


mongoDB的读写分离
二、springboot中实现读写分离
2.2、在代码层面动态切换
一、读写分离相关的理论
1.1、ReadPreference读偏好
在副本集Replica Set中才涉及到ReadPreference的设置,默认情况下,读写都是分发都Primary节点执行,但是对于写少读多的情况,我们希望进行读写分离来分摊压力,所以希望使用Secondary节点来进行读取,Primary只承担写的责任(实际上写只能分发到Primary节点,不可修改)。
MongoDB有5种ReadPreference模式:
-
primary: 主节点,默认模式,读操作只在主节点,如果主节点不可用,报错或者抛出异常。
-
primaryPreferred:首选主节点,大多情况下读操作在主节点,如果主节点不可用,如故障转移,读操作在从节点。
-
secondary:从节点,读操作只在从节点, 如果从节点不可用,报错或者抛出异常。
-
secondaryPreferred:首选从节点,大多情况下读操作在从节点,特殊情况(如单主节点架构)读操作在主节点。
-
nearest:最邻近节点,读操作在最邻近的成员,可能是主节点或者从节点。
1.2脏数据
其实说的就是 MongoDB 的数据持久化,在一个数据写到 journal 并 flush 到磁盘上之前,数据都是脏的,而在复制集内,数据会通过 Oplog 传播到其它节点上,然后重复写入的步骤。
假如这个过程中,主节点挂掉了,之前的某一个 Secondary 提升成为了 Primary,由于数据没有写到大部分节点上,于是新的 Primary 看不到之前的应该写入的新数据,即使这时候旧的 Primary 回来了,它也只能是 Secondary,它之前的那些新数据就会丢失,从而导致数据的回滚。
1.3复制集的缺点
说了优点之后,再说说它的缺点,毕竟 CAP 原理还是统治着分布式领域。在 CAP 原理中,C 表示一致性,A 表示一致性,P 表示分区容忍性。
MongoDB 的默认复制集配置是显然的 CP,因为 ReadPreference 默认为 Primary;如果换成 Secondary 或者 SecondaryPreferred,就相当于 AP 了,C 用了业界默认的最终一致性,因为它的复制是基于 Oplog 的异步方案。
但是,AP 方案容易导致的问题有复制延迟导致的:
注意:这些的例子只是随便举例,不一定会是真实情况。
- 写后读,或者说是读己写问题:即从 Primary 写入数据后,然后马上从 Secondary 读,这时候由于延迟问题而有可能在 Secondary 读不到最新数据,于是我刚发了个微博,刷新了下反而消失了,过一会儿又出现了;
- 单调读问题,或者说是时光倒流问题:这时候由于多次从不同的 Secondary 读取数据,比如微博的评论下面,如果两次读到的数据不一致后,容易导致先看到了回复,刷新后却消失了,再过一会儿又出现了;
- 因果读写不一致问题:与上面的微博例子相似,即出现在一个微博下面,评论的回复比评论先到达的现象;
解决的办法显然是有的,MongoDB 分别从读与写提供了解决方案,让你能够调整配置来取舍复制集中的 C 与 A。
1.4读隔离 Read Concern
目前一共有五种读隔离的设置:
- local:不保证数据都被写入了大部分节点,我们在使用的时候基本默认的选项;
- available:3.6 版本引入,与 因果一致性会话 有关,也是不保证数据都被写入了大部分节点,暂时还没用过;
- majority:保证数据都被写入了大部分节点,但是必须使用 WiredTiger 存储引擎;
- linearizable:这个也没有用过,意思也不是很清楚,文档大致意思理解为对文档所有的读写都是顺序,或者说线性执行的,会导致花费时间超过 majority,建议与 maxTimeMS 一起食用;
- snapshot:4.0 版本引入,与多文档的事务有关,也是没用过;
所以除了 local 与 majority,我都不能保证叙述的准确性,毕竟与实际用还是有区别的。但是基本上可以了解到:读隔离的效果是需要用时间去交换的,或者说降低可用性去交换的。
另外特别提一下这句文档中的话:
Regardless of the read concern level, the most recent data on a node may not reflect the most recent version of the data in the system.
不管 Read concern 的具体配置,节点上最新的数据,不一定意味着它也是系统中最新的数据。
因为不管 Read concern 如何配置,它始终是从单个节点读的,这个设计的初衷只能保证不读到脏数据。
1.5写确认 Write Concern
{ w: <value>, j: <boolean>, wtimeout: <number> }
对于 w 参数,则有三种,表示写入后得到多少个 Secondary 的确认后再返回:这三个参数,在进行写操作的时候非常有用,常见的设置便是将 j 设置为 true,表示等数据已经写入了磁盘上的 journal 后再返回,这时候即便数据库挂掉,也是能从 journal 中恢复的,注意这不是 oplog 它是高层次的日志,而 journal 是低层次的日志,是可以用来故障恢复后重建当前节点数据的日志5。
- 数字:那就是确切的个数了;
- majority:自动帮你计算 n/2 + 1;
- tag set,标签组:即制定哪几个 tag 的 Secondary;
最后一个 wtimeout,则是在制定 w 参数的时候,推荐一并设置,防止超时,毕竟这种确认是牺牲性能的,很可能导致超时。
看到这里,大致可以得出结论,MongoDB 将读隔离与写确认交给客户端去取舍,一定程度上解决了复制延迟导致的业务问题,而本质上,这种解决方案的原理就在于用事务6
------------------------------------------------------------------------------------------------------
readConcern 的是为了在于解决脏读问题,用户从 MongoDB 的 primary 上读的数据并没有同步到大多数节点,然后 primary 宕机恢复, primary节点会将未同步到大多数节点的数据回滚,导致用户读到了脏数据。
当指定 readConcern 级别为majority ,能保证用户读到的数据已经写入到大多数节点,而这样的数据肯定不会发生回滚,避免了脏读的问题。
需要注意的是,readConcern 只是保证读到的数据不会发生回滚,但并不能保证读到的数据最新。
参考官网:
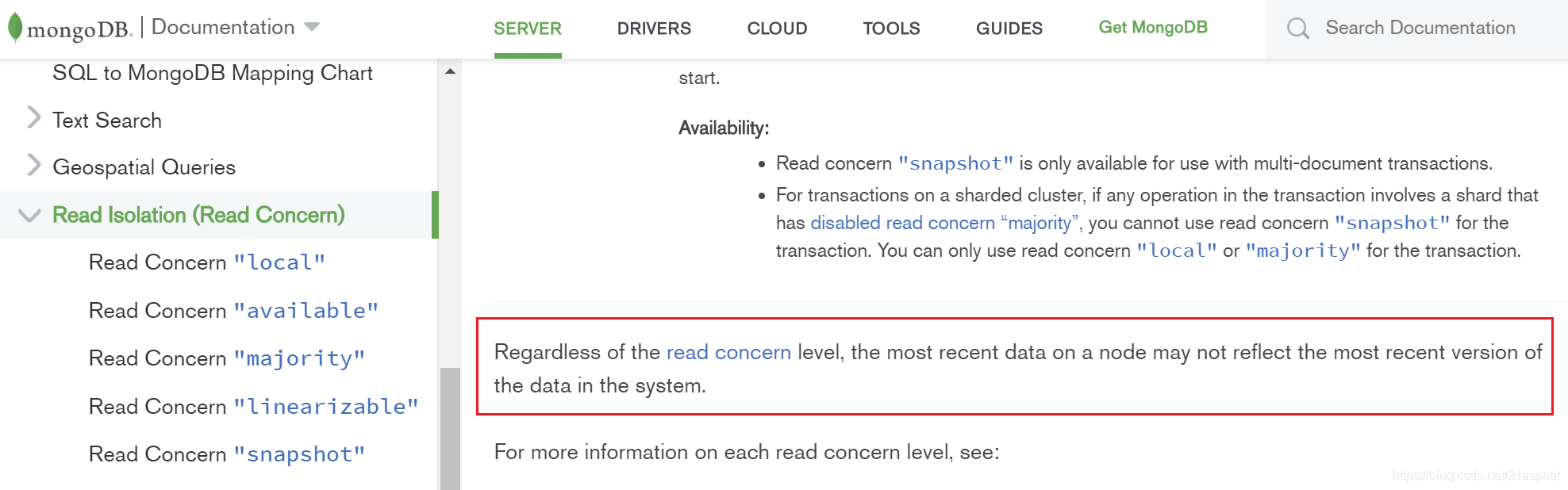
误区: majority并非从多节点读取,依然是单节点读取。
readConcern 原理
snapshot 0,1,2,3......N的状态是committed/uncommitted
同步到大多数节点时,对应的snapshot会标记为commmited。
用户读取:读最新的 commited 状态的 snapshot,这样就保证了读到的数据是已经同步到大多数节点。
secondary节点在自身oplog发生变化会同步信息到primary。
primary节点统计超过半数的节点的同步信息就修改该snapshot为uncommitted->commited。
同时secondary拉取oplog的同时从primary节点得到最新一条已经同步到大多数节点的oplog,更新自身的 snapshot 状态。
------------------------------------------------------------------------------------------------------
-----------------------------------------------------
mongodb 的读写一致性由 WriteConcern 和 ReadConcern 两个参数保证。
两者组合可以得到不同的一致性等级。
指定 writeConcern:majority 可以保证写入数据不丢失,不会因选举新主节点而被回滚掉。
readConcern:majority + writeConcern:majority 可以保证强一致性的读
readConcern:local + writeConcern:majority 可以保证最终一致性的读
mongodb 对configServer全部指定writeConcern:majority 的写入方式,因此元数据可以保证不丢失。
对 configServer 的读指定了 ReadPreference:PrimaryOnly 的方式,在 CAP 中舍弃了A与P得到了元数据的强一致性读。
---------------------------------------------------
二、springboot中的MongoDB读写分离实现
2.1 MongoDB连接池指定读模式
再重申下在副本集Replica Set中才涉及到ReadPreference的设置才有意义。
连接池的配置中主要注意几个参数:
// 客户端配置(连接数、副本集群验证) MongoClientOptions.Builder builder = new MongoClientOptions.Builder(); //... builder.readPreference(ReadPreference.secondaryPreferred()); builder.readConcern(ReadConcern.MAJORITY); //... MongoClientOptions mongoClientOptions = builder.build();
xml示例(没有测试过):
<!-- mongodb配置 --> <mongo:mongo id="mongo" host="${mongo.host}" port="${mongo.port}" write-concern="NORMAL" > <mongo:options connections-per-host="${mongo.connectionsPerHost}" threads-allowed-to-block-for-connection-multiplier="${mongo.threadsAllowedToBlockForConnectionMultiplier}" connect-timeout="${mongo.connectTimeout}" max-wait-time="${mongo.maxWaitTime}" auto-connect-retry="${mongo.autoConnectRetry}" socket-keep-alive="${mongo.socketKeepAlive}" socket-timeout="${mongo.socketTimeout}" slave-ok="${mongo.slaveOk}" write-number="1" write-timeout="0" write-fsync="false" /> </mongo:mongo> <!-- mongo的工厂,通过它来取得mongo实例,dbname为mongodb的数据库名,没有的话会自动创建 --> <mongo:db-factory id="mongoDbFactory" dbname="uba" mongo-ref="mongo" /> <!-- 读写分离级别配置 --> <!-- 首选主节点,大多情况下读操作在主节点,如果主节点不可用,如故障转移,读操作在从节点。 --> <bean id="primaryPreferredReadPreference" class="com.mongodb.TaggableReadPreference.PrimaryPreferredReadPreference" /> <!-- 最邻近节点,读操作在最邻近的成员,可能是主节点或者从节点。 --> <bean id="nearestReadPreference" class="com.mongodb.TaggableReadPreference.NearestReadPreference" /> <!-- 从节点,读操作只在从节点, 如果从节点不可用,报错或者抛出异常。存在的问题是secondary节点的数据会比primary节点数据旧。 --> <bean id="secondaryReadPreference" class="com.mongodb.TaggableReadPreference.SecondaryReadPreference" /> <!-- 优先从secondary节点进行读取操作,secondary节点不可用时从主节点读取数据 --> <bean id="secondaryPreferredReadPreference" class="com.mongodb.TaggableReadPreference.SecondaryPreferredReadPreference" /> <!-- mongodb的主要操作对象,所有对mongodb的增删改查的操作都是通过它完成 --> <bean id="mongoTemplate" class="org.springframework.data.mongodb.core.MongoTemplate"> <constructor-arg name="mongoDbFactory" ref="mongoDbFactory" /> <property name="readPreference" ref="primaryPreferredReadPreference" /> </bean>
对应的配置(在建立mongoDB的连接时,指定ReadPreference)
请仔细看好 spring.data.mongodb.uri 的配置,他的格式如下,可以参考mongodb连接:
mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]
例子:
# MongoDB URI配置 重要,添加了用户名和密码验证 spring.data.mongodb.uri=mongodb://zhuyu:zhuyu@192.168.68.138:27017,192.168.68.137:27017,192.168.68.139:27017/ai?slaveOk=true&replicaSet=zypcy&write=1&readPreference=secondaryPreferred&connectTimeoutMS=300000 #每个主机的连接数 spring.data.mongodb.connections-per-host=50 #线程队列数,它以上面connectionsPerHost值相乘的结果就是线程队列最大值 spring.data.mongodb.threads-allowed-to-block-for-connection-multiplier=50 spring.data.mongodb.connect-timeout=5000 spring.data.mongodb.socket-timeout=3000 spring.data.mongodb.max-wait-time=1500 #控制是否在一个连接时,系统会自动重试 spring.data.mongodb.auto-connect-retry=true spring.data.mongodb.socket-keep-alive=true
验证读写分离是否生效:
创建一个 Rest风格的 IndexController ,提供:添加与查询接口,访问这2个接口,看控制台输出,是否查操作自动分配到从库,写操作分配到主库
@RequestMapping("/index")
@RestController
public class IndexController {
@Autowired private MongoTemplate mongoTemplate;
@RequestMapping("/getList")
public List<TestModel> getList(){
List<TestModel> list = mongoTemplate.findAll(TestModel.class,"test");
return list;
}
@RequestMapping("/add")
public String add(){
TestModel model = new TestModel("zhuyu" + System.currentTimeMillis());
mongoTemplate.insert(model , "test");
return "success";
}
}
2.2、在代码层面动态切换
通过mongoTemplate对象动态指定 mongoTemplate.setReadPreference(readPreference);
例如,在同一个应用中定义2个mongoTemplate对象,一个设置从primary读,一个设置从Secondary读,根据应用场景选择不同的mongoTemplate
三、MongoDB读写分离验证

调整优先级的方法1:
改优先级,登录指定shard主节点,mongo ip:22001 -u root --password=xxxx --authenticationDatabase admin
1. 先删除节点,rs.remove("ip1:22002")
2. 再添加回节点,指定优先级
rs.add({
_id: 0,
host: "ip1:22002",
priority: 5
})
3. 执行rs.reconfig()使配置生效
rs.add({
_id: 0,
host: "ip1:22002",
priority: 5
})
调整优先级的方法2:

分别进行读/写的场景压测,看服务器资源的消耗情况就知道读写分离是否生效了。
转自:
https://blog.csdn.net/zhuyu19911016520/article/details/82998162?depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-3&utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-3
https://blog.xizhibei.me/2019/05/05/mongodb-replica-set/
https://blog.csdn.net/cxu123321/article/details/108897067

