

Spring Boot Actutaur + Telegraf + InFluxDB + Grafana 构建监控平台
完成一套精准,漂亮图形化监控系统从这里开始第一步
为啥选择这些组件
- Jolokia: Spring Boot 认可使用Jolokia来通过HTTP导出export JMX数据。你只需要在工程类路径中增加一些依赖项,一切都是开箱即用的。不需要任何额外的实现。
- Telegraf: Telegraf支持通过整合Jolokia来集成JMX数据的收集。它有一个预制的输入插件,它是开箱即用的。不需要任何额外的实现。只需要做一些配置即可。
- InfluxDB: InfluxDB通过 输出插件从Telegraf接收指标数据,它是开箱即用的,不需要任何额外的实现。
- Grafana: Grafana通过连接InfluxDB作为数据源来渲染图标。它是开箱即用的,不需要额外的实现。
Telegraf是收集和报告指标和数据的代理
它是TICK堆栈的一部分,是一个用于收集和报告指标的插件驱动的服务器代理。Telegraf拥有插件或集成功能,可直接从运行的系统获取各种指标,从第三方API获取指标,甚至通过StatsD和Kafka消费者服务来收听指标。它还具有输出插件,可将指标发送到各种其他数据存储,服务和消息队列,包括InfluxDB,Graphite,OpenTSDB,Datadog,Librato,Kafka,MQTT,NSQ等等。
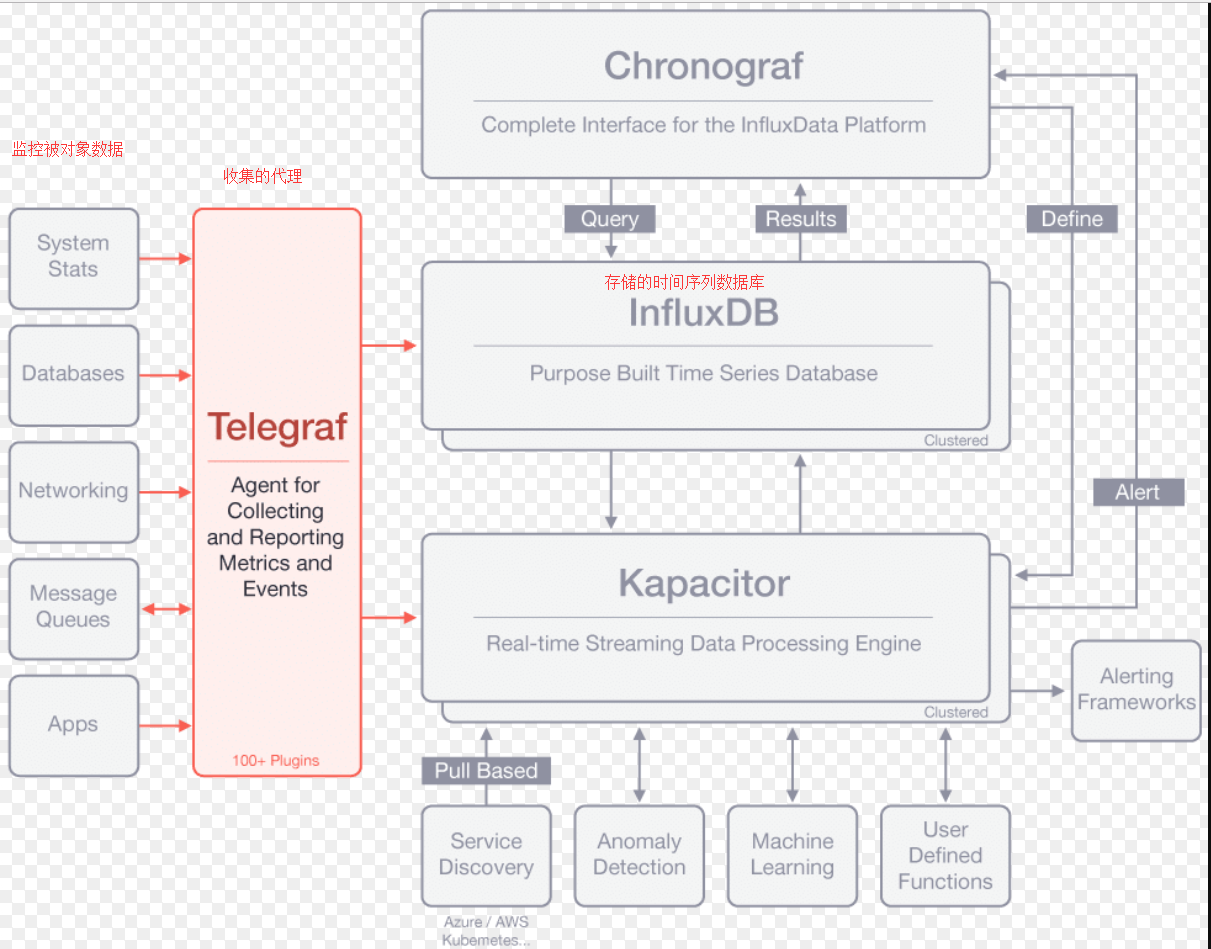
二、搭建监控系统
jolokia把springboot的endpoint暴露出去,telegraf就是采集endpoint收集信息的(比如每隔10s访问一次上面那个URL得到metrics),收集到的数据存到InfluxDB,然后Grafana连接InfluxDB,读取数据可视化展示。
2.1、jolokia
Jolokia作为目前最主流的JMX监控组件,spring社区(springboot、MVC、cloud)以及目前主流的中间件服务均采用它作为JMX监控,简单来说,jolokia可以帮助我们解决:
1)JMX可以实现VM内部运行时数据状态的对外export,我们通过将运行态数据封装成MBean,通过JMX Server统一管理,并允许外部程序通过RMI方式获取数据。总之,JMX允许运行态数据通过RMI协议被外部程序获取。这对我们监控、操作VM内部数据提供窗口。
2)JMX扩展性、可实施能力非常强大,但是其问题就是如果获取MBean数据,需要使用JAVA栈的RMI协议,这对外部程序比如监控组件(非JAVA栈)支持不够良好。
3)jolokia完全兼容并支撑JMX组件,它可以作为agent嵌入到任何JAVA程序中,特别是WEB应用,它将复杂而且难以理解的MBean Filter查询语句,转换成更易于实施和操作的HTTP 请求范式,不仅屏蔽了RMI的开发困难问题,还实现了对外部监控组件的透明度,而且更易于测试和使用。
4)直观来说,jolokia就是用于解决JMX数据获取时,所遇到的RMI协议复杂性、Mbean查询的不便捷、数据库序列化、MBeanServer的托管等问题;我们只需要使用HTTP请求,直接访问与WEB服务相同的port即可获取JMX数据。
Jolokia是一个JMX-HTTP桥梁,它提供了访问JMX bean的HTTP访问方法。例如,我要被监控服务是spring-boot的项目,为其gradle配置文件添加jolokia(主要就是为了把JMX的mbean通过HTTP暴露出去)
gradle.build
compile 'org.jolokia:jolokia-core'
然后在springboot的配置文件application.yml配置如下:

endpoints:
enabled: true #打开endpoint
jmx:
enabled: true #打开endpoint
jolokia:
enabled: true #打开endpoint
management:
security:
enabled: false #关闭
访问一下URL:
http://localhost:8080/jolokia/read/org.springframework.boot:name=metricsEndpoint,type=Endpoint/Data
看看是不是有返回,如下:

如果能看到数据,说明server端配置没问题了。
2.2、telegraf采集数据
如上面所说,Telegraf实际就是收集信息的,比如每隔10s访问一次上面那个URL得到metrics,收集到的数据写入到InfluxDB。
配置方面,主要是要修改Telegraf的,因为它是对接不同项目的,你需要收集什么样的信息,比如cpu,disk,net等等都要在Telegraf里配。简单起见,我只设置了三个输入。
# /etc/telegraf/telegraf.conf [[inputs.jolokia]] context = "/jolokia" [[inputs.jolokia.servers]] name = "springbootapp" host = "{app ip address}" port = "8080" [[inputs.jolokia.metrics]] name = "metrics" mbean = "org.springframework.boot:name=metricsEndpoint,type=Endpoint" attribute = "Data" [[inputs.jolokia.metrics]] name = "tomcat_max_threads" mbean = "Tomcat:name=\"http-nio-8080\",type=ThreadPool" attribute = "maxThreads" [[inputs.jolokia.metrics]] name = "tomcat_current_threads_busy" mbean = "Tomcat:name=\"http-nio-8080\",type=ThreadPool" attribute = "currentThreadsBusy"
其实就是spring-boot标准的metrics以及tomcat的Threads。
再配置telegraf的输出,还是配置/etc/telegraf/telegraf.conf文件,只是配置的是OUTPUTS部分:
# The target database for metrics (telegraf will create it if not exists) database = "telegraf" # required # Precision of writes, valid values are "ns", "us" (or "µs"), "ms", "s", "m", "h". # note: using second precision greatly helps InfluxDB compression precision = "s" ## Write timeout (for the InfluxDB client), formatted as a string. ## If not provided, will default to 5s. 0s means no timeout (not recommended). timeout = "5s" username = "telegraf" password = "password"
完成之后重启服务/etc/init.d/telegraf restart。
查看采集数据
我们访问InfluxDB看看有数据了没有http://localhost:3004/,切换数据库到Telegraf。输入以下命令试试吧
SHOW MEASUREMENTS
SELECT * FROM jolokia
SELECT * FROM cpu
SELECT * FROM mem
SELECT * FROM diskio比如输入SELECT * FROM jolokia就能看到spring-boot暴露了哪些数据,从time列也可以看出Telegraf是每隔10s收集一次,太频繁了对server也是压力。
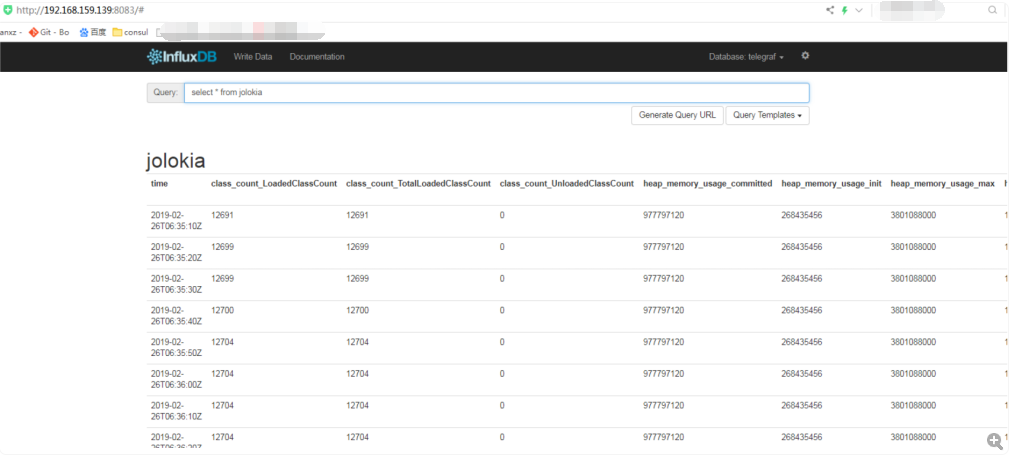
上面基本涵盖了cpu,内存和存储的一些metrics。
其实也可以配置网络相关的,感兴趣的可以看官方的telegraf.conf,里面有配置[[inputs.net]]的例子。
2.3、grafana数据可视化
在grafana中配置influxDB的数据源,再添加对应的dashboard展示。
添加好InfluxDB后,新建一个Dashboard,然后快速的ADD几个Graph来。
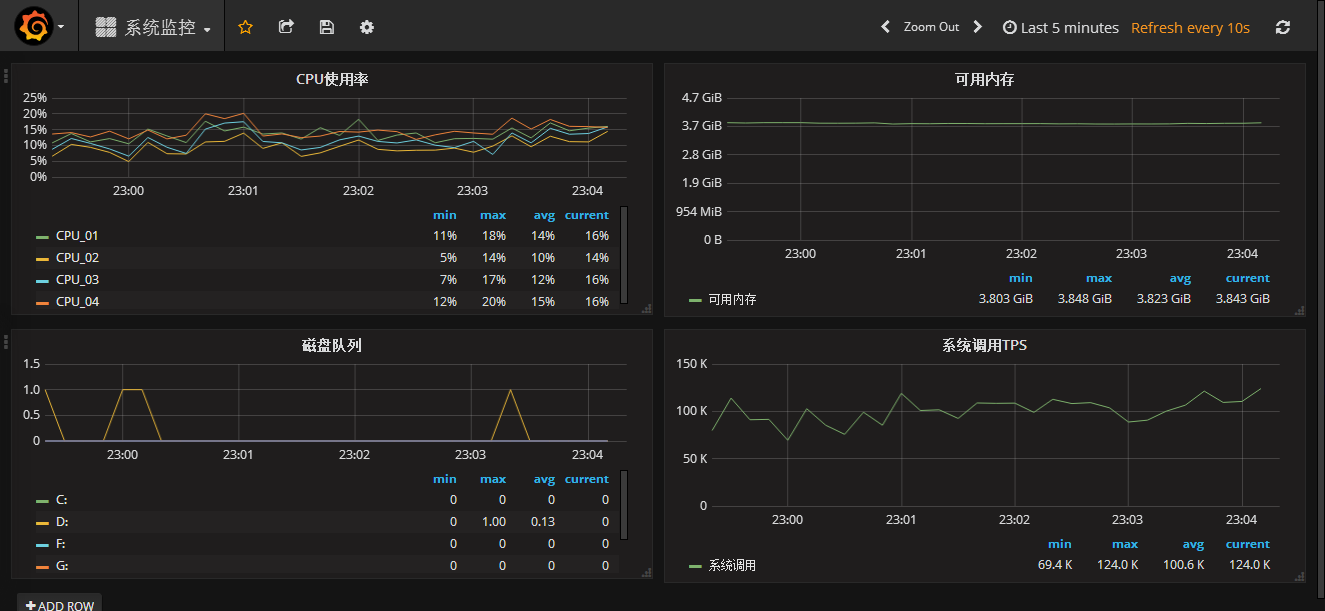
为了演示,我添加了三个,分别使用下面三组查询语句来渲染出三张图表
SELECT MEAN(usage_system) + MEAN(usage_user) AS cpu_total FROM cpu WHERE $timeFilter GROUP BY time($interval)
SELECT mean("total") as "total" FROM "mem" WHERE $timeFilter GROUP BY time($interval) fill(null)
SELECT mean("used") as "used" FROM "mem" WHERE $timeFilter GROUP BY time($interval) fill(null)
SELECT mean("metrics_heap.used") as "heap_usage" FROM "jolokia" WHERE $timeFilter GROUP BY time($interval) fill(null)
第一张是CPU占用率;第二张是内存占用情况,绿线是Total,黄线是Used;第三张是jolokia提供的jvm heap的使用,可以到看到GC的情况。
刚才还配置了Tomcat的收集,想看Tomcat的Thread情况也是妥妥的。
SELECT mean("tomcat_max_threads") FROM "jolokia" WHERE $timeFilter GROUP BY time($interval) fill(null)
SELECT mean("tomcat_current_threads_busy") FROM "jolokia" WHERE $timeFilter GROUP BY time($interval) fill(null)
可以看到搭建这样一套环境其实很快,原理也并不复杂,监控数据可视化的难点在于
- 哪些metrics需要监控
- 哪些metrics需要配合起来可以判断问题,比如diskio+net是不是可以判断系统整体IO的瓶颈。
三、环境搭建
3.1、下载Telegraf、influxdb 、grafana
influxDB的安装
wget https://dl.influxdata.com/influxdb/releases/influxdb-0.13.0.x86_64.rpm sudo yum localinstall influxdb-0.13.0.x86_64.rpm sudo service influxdb start
grafana的安装
wget https://dl.grafana.com/oss/release/grafana-5.4.3-1.x86_64.rpm sudo yum localinstall grafana-5.4.3-1.x86_64.rpm systemctl start grafana-server
Telegraf的安装
wget https://dl.influxdata.com/telegraf/releases/telegraf-1.7.4-1.x86_64.rpm sudo yum localinstall telegraf-1.7.4-1.x86_64.rpm
systemctl start telegraf
安装完成后,开始配置:
3.2.创建 Influxdb 用户和数据库
[root@localhost apm]# influx Visit https://enterprise.influxdata.com to register for updates, InfluxDB server management, and monitoring. Connected to http://localhost:8086 version 0.13.0 InfluxDB shell version: 0.13.0 > create user "telegraf" with password 'password' > show users; user admin telegraf false > create database telegraf > show databases name: databases --------------- name _internal telegraf > exit
3.3.配置Telegraf
[root@localhost apm]# vim /etc/telegraf/telegraf.conf ## 修改内容如下: [[outputs.influxdb]] urls = ["http://localhost:8086"] # required database = "telegraf" # required retention_policy = "" precision = "s" timeout = "5s" username = "telegraf" password = "password" [root@localhost apm]# systemctl restart telegraf
3.4、grafana配置telegraf,打开grafana的控制台:http://ip:3000
从左边的设置菜单栏找到数据源配置项,添加上面的库信息,结果如下:
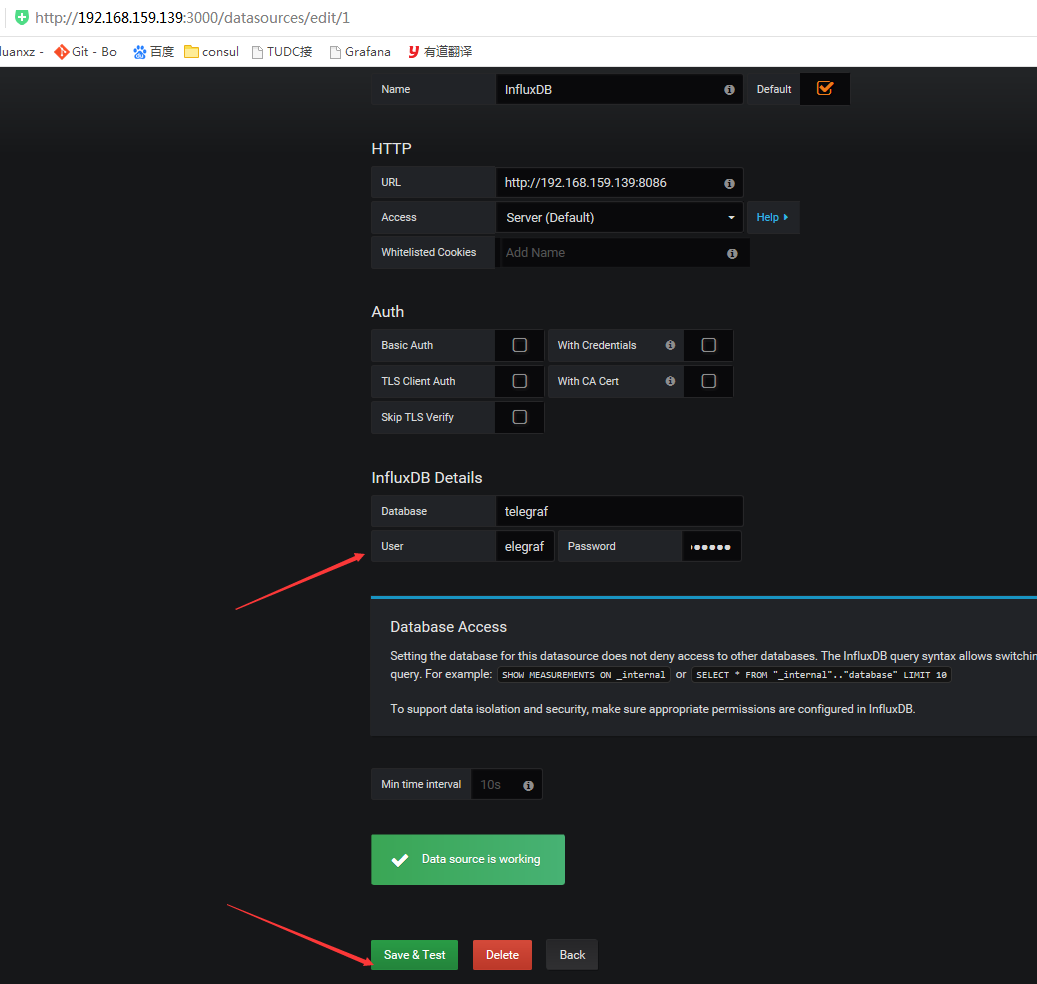
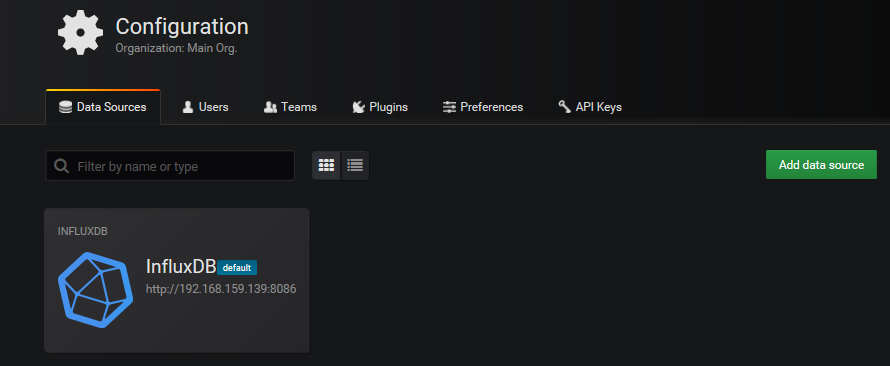
3.5.点击new创建一个Dashboards
创建仪表盘。我们可以通过访问https://grafana.com/dashboards来查看已经由其他用户共享的仪表盘,选取合适的使用,缩短上手时间。在这里,作者选取的是https://grafana.com/dashboards/1443这个仪表盘,该仪表盘内已经基本涵盖一个系统需要监控的相关参数。
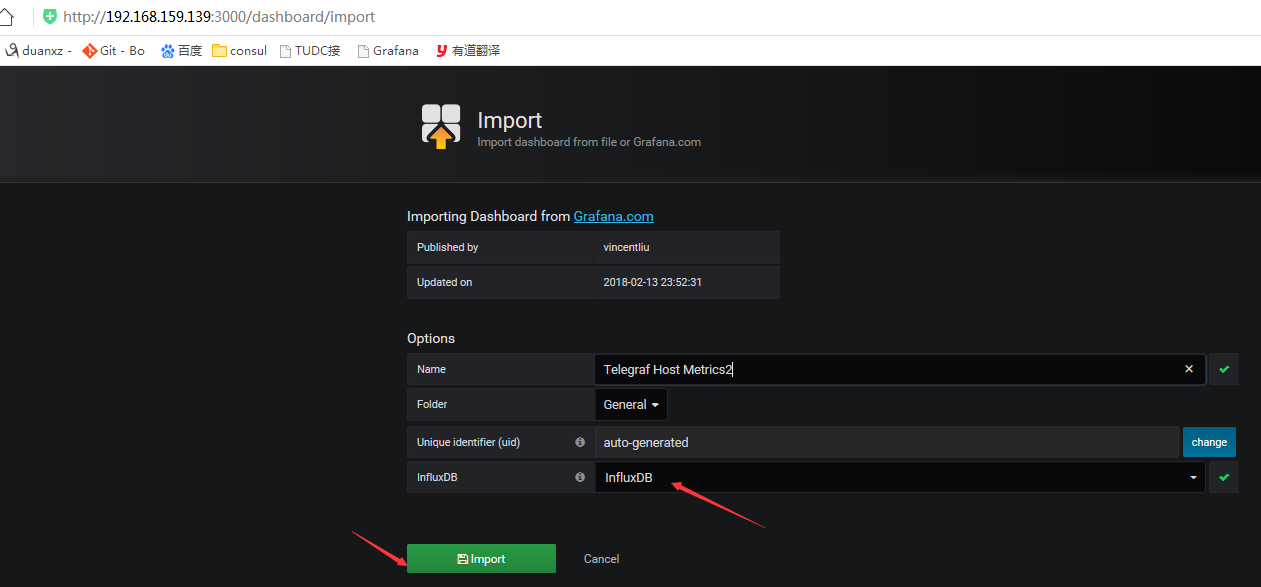
看结果:
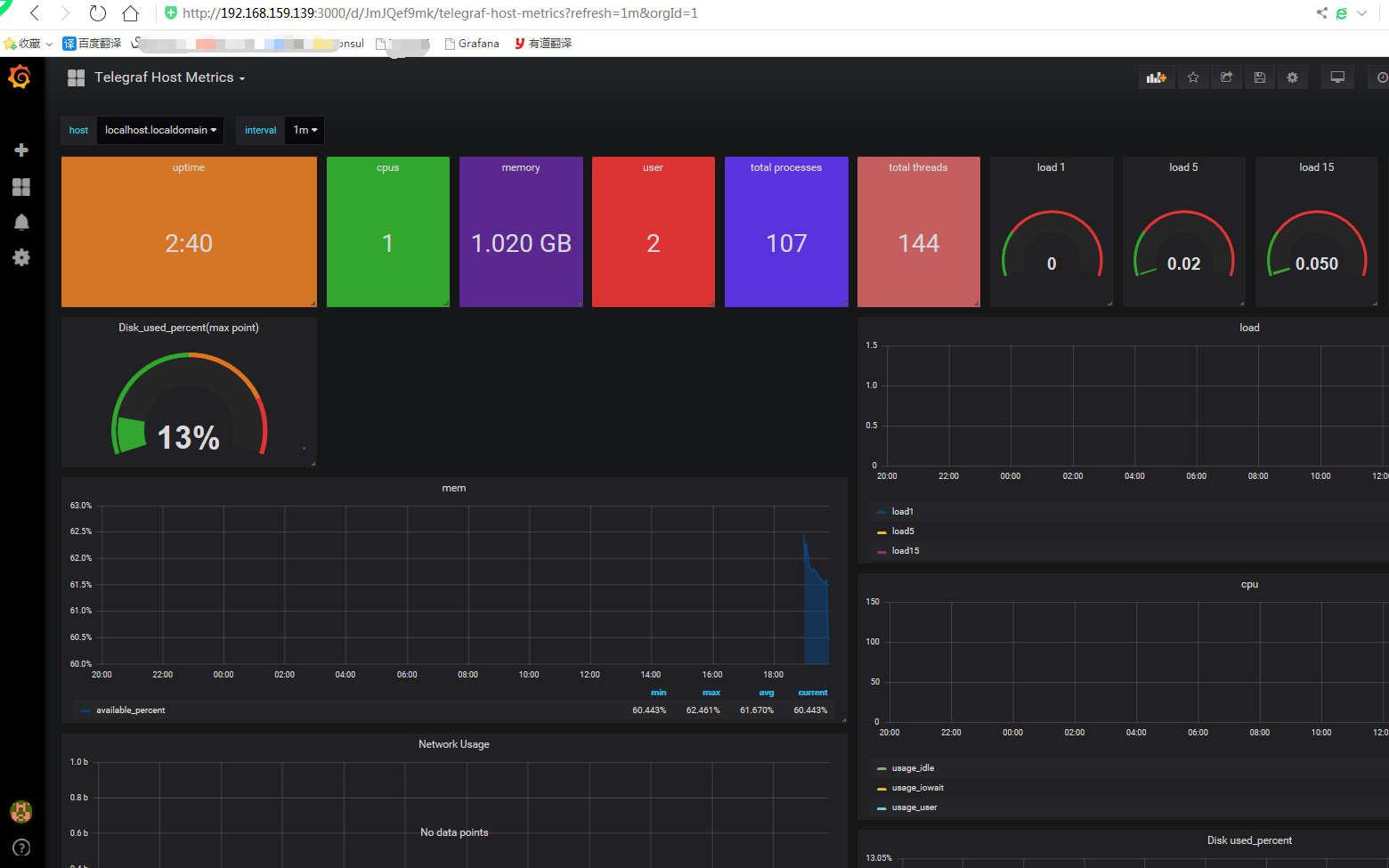
点击metrics,配置收集到的收据信息,实际就是写sql查询,不同数据库数据sql书写方式不同
查看http://localhost:8083,可以发现telegraf库中,默认有4个Measurements(表):
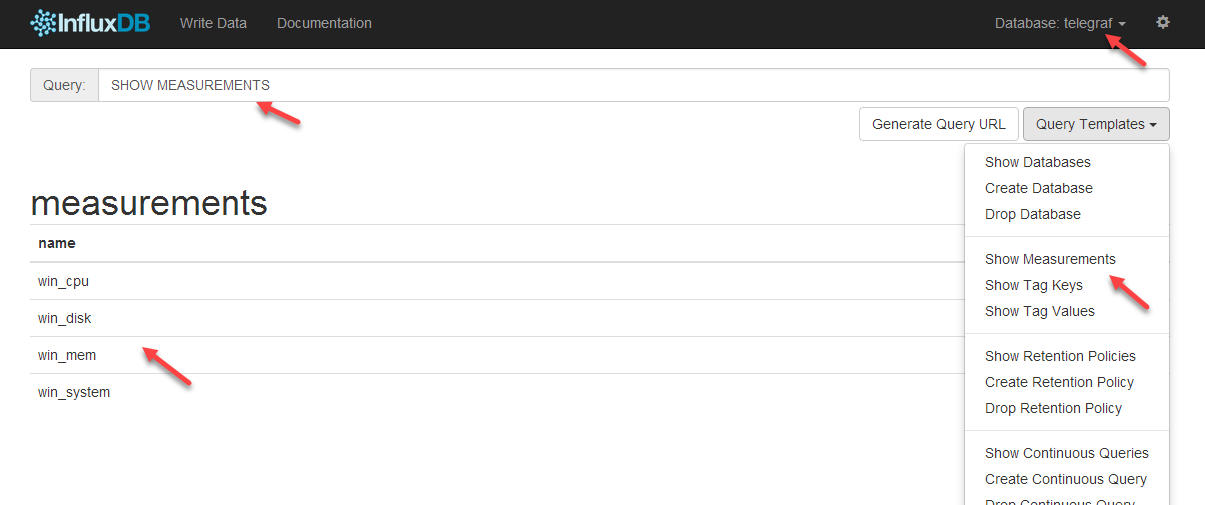
配置Grafana中的面板完成后,这样一个简易的本机监控系统就搭建完了:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
2016-02-25 spring AOP 之四:@AspectJ切入点标识符语法详解
2016-02-25 IP地址漂移的实现与原理
2016-02-25 高可用集群heartbeat全攻略
2016-02-25 http请求的referer属性
2016-02-25 HTTP协议详解
2014-02-25 linux参数之max_map_count
2014-02-25 declare handler 声明异常处理的语法