

Redis集群的节点通信原理
Redis集群搭建中,数据如何在节点分布的原理,下面来介绍一下节点之间是如何进行通信(节点握手)
一、基础通讯原理
1、维护集群的元数据的两种方案介绍及对比
在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据是指:节点负责哪些数据,是否出现故障等状态信息。常见的元数据维护方式分为:集中式和P2P方式。
- 集中式:
- 优点 :元数据的更新和读取,时效性非常好,一旦元数据出现了变更,立即就更新到集中式的存储中。
- 缺点 :所有的元数据的更新压力全部集中在一个地方,可能导致元数据的存储有压力。
- gossip:
- 优点 :元数据的更新比较分散,不是集中在同一个地方,更新请求会陆陆续续到达所有节点上去更新,有一定的延时,降低了压力。
- 缺点 :元数据更新有延时,可能会导致集群的一些操作会有一些滞后。
集中式示例图-1:
集群元数据集中式存储的典型代表就是storm:

集中式示例图-2:假如redis cluster采用集中式存储元数据如下图:

P2P方式的gossip的redis cluster方式示例图-3:
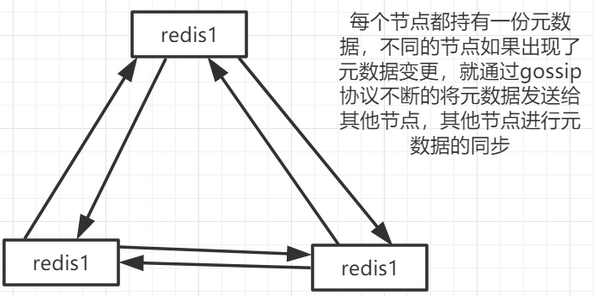
2、redis cluster节点间采用gossip协议进行通讯
回到redis cluster,Redis集群采用P2P的Gossip(流言)协议,跟集中式不同,不是将集群元数据(节点信息、hashslot->node之间的映射表关系,还有master->slave之间关系,故障的信息等)集中存储在某个节点上,Gossip协议工作原理就是节点彼此不断通信交换信息,一段时间后集群的所有的节点都会有完整的(集群)信息,这种方式类似流言传播
节点之间通信示意图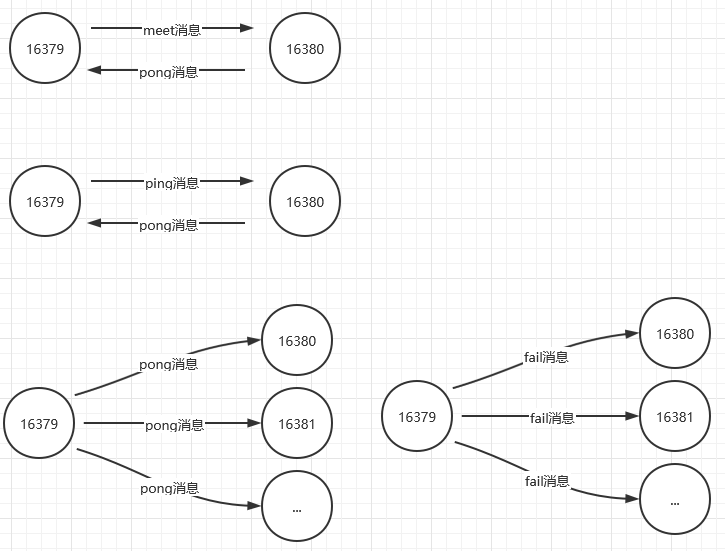
3、10000端口
每个节点都有一个专门用于节点间通信的端口号,就是自己提供服务的端口号+10000。每个节点每隔一段时间都会往另外几个节点发送ping消息,同时其他节点接收到ping之后会返回pong消息。
4、节点间交换的信息
包含故障信息,节点的增加和移除,hash slot信息等等。
二、Gossip消息
Gossip协议的主要职责就是信息交换。信息交换的载体就是节点彼此发送的Gossip消息,常用的Gossip消息可分为:ping消息、pong消息、meet消息、fail消息
- meet消息:用于通知新节点加入(某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信)。消息发送者通知接收者加入到当前集群,meet消息通信正常完成后,接收节点会加入到集群中并进行周期性的ping、pong消息交换
- 例如:执行redis-trib.rb add-node 命令时,其实内部就是发送了一个gossip meet消息,给新加入的节点,通知那个节点去加入我们的集群
- ping消息:集群内交换最频繁的消息,集群内每个节点每秒向多个其他节点发送ping消息,用于检测节点是否在线和交换彼此状态信息。ping消息发送封装了自身节点和部分其他节点的状态数据
- ping消息深入
ping很频繁,而且要携带一些元数据,所以可能会加重网络负担
每个节点每秒会执行10次ping,每次会选择5个最久没有通信的其他节点
当然如果发现某个节点通信延时达到了cluster_node_timeout / 2,那么立即发送ping,避免数据交换延时过长,落后的时间太长了
比如说,两个节点之间都10分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题
所以cluster_node_timeout可以调节,如果调节比较大,那么会降低发送的频率
每次ping,一个是带上自己节点的信息,还有就是带上1/10其他节点的信息,发送出去,进行数据交换
至少包含3个其他节点的信息,最多包含总节点-2个其他节点的信息
- ping消息深入
- pong消息:当接收到ping、meet消息时,作为响应消息回复给发送方确认消息正常通信。pong消息内部封装了自身状态数据。节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新,也可以用于信息广播和更新
- fail消息:当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其他节点接收到fail消息之后把对应节点更新为下线状态
接收节点会解析消息内容并根据自身的识别情况做出相应处理,对应流程:
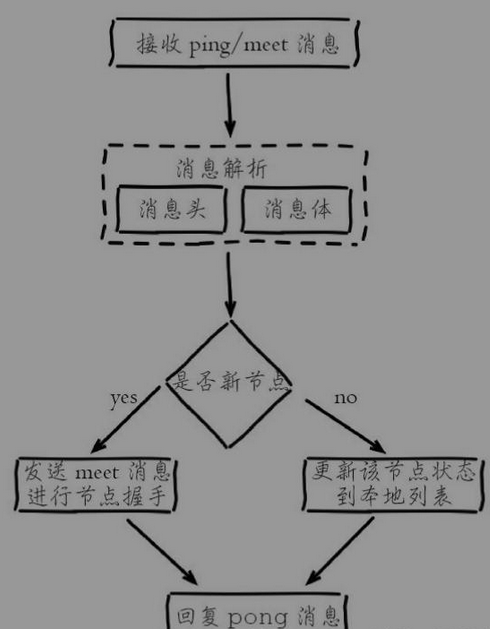
- 解析消息头过程:消息头包含了发送节点的信息,如果发送节点是新节点且消息是meet类型,则加入到本地节点列表;如果是已知节点,则尝试更新发送节点的状态,如槽映射关系、主从角色等状态
- 解析消息体过程:如果消息体的clusterMsgDataGossip数组包含的节点是新节点,则尝试发起与新节点的meet握手流程;如果是已知节点,则根据cluster MsgDataGossip中的flags字段判断该节点是否下线,用于故障转移
三、节点通讯优化
节点选择
由于内部需要频繁地进行节点信息交换,而ping/pong消息会携带当前节点和部分其他节点的状态数据,势必会加重带宽和计算的负担。Redis集群内节点通信采用固定频率(定时任务每秒执行10次)。因此节点每次选择需要通信的节点列表变得非常重要。通信节点选择过多虽然可以做到信息及时交换但成本过高。节点选择过少会降低集群内所有节点彼此信息交换频率,从而影响故障判定、新节点发现等需求的速度。因此Redis集群的Gossip协议需要兼顾信息交换实时性和成本开销,
选择发送消息的节点数量
集群内每个节点维护定时任务默认每秒执行10次,每秒会随机选取5个节点找出最久没有通信的节点发送ping消息,用于保证Gossip信息交换的随机性。每100毫秒都会扫描本地节点列表,如果发现节点最近一次接受pong消息的时间大于cluster_node_timeout/2,则立刻发送ping消息,防止该节点信息太长时间未更新。根据以上规则得出每个节点每秒需要发送ping消息的数量=1+10*num(node.pong_received>cluster_node_timeout/2),因此cluster_node_timeout参数对消息发送的节点数量影响非常大。当我们的带宽资源紧张时,可以适当调大这个参数,如从默认15秒改为30秒来降低带宽占用率。过度调大cluster_node_timeout会影响消息交换的频率从而影响故障转移、槽信息更新、新节点发现的速度。因此需要根据业务容忍度和资源消耗进行平衡。同时整个集群消息总交换量也跟节点数成正比。
消息数据量
每个ping消息的数据量体现在消息头和消息体中,其中消息头主要占用空间的字段是myslots[CLUSTER_SLOTS/8],占用2KB,这块空间占用相对固定。消息体会携带一定数量的其他节点信息用于信息交换,消息体携带数据量跟集群的节点数息息相关,更大的集群每次消息通信的成本也就更高,因此对于Redis集群来说并不是大而全的集群更好
四、面向集群的jedis内部实现原理
1.基于重定向的客户端
redis-cli c,自动重定向
①请求重定向
客户端可能会挑选任意一个redis实例去发送命令,每个redis实例接收到命令之后,都会接受key对应的hash slot,如果在本地就在本地处理,否则返回moved给客户端,让客户端进行重定向。
cluster keyslot mykey ,可以查看一个key对应的hash slot是什么。
用redis-cli的时候,可以加入-c参数,支持自动的请求重定向,redis-cli接收到moved之后,会自动重定向到对应的节点执行命令。
②计算hash slot
计算hash slot的算法,就是根据key计算CRC16值,然后对16384取模,拿到对应的hash slot。
用hash tag可以手动指定key对应的slot,同一个hash tag下的key,都会在一个hash slot中,比如set mykey1:{100}和set mykey2:{100}。
③hash slot查找
节点间通过gossip协议进行数据交换,就知道每个hash slot在那个节点上面了
2.smart jedis
①什么是smart jedis:
基于重定向的客户端,很消耗网络IO,因为大部分情况下,可能都会出现一次请求重定向,才能找到正确的节点。
所以大部分的客户端,比如java redis客户端,就是jedis,都是smart的。
本地维护一份hashslot -> node的映射表,缓存,大部分情况下,直接走本地缓存就可以找到hashslot -> node,不需要通过节点进行moved重定向。
②JedisCluster的工作原理
A:在JedisCluster初始化的时候,就会随机选择一个node,初始化hash slot到node的映射表,同时为每个节点创建一个JedisPool连接池。
B:每次基于JedisCluster执行操作,首先会在本地计算key的hash slot,然后在本地映射表中找到节点。
C:如果那个node真好还是持有那个hash slot,那么就OK。
D:如果JedisCluster API返回的是moved,那么利用该节点的数据,更新本地的hash slot 和node的映射表。
E:重复上面的步骤,知道找到对应的节点,如果重试超过5次,就会报错,抛出JedisClusterMaxRedirectionException异常。
jedis老版本,可能会出现在集群某个节点故障还没完成自动切换恢复时,频繁更新hash slot,频繁ping节点检查活跃,导致大量网络IO开销。
jedis最新版本,对于这些过度的hash slot更新和ping,都进行了优化,避免了类似问题。
③hash slot迁移和ask重定向
A:如果hash slot正在进行迁移,那么会返回ask重定向给jedis,
B:jedis接收到ask重定向之后,会重新定位到目标节点去执行。
C:但是因为ask发生在hash slot迁移过程中,所以收到ask是不会更新hash slot本地缓存。
D:已经可以确定说hash slot已经迁移完了,moved是会更新本地hash slot到node的映射缓存的。
(3)高可用与主备切换原理
redis cluster的高可用原理,几乎和哨兵时类似的。
1.判断节点宕机
①如果一个节点认为另一个节点道济,那么就是pfail,主观宕机。
②如果多个节点都认为另外一个 节点宕机了,那就是fail,客观宕机。
③在cluster-node-timeout内,某个几点一直没有返回pong,那么就认为pfail。
④如果一个节点认为某个节点pfail了,那么会在gossip ping消息中,发送给其他节点,如果超过半数的节点都认为pfail了,那就好变成fail。
2.从节点过滤
①对宕机的master node,从其所有的slave node中,选择一个切换成master node。
②检查每个slave node与master node断开连接的时机,如果超过了cluster-node-timeout * cluster-slave-validity-factor,那么这个节点就没有资格切换成 master node,直接被过滤。
3.从节点选举
①每个从几点,都根据自己对master复制数据的offset,来设置一个选举时间,offset越大的从节点,选举时间越靠前,优先进行选举。
②所有的master node开始slave选举投票,给要进行选举的slave进行投票,如果大部分master node(N/2 + 1)都投票给了某个从节点,那么选举通过,那个从节点可以切换成master node。
③从节点执行主备切换,从节点切换为主节点。
4.与哨兵进行比较
整个流程跟哨兵相比,非常类似,所以说,redis cluster功能强大,直接集成了replication和sentinal的功能
https://blog.csdn.net/nihao12323432/article/details/81204499
https://www.cnblogs.com/jack1995/p/10915801.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App
· 张高兴的大模型开发实战:(一)使用 Selenium 进行网页爬虫
2019-02-14 Kong(V1.0.2) Clustering Reference
2019-02-14 Kong(V1.0.2) Health Checks and Circuit Breakers Reference
2019-02-14 Kong(V1.0.2)loadbalancing
2019-02-14 Kong(v1.0.2)认证