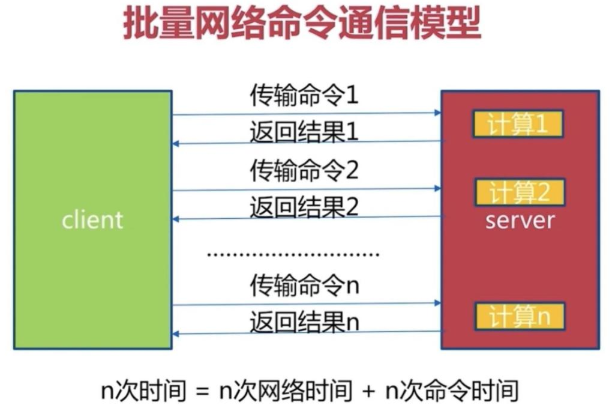
基 本上四个命令需要8个tcp报文才能完成。由于通信会有网络延迟,假如从client和server之间的包传输时间需要0.125秒。那么上面的四个命 令8个报文至少会需要1秒才能完成。这样即使redis每秒能处理100个命令,而我们的client也只能一秒钟发出四个命令。这显示没有充分利用 redis的处理能力。
执行n次就需要:n次时间=n次网络时间+n次命令时间
2、redis pipeline
由于命令时间非常短,影响时间开销的主要是网络时间,所以我们可以把一组命令打包,然后一次发送过去。这样的话,时间开销就变为:
1 次 pipeline(n条命令) = 1 次网络时间 + n 次命令时间
除了可以利用mget,mset 之类的单条命令处理多个key的命令外,我们还可以利用pipeline的方式从client打包多条命令一起发出,不需要等待单条命令的响应返回,而redis服务端会处理完多条命令后会将多条命令的处理结果打包到一起返回给客户端。
通信过程如下: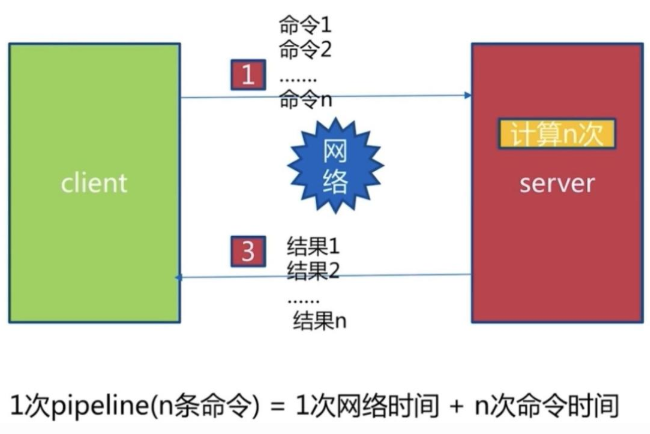
通过pipeline方式当有大批量的操作时候。我们可以节省很多原来浪费在网络延迟的时间。需要注意到是用 pipeline方式打包命令发送,redis必须在处理完所有命令前先缓存起所有命令的处理结果。
| 命令 | N个命令操作 | 1次pipeline(n个命令) |
|---|---|---|
| 时间 | n次网络+n次命令 | 1次网络+n次命令 |
| 数据量 | 1条命令 | n条命令 |
二、pipeline 的优缺点
1、pipeline的优点
- 省略由于单线程导致的命令排队时间,一次命令的消耗时间=一次网络时间 + 命令执行时间
- 比起命令执行时间,网络时间很可能成为系统的瓶颈
- pipeline的作用是将一批命令进行打包,然后发送给服务器,服务器执行完按顺序打包返回。
- 通过pipeline,一次pipeline(n条命令)=一次网络时间 + n次命令时间
2、pipeline VS M 操作(mget、mset)
之前我们讲过 M 操作,也是类似 pipeline,将多个命令一次执行,一次发送出去,节省网络时间。对比如下:
- M操作在Redis队列中是一个原子操作,pipeline不是原子操作
- pipeline与M操作都会将数据顺序的传送顺序地返回(redis 单线程)
- M 操作一个命令对应多个键值对,而Pipeline是多条命令
mget的性能:这个文章里有mget的批量性能对比:https://www.jianshu.com/p/172b39244c85
3.1 单次mget的key数目在50以内时 一次操作10个key的性能达到一次操作1个key的88% 一次操作20个key的性能达到一次操作1个key的72% 一次操作50个key的性能达到一次操作1个key的59%
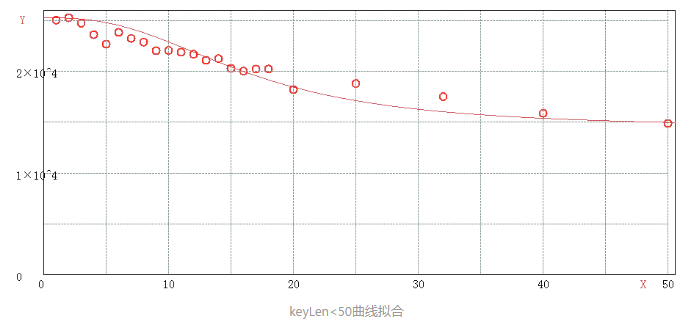
虽然文章中没有说明测试的机器配置情况,但也可以看出性能的高点和单次的key数量有关系,具体实际应用中,还需要注意。
3、pipeline注意事项
- 每次pipeline携带数量不推荐过大,否则会影响网络性能
- pipeline每次只能作用在一个Redis节点上
- 打包的命令越多,缓存消耗内存也越多。所以并是不是打包的命令越多越好。具体多少合适需要根据具体情况测试。
三、pipeline的示例
1、jredis客户端使用pipeline
下面是个jredis客户端使用pipeline的测试:
package jredisStudy; import org.jredis.JRedis; import org.jredis.connector.ConnectionSpec; import org.jredis.ri.alphazero.JRedisClient; import org.jredis.ri.alphazero.JRedisPipelineService; import org.jredis.ri.alphazero.connection.DefaultConnectionSpec; public class PipeLineTest { public static void main(String[] args) { long start = System.currentTimeMillis(); usePipeline(); long end = System.currentTimeMillis(); System.out.println(end-start); start = System.currentTimeMillis(); withoutPipeline(); end = System.currentTimeMillis(); System.out.println(end-start); } private static void withoutPipeline() { try { JRedis jredis = new JRedisClient("192.168.56.55",6379); for(int i =0 ; i < 100000 ; i++) { jredis.incr("test2"); } jredis.quit(); } catch (Exception e) { } } private static void usePipeline() { try { ConnectionSpec spec = DefaultConnectionSpec.newSpec("192.168.56.55", 6379, 0, null); JRedis jredis = new JRedisPipelineService(spec); for(int i =0 ; i < 100000 ; i++) { jredis.incr("test2"); } jredis.quit(); } catch (Exception e) { } } }
输出
103408 //使用了pipeline
104598 //没有使用
测试结果不是很明显,这应该是跟我的测试环境有关。我是在自己win连接虚拟机的linux。网络延迟比较小。所以pipeline优势不明显。如果网络延迟小的话,最好还是不用pipeline。除了增加复杂外,带来的性能提升不明显。
示例2:
package com.lxw1234.redis; import java.util.HashMap; import java.util.Map; import java.util.Set; import redis.clients.jedis.Jedis; import redis.clients.jedis.Pipeline; import redis.clients.jedis.Response; public class Test { public static void main(String[] args) throws Exception { Jedis redis = new Jedis("127.0.0.1", 6379, 400000); Map<String,String> data = new HashMap<String,String>(); redis.select(8); redis.flushDB(); //hmset long start = System.currentTimeMillis(); //直接hmset for (int i=0;i<10000;i++) { data.clear(); data.put("k_" + i, "v_" + i); redis.hmset("key_" + i, data); } long end = System.currentTimeMillis(); System.out.println("dbsize:[" + redis.dbSize() + "] .. "); System.out.println("hmset without pipeline used [" + (end - start) / 1000 + "] seconds .."); redis.select(8); redis.flushDB(); //使用pipeline hmset Pipeline p = redis.pipelined(); start = System.currentTimeMillis(); for (int i=0;i<10000;i++) { data.clear(); data.put("k_" + i, "v_" + i); p.hmset("key_" + i, data); } p.sync(); end = System.currentTimeMillis(); System.out.println("dbsize:[" + redis.dbSize() + "] .. "); System.out.println("hmset with pipeline used [" + (end - start) / 1000 + "] seconds .."); //hmget Set keys = redis.keys("*"); //直接使用Jedis hgetall start = System.currentTimeMillis(); Map<String,Map<String,String>> result = new HashMap<String,Map<String,String>>(); for(String key : keys) { result.put(key, redis.hgetAll(key)); } end = System.currentTimeMillis(); System.out.println("result size:[" + result.size() + "] .."); System.out.println("hgetAll without pipeline used [" + (end - start) / 1000 + "] seconds .."); //使用pipeline hgetall Map<String,Response<Map<String,String>>> responses = new HashMap<String,Response<Map<String,String>>>(keys.size()); result.clear(); start = System.currentTimeMillis(); for(String key : keys) { responses.put(key, p.hgetAll(key)); } p.sync(); for(String k : responses.keySet()) { result.put(k, responses.get(k).get()); } end = System.currentTimeMillis(); System.out.println("result size:[" + result.size() + "] .."); System.out.println("hgetAll with pipeline used [" + (end - start) / 1000 + "] seconds .."); redis.disconnect(); } }
dbsize:[10000] .. hmset without pipeline used [243] seconds .. dbsize:[10000] .. hmset with pipeline used [0] seconds .. result size:[10000] .. hgetAll without pipeline used [243] seconds .. result size:[10000] .. hgetAll with pipeline used [0] seconds .
使用pipeline来批量读写10000条记录,就是小菜一碟,秒完。
2、springboot中redisTemplate使用pipeline
redisTemplate批量获取值的2种方式
1、利用mGet
List<String> keys = new ArrayList<>(); //初始keys List<YourObject> list = this.redisTemplate.opsForValue().multiGet(keys);
2、利用PipeLine
List<YourObject> list = this.redisTemplate.executePipelined(new RedisCallback<YourObject>() { @Override public YourObject doInRedis(RedisConnection connection) throws DataAccessException { StringRedisConnection conn = (StringRedisConnection)connection; for (String key : keys) { conn.get(key); } return null; } });
其实2者底层都是用到execute方法,multiGet在使用连接是没用到pipeline,一条mget命令《Redis对象--字符串》直接传给Redis,Redis返回结果。而executePipelined实际上一条或多条命令,但是共用一个连接。
示例2-1:
//批量操作 @RequestMapping(value = "/add/pipeline", method = RequestMethod.GET) public void addPipeline() { strRedisTemplate.executePipelined(new RedisCallback<String>() { @Override public String doInRedis(RedisConnection connection) throws DataAccessException { for (int i = 0; i < 100; i++) { connection.set(("pipel:" + i).getBytes(), "123".getBytes()); } return null; } }); } //单个操作 @RequestMapping(value = "/add/single", method = RequestMethod.GET) public void addSingle() { for (int i = 0; i < 100; i++) { strRedisTemplate.opsForValue().set("single:" + i, "123"); } }
示例2-2:
@Autowired private RedisTemplate<String, String> strRedisTemplate; /** * Redis批量Set */ @Override public Object postMultiSet(PostMultiSetRequest postMultiSetRequest) { Map<String, String> batchSetMap = new HashMap<>(); List<BatchRedisDto> batchRedisDtoList = postMultiSetRequest.getBatchRedisDtoList(); for (BatchRedisDto batchRedisDto : batchRedisDtoList) { batchSetMap.put(batchRedisDto.getRedisKey(), batchRedisDto.getRedisValue()); } strRedisTemplate.opsForValue().multiSet(batchSetMap); return WrapMapper.ok(); } /** * Redis批量Get */ @Override public Object listMultiGet(ListMultiGetRequest listMultiGetRequest) { List<String> keyList = listMultiGetRequest.getKeyList(); List<String> valueList = strRedisTemplate.opsForValue().multiGet(keyList); List<BatchRedisDto> batchRedisDtoList = new ArrayList<>(); ListMultiGetResponse listMultiGetResponse = new ListMultiGetResponse(); for (int i = 0; i < valueList.size(); i++) { String value = valueList.get(i); if (StringUtils.isEmpty(value)) { continue; } BatchRedisDto batchRedisDto = new BatchRedisDto(); batchRedisDto.setRedisKey(keyList.get(i)); batchRedisDto.setRedisValue(value); batchRedisDtoList.add(batchRedisDto); } listMultiGetResponse.setBatchRedisDtoList(batchRedisDtoList); return WrapMapper.ok(listMultiGetResponse); } /** * Redis批量Set且设置失效时间 */ @Override public Object postMultiSetAndExpire(PostMultiSetRequest postMultiSetRequest) { List<BatchRedisDto> batchRedisDtoList = postMultiSetRequest.getBatchRedisDtoList(); strRedisTemplate.executePipelined(new RedisCallback<String>() { @Override public String doInRedis(RedisConnection connection) throws DataAccessException { for (BatchRedisDto batchRedisDto : batchRedisDtoList) { String key = batchRedisDto.getRedisKey(); String value = batchRedisDto.getRedisValue(); connection.set(key.getBytes(), value.getBytes(), Expiration.from(1, TimeUnit.DAYS), RedisStringCommands.SetOption.UPSERT); } return null; } }); return WrapMapper.ok(); } /** * Redis批量Delete */ @Override public Object postMultiDelete(PostMultiDeleteRequest postMultiDeleteRequest) { strRedisTemplate.delete(postMultiDeleteRequest.getKeyList()); return WrapMapper.ok(); } 转:https://blog.csdn.net/zhanghan18333611647/article/details/108305904

