


jaeger 使用初探
不知道大家是怎么处理开头提到的那种问题的呢?最简单粗暴的办法就是把相关人员集中到一个会议室里面对数据,怎么对呢?
客户端开发人员:我查了日志,客户端的请求过程一共用了5s,请求是从几点几分几秒发起的,你们查下服务端的日志;
交易系统开发人员:我这边是几点几分几秒收到的请求,交易系统一共花了4s多一些,其中调用支付网关花了将近4s,网关那边看下日志吧;
网关开发人员:我这边是几点几分几秒收到的请求,网关一共花了3s多一点,大部分时间都花在了调用第三方上;
估计大多数人最开始都是这么处理此类问题的,简单粗暴。但如果三天两头给你来这么一下子你还受得了吗?每天给你几百个上千个订单号让你对数据,你还能抽时间写代码吗?估计连带薪上厕所的时间都没了吧。最后这个问题可能传到了领导那里,领导一般喜欢要全局报表数据,你怎么给他出这个报表?是不是束手无策,突然有点想换工作了,哈哈。我们还真是接到过这种需求,一堆人在那里awk然后就没有然后了。
“当一件事情成为一件常态,那意味着我们可能需要一件工具来解放自己了,靠人终究是靠不住的”,就在这种背景之下我们决定引入一个调用链追踪的工具来解放我们,也就是今天的主角jaeger。关于jaeger的说明网上很多,推荐去官网系统的了解一下 https://www.jaegertracing.io,我这里只是把搭建过程和使用上的一些心得分享出来和大家一起交流。
jaeger架构
直接引入一张官网的图
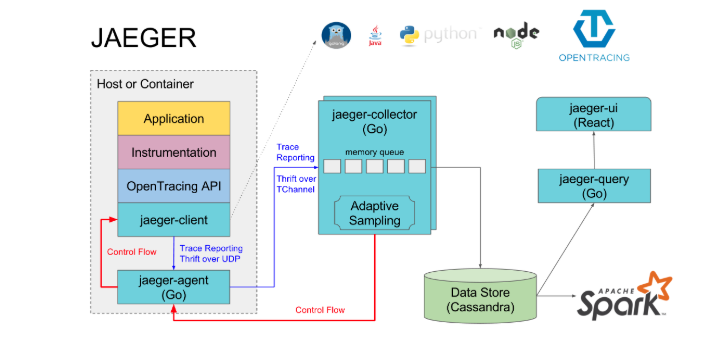
jaeger组件介绍:
jaeger-client:jaeger 的客户端,实现了opentracing协议;
jaeger-agent:jaeger client的一个代理程序,client将收集到的调用链数据发给agent,然后由agent发给collector;
jaeger-collector:负责接收jaeger client或者jaeger agent上报上来的调用链数据,然后做一些校验,比如时间范围是否合法等,最终会经过内部的处理存储到后端存储;
jaeger-query:专门负责调用链查询的一个服务,有自己独立的UI;
jaeger-ingester:中文名称“摄食者”,可用从kafka读取数据然后写到jaeger的后端存储,比如Cassandra和Elasticsearch;
spark-job:基于spark的运算任务,可以计算服务的依赖关系,调用次数等;
其中jaeger-collector和jaeger-query是必须的,其余的都是可选的,我们没有采用agent上报的方式,而是让客户端直接通过endpoint上报到collector。
搭建jaeger
因为我们的应用服务都是采用容器部署的,所以我们的jaeger服务也沿用以往的风格。
docker启动jaeger-collector
docker run -d --rm -p 14268:14268 -p 14269:14269 -e SPAN_STORAGE_TYPE=elasticsearch -e ES_SERVER_URLS=http://10.200.46.229:9200 jaegertracing/jaeger-collector:1.11
docker启动jaeger-query
docker run -d --rm -p 16686:16686 -p 16687:16687 -e SPAN_STORAGE_TYPE=elasticsearch -e ES_SERVER_URLS=http://10.200.46.229:9200 jaegertracing/jaeger-query:1.11
应用程序接入
接下来就是如何让调用链条上的各端接入了,这里只需要把握一个原则就好,“尽量让接入方无感知,没有侵入性”,这里简单说下我们的接入方式:
- 客户端接入:客户端采用okhttp 拦截器的方式接入,使用请求头传递trace上下文,这里还可以和okhttp 的EventListener配合起来获取一些网络层面的指标,比如dns解析时间,连接发起时间等等;
- web程序接入:web端采用springmvc拦截器方式接入,从http请求头里面来提取trace上下文,然后基于上下文构建一个springmvc的span,记得在请求结束的时候finish奥,否则调用链数据可能会长这样:

- RPC框架如何集成:一般RPC框架都会提供一些扩展点让使用者来做一些框架集成的事情,拿dubbo来说可以采用Filter和隐示传参的方式来实现请求上下文的传递;
- 外部调用如何集成:有一些调用是基于sdk或者httpclient调用的,这类调用我们如何植入调用链的逻辑呢?这里不得不佩服AspectJ的强大了,为了避免你少走弯路我还会推荐你去了解一下“spectj-maven-plugin”这个maven插件,什么?不是基于spring的那一堆注解就可以了吗,为什么还要引入maven来干这事。估计你还需要去了解一下运行期植入和编译器植入的相关概念以及适用场景。
具体你要把Span包装成什么样就靠你自由发挥了,但是不要太离谱,建议参考下这个https://opentracing.io/docs/overview/spans/。
上线
上线前问自己几个问题,我的拦截器写的是否健壮,抛异常了不会影响正常调用吧?是否需要评估一下数据量?别一上线把后端存储打死了。
使用jaeger-quey来检索调用链
- 先选择一个service然后针对这个service做一些复杂的检索,比如针对某个标签,操作的耗时等;
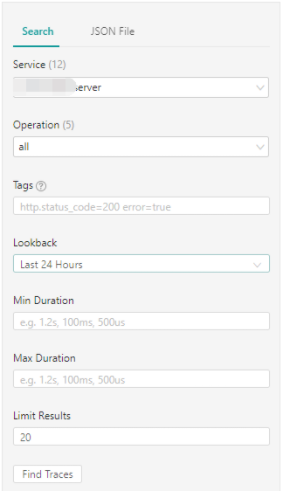
2.如果有满足条件的数据右边会展示出结果

上面图中分别展示了两条支付的调用链路,一条成功了,一条失败了,你可能会问:jaeger是怎么判断成功失败的呢?简单来说就是通过特殊的标签,直接甩给你一篇opentracing的文档看完就懂了 https://github.com/opentracing/specification/blob/master/semantic_conventions.md。
3.查看调用链详情

4.查看依赖关系,以及调用次数
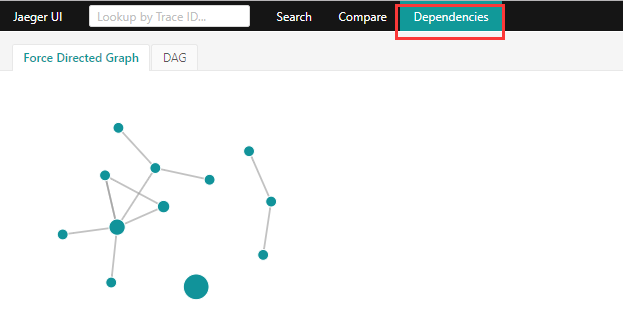
也许你服务也搭好了,调用链数据也看到了,但就是看不到这个调用关系图,别急你去这溜达一圈就知道了https://www.jaegertracing.io/docs/1.11/faq/。
好吧,今天就到这,大周六的晚上抽一点时间来梳理一下最近的工作,还希望对各位有一点点的帮助。

