

MongoDB里做表间关联
MongoDB与关系型数据库的建模还是有许多不同,因为MongoDB支持内嵌对象和数组类型。MongoDB建模有两种方式,一种是内嵌(Embed),另一种是连接(Link)。那么何时Embed何时Link呢?那得看两个实体之间的关系是什么类型。
一对一的关系:Embed,比如用户信息集合有Address字段,Address字段有省、市、县三个字段。
在关系型数据库中,通过连接运算符可以实现多个表联合查询。而非关系型数据库的特点是表之间属于弱关联,Mongodb作为Nosql代表,其本身特性不建议对多Collection关联处理,不过对于有些需要对多表关联处理的需求,Mongodb也可以实现。主要分为几种方式:简单手工关联和DBRef方式关联、esProc
1.简单手工关联
下图表示帖子和用户两个Collection的ER图:

首先将authors集合中的用户对象查询出来,放在一个变量author中,代码如下:
> author=db.authors.findOne({name:"chenzhou"})
{
"_id" : ObjectId("5030ba7621bdee44765b2147"),
"name" : "chenzhou",
"email" : "chenzhou1025@126.com"
}
通过用户对象author来获取帖子列表,代码如下:
> for(var post=db.posts.find({"author_name":author.name}); post.hasNext();){
... printjson(post.next().title);
... }
"Hello Mongodb"
"Hello World"
"Hello My Friend"
2.DBRef方式关联
{ $ref : <value>, $id : <value>, $db : <value> }
$ref:集合名称;$id:引用的id;$db:数据库名称,可选参数。
可以看到DBRef的结构比Manual References的复杂,占用的空间大,但是功能也强大,如果要跨数据库连接,上面讲的评论集合的例子,都得需要使用DBRef,MongoDB提供了函数来解析DBRef,不用像Manual References需要自己手动写两次查询。
DBRef就是在两个Collection之间定义的一个关联关系,比如,把CollectionB "_id"列的值存在CollectionA的一个列中,然后通过CollectionA这个列中所存的值在CollectionB中找到相应的记录。
示例:模拟用户发帖的过程,看一看如何将帖子表和用户表建立关联。
步骤1:取得当前用户信息,代码如下:
> author=db.authors.find({name:"chenzhou"})[0]
{
"_id" : ObjectId("5030ba7621bdee44765b2147"),
"name" : "chenzhou",
"email" : "chenzhou1025@126.com"
}
步骤2:发帖子并做关联,代码如下:
> db.posts.insert({"title":"Hello Mongodb DBRef1",
... authors:[new DBRef('authors',author._id)]})
> db.posts.insert({"title":"Hello Mongodb DBRef2",
... authors:[new DBRef('authors',author._id)]})
>
步骤3:通知帖子查找用户信息,代码如下:
> db.posts.find({"title":"Hello Mongodb DBRef1"})[0].authors[0].fetch()
{
"_id" : ObjectId("5030ba7621bdee44765b2147"),
"name" : "chenzhou",
"email" : "chenzhou1025@126.com"
}
通过这个例子可以看出,DBRef就是从文档的一个属性指向另一个文档的指针。
关于DBRef详细信息,可以参见官网说明:http://docs.mongodb.org/manual/applications/database-references/
$lookup
我们来看mongodb另一个非常有意思的东西,那就是$lookup,我们知道mongodb是一个文档型的数据库,而且它也是最像关系型数据库的
一种nosql,但是呢,既然mongodb是无模式的,自然就很难在关系型数据库中非常擅长的多表关联上发挥作用,在这之前,我们可以使用DbRef,但
是呢,在mongodb 3.2 中给你增加了一个相当牛逼的手段,那就是$lookup,而且放到了aggreation这种重量级的pipeline分析框架上,自然就是一等
公民了,牛逼哈~。
$lookup:
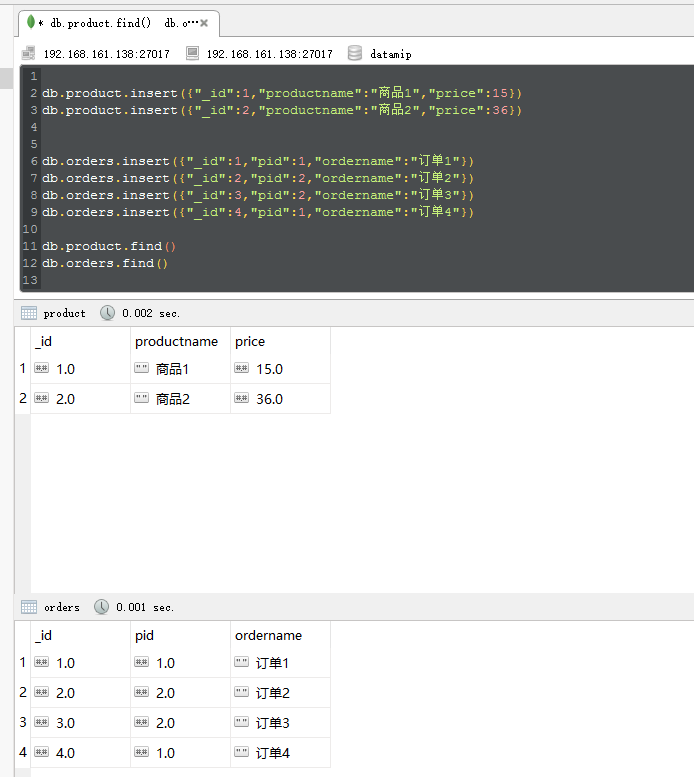
db.product.insert({"_id":1,"productname":"商品1","price":15})
db.product.insert({"_id":2,"productname":"商品2","price":36})
db.orders.insert({"_id":1,"pid":1,"ordername":"订单1"})
db.orders.insert({"_id":2,"pid":2,"ordername":"订单2"})
db.orders.insert({"_id":3,"pid":2,"ordername":"订单3"})
db.orders.insert({"_id":4,"pid":1,"ordername":"订单4"})
db.product.find()
db.orders.find()
语法:
db.product.aggregate([ { $lookup: { from: "orders", localField: "_id", foreignField: "pid", as: "inventory_docs" } } ])
然后展示的结果如下:
1 /* 1 */
2 {
3 "_id" : 1.0,
4 "productname" : "商品1",
5 "price" : 15.0,
6 "inventory_docs" : [
7 {
8 "_id" : 1.0,
9 "pid" : 1.0,
10 "ordername" : "订单1"
11 },
12 {
13 "_id" : 4.0,
14 "pid" : 1.0,
15 "ordername" : "订单4"
16 }
17 ]
18 }
19
20 /* 2 */
21 {
22 "_id" : 2.0,
23 "productname" : "商品2",
24 "price" : 36.0,
25 "inventory_docs" : [
26 {
27 "_id" : 2.0,
28 "pid" : 2.0,
29 "ordername" : "订单2"
30 },
31 {
32 "_id" : 3.0,
33 "pid" : 2.0,
34 "ordername" : "订单3"
35 }
36 ]
37 }

下面我简单介绍一些$lookup中的参数:
from:需要关联的表【orders】
localField: 【product】表需要关联的键。
foreignField:【orders】的matching key。
as: 对应的外键集合的数据,【因为可能是一对多的,对吧】
MongoDB不支持join,其官网上推荐的unity jdbc可以把数据取出来进行二次计算实现join运算,但收费版才有这个功能。其他免费的jdbc drive只能支持最基本的SQL语句,不支持join。如果用Java等编程语言将数据取出后实现join计算,也比较复杂。
3、esProc
用免费的esProc配合MongoDB,可以实现join计算。这里通过一个例子来说明一下具体作法。
MongoDB中的文档orders保存了订单数据,employee保存了员工数据。如下:
MongoDB shell version: 2.6.4
connecting to: test
> db.orders.find();
{ “_id” : ObjectId(“5434f88dd00ab5276493e270″), “ORDERID” : 1, “CLIENT” : “UJRNP
”, “SELLERID” : 17, “AMOUNT” : 392, “ORDERDATE” : “2008/11/2 15:28″ }
{ “_id” : ObjectId(“5434f88dd00ab5276493e271″), “ORDERID” : 2, “CLIENT” : “SJCH”
, “SELLERID” : 6, “AMOUNT” : 4802, “ORDERDATE” : “2008/11/9 15:28″ }
{ “_id” : ObjectId(“5434f88dd00ab5276493e272″), “ORDERID” : 3, “CLIENT” : “UJRNP
”, “SELLERID” : 16, “AMOUNT” : 13500, “ORDERDATE” : “2008/11/5 15:28″ }
{ “_id” : ObjectId(“5434f88dd00ab5276493e273″), “ORDERID” : 4, “CLIENT” : “PWQ”,
”SELLERID” : 9, “AMOUNT” : 26100, “ORDERDATE” : “2008/11/8 15:28″ }
…
> db.employee.find();
{ “_id” : ObjectId(“5437413513bdf2a4048f3480″), “EID” : 1, “NAME” : “Rebecca”, ”
SURNAME” : “Moore”, “GENDER” : “F”, “STATE” : “California”, “BIRTHDAY” : “1974-1
1-20″, “HIREDATE” : “2005-03-11″, “DEPT” : “R&D”, “SALARY” : 7000 }
{ “_id” : ObjectId(“5437413513bdf2a4048f3481″), “EID” : 2, “NAME” : “Ashley”, “S
URNAME” : “Wilson”, “GENDER” : “F”, “STATE” : “New York”, “BIRTHDAY” : “1980-07-
19″, “HIREDATE” : “2008-03-16″, “DEPT” : “Finance”, “SALARY” : 11000 }
{ “_id” : ObjectId(“5437413513bdf2a4048f3482″), “EID” : 3, “NAME” : “Rachel”, “S
URNAME” : “Johnson”, “GENDER” : “F”, “STATE” : “New Mexico”, “BIRTHDAY” : “1970-
12-17″, “HIREDATE” : “2010-12-01″, “DEPT” : “Sales”, “SALARY” : 9000 }
…
Orders中的sellerid对应employee中的eid。需要查询出employee的state属性等于California的所有订单信息。其中orders数据量较大,不能一次装入内存。Employee数据量较小,Orders过滤之后的结果数据量也比较小。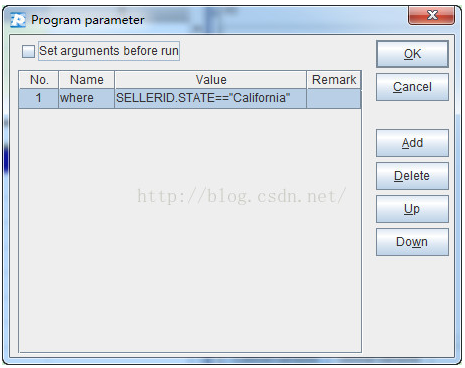
查询条件表达式可以作为参数传递给esProc,如下图:
A1: 连接MongoDB数据库,ip和端口号是localhost:27017,数据库是test,用户名和密码都是test。
A2: 使用find函数从MongoDB中取数,形成游标。集合是orders,过滤条件是空,指定键_id不取出。esProc在find函数中采用了和mongdb的find语句一样的参数格式。esProc的游标支持分批读取和处理数据,可以避免数据量过大,内存出现溢出的情况。
A3: 取得employee中的数据。因为数据量不大,所以用fetch函数一次取出。
A4: 使用switch函数,将游标A2中SELLERID字段的值,转换为A3(employee)中的记录引用。
A5: 按照条件过滤。这里使用宏来实现动态解析表达式,其中的where就是传入参数。集算器将先计算${…}里的表达式,将计算结果作为宏字符串值替换${…}之后解释执行。这个例子中最终执行的是:=A4.select(SELLERID.STATE==”California”)。由于SELLERID已经转化为employee的对应记录的引用,所以可以直接写SELLERID.STATE。过滤之后的结果数据量较小,所以一次取出。如果结果数据量仍然比较大的话,可以分批取出,比如每次取出10000条:fetch(10000)。
A6:将过滤结果中的SELLERID重新切换为普通值。
A6的计算结果是: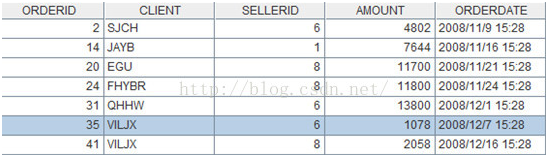
过滤条件发生变化时不用改变程序,只需改变where参数即可。例如,条件变为:state等于California的订单,或者CLIENT等于PWQ的订单。Where的参数值可以写为:CLIENT==”PWQ”|| SELLERID.STATE==”California”。
esProc并不包含MongoDB的java驱动包。用esProc来访问MongoDB,必须提前将MongoDB的java驱动包(esProc要求2.12.2或以上版本的驱动,mongo-java-driver-2.12.2.jar)放到[esProc安装目录]\common\jdbc中。
esProc协助MongoDB计算的脚本很容易集成到java中,只要增加一行A7,写成result A6即可向java输出resultset形式的结果,具体的代码请参考esProc教程。同样,用java调用esProc访问MongoDB也必须将mongdb的java驱动包放到java程序的classpath中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号