



Spark Streaming之五:Window窗体相关操作
SparkStreaming之window滑动窗口应用,Spark Streaming提供了滑动窗口操作的支持,从而让我们可以对一个滑动窗口内的数据执行计算操作。每次掉落在窗口内的RDD的数据,会被聚合起来执行计算操作,然后生成的RDD,会作为window DStream的一个RDD。
网官图中所示,就是对每三秒钟的数据执行一次滑动窗口计算,这3秒内的3个RDD会被聚合起来进行处理,然后过了两秒钟,又会对最近三秒内的数据执行滑动窗口计算。所以每个滑动窗口操作,都必须指定两个参数,窗口长度以及滑动间隔,而且这两个参数值都必须是batch间隔的整数倍。
Spark Streaming对滑动窗口的支持,是比Storm更加完善和强大的。
之前有些朋友问:
spark官网图片中: 滑动窗口宽度是3个时间单位,滑动时间是2两个单位,这样的话中间time3的Dstream不是重复计算了吗?
Answer:比如下面这个例子是针对热搜的应用场景,官方的例子也可能是是针对不同的场景给出了的。如果你不想出现重叠的部分,把滑动间隔由2改成3即可
SparkStreaming对滑动窗口支持的转换操作:
示例讲解:
1、window(windowLength, slideInterval)
该操作由一个DStream对象调用,传入一个窗口长度参数,一个窗口移动速率参数,然后将当前时刻当前长度窗口中的元素取出形成一个新的DStream。
下面的代码以长度为3,移动速率为1截取源DStream中的元素形成新的DStream。
val windowWords = words.window(Seconds( 3 ), Seconds( 1))

基本上每秒输入一个字母,然后取出当前时刻3秒这个长度中的所有元素,打印出来。从上面的截图中可以看到,下一秒时已经看不到a了,再下一秒,已经看不到b和c了。表示a, b, c已经不在当前的窗口中。
2、 countByWindow(windowLength,slideInterval)
返回指定长度窗口中的元素个数。
代码如下,统计当前3秒长度的时间窗口的DStream中元素的个数:
val windowWords = words.countByWindow(Seconds( 3 ), Seconds( 1))

3、 reduceByWindow(func, windowLength,slideInterval)
类似于上面的reduce操作,只不过这里不再是对整个调用DStream进行reduce操作,而是在调用DStream上首先取窗口函数的元素形成新的DStream,然后在窗口元素形成的DStream上进行reduce。
val windowWords = words.reduceByWindow(_ + "-" + _, Seconds( 3) , Seconds( 1 ))

4、 reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks])
调用该操作的DStream中的元素格式为(k, v),整个操作类似于前面的reduceByKey,只不过对应的数据源不同,reduceByKeyAndWindow的数据源是基于该DStream的窗口长度中的所有数据。该操作也有一个可选的并发数参数。
下面代码中,将当前长度为3的时间窗口中的所有数据元素根据key进行合并,统计当前3秒中内不同单词出现的次数。
val windowWords = pairs.reduceByKeyAndWindow((a:Int , b:Int) => (a + b) , Seconds(3 ) , Seconds( 1 ))

5、 reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks])
这个窗口操作和上一个的区别是多传入一个函数invFunc。前面的func作用和上一个reduceByKeyAndWindow相同,后面的invFunc是用于处理流出rdd的。
在下面这个例子中,如果把3秒的时间窗口当成一个池塘,池塘每一秒都会有鱼游进或者游出,那么第一个函数表示每由进来一条鱼,就在该类鱼的数量上累加。而第二个函数是,每由出去一条鱼,就将该鱼的总数减去一。
val windowWords = pairs.reduceByKeyAndWindow((a: Int, b:Int ) => (a + b) , (a:Int, b: Int) => (a - b) , Seconds( 3 ), Seconds( 1 ))
下面是演示结果,最终的结果是该3秒长度的窗口中历史上出现过的所有不同单词个数都为0。
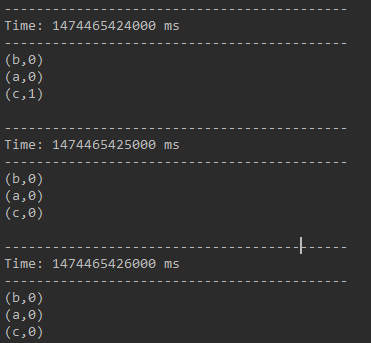
6、 countByValueAndWindow(windowLength,slideInterval, [numTasks])
类似于前面的countByValue操作,调用该操作的DStream数据格式为(K, v),返回的DStream格式为(K, Long)。统计当前时间窗口中元素值相同的元素的个数。
val windowWords = words.countByValueAndWindow(Seconds( 3 ), Seconds( 1))

示例二:热点搜索词滑动统计,每隔10秒钟,统计最近60秒钟的搜索词的搜索频次,并打印出排名最靠前的3个搜索词以及出现次数
Scala版本:
package com.spark.streaming import org.apache.spark.streaming.Seconds import org.apache.spark.streaming.StreamingContext import org.apache.spark.SparkConf /** * @author Ganymede */ object WindowHotWordS { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("WindowHotWordS").setMaster("local[2]") //Scala中,创建的是StreamingContext val ssc = new StreamingContext(conf, Seconds(5)) val searchLogsDStream = ssc.socketTextStream("spark1", 9999) val searchWordsDStream = searchLogsDStream.map { searchLog => searchLog.split(" ")(1) } val searchWordPairDStream = searchWordsDStream.map { searchWord => (searchWord, 1) } // reduceByKeyAndWindow // 第二个参数,是窗口长度,这是是60秒 // 第三个参数,是滑动间隔,这里是10秒 // 也就是说,每隔10秒钟,将最近60秒的数据,作为一个窗口,进行内部的RDD的聚合,然后统一对一个RDD进行后续计算 // 而是只是放在那里 // 然后,等待我们的滑动间隔到了以后,10秒到了,会将之前60秒的RDD,因为一个batch间隔是5秒,所以之前60秒,就有12个RDD,给聚合起来,然后统一执行reduceByKey操作 // 所以这里的reduceByKeyAndWindow,是针对每个窗口执行计算的,而不是针对 某个DStream中的RDD // 每隔10秒钟,出来 之前60秒的收集到的单词的统计次数 val searchWordCountsDStream = searchWordPairDStream.reduceByKeyAndWindow((v1: Int, v2: Int) => v1 + v2, Seconds(60), Seconds(10)) val finalDStream = searchWordCountsDStream.transform(searchWordCountsRDD => { val countSearchWordsRDD = searchWordCountsRDD.map(tuple => (tuple._2, tuple._1)) val sortedCountSearchWordsRDD = countSearchWordsRDD.sortByKey(false) val sortedSearchWordCountsRDD = sortedCountSearchWordsRDD.map(tuple => (tuple._1, tuple._2)) val top3SearchWordCounts = sortedSearchWordCountsRDD.take(3) for (tuple <- top3SearchWordCounts) { println("result : " + tuple) } searchWordCountsRDD }) finalDStream.print() ssc.start() ssc.awaitTermination() } }

