MySQL中事务:
- 事务的实现:
ACID:
-
- 原子性(A : Atomicity)
- 一致性(C : consistency )
- 隔离性(I : isolation)
- 持久性(D : durability )
- 实现方式:
-
- 隔离性:通过锁来实现
- 原子性和持久性:通过redo log 来实现
- 一致性:通过undo来实现
- redo 和 undo 比较:
都是恢复操作:
- redo:恢复提交事务修改的页操作
- undo: 回滚行记录到某个特定版本
记录内容不同:
- redo: 是物理日志,记录的是物理的修改操作
- undo: 是逻辑日志,根据每行记录进行记录
读取方式不同:
- redo : 在数据库运行时,不需要读取操作(注:数据库恢复时,才用redo)
- undo : 在数据库运行时,需要随机读取(注:回滚时用)
redo-在事务中的应用
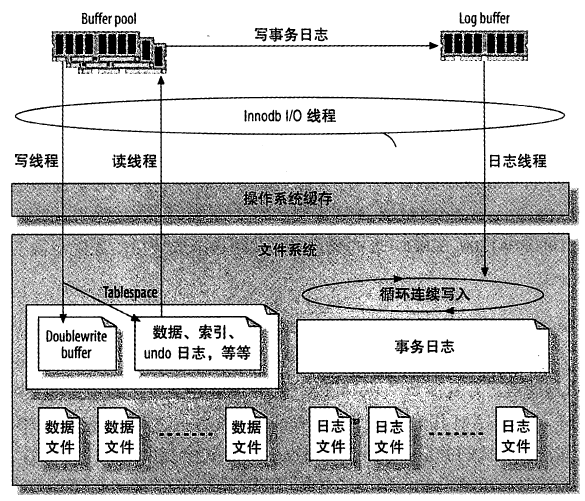
InnoDB使用日志来减少提交事务时的开销。因为日志中已经记录了事务,就无须在每个事务提交时把缓冲池的脏块刷新(flush)到磁盘中。事务修改的数据和索引通常会映射到表空间的随机位置,所以刷新这些变更到磁盘需要很多随机IO。InnoDB假设使用常规磁盘,随机IO比顺序IO昂贵得多,因为一个IO请求需要时间把磁头移到正确的位置,然后等待磁盘上读出需要的部分,再转到开始位置。
InnoDB用日志把随机IO变成顺序IO。一旦日志安全写到磁盘,事务就持久化了,即使断电了,InnoDB可以重放日志并且恢复已经提交的事务。
InnoDB使用一个后台线程智能地刷新这些变更到数据文件。这个线程可以批量组合写入,使得数据写入更顺序,以提高效率。
整体的日志文件大小受控于innodb_log_file_size和innodb_log_files_in_group两个参数,这对写性能非常重要。日志文件的总大小是每个文件的大小之和。
当InnoDB变更任何数据时,会写一条变更记录到内存日志缓冲区中。在缓冲满的时候,事务提交的时候,或者每一秒钟,这三个条件无论哪个先达到,InnoDB都会刷新缓冲区的内容到磁盘日志文件。变量innodb_log_buffer_size可以控制日志缓冲区的大小,默认为1M。通常不需要把日志缓冲区设置得非常大。推荐的范围是1~8M。作为一个经验法则,日志文件的全部大小,应该足够容纳服务器一个小时的活动内容。
InnoDB怎么刷新日志缓冲?当InnoDB把日志缓冲刷新到磁盘日志文件时,会先使用一个Mutex锁住缓冲区,刷新到所需要的位置,然后移动剩下的条目到缓冲区的前面。日志缓冲必须被刷新到持久化存储,以确保提交的事务完全被持久化了。如果和持久相比更在乎性能,可以修改innodb_flush_log_at_trx_commit变量来控制日志缓冲刷新的频繁程度。可能的设置如下:
0:每秒一次把日志缓冲写到日志文件,但是事务提交时不做任何时。
1:将日志缓冲写到日志文件,然后每次事务提交都刷新到持久化存储(默认并且最安全的设置),该设置保证不会丢失任何已提交的事务。
2:每秒钟做一次刷新,但每次提交时把日志缓冲写到日志文件,但是不刷新到持久化存储。
“把日志缓冲写到日志文件”和“把日志刷新到持久化存储”是不同的。在大部分操作系统中,把缓冲写到日志只是简单地把数据从InnoDB的内存缓冲转移到了操作系统的缓存,也是在内存里,并没有真正把数据写到持久化存储。
如果MySQL崩溃了或者断电了,设置0和2通常会导致最多1秒的数据丢失,因为数据可能存在于操作系统的缓存中。
相反,把日志刷新到持久化存储意味着InnoDB请求操作系统把数据刷出缓存,并且确认写到磁盘了,这是一个阻塞IO的调用,直到数据被完全写回才会完成,当写数据到磁盘比较慢,而该配置项设置为1时,可能明显地降低InnoDB每秒可以提交的事务数。
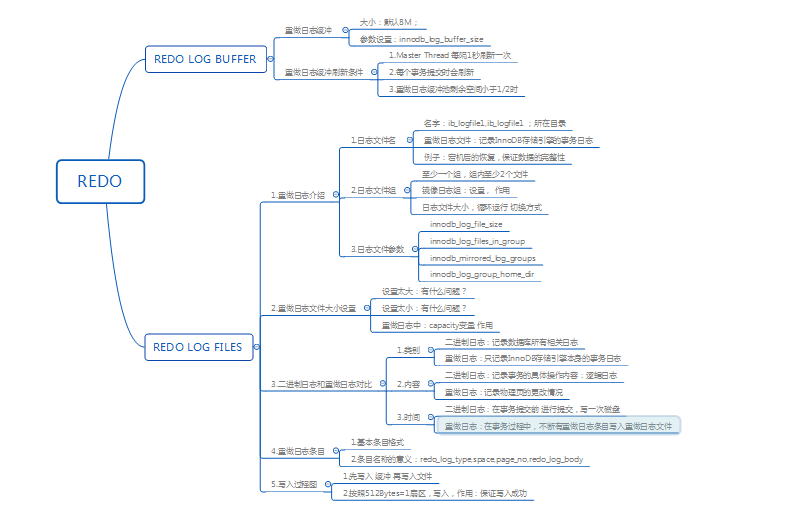
1.基本概念
【事务持久性:D】-- 【重做日志来实现】
【持久性构成】:1.重做日志缓冲(redo log buffer) ,是易失的 2.重做日志文件(redo log file),是持久的
【持久性原理】:InnoDB是事务的存储引擎,通过Flush Log at Commit机制实现事务的持久性。即:当事务提交(Commit)时,必须先将事务的所有日志(这里只重做日志)写入到重做日志文件中,进行持久化,待事务的commit完成才算完成。
【事务的所有日志】:在InnoDB中,事务的所有日志有两部分:redo log 和 undo log
【fsync操作】:为了确保每次重做日志都写入重做日志文件,在将重做日志缓冲写入重做日志文件后,InnoDB存储引擎都需要调用一次fsync操作。
【innodb_flush_method = O_DIRECT/NULL】: 控制InnoDB数据文件和redo log 文件打开,刷写模式。
1.设置为NULL时,默认是:fsync选项。过程:重做日志缓冲先写入文件系统缓存,再进行fsync(将日志刷新到重做日志文件 )操作。依赖磁盘的性能。
2.设置为O_DIRECT,过程:调用用O_DIRECT打开数据文件, 然后调用:fsync(),将所有刷新到数据和log文件中。不经过操作系统缓存,避免两次写操作。
【非持久性】:通过手工设置非持久性来提高数据库性能。
原理:事务提交时,日志不写入重做日志文件,而是等待一个周期后,再执行fsync操作。不是强制每次提交都fsync,可以显著提高性能。
弊端:如果数据库发生宕机,由于部分日志未刷新到磁盘,会丢失最后一段的事务。
【innodb_flush_log_at_trx_commit = 0/1/2】:该参数控制重做日志刷新到磁盘的策略。
1 : 默认是1,表示事务提交时必须调用一次fsync,<redo log刷新条件之一:事务提交前必刷新到日志文件>。遵循ACID的持久性。
0 : 事务提交时,不进行写重做日志操作.写的操作仅在master Thread中完<redo log 刷新条件之二>,大概每隔1秒执行一次fsync操作.在1秒内有数据库宕机丢数据的风险.
2 : 写重做日志文件,但仅仅写入文件系统缓存中,不进行fsync操作。仅数据库宕机系统正常,不会丢数据。 系统宕机,缓存中未刷新到重做日志文件的那部分事务会丢失.
总结:0和2能提高事务提交性能,但是这种情况丧失了事务的ACID特性,因此在大量执行insert操作时,在最后执行一次commit操作。这样回滚时可以回滚到事务最开始的状态.
Innodb存储引擎使用中,为了遵循持久性和一致性,关于复制的设置:
1.如果启用二进制日志(binlog),设置: sync_binlog=1;
2.同时也设置: innodb_flush_log_at_trx_commit=1.
【sync_binlog = N】:
N=0,事务提交后,不做fsync之类的磁盘同步指令,刷新binlog_cache到磁盘文件,而是让文件系统自行决定什么时间同步。性能高,但是有丢失数据的风险.
N=1,1次事务提交后,执行fsync操作,将binlog chace同步到磁盘文件。这种选择是最安全的,但是是最慢的.
【binlog和redo log比较】:
1.产生层面不同
redo log: 是在存储引擎层产生,只针对InnoDB存储引擎
binlog:在数据库上层产生的.MySQL中任何存储引擎对数据库的更改都会产生二进制日志.
2.记录内容形式不同
redo log: 是物理格式的日志,记录的是对于每个页的修改.
binlog: 是一种逻辑日志,记录的是sql语句.
3.写入磁盘时间不同
redo log: 在事务进行中不断的写入.不随事务的提交而提交,不是顺序写入的.
binlog: 在事务提交后进行写入.
2.日志块的结构
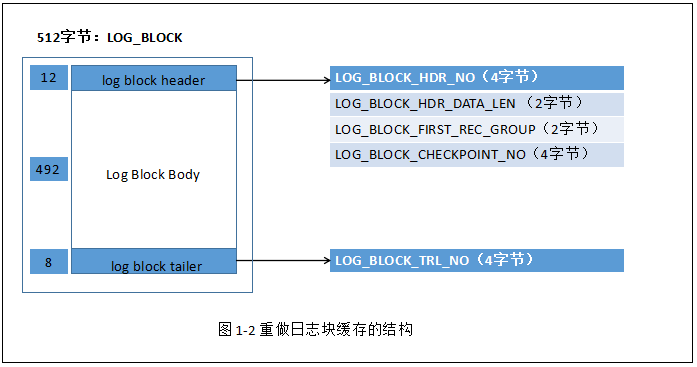
在InnoDB存储引擎中,重做日志都是以512字节进行存储的.也就是说重做日志缓冲,重做日志文件都是以块(block)的方式进行保存.称为:重做日志块(redo log block),大小:512字节.
如果一个页中产生的重做日志大于512字节,就分割成多个重做日志块就行存储.
重做日志块的大小和磁盘扇区的大小一样,512字节,因此重做日志的写入可以保证原子性,不需要doublewrite技术.
日志块的组成:日志本身,日志块头(log block header),日志块尾(log block tailer)
Log Block Header 解析:
LOG_BLOCK_HDR_NO:4字节
log buffer由log block组成,在内部就像一个数组,而LOG_BLOCK_HDR_NO,用来标记这个数组中的位置。改制必须大于0,允许最大2G;如果在日志刷新写入段时,是第一个日志块,最高位就设置成1.
LOG_BLOCK_DATA_LEN:2字节
表示LOG_BLOCK所占用的大小,被写满时,该值为:0x200,表示全部block空间,即占用512字节。
LOG_BLOCK_FIRST_REC_GROUP:占用2字节
表示LOG_BLOCK中第一个日志所在的偏移量。如果LOG_BLOCK_FIRST_REC_GROUP=LOG_BLOCK_DATA_LEN 表示log block不包含新的日志。
LOG_BLOCK_CHECKPOINT_NO:4字节
表示:LOG_BLOCK最后被写入时的检查点。如果此时log block还没写满,只能等下次log flush 时,才会更新。
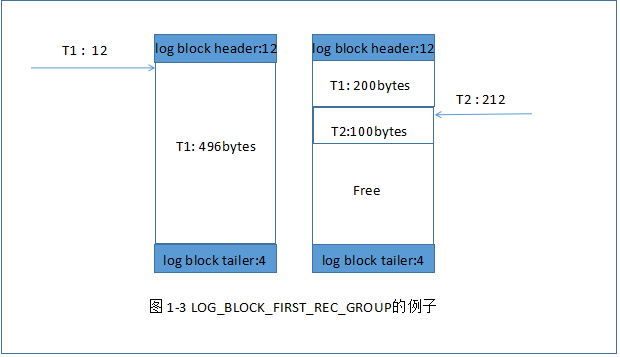
关于一个事务占用两个log block的图:
事务T1的重做日志占用:696字节
事务T2的重做日志占用:100字节
有图知道:事务T1 696字节,占用两个log block,左侧的log block中 LOG_BLOCK_FIRST_REC_GROUP=12,即第一个日志开始的位置。
在第二个block中,由于包含了T1的重做日志,因此事务T2的重做日志才是block中的第一个日志,即 LOG_BLOCK_FIRST_REC_GROUP=(12+200)=212
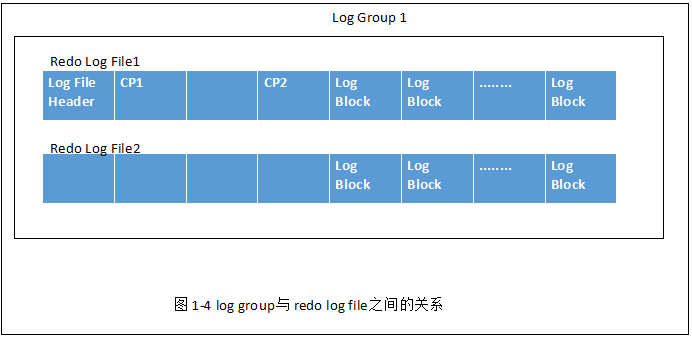
3.重做日志组(log group)
log group为重做日志组,里面有多个重做日志文件。源码中支持log group的镜像功能,但已禁用了,因此InnoDB存储引擎实际只有1个log group。
log group 是逻辑上的概念!!!
重做日志存储的就是之前在log buffer中保存的块,因此也是根据块的方式进行物理存储的管理。block=512bytes。
InnoDB存储引擎运行过程中, log buffer根据一定的规则将log block刷新到磁盘:
1.事务提交时
2.当log buffer中一半的空间已经被使用
3.log checkpoint时
redo log file的写入顺序:
log block 写入追加到redo log file的最后部分,当一个redo log file写满时,会写入下一个redo log file。 这种方式:round-robin.
看起来是顺序的,其实不然,除了保存log buffer刷新到磁盘的log block,还保存了一些其他信息,这些信息占:2KB,即redo log file 的前2KB不保存log block的信息。
2KB的信息:保存 4 * 512字节的 块。
| 名称 |
大小(字节)
|
|
log file header
|
512
|
|
checkpoint1
|
512
|
|
空
|
512
|
|
checkpoint2
|
512
|
上述信息只在log group的第一个redo log file里存储,其余file留空,这也就是说 写入不是顺序的!如下图:
4.重做日志的格式
5.LSN
LSN : Log Sequence Number的缩写,代表日志序列号,单位:字节。在innodb存储引擎中占有8字节,单调递增。
LSN : 表示的含义
- 重做日志写入的总量
- checkpoint的位置
- 页的版本
LSN 表示事务写入重做日志的字节总量。例如,当前重做日志的LSN是1000,事务T1写入了100字节的重做日志,LSN就变成1100,又有事务T2写入200字节的重做日志,那么LSN变成:1300.
LSN不仅记录在重做日志中,还记录在页中。每个页的开头部有一个FIL_PAGE_LNS,记录该页的LSN。
页中的LSN表示:该页最后刷新时LSN的大小。
重做日志记录的是每个页的物理更改日志,因此页中的LSN用来判断是否需要进行恢复操作。例如:页的LSN为:10000,数据库启动时,写入重做日志的LSN:13000,表明该事务已经提交,数据库需要恢复;重做日志中的LSN小于页中的LSN,不需要进行重做,因为页中的LSN表示已经刷新到该位置。
通过:SHOW ENGINE INNODB STATUS\G来查看LSN的情况
---
LOG
---
Log sequence number 47324552 ----------------->表示当前的LSN
Log flushed up to 47324552 ----------------->表示刷新到重做日志的LSN
Pages flushed up to 47324552 ----------------->表示刷新到磁盘的LSN
Last checkpoint at 47324552
Max checkpoint age 80826164
Checkpoint age target 78300347
....
上述的3个值,生产环境中可能是不同的:因为一个事务从重做日志缓冲刷新到重做日志文件,并不只是在事务提交时发生,每秒都会有重做日志缓冲刷新到重做日志文件的操作。
6.恢复
InnoDB存储引擎在启动时,不管上次数据库是否正常关闭,都会尝试进行恢复。重做日志是物理日志,恢复时比较快。
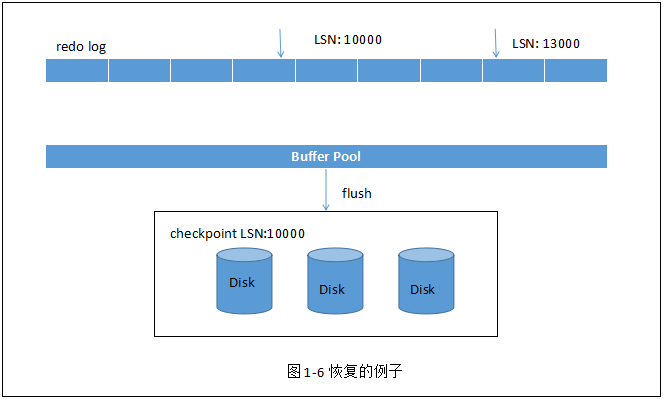
checkpoint 表示已经刷新到磁盘上的LSN。
例子:redo log file 记录的LSN:13000,刷新到磁盘上的LSN:10000,数据库在10000处宕机,恢复时,只需恢复10000~13000的部分。
【redo log buffer】【redo log file】-原理
目录:
1.重做日志写入过程图
2.相关知识点汇总图
3.redo_log_buffer 原理
4.redo_log_file 原理
1. 重做日志写入过程:
2. 相关知识点汇总:
3. redo log buffer 原理
重做日志缓冲(redo log buffer)是Innodb存储引擎的内存区域中的一部分。
【重做日志信息--(1)-->redo log buffer--(2)-->重做日志文件】
在(2)中涉及知识:
<1>.关于innodb_log_buffer_size的大小:(默认8M)
mysql> show variables like 'innodb_log_buffer_size%';
+------------------------+---------+
| innodb_log_buffer_size | 8388608 |
+------------------------+---------+
8388608(Byte)/1024/1024=8M
重做日志缓冲不需要设置的太大,只要保证每秒产生的事务量在缓冲大小范围之内。因为每秒都会刷新缓冲到日志文件。8M足够了。
<2>.在以下三种情况下,会将重做日志缓冲中的内容刷新到外部磁盘的重做日志文件中。
- Master Thread 每一秒将重做日志缓冲刷新到重做日志文件;
- 每个事务提交时会将重做日志缓冲刷新到重做日志文件;
- 当重做日志缓冲池剩余空间小于1/2时,重做日志缓冲刷新到重做日志文件。
4. redo log file 原理
<1>.重做日志介绍
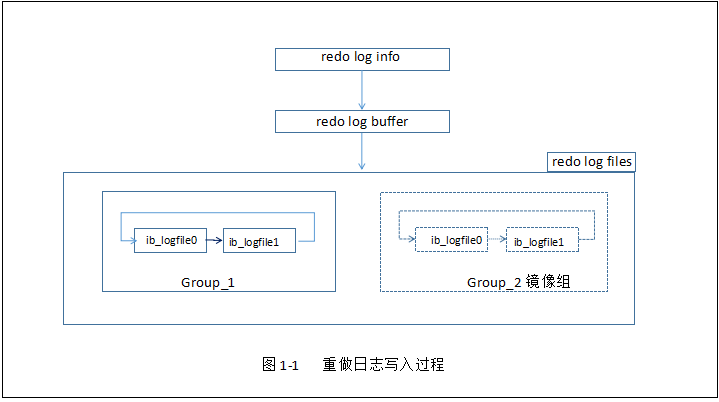
日志文件名:
1.innodb_log_group_home_dir参数指定的目录下有两个文件:ib_logfile0,ib_logfile1
2.该文件被称为:重做日志文件(redo log file),记录Innodb存储引擎的事务日志。至关重要!!!
3.例如:服务器意外宕机导致实例失败,Innodb存储引擎利用重做日志恢复到宕机前的状态,以此保证数据的完整性。
日志文件组:
1.每个Innodb存储引擎至少有1个重做日志文件组,每个组至少包含2个重做日志文件(ib_logfile0,ib_logfile1).
2.可以通过设置多个镜像日志组(mirrored log groups),将不同组放到不同磁盘,提高重做日志的高可用性。
3.日志组中的文件大小是一致的,以循环的方式运行。文件1写满时,切换到文件2,文件2写满时,再次切换到文件1.
日志文件参数:
1.innodb_log_file_size 重做日志文件的大小。
2.innodb_log_files_in_group 指定重做日志文件组中文件的数量,默认2
3.innodb_mirrored_log_groups 指定了日志镜像文件组的数量,默认1
4.innodb_log_group_home_dir 指定日志文件组所在的路径,默认./ ,表示在数据库的数据目录下。
<2>.重做日志文件大小设置
- 太大:恢复时可能需要很长时间
- 太小:可能导致一个事务需要多次切换重做日志文件;会导致async checkpoint,导致性能抖动。
- 错误日志警告信息:
InnoDB:ERROR:the age of the last checkpoint is 9433645,InnoDB:which exceeds the log group capacity 9433498.
解析:重做日志有个capacity变量,代表最后的检查点不能超过这个阈值,如果超过,必须将缓冲池中脏页列表(flush list)中的部分脏数据页写回磁盘,这是会导致用户线程的阻塞。
<3>.二进制日志和重做日志的对比:
1.类别
二进制日志:记录MySQL数据库相关的日志记录,包括InnoDB,MyISAM等其它存储引擎的日志。
重做日志:只记录InnoDB存储引擎本身的事务日志。
2.内容
二进制日志:记录事务的具体操作内容,是逻辑日志。
重做日志:记录每个页的更改的物理情况。
3.时间
二进制日志:只在事务提交完成后进行写入,只写磁盘一次,不论这时事务量多大。
重做日志:在事务进行中,就不断有重做日志条目(redo entry)写入重做日志文件。
<4>.重做日志条目
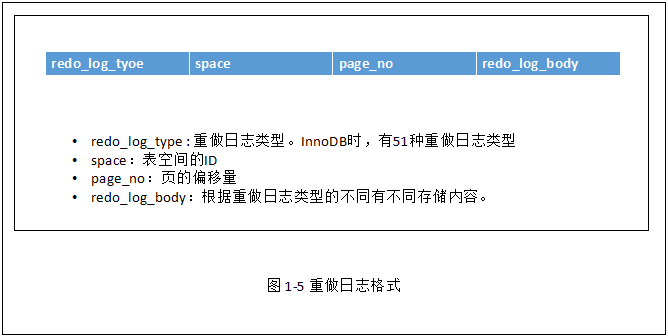
1.条目基本格式
| redo_log_type (1字节) |
space (压缩后可能<4字节) |
page_no |
redo_log_body |
reod_log_type: 占用1字节,表示重做日志类型。各种不同操作有不同的重做日志格式,但有基本的格式。
space:表空间的ID,采用压缩的方式,占用空间可能小于4字节。
page_no:页的偏移量,同样采用压缩方式
redo_log_body:每个重做日志的数据部分,恢复时需要调用相应的函数解析。
<5>.写入过程
1.重做日志信息 先写入 重做日志缓冲 再按一定条件顺序写入重做日志文件!
2.redo log buffer 向 redo log file 写,是按512个字节,也就是一个扇区的大小进行写入。扇区是写入的最小单位,一定能写入成功,因此过程中不需要double write.