
RPC介绍
转载http://blog.csdn.net/mindfloating/article/details/39474123/
近几年的项目中,服务化和微服务化渐渐成为中大型分布式系统架构的主流方式,而 RPC 在其中扮演着关键的作用。在平时的日常开发中我们都在隐式或显式的使用 RPC,一些刚入行的程序员会感觉 RPC 比较神秘,而一些有多年使用 RPC 经验的程序员虽然使用经验丰富,但有些对其原理也不甚了了。缺乏对原理层面的理解,往往也会造成开发中的一些误用。
其目标就是想尝试深入浅出的分析下 RPC 本质,我总是这么认为理解了本质才能更好的应用。
RPC 是什么?
RPC 的全称是 Remote Procedure Call 是一种进程间通信方式。它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。即程序员无论是调用本地的还是远程的,本质上编写的调用代码基本相同。
RPC 起源
RPC 这个概念术语在上世纪 80 年代由 Bruce Jay Nelson 提出。这里我们追溯下当初开发 RPC 的原动机是什么?在 Nelson 的论文 "Implementing Remote Procedure Calls" 中他提到了几点:
1. 简单:RPC 概念的语义十分清晰和简单,这样建立分布式计算就更容易。
2. 高效:过程调用看起来十分简单而且高效。
3. 通用:在单机计算中过程往往是不同算法部分间最重要的通信机制。
通俗一点说,就是一般程序员对于本地的过程调用很熟悉,那么我们把 RPC 作成和本地调用完全类似,那么就更容易被接受,使用起来毫无障碍。Nelson 的论文发表于 30 年前,其观点今天看来确实高瞻远瞩,今天我们使用的 RPC 框架基本就是按这个目标来实现的。
RPC框架
RPC 框架的发展与现状
RPC(Remote Procedure Call)是一种远程调用协议,简单地说就是能使应用像调用本地方法一样的调用远程的过程或服务,可以应用在分布式服务、分布式计算、远程服务调用等许多场景。说起 RPC 大家并不陌生,业界有很多开源的优秀 RPC 框架,例如 Dubbo、Thrift、gRPC、Hprose 等等。下面先简单介绍一下 RPC 与常用远程调用方式的特点,以及一些优秀的开源 RPC 框架。
RPC 与其它远程调用方式比较
RPC 与 HTTP、RMI、Web Service 都能完成远程调用,但是实现方式和侧重点各有不同。
HTTP
HTTP(HyperText Transfer Protocol)是应用层通信协议,使用标准语义访问指定资源(图片、接口等),网络中的中转服务器能识别协议内容。HTTP 协议是一种资源访问协议,通过 HTTP 协议可以完成远程请求并返回请求结果。
HTTP 的优点是简单、易用、可理解性强且语言无关 ,在远程服务调用中包括微博有着广泛应用。HTTP 的缺点是协议头较重,一般请求到具体服务器的链路较长,可能会有 DNS 解析、Nginx 代理等。
RPC 是一种协议规范,可以把 HTTP 看作是一种 RPC 的实现,也可以把 HTTP 作为 RPC 的传输协议来应用。RPC 服务的自动化程度比较高,能够实现强大的服务治理功能,和语言结合更友好,性能也十分优秀。与 HTTP 相比,RPC 的缺点就是相对复杂,学习成本稍高。
RMI
RMI(Remote Method Invocation)是指 Java 语言中的远程方法调用,RMI 中的每个方法都具有方法签名,RMI 客户端和服务器端通过方法签名进行远程方法调用。RMI 只能在 Java 语言中使用, 可以把 RMI 看作面向对象的 Java RPC 。
Web Service
Web Service 是一种基于 Web 进行服务发布、查询、调用的架构方式,重点在于服务的管理与使用。Web Service 一般通过 WSDL 描述服务,使用 SOAP(简单对象访问协议)通过 HTTP 调用服务。
RPC 是一种远程访问协议,而 Web Service 是一种体系结构,Web Service 也可以通过 RPC 来进行服务调用,因此 Web Service 更适合同一个 RPC 框架进行比较。当 RPC 框架提供了服务的发现与管理,并使用 HTTP 作为传输协议时,其实就是 Web Service。
相对 Web Service,RPC 框架可以对服务进行更细粒度的治理,包括流量控制、SLA 管理等,在微服务化、分布式计算方面有更大的优势。
RPC 框架介绍
RPC 协议只规定了 Client 与 Server 之间的点对点调用流程,包括 stub、通信协议、RPC 消息解析等部分,在实际应用中,还需要考虑服务的高可用、负载均衡等问题,所以这里的 RPC 框架指的是能够完成 RPC 调用的解决方案,除了点对点的 RPC 协议的具体实现外,还可以包括服务的发现与注销、提供服务的多台 Server 的负载均衡、服务的高可用等更多的功能。 目前的 RPC 框架大致有两种不同的侧重方向,一种偏重于服务治理,另一种偏重于跨语言调用 。
1、偏重于服务治理--服务治理型 RPC 框架
服务治理型的 RPC 框架有 Dubbo、DubboX 等,Dubbo 是阿里开源的分布式服务框架,能够实现高性能 RPC 调用,并且提供了丰富的管理功能,是十分优秀的 RPC 框架。DubboX 是基于 Dubbo 框架开发的 RPC 框架,支持 REST 风格远程调用,并增加了一些新的 feature。
这类的 RPC 框架的特点是功能丰富,提供高性能的远程调用以及服务发现及治理功能, 适用于大型服务的微服务化拆分以及管理,对于特定语言(Java)的项目可以十分友好的透明化接入。但缺点是语言耦合度较高,跨语言支持难度较大。
2、偏重于跨语言调用--跨语言调用型
跨语言调用型的 RPC 框架有 Thrift、gRPC、Hessian、Hprose 等,这一类的 RPC 框架重点关注于服务的跨语言调用,能够支持大部分的语言进行语言无关的调用,非常适合于为不同语言提供通用远程服务的场景。 但这类框架没有服务发现相关机制 ,实际使用时一般需要代理层进行请求转发和负载均衡策略控制。
微博的 RPC 框架 Motan 属于服务治理类型,是一个基于 Java 开发的高性能的轻量级 RPC 框架,Motan 提供了实用的服务治理功能和优秀的 RPC 协议扩展能力。
RPC实现:
RPC 可基于 HTTP 或 TCP 协议,Web Service 就是基于 HTTP 协议的 RPC,它具有良好的跨平台性,但其性能却不如基于 TCP 协议的 RPC。会两方面会直接影响 RPC 的性能,一是传输方式,二是序列化。
众所周知,TCP 是传输层协议,HTTP 是应用层协议,而传输层较应用层更加底层,在数据传输方面,越底层越快,因此,在一般情况下,TCP 一定比 HTTP 快。就序列化而言,Java 提供了默认的序列化方式,但在高并发的情况下,这种方式将会带来一些性能上的瓶颈,于是市面上出现了一系列优秀的序列化框架,比如:Protobuf、Kryo、Hessian、Jackson 等,它们可以取代 Java 默认的序列化,从而提供更高效的性能。
为了支持高并发,传统的阻塞式 IO 显然不太合适,因此我们需要异步的 IO,即 NIO。Java 提供了 NIO 的解决方案,Java 7 也提供了更优秀的 NIO.2 支持,用 Java 实现 NIO 并不是遥不可及的事情,只是需要我们熟悉 NIO 的技术细节。
RPC 结构
Nelson 的论文中指出实现 RPC 的程序包括 5 个部分:
1. User
2. User-stub
3. RPCRuntime
4. Server-stub
5. Server
这 5 个部分的关系如下图所示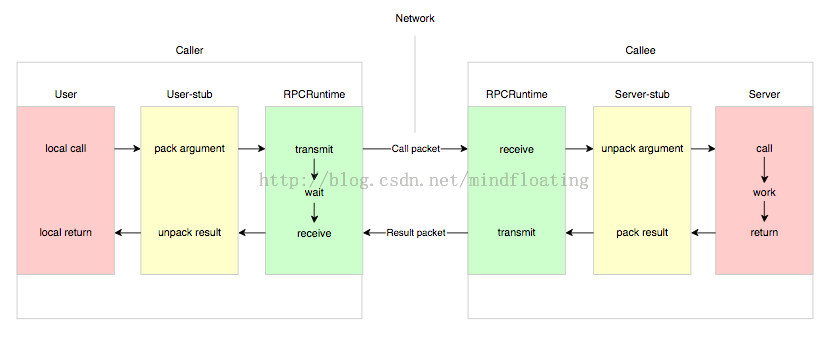
这里 user 就是 client 端,当 user 想发起一个远程调用时,它实际是通过本地调用 user-stub。user-stub 负责将调用的接口、方法和参数通过约定的协议规范进行编码并通过本地的 RPCRuntime 实例传输到远端的实例。远端 RPCRuntime 实例收到请求后交给 server-stub 进行解码后发起本地端调用,调用结果再返回给 user 端。
RPC 实现
Nelson 论文中给出的这个实现结构也成为后来大家参考的标准范本。大约 10 年前,我最早接触分布式计算时使用的 CORBAR 实现结构基本与此类似。CORBAR 为了解决异构平台的 RPC,使用了 IDL(Interface Definition Language)来定义远程接口,并将其映射到特定的平台语言中。后来大部分的跨语言平台 RPC 基本都采用了此类方式,比如我们熟悉的 Web Service(SOAP),近年开源的 Thrift 等。他们大部分都通过 IDL 定义,并提供工具来映射生成不同语言平台的 user-stub 和 server-stub,并通过框架库来提供 RPCRuntime 的支持。不过貌似每个不同的 RPC 框架都定义了各自不同的 IDL 格式,导致程序员的学习成本进一步上升(苦逼啊),Web Service 尝试建立业界标准,无赖标准规范复杂而效率偏低,否则 Thrift 等更高效的 RPC 框架就没必要出现了。
IDL 是为了跨平台语言实现 RPC 不得已的选择,要解决更广泛的问题自然导致了更复杂的方案。而对于同一平台内的 RPC 而言显然没必要搞个中间语言出来,例如 java 原生的 RMI,这样对于 java 程序员而言显得更直接简单,降低使用的学习成本。目前市面上提供的 RPC 框架已经可算是五花八门,百家争鸣了。需要根据实际使用场景谨慎选型,需要考虑的选型因素我觉得至少包括下面几点:
1. 性能指标
2. 是否需要跨语言平台
3. 内网开放还是公网开放
4. 开源 RPC 框架本身的质量、社区活跃度
RPC 功能目标
RPC 的主要功能目标是让构建分布式计算(应用)更容易,在提供强大的远程调用能力时不损失本地调用的语义简洁性。为实现该目标,RPC 框架需提供一种透明调用机制让使用者不必显式的区分本地调用和远程调用,在前文《浅出篇》中给出了一种实现结构,基于 stub 的结构来实现。下面我们将具体细化 stub 结构的实现。
RPC 调用分类
RPC 调用分以下两种:
1. 同步调用
客户方等待调用执行完成并返回结果。
2. 异步调用
客户方调用后不用等待执行结果返回,但依然可以通过回调通知等方式获取返回结果。
若客户方不关心调用返回结果,则变成单向异步调用,单向调用不用返回结果。
异步和同步的区分在于是否等待服务端执行完成并返回结果。
RPC 结构拆解
《浅出篇》给出了一个比较粗粒度的 RPC 实现概念结构,这里我们进一步细化它应该由哪些组件构成,如下图所示。

RPC 服务方通过 RpcServer 去导出(export)远程接口方法,而客户方通过 RpcClient 去引入(import)远程接口方法。客户方像调用本地方法一样去调用远程接口方法,RPC 框架提供接口的代理实现,实际的调用将委托给代理RpcProxy 。代理封装调用信息并将调用转交给RpcInvoker 去实际执行。在客户端的RpcInvoker 通过连接器RpcConnector 去维持与服务端的通道RpcChannel,并使用RpcProtocol 执行协议编码(encode)并将编码后的请求消息通过通道发送给服务方。
RPC 服务端接收器 RpcAcceptor 接收客户端的调用请求,同样使用RpcProtocol 执行协议解码(decode)。解码后的调用信息传递给RpcProcessor 去控制处理调用过程,最后再委托调用给RpcInvoker 去实际执行并返回调用结果。
RPC 组件职责
上面我们进一步拆解了 RPC 实现结构的各个组件组成部分,下面我们详细说明下每个组件的职责划分。
负责导出(export)远程接口
2. RpcClient
负责导入(import)远程接口的代理实现
3. RpcProxy
远程接口的代理实现
4. RpcInvoker
客户方实现:负责编码调用信息和发送调用请求到服务方并等待调用结果返回
服务方实现:负责调用服务端接口的具体实现并返回调用结果
5. RpcProtocol
负责协议编/解码
6. RpcConnector
负责维持客户方和服务方的连接通道和发送数据到服务方
7. RpcAcceptor
负责接收客户方请求并返回请求结果
8. RpcProcessor
负责在服务方控制调用过程,包括管理调用线程池、超时时间等
9. RpcChannel
数据传输通道
RPC 实现分析
在进一步拆解了组件并划分了职责之后,这里以在 java 平台实现该 RPC 框架概念模型为例,详细分析下实现中需要考虑的因素。
导出远程接口
导出远程接口的意思是指只有导出的接口可以供远程调用,而未导出的接口则不能。在 java 中导出接口的代码片段可能如下:
DemoService demo = new ...;
RpcServer server = new ...;
server.export(DemoService.class, demo, options);
我们可以导出整个接口,也可以更细粒度一点只导出接口中的某些方法,如:
// 只导出 DemoService 中签名为 hi(String s) 的方法 server.export(DemoService.class, demo, "hi", new Class<?>[] { String.class }, options);
java 中还有一种比较特殊的调用就是多态,也就是一个接口可能有多个实现,那么远程调用时到底调用哪个?这个本地调用的语义是通过 jvm 提供的引用多态性隐式实现的,那么对于 RPC 来说跨进程的调用就没法隐式实现了。如果前面DemoService 接口有 2 个实现,那么在导出接口时就需要特殊标记不同的实现,如:
上面 demo2 是另一个实现,我们标记为 "demo2" 来导出,那么远程调用时也需要传递该标记才能调用到正确的实现类,这样就解决了多态调用的语义。
导入远程接口与客户端代理
导入相对于导出远程接口,客户端代码为了能够发起调用必须要获得远程接口的方法或过程定义。目前,大部分跨语言平台 RPC 框架采用根据 IDL 定义通过 code generator 去生成 stub 代码,这种方式下实际导入的过程就是通过代码生成器在编译期完成的。我所使用过的一些跨语言平台 RPC 框架如 CORBAR、WebService、ICE、Thrift 均是此类方式。
代码生成的方式对跨语言平台 RPC 框架而言是必然的选择,而对于同一语言平台的 RPC 则可以通过共享接口定义来实现。在 java 中导入接口的代码片段可能如下:
在 java 中 'import' 是关键字,所以代码片段中我们用 refer 来表达导入接口的意思。这里的导入方式本质也是一种代码生成技术,只不过是在运行时生成,比静态编译期的代码生成看起来更简洁些。java 里至少提供了两种技术来提供动态代码生成,一种是 jdk 动态代理,另外一种是字节码生成。动态代理相比字节码生成使用起来更方便,但动态代理方式在性能上是要逊色于直接的字节码生成的,而字节码生成在代码可读性上要差很多。两者权衡起来,个人认为牺牲一些性能来获得代码可读性和可维护性显得更重要。
协议编解码
客户端代理在发起调用前需要对调用信息进行编码,这就要考虑需要编码些什么信息并以什么格式传输到服务端才能让服务端完成调用。出于效率考虑,编码的信息越少越好(传输数据少),编码的规则越简单越好(执行效率高)。我们先看下需要编码些什么信息:
-- 调用编码 --
1. 接口方法
包括接口名、方法名
2. 方法参数
包括参数类型、参数值
3. 调用属性
包括调用属性信息,例如调用附件隐式参数、调用超时时间等
- -- 返回编码 --
- 1. 返回结果
- 接口方法中定义的返回值
- 2. 返回码
- 异常返回码
- 3. 返回异常信息
- 调用异常信息
除了以上这些必须的调用信息,我们可能还需要一些元信息以方便程序编解码以及未来可能的扩展。这样我们的编码消息里面就分成了两部分,一部分是元信息、另一部分是调用的必要信息。如果设计一种 RPC 协议消息的话,元信息我们把它放在协议消息头中,而必要信息放在协议消息体中。下面给出一种概念上的 RPC 协议消息设计格式:
-- 消息头 --
magic : 协议魔数,为解码设计
header size: 协议头长度,为扩展设计
version : 协议版本,为兼容设计
st : 消息体序列化类型
hb : 心跳消息标记,为长连接传输层心跳设计
ow : 单向消息标记,
rp : 响应消息标记,不置位默认是请求消息
status code: 响应消息状态码
reserved : 为字节对齐保留
message id : 消息 id
body size : 消息体长度
- -- 消息体 --
- 采用序列化编码,常见有以下格式
- xml : 如 webservie soap
- json : 如 JSON-RPC
- binary: 如 thrift; hession; kryo 等
格式确定后编解码就简单了,由于头长度一定所以我们比较关心的就是消息体的序列化方式。序列化我们关心三个方面:
1. 序列化和反序列化的效率,越快越好。
2. 序列化后的字节长度,越小越好。
3. 序列化和反序列化的兼容性,接口参数对象若增加了字段,是否兼容。
上面这三点有时是鱼与熊掌不可兼得,这里面涉及到具体的序列化库实现细节,就不在本文进一步展开分析了。
传输服务
协议编码之后,自然就是需要将编码后的 RPC 请求消息传输到服务方,服务方执行后返回结果消息或确认消息给客户方。RPC 的应用场景实质是一种可靠的请求应答消息流,和 HTTP 类似。因此选择长连接方式的 TCP 协议会更高效,与 HTTP 不同的是在协议层面我们定义了每个消息的唯一 id,因此可以更容易的复用连接。
既然使用长连接,那么第一个问题是到底 client 和 server 之间需要多少根连接?实际上单连接和多连接在使用上没有区别,对于数据传输量较小的应用类型,单连接基本足够。单连接和多连接最大的区别在于,每根连接都有自己私有的发送和接收缓冲区,因此大数据量传输时分散在不同的连接缓冲区会得到更好的吞吐效率。所以,如果你的数据传输量不足以让单连接的缓冲区一直处于饱和状态的话,那么使用多连接并不会产生任何明显的提升,反而会增加连接管理的开销。
连接是由 client 端发起建立并维持。如果 client 和 server 之间是直连的,那么连接一般不会中断(当然物理链路故障除外)。如果 client 和 server 连接经过一些负载中转设备,有可能连接一段时间不活跃时会被这些中间设备中断。为了保持连接有必要定时为每个连接发送心跳数据以维持连接不中断。心跳消息是 RPC 框架库使用的内部消息,在前文协议头结构中也有一个专门的心跳位,就是用来标记心跳消息的,它对业务应用透明。
执行调用
client stub 所做的事情仅仅是编码消息并传输给服务方,而真正调用过程发生在服务方。server stub 从前文的结构拆解中我们细分了 RpcProcessor 和RpcInvoker 两个组件,一个负责控制调用过程,一个负责真正调用。这里我们还是以 java 中实现这两个组件为例来分析下它们到底需要做什么?
java 中实现代码的动态接口调用目前一般通过反射调用。除了原生的 jdk 自带的反射,一些第三方库也提供了性能更优的反射调用,因此 RpcInvoker 就是封装了反射调用的实现细节。
调用过程的控制需要考虑哪些因素,RpcProcessor 需要提供什么样地调用控制服务呢?下面提出几点以启发思考:
1. 效率提升
每个请求应该尽快被执行,因此我们不能每请求来再创建线程去执行,需要提供线程池服务。
2. 资源隔离
当我们导出多个远程接口时,如何避免单一接口调用占据所有线程资源,而引发其他接口执行阻塞。
3. 超时控制
当某个接口执行缓慢,而 client 端已经超时放弃等待后,server 端的线程继续执行此时显得毫无意义。
RPC 异常处理
无论 RPC 怎样努力把远程调用伪装的像本地调用,但它们依然有很大的不同点,而且有一些异常情况是在本地调用时绝对不会碰到的。在说异常处理之前,我们先比较下本地调用和 RPC 调用的一些差异:
1. 本地调用一定会执行,而远程调用则不一定,调用消息可能因为网络原因并未发送到服务方。
2. 本地调用只会抛出接口声明的异常,而远程调用还会跑出 RPC 框架运行时的其他异常。
3. 本地调用和远程调用的性能可能差距很大,这取决于 RPC 固有消耗所占的比重。
正是这些区别决定了使用 RPC 时需要更多考量。当调用远程接口抛出异常时,异常可能是一个业务异常,也可能是 RPC 框架抛出的运行时异常(如:网络中断等)。业务异常表明服务方已经执行了调用,可能因为某些原因导致未能正常执行,而 RPC 运行时异常则有可能服务方根本没有执行,对调用方而言的异常处理策略自然需要区分。
由于 RPC 固有的消耗相对本地调用高出几个数量级,本地调用的固有消耗是纳秒级,而 RPC 的固有消耗是在毫秒级。那么对于过于轻量的计算任务就并不合适导出远程接口由独立的进程提供服务,只有花在计算任务上时间远远高于 RPC 的固有消耗才值得导出为远程接口提供服务。
总结
至此我们提出了一个 RPC 实现的概念框架,并详细分析了需要考虑的一些实现细节。无论 RPC 的概念是如何优雅,但是“草丛中依然有几条蛇隐藏着”,只有深刻理解了 RPC 的本质,才能更好地应用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号