Docker 部署ELK
1、安装docker前安装pip
sudo yum -y install epel-release
sudo yum install python-pip
2、安装docker
#安装依赖包
yum install -y yum-utils device-mapper-persistent-data lvm2
#添加docker yum源
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
#可选操作:允许拓展最新的不稳定的repository
yum-config-manager --enable docker-ce-edge
#安装Docker
yum -y install docker-ce
#安装docker-compose
sudo pip install -U docker-compose
#启动Docker
systemctl start docker
安装ELK:
1、下载镜像
这里我们使用elk集成镜像,地址:https://hub.docker.com/r/sebp/elk/tags
[root@centos-mq ~]# docker pull sebp/elk:660
注:660为elk版本
2、启动

[root@centos-mq ~]# echo "vm.max_map_count=262144" > /etc/sysctl.conf
[root@centos-mq ~]# sysctl -p
[root@centos-mq ~]# docker run -dit --name elk \ -p 5601:5601 \ -p 9200:9200 \ -p 5044:5044 \ -v /opt/elk-data:/var/lib/elasticsearch \ -v /etc/localtime:/etc/localtime \ sebp/elk:660
说明:-p 指定映射端口,5601kibana访问,9200es端口,5044 logstash收集日志端口;-v 指定es数据目录
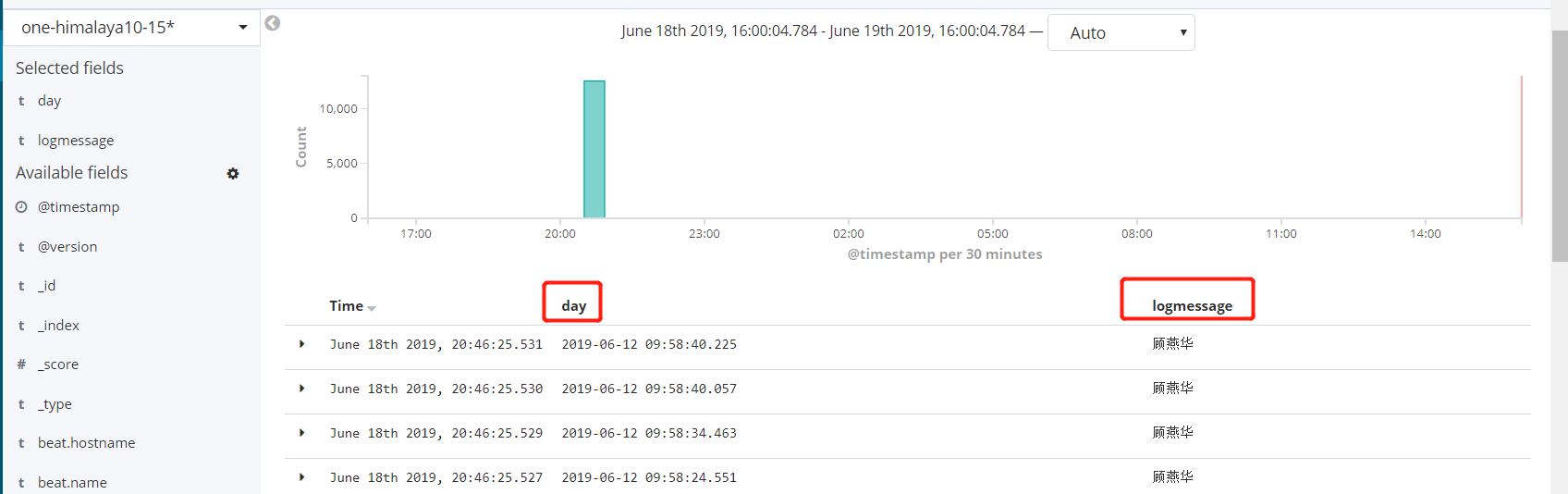
3、访问
启动后等待数据初始化后,浏览器输入:http://10.200.110.106:5601/app/kibana,可看到kibana web界面
4、文件目录
通过docker exec -it elk /bin/bash可进入容器中,具体各服务配置文件路径如下
[root@centos-mq ~]# docker exec -it elk /bin/bash /etc/logstash/ ## logstash 配置文件路径 /etc/elasticsearch/ ##es 配置文件路径 /var/log/ ## 日志路径
5、通过filebeat收集java
filebeat部署,版本最好与elk一直,这里也选择6.6.0版本,filebeat部署在应用所在服务器,进行日志收集,日志样例;
a)下载安装
[root@centos-mq ~]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.6.0-x86_64.rpm
[root@centos-mq ~]# rpm -ivh filebeat-6.6.0-x86_64.rpm
我本地是windows的,参考《windows系统安装运行filebeat》
b)配置收集java日志
[root@vanje-dev02 ~]# vim /etc/filebeat/filebeat.yml
#=========================== Filebeat inputs ============================
filebeat.inputs:- type: log
enabled: true
paths:
- /apps/oneJars/himalaya/logs/one.log ## 日志路径
tags: ["one-himalaya"] ## 标签,用于判断
multiline.pattern: '^\d{4}-\d{2}-\d{2}' ## 匹配日志开头
multiline.negate: true ## 日志合并
multiline.match: after
#output.elasticsearch:
#hosts: ["localhost:9200"] ## 注释 这里是配置采集的日志存放的方式,我们先经过logstash处理,所以这里注释
output.logstash:
hosts: ["10.10.0.13:5044"] ## 采集日志输出到logstash,ip为logstash服务ip
c)logstash配置
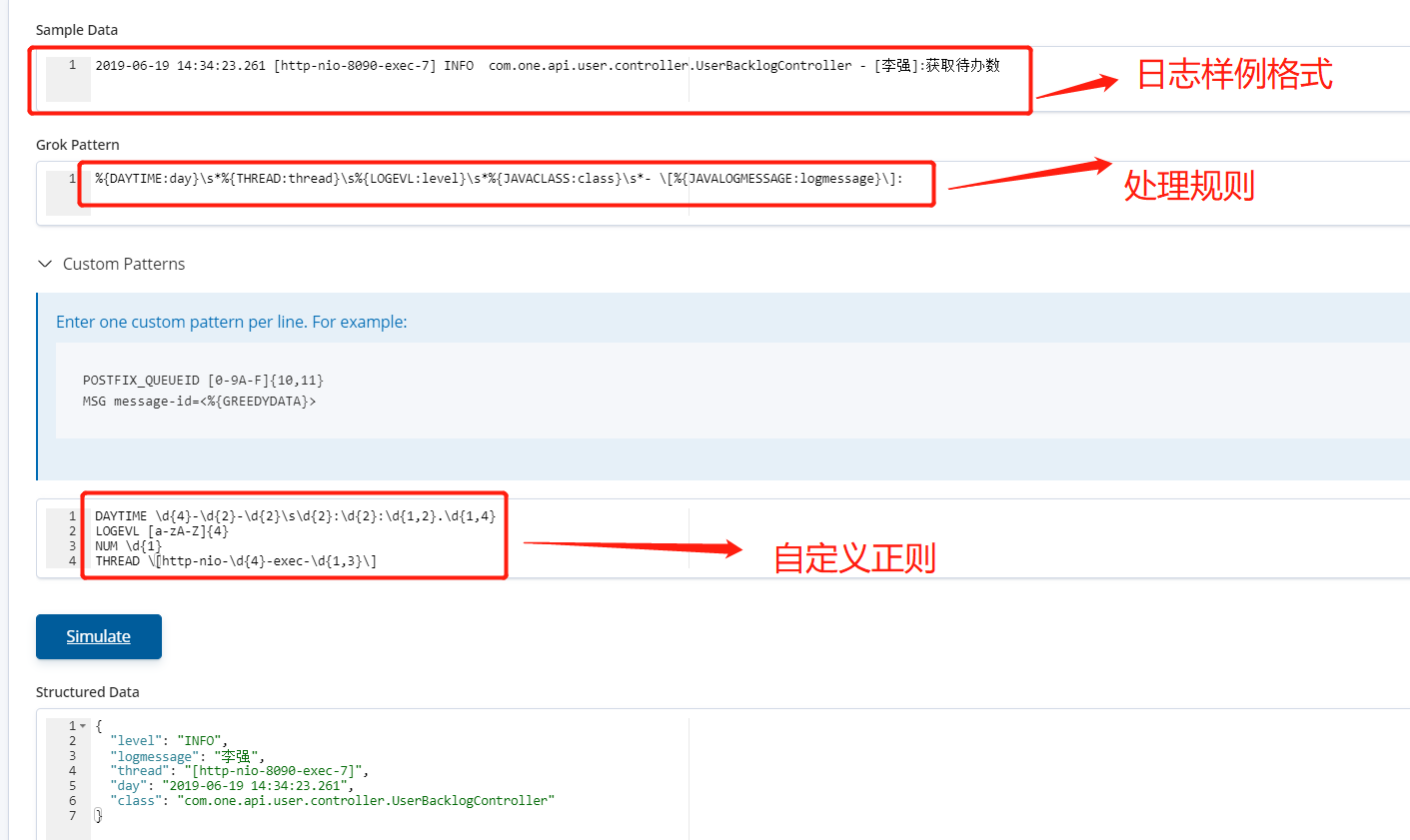
以下配置只是收集"2019-06-19 14:34:23.261 [http-nio-8090-exec-7] INFO com.one.api.user.controller.UserBacklogController - [李强]:获取待办数"格式日志,用来分析用户使用时间及姓名
## 定过滤指定日志,没用的日志我们这里不收集,正常是要收集所有,
vim /etc/logstash/conf.d/02-beats-input.conf input { beats { port => 5044 } } filter { #if "one-himalaya" in [tags] { if [message] =~ '获取待办数' { grok { patterns_dir => ["/etc/logstash/patterns"] match => { "message" => "%{DAYTIME:day}\s*%{THREAD:thread}\s%{LOGEVL:level}\s*%{JAVACLASS:class}\s*- \[%{JAVALOGMESSAGE:logmessage}\]:" } } } } output { # if "one-himalaya" in [tags] { if [message] =~ '获取待办数' { elasticsearch { hosts => ["172.16.223.55:9200"] index => "one-himalaya10-15-%{+YYYY.MM.dd}" } } }
## 自定义匹配规则
vim /etc/logstash/patterns
DAYTIME \d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{1,2}.\d{1,4}
LOGEVL [a-zA-Z]{4}
NUM \d{1}
THREAD \[http-nio-\d{4}-exec-\d{1,3}\]
## 重启logstash
/etc/init.d/logstash restart
说明:实际生产中,我们会对收集的日志做各种分析提取,需要灵活使用grok 正则匹配来提取自己想要的数据。 可以通过Kibana Dev Tools>>Grok Debugger工具进行调式,例如:
6、kibana查看日志
打开kibana web界面,跟据提示创建索引,即可看到已经收集的日志信息:day logmessage 这两个字段,为切割日志自定义的字段,这些字段跟据自己所需灵活定义,以区分切割的数据。