


高性能线程间队列 DISRUPTOR 简介
disruptor简介
背景
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题。与Kafka(Apache Kafka)、RabbitMQ(RabbitMQ)用于服务间的消息队列不同,disruptor一般用于线程间消息的传递。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。2011年,企业应用软件专家Martin Fowler专门撰写长文介绍The LMAX Architecture。同年它还获得了Oracle官方的Duke大奖。其他关于disruptor的背景就不在此多言,可以自己google。
官方资料
disruptor github wiki有关于disruptor相关概念和原理的介绍,该wiki已经很久没有更新。像Design and Implementation,对于想了解disruptor的人是很有吸引力的,但是只有题目没有内容,还是很遗憾的。本文稍后会对其内部原理做一个介绍性的描述。
disruptor github wiki:
Home · LMAX-Exchange/disruptor Wiki
disruptor github:
LMAX-Exchange/disruptor: High Performance Inter-Thread Messaging Library
这个地方也有很多不错的资料:Disruptor by LMAX-Exchange
性能
disruptor是用于一个JVM中多个线程之间的消息队列,作用与ArrayBlockingQueue有相似之处,但是disruptor从功能、性能都远好于ArrayBlockingQueue,当多个线程之间传递大量数据或对性能要求较高时,可以考虑使用disruptor作为ArrayBlockingQueue的替代者。
官方也对disruptor和ArrayBlockingQueue的性能在不同的应用场景下做了对比,本文列出其中一组数据,数据中P代表producer,C代表consumer,ABS代表ArrayBlockingQueue:
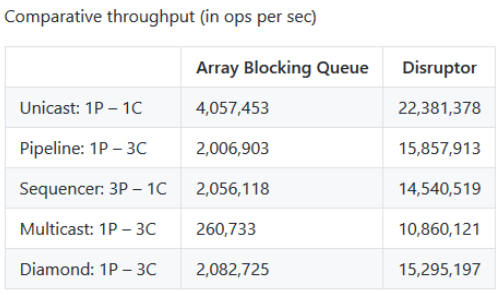
完整的官方性能测试数据在Performance Results · LMAX-Exchange/disruptor Wiki可以看到,性能测试的代码已经包含在disruptor的代码中,你完全可以git下来在自己的主机上测试一下看看
如何使用
单生产者,单消费者
//声明disruptor中事件类型及对应的事件工厂 private class LongEvent { private long value; public LongEvent() { this.value = 0L; } public void set(long value) { this.value = value; } public long get() { return this.value; } } private EventFactory<LongEvent> eventFactory = new EventFactory<LongEvent>() { public LongEvent newInstance() { return new LongEvent(); } }; //声明disruptor, private int ringBufferSize = 1024; private Executor executor = Executors.newFixedThreadPool(8); private Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(eventFactory, ringBufferSize, executor); //pubisher逻辑,将原始数据转换为event,publish到ringbuffer private class Publisher implements EventTranslatorOneArg<LongEvent , String> { public void translateTo(LongEvent event, long sequence, String arg0) { event.set(Long.parseLong(arg0)); } } //consumer逻辑,获取event进行处理 private class Consumer implements EventHandler<LongEvent> { public void onEvent(LongEvent event, long sequence, boolean endOfBatch) throws Exception { long value = event.get(); int index = (int) (value % Const.NUM_OF_FILE); fileWriter[index].write("" + value + "\n"); if(value == Long.MAX_VALUE) { isFinish = true; } } } //注册consumer启动disruptor disruptor.handleEventsWith(new Consumer()); disruptor.start(); //获取disruptor的ringbuffer,用于生产数据 private RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer(); ringBuffer.publishEvent(new Publisher(), line);
多生产者
多生产者的改动相对简单,只需将disruptor的声明换一个构造函数即可,但是多生产者ringbuffer的处理逻辑完全不同,只是这些不同对使用者透明,本文将在后边讨论单生产者,多生产者ringbuffer逻辑的不同
private Disruptor<LongEvent> disruptor1 = new Disruptor<LongEvent>(eventFactory, ringBufferSize, executor, ProducerType.MULTI, new BlockingWaitStrategy());
多消费者
多消费者的情况分为两类:
- 广播:对于多个消费者,每条信息会达到所有的消费者,被多次处理,一般每个消费者业务逻辑不通,用于同一个消息的不同业务逻辑处理
- 分组:对于同一组内的多个消费者,每条信息只会被组内一个消费者处理,每个消费者业务逻辑一般相同,用于多消费者并发处理一组消息
广播
- 消费者之间无依赖关系
假设目前有handler1,handler2,handler3三个消费者处理一批消息,每个消息都要被三个消费者处理到,三个消费者无依赖关系,则如下所示即可
disruptor.handleEventsWith(handler1,handler2,handler3);
- 消费者之间有依赖关系
假设handler3必须在handler1,handler2处理完成后进行处理
disruptor.handleEventsWith(handler1,handler2).then(handler3);
其他情况可视为以上两种情况的排列组合
分组
分组情况稍微不同,对于消费者,需要实现WorkHandler而不是EventHandler,借口定义分别如下所示:
public interface EventHandler<T> { /** * Called when a publisher has published an event to the {@link RingBuffer} * * @param event published to the {@link RingBuffer} * @param sequence of the event being processed * @param endOfBatch flag to indicate if this is the last event in a batch from the {@link RingBuffer} * @throws Exception if the EventHandler would like the exception handled further up the chain. */ void onEvent(T event, long sequence, boolean endOfBatch) throws Exception; }
public interface WorkHandler<T> { /** * Callback to indicate a unit of work needs to be processed. * * @param event published to the {@link RingBuffer} * @throws Exception if the {@link WorkHandler} would like the exception handled further up the chain. */ void onEvent(T event) throws Exception; }
假设handler1,handler2,handler3都实现了WorkHandler,则调用以下代码就可以实现分组
disruptor.handleEventsWithWorkerPool(handler1, handler2, handler3);
广播和分组之间也是可以排列组合的
tips
disruptor也提供了函数让你自定义消费者之间的关系,如
public EventHandlerGroup<T> handleEventsWith(final EventProcessor… processors)
当然,必须对disruptor有足够的了解才能正确的在EventProcessor中实现多消费者正确的逻辑
实现原理
为何高效
事件预分配
在定义disruptor的时候我们需要指定事件工厂EventFactory的逻辑,disruptor内部的ringbuffer的数据结构是数组,EventFactory就用于disruptor初始化时数组每个元素的填充。生产者开始后,是通过获取对应位置的Event,调用Event的setter函数更新Event达到生产数据的目的的。为什么这样?假设使用LinkedList,在生产消费的场景下生产者会产生大量的新节点,新节点被消费后又需要被回收,频繁的生产消费给GC带来很大的压力。使用数组后,在内存中存在的是一块大小稳定的内存,频繁的生产消费对GC并没有什么影响,大大减小了系统的最慢响应时间,更不会因为消费者的滞后导致OOM的发生。因此这种事件预分配的方法对于减轻GC压力可以说是一种简单有效的方法,日常工作中的借鉴意义还是很大的。
无锁算法
先看一段ABQ put算法的实现:
- 每个对象一个锁,首先加锁
- 如果数组是满的,加入锁的notFull条件等待队列。(notFull的具体机制可以看这里的一篇文章wait、notify与Condition | forever)
- 元素加入数组
- 释放锁
public void put(E e) throws InterruptedException { checkNotNull(e); final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == items.length) notFull.await(); enqueue(e); } finally { lock.unlock(); } }
通过以上代码说明两点:
- ABQ是通过lock机制实现的线程同步
- ABQ的所有操作共用同一个lock,故所有操作均是互斥的
这篇文章中讲述了一个实验, 测试程序调用了一个函数,该函数会对一个64位的计数器循环自增5亿次,在2.4G 6核机器上得到了如下的实验数据:
| METHOD | TIME (MS) |
|---|---|
| Single thread | 300 |
| Single thread with CAS | 5,700 |
| Single thread with lock | 10,000 |
| Single thread with volatile write | 4,700 |
| Two threads with CAS | 30,000 |
| Two threads with lock | 224,000 |
实验数据说明,使用CAS机制比使用lock机制快了一个数量级
另一方面,ABQ的所有操作都是互斥的,这点其实不是必要的,尤其像put和get操作,没必要共享一个lock,完全可以降低锁的粒度提高性能。
disruptor则与之不同:
disruptor使用了CAS机制同步线程,线程同步代价小于lock
disruptor遵守single writer原则,一块内存对应单个线程,不仅produce和consume不是互斥的,多线程的produce也不是互斥的
伪共享
伪共享一直是一个比较高级的话题,Doug lea在JDK的Concurrent使用了大量的缓存行机制避免伪共享,disruptor也是用了这样的机制。但是对于广大的码农而言,实际工作中我们可能很少会需要使用这样的机制。毕竟对于大部分人而言,与避免伪共享带来的性能提升而言,优化工程架构,算法,io等可能会给我们带来更大的性能提升。所以本文只简单提到这个话题,并不深入讲解,毕竟我也没有实际的应用经验去讲解这个话题。
单生产者模式
如图所示,图中数组代表ringbuffer,红色元素代表已经发布过的事件槽,绿色元素代表将要发布的事件槽,白色元素代表尚未利用的事件槽。disruptor生产时间包括三个阶段:申请事件槽,更新数据,发布事件槽。单生产者相对简单,
- 申请事件槽:此时,ringbuffer会将cursor后的一个事件槽返回给用户,但不更新cursor,所以对于消费者而言,该事件还是不可见的。
- 更新数据:生产者对该事件槽数据进行更新,
- 发布事件槽:发布的过程就是移动cursor的过程,完成移动cursor后,发布完成,该事件对生产者可见。
")
多生产者模式
多生产者的模式相对就比较复杂,也体现了disuptor是如何利用CAS机制进行的线程间同步,并保证多个生产者的生产不互斥。如图所示,红色的代表已经发布的事件,淡绿色代表生产者1申请的事件槽,淡黄色代表生产者2申请的事件槽。
- 申请事件槽:多生产者生产数据的过程就是移动cursor的过程,多个线程同时使用CAS操作更新cursor的值,哪个线程成功的更新了cursor的值哪个线程就成功申请了事件槽,而其他的线程则利用CAS操作继续尝试更新cursor的值。申请成功后cursor的值已经发生了改变,那怎么保证在该事件槽发布之前对消费者不可见呢?disruptor额外利用了一个数组,如图中所示。深黄色代表相应的事件槽已经发布,白色代表相应的事件槽尚未发布。disruptor使用了UNSAFE类对该数组进行操作,从而保证数组值更新的高效性。
- 更新数据:生产者按序将成功申请到的事件槽数据进行更新
- 发布事件槽:生产者将对应数组的标志位更新
")
多个生产者生产数据唯一的竞争就发生在cursor值的更新,disruptor使用CAS操作更新cursor的值从而避免使用了锁。申请数据之后,多个生产者可以并发更新数据,发布事件槽,互不影响。需要说明的是,如图中所示,生产者1申请了三个事件槽,发布了一个事件槽,生产者2申请了两个事件槽,发布了一个事件槽。时间上,在生产者1发布其剩余的两个事件槽之前,生产者2发布的事件槽对于消费则也还是不可见的。所以,每个生产者一定要保证即便发生异常也要发布事件槽,避免其后的生产者发布的事件槽对消费者不可见。所以生产则更新数据和发布事件槽一般是一个try…finally结构。或者使用disruptor提供的EventTranslator机制发布事件,EventTranslator自动封装了try…finally结构
tips
消费者的机制与生产者非常类似,本文不再赘述。
使用案例
LMAX应用场景
第一个讲LMAX的应用场景,毕竟是催生disruptor的应用场景,所以非常典型。同时,disruptor作为内存消息队列,怎么保证宕机的情况下数据不丢失这一关键问题在LMAX自身的应用中可以得到一点启示。
LMAX的机构如图所示,共包括三部分,Input Disruptor,Business Processor,Output Disruptor。
")
Input Disruptor从网络接收到消息,在Business Processor处理之前需要完成三种操作:
- Journal:将收到的信息持久化,在Business Processor线程崩溃的时候恢复数据
- Replicate:复制信息到其他Business Processor节点
- Unmarshall:重组信息数据格式,便于Business Processor处理
Business Processor负责业务逻辑处理,并将结果写入Output Disruptor
Output Disruptor负责读取Business Processor处理结果,重组数据格式进行网络传输。
重点介绍一下Input Disruptor,Input Disruptor的依赖关系如图所示:
")
用disruptor的语言编写就是:
disruptor.handleWith(journal, replacate, unmarshall).then(business)
LMAX为了避免business processor出现异常导致消息的丢失,在business processor处理前将消息全部持久化存储。当business processor出现异常时,重新处理持久化的数据即可。我们可以借鉴LMAX的这种方式,来避免消息的丢失。更详细关于LMAX的业务架构介绍可以参考The LMAX Architecture
log4j 2
以下一段文字引用自Apache log4j 2官网,这段文字足以说明disruptor对log4j 2的性能提升的巨大贡献。
Log4j 2 contains next-generation Asynchronous Loggers based on the LMAX Disruptor library. In multi-threaded scenarios Asynchronous Loggers have 18 times higher throughput and orders of magnitude lower latency than Log4j 1.x and Logback.
log4j2性能的优越主要体现在异步日志记录方面,以下两个图片摘自官网分别从吞吐率和响应时间两个方面体现了log4j2异步日志性能的强悍。
")
")
log4j2异步日志的实现就是每次调用将待记录的日志写入disruptor后迅速返回,这样无需等待信息落盘从而大大提高相应时间。同时,disruptor的事件槽重用机制避免产生大量Java对象,进而避免GC对相应时间和吞吐率的影响,也就是log4j2官网提到的Garbage-free。
文件hash
还有一种比较常见的应用场景是文件hash。如图所示,需要对大文件进行hash以方便后续处理,由于文件太大,所以把文件分给四个线程分别处理,每个线程读取相应信息,计算hash值,写入相应文件。
")
这样的方法有两个弊端:
- 同一个线程内,读写相互依赖,互相等待
- 不同线程可能争夺同一个输出文件,需要lock同步
于是改为如下方法,四个线程读取数据,计算hash值,将信息写入相应disruptor。每个disruptor对应一个消费者,将disruptor中的信息落盘持久化。对于四个读取线程而言,只有读取文件操作,没有写文件操作,因此不存在读写互相依赖的问题。对于写线程而言,只存在写文件操作,没有读文件,因此也不存在读写互相依赖的问题。同时disruptor的存在又很好的解决了多个线程互相竞争同一个文件的问题,因此可以大大提高程序的吞吐率。
")

