


Storm并行度详解
一、Storm并行度相关的概念
Storm集群有很多节点,按照类型分为nimbus(主节点)、supervisor(从节点),在conf/storm.yaml中配置了一个supervisor,有多个槽(supervisor.slots.ports),每个槽就是一个JVM,就是一个worker(一个节点,运行一个worker),在每个worker里面可以运行多个线程叫做executor,在executor里运行一个topology的一个component(spout、bolt)叫做task。task 是storm中进行计算的最小的运行单位,表示是spout或者bolt的运行实例。
总结一下,supervisor(节点)>worker(进程)>executor(线程)>task(实例)
程序执行的最大粒度的运行单位是进程,刚才说的task也是需要有进程来运行它的,在supervisor中,运行task的进程称为worker,
Supervisor节点上可以运行非常多的worker进程,一般在一个进程中是可以启动多个线程的,所以我们可以在worker中运行多个线程,这些线程称为executor,在executor中运行task。
提高storm的并行度,可 考虑如下几点:
worker(进程)>executor(线程)>task(实例)
增加work进程,增加executor线程,增加task实例
看下面的图:
这表示是一个work进程,其实就是一个jvm虚拟机进程,在这个work进程里面有多个executor线程,每个executor线程会运行一个或多个task实例。一个task是最终完成数据处理的实体单元。(默认情况下一个executor运行一个task).
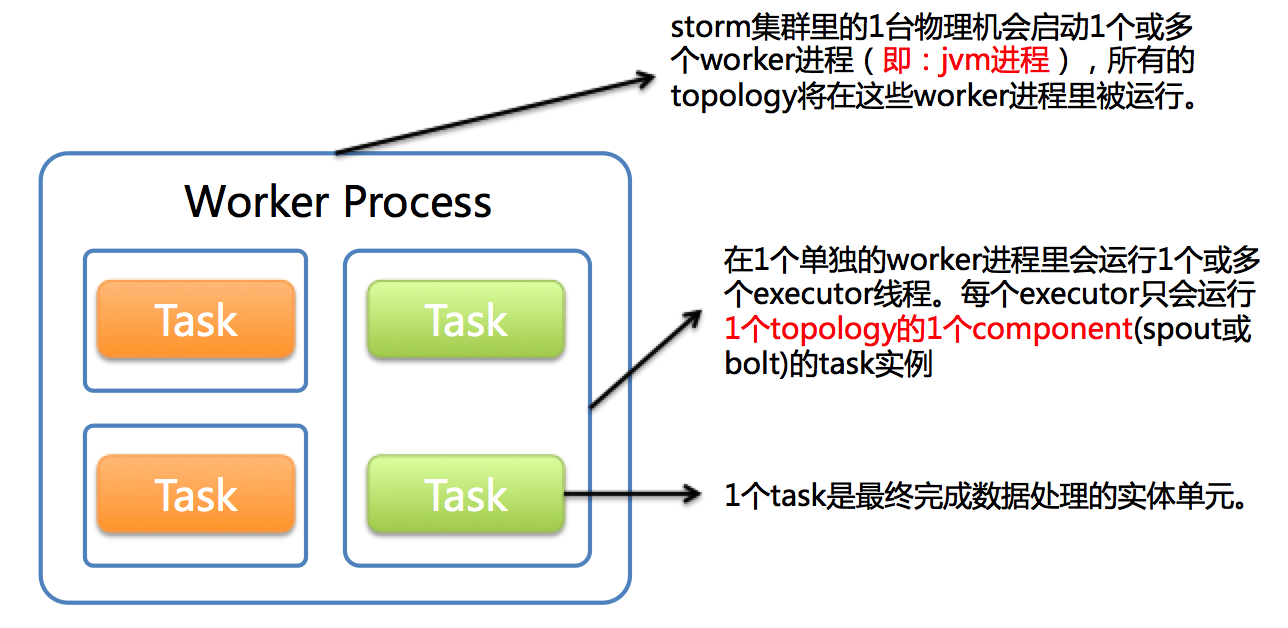
worker,executor,task解释
1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。1个worker进程会启动1个或多个executor线程来执行1个topology的component(spout或bolt)。因此,1个运行中的topology就是由集群中多台物理机上的多个worker进程组成的。
executor是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component(spout或bolt)的task(注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序调用所有task实例)。
task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实例)。这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task。
刚才从理论说明了如何提高集群的并行度,在这里我们就来看一下这些东西worker(进程)>executor(线程)>task(实例) 是如何设置的
l worker(进程):这个worker进程数量是在集群启动之前配置好的,在哪配置的呢?是在storm/conf/storm.yaml文件中,参数是supervisor.slots.port,如果我们不在这进行配置的话,这个参数也是有默认值的,在strom-1.0.2的压缩包中的lib目录下,有一个strom-core.jar,打开这个jar文件,在里面有一个defaults.yaml文件中是有一些默认配置的。

默认情况下一个storm项目只使用一个work进程,也可以通过代码进行修改,通过config.setNumWorkers(workers)设置。(最好一台机器上的一个topology只使用一个worker,主要原因时减少了worker之间的数据传输)
注意:如果worker使用完的话再提交topology就不会执行,因为没有可用的worker,只能处于等待状态,把之前运行的topology停止一个之后这个就会继续执行了,

l executor(线程):默认情况下一个executor运行一个task,可以通过在代码中设置builder.setSpout(id,spout, parallelism_hint);或者builder.setBolt(id,bolt,parallelism_hint);来提高线程数的。
l task(实例):通过boltDeclarer.setNumTasks(num);来设置实例的个数
默认情况下,一个supervisor节点会启动4个worker进程。每个worker进程会启动1个executor,每个executor启动1个task。
Ok,这几个参数都可以使用一些方法进行增加。
二、示例说明
下面来举个例子看一下对这些配置修改之后的效果
1、worker(进程)
通过在代码中设置,可以在ui界面上查看worker的总数,并且还可以在linux服务器上执行jps查看work进程。

在代码中设置使用3个worker,查看ui界面,发现workers是3个,executors使用了5个,为什么呢?因为每一个worker默认都会占用一个executor(这个executor会启动一个acker任务),这样就会占用三个,剩下的两个是spout和bolt实例占用了。
如果使用5个worker,executor会使用7个,因为worker本身就会占用5个,spout和bolt占用两个。

Acker任务:
acker任务默认是每个worker进程启动一个executor线程来执行,可以在topology中取消acker任务,这样的话就不会多出来一个executor和任务了。

或
实际上就是修改TOPOLOGY_ACKER_EXECUTORS配置,如下:
// storm配置 Config stormConf = new Config(); stormConf.TOPOLOGY_ACKER_EXECUTORS = 0;//关闭
这样的话在页面查看executor和task的个数一样了。
2、 executor(线程)
在spout和bolt中设置线程数,都设置为2个,查看ui界面

现在使用的executor和tasks就是7个了,因为worker本身使用3个,spout和bolt分别使用2个。

3、 task(实例)
在sum中设置实例个数为5,查看ui界面

发现ui界面上显示的tasks是10,因为spout占用2个,bolt占用5个,剩下的3个由acker任务占用

注意:虽然在这设置了多个task实例,但是并行度并没有很大提高,因为只有两个线程去运行这些实例,只有设置足够多的线程和实例才可以真正的提高并行度。
在这设置多个实例主要是为了下面执行rebalance的时候用到,因为rebalance不需要修改代码,就可以动态修改topology的并行度,这样的话就必须提前配置好多个实例,在rebalance的时候主要是对之前设置多余的任务实例分配线程去执行。
三、在命令行中动态修改并行度
除了使用代码进行调整,还可以在shell命令行下对并行度进行调整。
storm rebalance mytopology -w 10 -n 2 -e spout=2 -e bolt=2
表示 10秒之后对mytopology进行并行度调整。把spout调整为2个executor,把bolt调整为2个executor。
注意:并行度主要就是调整executor的数量,但是调整之后的executor的数量必须小于等于task的数量,如果分配的executor的线程数比task数量多的话也只能分配和task数量相等的executor。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步