


在Docker中监控Java应用程序的5个方法
译者注:Docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化。通常情况下,监控的主要目的在于:减少宕机时间、扩展和性能管理、资源计划、识别异常事件和故障排除分析等。本文作者介绍了5种方法帮助你在Docker中监控Java应用程序。
你知道有什么好的方法可以在Docker容器中监控Java应用程序吗?
在容器中运行应用程序是一种日益流行的维护大型分布式栈的方法,这种栈基于需求而变化。对于基于容器的架构来说,Java虚拟机是一种理想的编程语言。由于存在很多活动的部件和组成元素,在容器中监控Java应用程序时,需要提前计划和选择正确的工具,从而有效地监控对你有用的地方。
在一个监控堆栈中需要考虑5个部分的因素。首先,我会简要介绍前面两个部分,并且指出覆盖到这两部分的有用的资源,然后我将着重讲解后面三部分。
生成有用的日志
当然,Java会生成自己的应用程序日志,但是通常需要额外的工具去增加这些日志的可读性和可用性,其中包括公认的、大型的工具,例如Splunk and the Elastic stack,或小型的(但性能相当)工具,例如Sumo Logic, Graylog, Loggly, PaperTrail, Logentries and Stackify。
需要考虑的主要因素是你正在使用或计划与Docker集成的日志管理工具的性能如何。通常,与Docker集成会成为安装过程中另一个基本步骤,不需要绕什么弯路。
存在的缺陷就是,生成的日志只会和你选择的信息一样好,而其他的工具就可以填补这些空缺。
性能监控
应用程序性能监控(APM)工具可以识别代码或基础设施中的性能瓶颈,让你知道有哪些地方需要进一步提升。这是一个繁忙的空间,常用的工具有AppDynamics,Dynatrace,New Relic和一些开源工具。
和日志管理工具一样,从Docker的角度出发需要考虑的主要问题是集成工作的性能怎样。Docker容器已经成熟到足以成为APM安装过程中的一个步骤。
错误追踪
应用程序会生成错误,但是利用现有的复杂的interwoven和分布式代码基通常难以直接定位错误来源。错误追踪工具可以通过监控生产中的应用程序帮你解决这个难题。
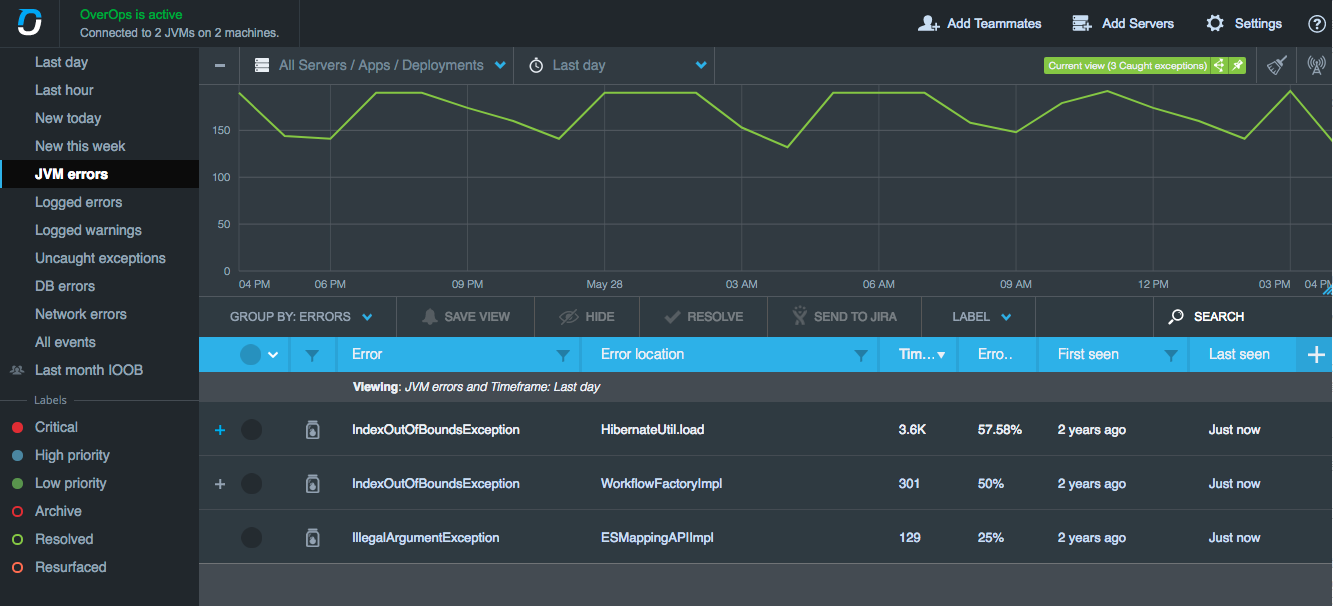
其中有一款叫做OverOps的工具脱颖而出,这是一款完全专注于基于JVM(Java虚拟机)应用程序的工具,是一款高度优化的本地代理,使用过程中最多增加1%的CPU开销,几乎不存在网络或存储开销。这对于内存空间和性能要求较高的基于容器的JVM来说是一个理想的选择。
你可以看到实时异常,并记录错误或警告,然后过滤出特定的错误,例如与JVM、数据库或网络有关的错误。
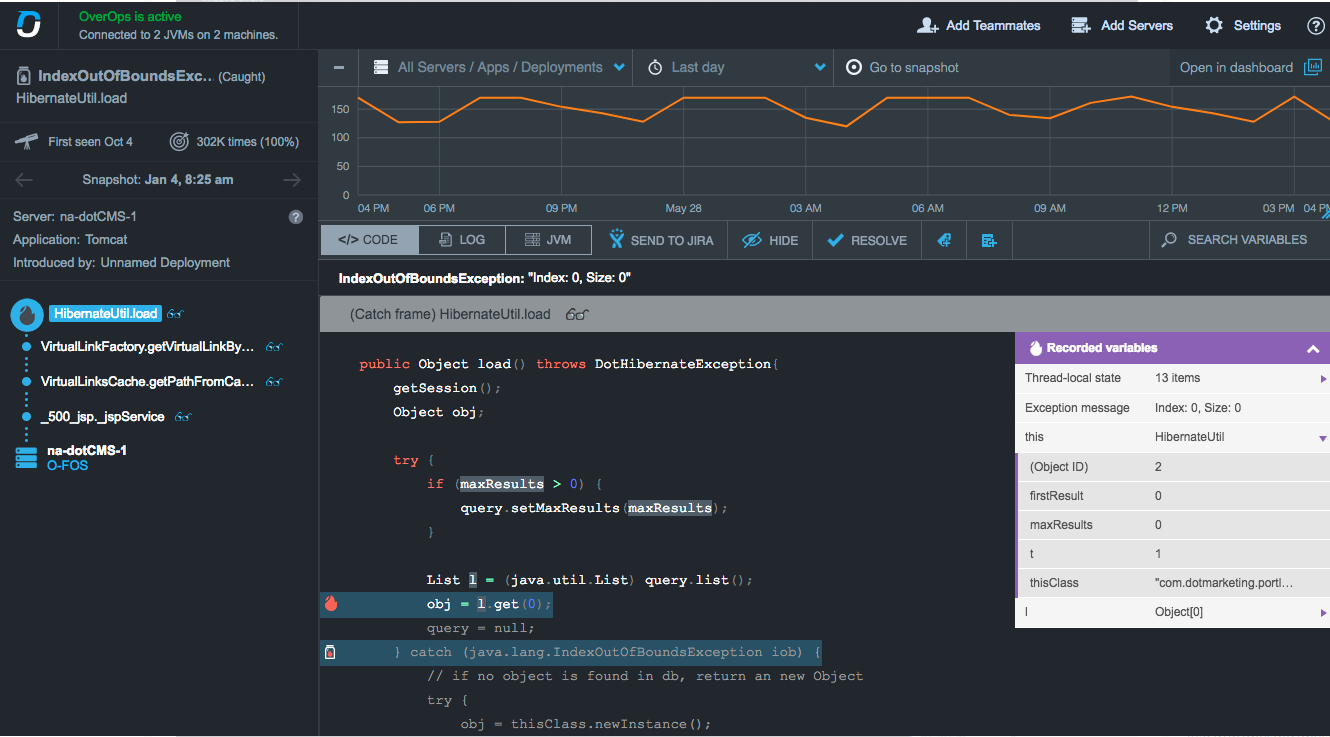
如果你发现一些错误需要进一步了解细节,你可以点进去,里面会显示整个调用堆栈内引发错误的代码和错误发生时具体的变量状态。
OverOps有一个专门为容器设计的版本,你可以通过在Dockerfile中添加少量的代码来访问和使用,其中包括Debian /Ubuntu、CentOS / RedHat和Alpine Linux。
一般来说,容器通常在持续变化的应用环境中使用,会定期介绍新代码,OverOps可以快速识别新增的错误并深入分析其原因。如果你的应用程序是在一个容器集群上运行,那么设置过程也是一样的,OverOps也可以监测并整合所有的错误。
容器测量指标
容器本质上是小型的、独立的机器,所以,例如CPU和内存使用率等指标对于跟踪高级应用程序问题来说至关重要。接下来我将重点介绍基于Docker的容器,也会稍微提一下这个工具是否支持其他选项。
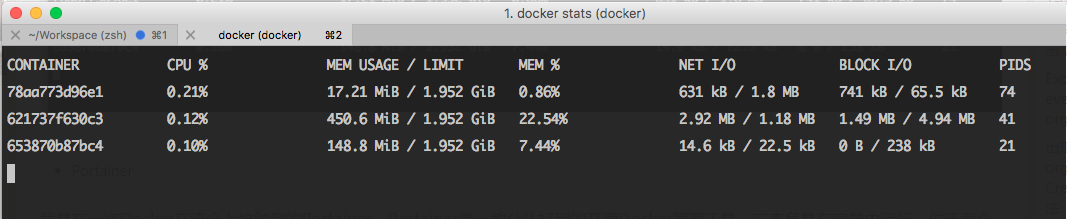
Docker Stats
首先,我说一下Docker自带的API接口,因为很多其他的工具是基于这个接口提供的数据,然后添加来自其他地方的信息。一个简单的docker stats命令可以让你一览容器的CPU、内存和I/O使用情况,其他API端点可以提供任务、日志、时间等等指标的具体情况。
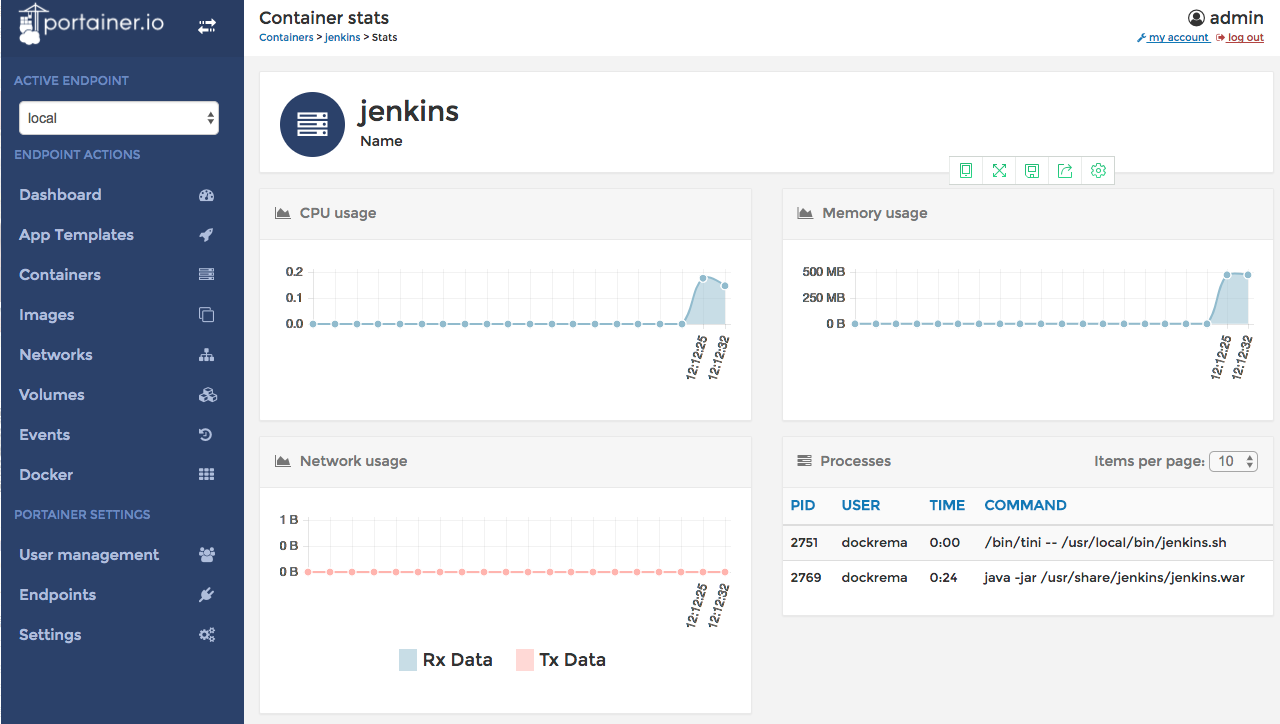
Portainer
我是在一次Docker交流会上接触到的Portainer,Portainer是一款公认好用的开源Docker管理工具,它本身是在容器内运行,位于两个无害的链接后面,这两个链接分别在应用程序的两个容器上。Portainer可以提供界面友好的可视化统计数据和日志明细,应该可以满足你的要求,另一个吸引人的地方就是这个项目简单易行并且成本低廉。
Datadog
Datadog主要用于为整个堆栈提供详细的测量指标,您可以将所有被监控的点排列成定制的仪表板,以满足你的需要,并根据问题和严重性触发适当的通知,当它标记一个潜在问题时,会有内置到Datadog的通信工具来进行注释和讨论,并且重点突出任何可能衍生的问题,帮你做到提前预防。
如果有一些数据是你的应用程序想要监控但是Datadog却缺乏正式集成的,你可以使用它们的全访问API去获取数据,然后把它们输入到相同的仪表板、警报和协同工具中。
对于在容器中运行的JVM应用程序来说,有几个组件反映了Datadog函数的粒度。你可以为你的主机操作系统添加一个代理,然后,监控独立容器性能和监控容器性能的Docker集成与它们正在运行的应用程序会关联起来。安装过程有可能很复杂,这取决于你的主机/Docker配置,由于Datadog想要监控主机、容器引擎和应用程序的性能,所以,将呈现出一个完整的画面。
比如,如下图所示,Docker运行在我的Mac上几个对于Datadog来说非常重要的层:
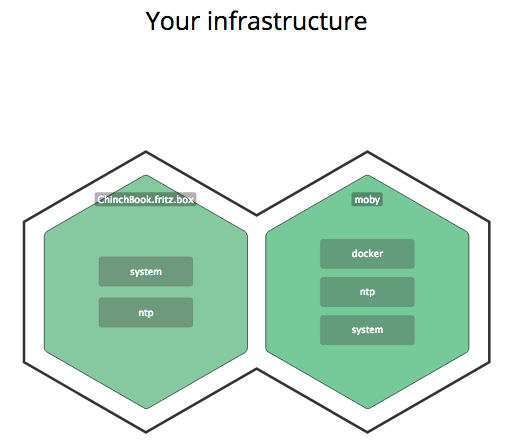
为了监控容器的内部情况,你通过把每一个代理加入到Dockerfile中,然后运行各个容器内部的代理。如果是监控应用程序的话,使用Java/JMX集成,你可以监控到任何你想监控的数据。
如果这些还不能满足你,Datadog还可以让你通过statsD发送测量指标,它们会提供一个Java库帮你完成。
SignalFX
虽然可以配置好文中提到的所有服务并与微服务友好协作,但这对于SignalFX来说却是主要关注点之一。SignalFX服务是基于开源collected统计守护进程的,统计守护进程提供了一个现成的生态系统和社区,意味着你可以把collected插件添加到SignalFX默认模式时无法访问的collect数据中。
对于Docker容器,SignalFX将使用stats API来监控数据从而显示CPU、内存和硬盘使用情况。一个仪表板将首先向你提供跨所有容器的指标的聚合视图,并让你深入到每个docker主机和容器中查看性能问题所在。
我喜欢SignalFX的一个特性是在系统级别上安装代理,因此更简单。比如,如果你想在Ubuntu和Debian上安装一个Java插件(其他分布是一个包括两个步骤的过程),你只需要通过JMX技术安装SignalFx的主collectd代理,它包括Java支持和其他代理,你可以在Java应用程序中为来自SignalFX的库添加自定义集合点。
Wavefront
Wavefront和本文中的其他方法不一样,它不是提供特定的日志解决方案,而是从其他日志服务(包括collectd、statsd和JMX)收集时间序列数据。
对于Docker容器,Wavefront有cAdvisor,cAdvisor是一个类似容器的轻量级代理,它用来监控CPU、内存和硬盘等底层资源利用率。如果你正在使用ECS、Kubernetes、Mesos或Docker Swarm等容器服务,那么Wavefront可以提供打包集成选项,这个选项在默认情况下可以提供跨集群的聚合指标。
Orchestration
随着容器架构越来越复杂,需求日益变化,你应该需要使用到orchestration工具去构建和管理你的应用程序,同时保持容器和机器问题的一致性。在这个空间里有几个主要的玩家,它们都提供了一个监控测量指标的解决方案,因为测量指标是一个非常关键的组件。
Prometheus
Prometheus是一个云本地计算基础项目,它是一个系统和服务的监控系统,当条件为真时,它会触发警报。这是现在很流行的一款开源工具,所以,你需要花费一定的时间对它进行配置以满足自己的需求。如果你使用Mesos或Kubernetes去管理和安排你的容器,那么对于很多用这些工具的人来说,Prometheus会是一个优先选择。
Kubernetes Dashboard
覆盖Kubernetes集群的选项本身就是另一篇文章,但值得一提的是默认的Kubernetes仪表板选项,以免你用Kubernetes去管理你的容器,它为每个’pod’、日志和作业查看器提供了资源使用的整体情况。
Mesos Metrics
如果你在用Mesos管理你的容器,同样,它也有自己内置的选项去监控它运行的容器。虽然不像Kubernetes仪表板那样可视性强,但是它可以提供一系列的端点,你需要自己去实现,或者使用一种工具将这些数据可视化。
结语
容器是小型的、独立的机器,通常,它的监控能力和一个“正常的”物理机或虚拟机差不多,主要的区别在于你的应用程序中容器数量的多少,并且它们的生存周期很短,容器不适用于长期运行的服务。组装好监控堆栈之后,确保你选择的解决方案使实例的数量容易变化,并且度量标准提供了对你的应用程序的一致概述。

