


并发容器Map之一:ConcurrentHashMap原理(jdk1.8)
一、ConcurrentHashMap简介
二、ConcurrentHashMap源码分析
2.1、类图结构
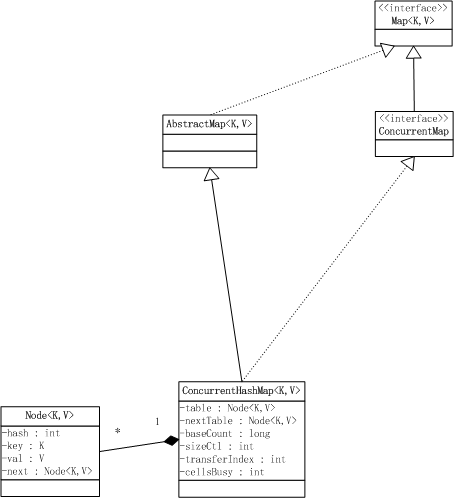
2.2、数据结构
1.8中放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现,结构如下:
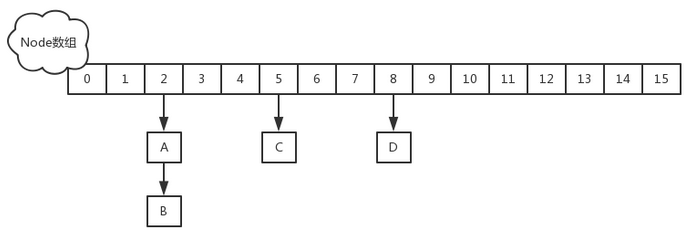
只有在执行第一次put方法时才会调用initTable()初始化Node数组,实现见put()-->putVal()-->initTable()
2.2.1 Node
Node是最核心的内部类,它包装了key-value键值对,所有插入ConcurrentHashMap的数据都包装在这里面。它与HashMap中的定义很相似,但是但是有一些差别它对value和next属性设置了volatile同步锁(与JDK7的Segment相同),它不允许调用setValue方法直接改变Node的value域,它增加了find方法辅助map.get()方法。
2.2.2 TreeNode
树节点类,另外一个核心的数据结构。当链表长度过长的时候,会转换为TreeNode。但是与HashMap不相同的是,它并不是直接转换为红黑树,而是把这些结点包装成TreeNode放在TreeBin对象中,由TreeBin完成对红黑树的包装。而且TreeNode在ConcurrentHashMap集成自Node类,而并非HashMap中的集成自LinkedHashMap.Entry<K,V>类,也就是说TreeNode带有next指针,这样做的目的是方便基于TreeBin的访问。
2.2.3 TreeBin
这个类并不负责包装用户的key、value信息,而是包装的很多TreeNode节点。它代替了TreeNode的根节点,也就是说在实际的ConcurrentHashMap“数组”中,存放的是TreeBin对象,而不是TreeNode对象,这是与HashMap的区别。另外这个类还带有了读写锁。
这里仅贴出它的构造方法。可以看到在构造TreeBin节点时,仅仅指定了它的hash值为TREEBIN常量,这也就是个标识为。同时也看到我们熟悉的红黑树构造方法
2.2.4 ForwardingNode
一个用于连接两个table的节点类。它包含一个nextTable指针,用于指向下一张表。而且这个节点的key value next指针全部为null,它的hash值为-1. 这里面定义的find的方法是从nextTable里进行查询节点,而不是以自身为头节点进行查找。
/** * A node inserted at head of bins during transfer operations. */ static final class ForwardingNode<K,V> extends Node<K,V> { final Node<K,V>[] nextTable; ForwardingNode(Node<K,V>[] tab) { super(MOVED, null, null, null); this.nextTable = tab; } Node<K,V> find(int h, Object k) { // loop to avoid arbitrarily deep recursion on forwarding nodes outer: for (Node<K,V>[] tab = nextTable;;) { Node<K,V> e; int n; if (k == null || tab == null || (n = tab.length) == 0 || (e = tabAt(tab, (n - 1) & h)) == null) return null; for (;;) { int eh; K ek; if ((eh = e.hash) == h && ((ek = e.key) == k || (ek != null && k.equals(ek)))) return e; if (eh < 0) { if (e instanceof ForwardingNode) { tab = ((ForwardingNode<K,V>)e).nextTable; continue outer; } else return e.find(h, k); } if ((e = e.next) == null) return null; } } } }
2.3、ConcurrentHashMap中的lock
在ConcurrentHashMap中,随处可以看到U, 大量使用了U.compareAndSwapXXX的方法,这个方法是利用一个CAS算法实现无锁化的修改值的操作,他可以大大降低锁代理的性能消耗。这个算法的基本思想就是不断地去比较当前内存中的变量值与你指定的一个变量值是否相等,如果相等,则接受你指定的修改的值,否则拒绝你的操作。因为当前线程中的值已经不是最新的值,你的修改很可能会覆盖掉其他线程修改的结果。这一点与乐观锁,SVN的思想是比较类似的。
我们可以发现JDK8中的实现也是锁分离的思想,只是锁住的是一个Node,而不是JDK7中的Segment,而锁住Node之前的操作是无锁的并且也是线程安全的,建立在后面提到的3个原子操作上。
2.3.1 unsafe静态块
unsafe代码块控制了一些属性的修改工作,比如最常用的SIZECTL 。在这一版本的concurrentHashMap中,大量应用来的CAS方法进行变量、属性的修改工作。利用CAS进行无锁操作,可以大大提高性能。
private static final sun.misc.Unsafe U; private static final long SIZECTL; private static final long TRANSFERINDEX; private static final long BASECOUNT; private static final long CELLSBUSY; private static final long CELLVALUE; private static final long ABASE; private static final int ASHIFT; static { try { U = sun.misc.Unsafe.getUnsafe(); Class<?> k = ConcurrentHashMap.class; SIZECTL = U.objectFieldOffset (k.getDeclaredField("sizeCtl")); TRANSFERINDEX = U.objectFieldOffset (k.getDeclaredField("transferIndex")); BASECOUNT = U.objectFieldOffset (k.getDeclaredField("baseCount")); CELLSBUSY = U.objectFieldOffset (k.getDeclaredField("cellsBusy")); Class<?> ck = CounterCell.class; CELLVALUE = U.objectFieldOffset (ck.getDeclaredField("value")); Class<?> ak = Node[].class; ABASE = U.arrayBaseOffset(ak); int scale = U.arrayIndexScale(ak); if ((scale & (scale - 1)) != 0) throw new Error("data type scale not a power of two"); ASHIFT = 31 - Integer.numberOfLeadingZeros(scale); } catch (Exception e) { throw new Error(e); } }
2.3.2 三个核心方法
ConcurrentHashMap定义了三个原子操作,用于对指定位置的节点进行操作。正是这些原子操作保证了ConcurrentHashMap的线程安全。
//获得在i位置上的Node节点 static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) { return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE); } //利用CAS算法设置i位置上的Node节点。之所以能实现并发是因为他指定了原来这个节点的值是多少 //在CAS算法中,会比较内存中的值与你指定的这个值是否相等,如果相等才接受你的修改,否则拒绝你的修改 //因此当前线程中的值并不是最新的值,这种修改可能会覆盖掉其他线程的修改结果,有点类似于SVN static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) { return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v); } //利用volatile方法设置节点位置的值 static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) { U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v); }
2.3.3 初始化方法initTable
对于ConcurrentHashMap来说,调用它的构造方法仅仅是设置了一些参数而已。而整个table的初始化是在向ConcurrentHashMap中插入元素的时候发生的。如调用put、computeIfAbsent、compute、merge等方法的时候,调用时机是检查table==null。
初始化方法主要应用了关键属性sizeCtl 如果这个值〈0,表示其他线程正在进行初始化,就放弃这个操作。在这也可以看出ConcurrentHashMap的初始化只能由一个线程完成。如果获得了初始化权限,就用CAS方法将sizeCtl置为-1,防止其他线程进入。初始化数组后,将sizeCtl的值改为0.75*n。
/** * Initializes table, using the size recorded in sizeCtl. */ private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; while ((tab = table) == null || tab.length == 0) { //sizeCtl表示有其他线程正在进行初始化操作,把线程挂起。对于table的初始化工作,只能有一个线程在进行。 if ((sc = sizeCtl) < 0) Thread.yield(); // lost initialization race; just spin else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {//利用CAS方法把sizectl的值置为-1 表示本线程正在进行初始化 try { if ((tab = table) == null || tab.length == 0) { int n = (sc > 0) ? sc : DEFAULT_CAPACITY; @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; table = tab = nt; sc = n - (n >>> 2);//相当于0.75*n 设置一个扩容的阈值 } } finally { sizeCtl = sc; } break; } } return tab; }
2.3.4 扩容方法 transfer
当ConcurrentHashMap容量不足的时候,需要对table进行扩容。这个方法的基本思想跟HashMap是很像的,但是由于它是支持并发扩容的,所以要复杂的多。原因是它支持多线程进行扩容操作,而并没有加锁。我想这样做的目的不仅仅是为了满足concurrent的要求,而是希望利用并发处理去减少扩容带来的时间影响。因为在扩容的时候,总是会涉及到从一个“数组”到另一个“数组”拷贝的操作,如果这个操作能够并发进行,那真真是极好的了。
整个扩容操作分为两个部分
- 第一部分是构建一个nextTable,它的容量是原来的两倍,这个操作是单线程完成的。这个单线程的保证是通过RESIZE_STAMP_SHIFT这个常量经过一次运算来保证的,这个地方在后面会有提到;
- 第二个部分就是将原来table中的元素复制到nextTable中,这里允许多线程进行操作。
2.4、成员变量
// 以下两个是用来控制扩容的时候 单线程进入的变量 /** * The number of bits used for generation stamp in sizeCtl. * Must be at least 6 for 32bit arrays. */ private static int RESIZE_STAMP_BITS = 16; /** * The bit shift for recording size stamp in sizeCtl. */ private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; /* * Encodings for Node hash fields. See above for explanation. */ static final int MOVED = -1; // hash值是-1,表示这是一个forwardNode节点 static final int TREEBIN = -2; // hash值是-2 表示这时一个TreeBin节点
//盛装Node元素的数组 它的大小是2的整数次幂
transient volatile Node<K,V>[] table; //resize时使用 private transient volatile Node<K,V>[] nextTable; //记录元素的个数 private transient volatile long baseCount; private transient volatile int sizeCtl; /** * The next table index (plus one) to split while resizing. */ private transient volatile int transferIndex; /** * Spinlock (locked via CAS) used when resizing and/or creating CounterCells. */ private transient volatile int cellsBusy; /** * Table of counter cells. When non-null, size is a power of 2. */ private transient volatile CounterCell[] counterCells; // views private transient KeySetView<K,V> keySet; private transient ValuesView<K,V> values; private transient EntrySetView<K,V> entrySet;
sizeCtl属性:
ConcurrentHashMap中出镜率很高的一个属性,因为它是一个控制标识符,在不同的地方有不同用途,而且它的取值不同,也代表不同的含义。
- 负数代表正在进行初始化或扩容操作
- -1代表正在初始化
- -N 表示有N-1个线程正在进行扩容操作
- 正数或0代表hash表还没有被初始化,这个数值表示初始化或下一次进行扩容的大小,这一点类似于扩容阈值的概念。还后面可以看到,它的值始终是当前ConcurrentHashMap容量的0.75倍,这与loadfactor是对应的。
2.5、构造函数
/** * Creates a new, empty map with the default initial table size (16). */ public ConcurrentHashMap() { } public ConcurrentHashMap(int initialCapacity) { if (initialCapacity < 0) throw new IllegalArgumentException(); int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY : tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1)); this.sizeCtl = cap; } public ConcurrentHashMap(int initialCapacity, float loadFactor) { this(initialCapacity, loadFactor, 1); }
2.6、增加元素
当执行put方法插入数据时,根据key的hash值,在Node数组中找到相应的位置
1、如果相应位置的Node还未初始化,则通过CAS插入相应的数据;
2、如果相应位置的Node不为空,且当前该节点不处于移动状态,则对该节点加synchronized锁,如果该节点的hash不小于0,则遍历链表更新节点或插入新节点;
3、如果该节点是TreeBin类型的节点,说明是红黑树结构,则通过putTreeVal方法往红黑树中插入节点;
4、如果binCount不为0,说明put操作对数据产生了影响,如果当前链表的个数达到8个,则通过treeifyBin方法转化为红黑树,如果oldVal不为空,说明是一次更新操作,没有对元素个数产生影响,则直接返回旧值;
5、如果插入的是一个新节点,则执行addCount()方法尝试更新元素个数baseCount;
public V put(K key, V value) { return putVal(key, value, false); } final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode());//根据key的hash值 int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; //table还是空的情况,初始化 if (tab == null || (n = tab.length) == 0) tab = initTable(); //找到元素的位置是空的,直接放进去,下面的注释也说到了,不用锁 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))//如果相应位置的Node还未初始化,则通过CAS插入相应的数据; break; // no lock when adding to empty bin } else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else {//如果相应位置的Node不为空,且当前该节点不处于移动状态,则对该节点加synchronized锁,更新或插入新元素; //到了这里,应该是找到了新的元素应该存放的位置,而且这个位置上还有其他的元素 V oldVal = null; //对该节点加synchronized锁,该节点是找到的位于数组上的待存放元素位置上的第一个元素 synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) {//如果该节点的hash不小于0,则遍历链表更新节点或插入新节点 binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {//key已经存在,替换为新值 oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) {//没有找到key元素,则将新元素加在链表末尾 pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) { //如果该节点是TreeBin类型的节点,说明是红黑树结构,则通过putTreeVal方法往红黑树中插入节点; Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) {//4、如果binCount不为0,说明put操作对数据产生了影响,如果当前链表的个数达到8个,则通过treeifyBin方法转化为红黑树,如果oldVal不为空,说明是一次更新操作,没有对元素个数产生影响,则直接返回旧值; if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount);//5、如果插入的是一个新节点,则执行addCount()方法尝试更新元素个数baseCount; return null; }
这里用到了一个锁,锁的是一个对象,是找到该元素对应的数组的位置上的那个元素。也的确,对数组其他位置上进行操作的时候,与该操作是完全没影响的(扩容除外)。
所以说,ConcurrentHashMap的性能要比Hashtable的性能要好,支持多线程同时进行增加,查找等操作(只要hash定的index不一样,且不扩容。)
2.7、查询元素
public V get(Object key) { Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; //spread相当于HashMap中的hash方法,处理一下hash值,使其分布不容易碰撞 int h = spread(key.hashCode()); //table是当前对象中用于保存所有元素的数组,必须不能为空,而且长度大于0 //tabAt的意思就是从table中找到hash为h的这个元素,如果没找到,说明不含有key为此值的元素 if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) { //如果hash值相同,说明几乎就是 if ((eh = e.hash) == h) { //再判断一下key是不是相同啊,是不是equals啊什么的,就准备返回了 if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } //这里跟下面的一样,都是遍历链表 else if (eh < 0) return (p = e.find(h, key)) != null ? p.val : null; //既然在当前位置,第一个元素还不是,那就遍历这条链表,找到对应的 while ((e = e.next) != null) { if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null; } //tabAt的具体实现如下,这里U对象是Unsafe类型的,其实就是通过操作内存,偏移来找到这个元素的所在位置 static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) { return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE); }
2.7、size
jdk1.8中使用一个volatile类型的变量baseCount记录元素的个数,当插入新数据或则删除数据时,会通过addCount()方法更新baseCount。
addCount():这个方法2个参数,第一个是增加了几个,第二个是binCount链表的长度
private final void addCount(long x, int check) { CounterCell[] as; long b, s; //1、初始化时counterCells为空,在并发量很高时,如果存在两个线程同时执行CAS修改baseCount值,则失败的线程会继续执行方法体中的逻辑,使用CounterCell记录元素个数的变化; if ((as = counterCells) != null || !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) { CounterCell a; long v; int m; boolean uncontended = true; //2、如果CounterCell数组counterCells为空,调用fullAddCount()方法进行初始化,并插入对应的记录数,通过CAS设置cellsBusy字段,只有设置成功的线程才能初始化CounterCell数组 if (as == null || (m = as.length - 1) < 0 || (a = as[ThreadLocalRandom.getProbe() & m]) == null || !(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) { fullAddCount(x, uncontended); return; } if (check <= 1) return; s = sumCount(); } if (check >= 0) { Node<K,V>[] tab, nt; int n, sc; while (s >= (long)(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { int rs = resizeStamp(n); if (sc < 0) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0) break; if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) transfer(tab, nt); } else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)) transfer(tab, null); s = sumCount(); } } } private final void fullAddCount(long x, boolean wasUncontended) { int h; if ((h = ThreadLocalRandom.getProbe()) == 0) { ThreadLocalRandom.localInit(); // force initialization h = ThreadLocalRandom.getProbe(); wasUncontended = true; } boolean collide = false; // True if last slot nonempty for (;;) { CounterCell[] as; CounterCell a; int n; long v; if ((as = counterCells) != null && (n = as.length) > 0) { if ((a = as[(n - 1) & h]) == null) { if (cellsBusy == 0) { // Try to attach new Cell CounterCell r = new CounterCell(x); // Optimistic create if (cellsBusy == 0 && U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {//volatile成员变量counterCells不为空,通过CAS设置cellsBusy字段,设置成功的线程想counterCells中插入new CounterCell(x)。 boolean created = false; try { // Recheck under lock CounterCell[] rs; int m, j; if ((rs = counterCells) != null && (m = rs.length) > 0 && rs[j = (m - 1) & h] == null) { rs[j] = r; created = true; } } finally { cellsBusy = 0; } if (created) break; continue; // Slot is now non-empty } } collide = false; } else if (!wasUncontended) // CAS already known to fail wasUncontended = true; // Continue after rehash else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x)) break; else if (counterCells != as || n >= NCPU) collide = false; // At max size or stale else if (!collide) collide = true; else if (cellsBusy == 0 && U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) { try { if (counterCells == as) {// Expand table unless stale CounterCell[] rs = new CounterCell[n << 1]; for (int i = 0; i < n; ++i) rs[i] = as[i]; counterCells = rs; } } finally { cellsBusy = 0; } collide = false; continue; // Retry with expanded table } h = ThreadLocalRandom.advanceProbe(h); } else if (cellsBusy == 0 && counterCells == as && U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {//volatile成员变量counterCells为空,通过CAS设置cellsBusy字段,设置成功的线程才能初始化CounterCell数组 boolean init = false; try { // Initialize table if (counterCells == as) { CounterCell[] rs = new CounterCell[2]; rs[h & 1] = new CounterCell(x); counterCells = rs; init = true; } } finally { cellsBusy = 0; } if (init) break; } else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x)) //如果通过CAS设置cellsBusy字段失败的话,则继续尝试通过CAS修改baseCount字段,如果修改baseCount字段成功的话,就退出循环,否则继续循环插入CounterCell对象 break; // Fall back on using base } }
由上面可知:因为元素个数保存baseCount中,部分元素的变化个数保存在CounterCell数组中,通过累加baseCount和CounterCell数组中的数量,即可得到元素的总个数。
public int size() { long n = sumCount(); return ((n < 0L) ? 0 : (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int)n); } final long sumCount() { CounterCell[] as = counterCells; CounterCell a; long sum = baseCount; if (as != null) { for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) sum += a.value; } } return sum; }
2.8、remove
final V replaceNode(Object key, V value, Object cv) { int hash = spread(key.hashCode()); for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0 || (f = tabAt(tab, i = (n - 1) & hash)) == null)//没有找到要删除的key元素,直接返回null break; else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { V oldVal = null; boolean validated = false; synchronized (f) {//找到要删除的key元素,对该节点加锁, if (tabAt(tab, i) == f) { if (fh >= 0) {//该节点的链表还有其他元素,则删除元素及维护链表结构 validated = true; for (Node<K,V> e = f, pred = null;;) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { V ev = e.val; if (cv == null || cv == ev || (ev != null && cv.equals(ev))) { oldVal = ev; if (value != null) e.val = value; else if (pred != null) pred.next = e.next; else setTabAt(tab, i, e.next); } break; } pred = e; if ((e = e.next) == null) break; } } else if (f instanceof TreeBin) { validated = true; TreeBin<K,V> t = (TreeBin<K,V>)f; TreeNode<K,V> r, p; if ((r = t.root) != null && (p = r.findTreeNode(hash, key, null)) != null) { V pv = p.val; if (cv == null || cv == pv || (pv != null && cv.equals(pv))) { oldVal = pv; if (value != null) p.val = value; else if (t.removeTreeNode(p)) setTabAt(tab, i, untreeify(t.first)); } } } } } if (validated) { if (oldVal != null) { if (value == null) addCount(-1L, -1); return oldVal; } break; } } } return null; }
2.9、扩容
当往hashMap中成功插入一个key/value节点时,有可能触发扩容动作:
1、如果新增节点之后,所在链表的元素个数达到了阈值 8,则会调用treeifyBin方法把链表转换成红黑树,不过在结构转换之前,会对数组长度进行判断,实现如下:

如果数组长度n小于阈值MIN_TREEIFY_CAPACITY,默认是64,则会调用tryPresize方法把数组长度扩大到原来的两倍,并触发transfer方法,重新调整节点的位置。

2、新增节点之后,会调用addCount方法记录元素个数,并检查是否需要进行扩容,当数组元素个数达到阈值时,会触发transfer方法,重新调整节点的位置。

transfer实现
transfer方法实现了在并发的情况下,高效的从原始组数往新数组中移动元素,假设扩容之前节点的分布如下,这里区分蓝色节点和红色节点,是为了后续更好的分析:

在上图中,第14个槽位插入新节点之后,链表元素个数已经达到了8,且数组长度为16,优先通过扩容来缓解链表过长的问题,实现如下:
1、根据当前数组长度n,新建一个两倍长度的数组nextTable;

2、初始化ForwardingNode节点,其中保存了新数组nextTable的引用,在处理完每个槽位的节点之后当做占位节点,表示该槽位已经处理过了;

3、通过for自循环处理每个槽位中的链表元素,默认advace为真,通过CAS设置transferIndex属性值,并初始化i和bound值,i指当前处理的槽位序号,bound指需要处理的槽位边界,先处理槽位15的节点;

4、在当前假设条件下,槽位15中没有节点,则通过CAS插入在第二步中初始化的ForwardingNode节点,用于告诉其它线程该槽位已经处理过了;

5、如果槽位15已经被线程A处理了,那么线程B处理到这个节点时,取到该节点的hash值应该为MOVED,值为-1,则直接跳过,继续处理下一个槽位14的节点;

6、处理槽位14的节点,是一个链表结构,先定义两个变量节点ln和hn,按我的理解应该是lowNode和highNode,分别保存hash值的第X位为0和1的节点,具体实现如下:

使用fn&n可以快速把链表中的元素区分成两类,A类是hash值的第X位为0,B类是hash值的第X位为1,并通过lastRun记录最后需要处理的节点,A类和B类节点可以分散到新数组的槽位14和30中,在原数组的槽位14中,蓝色节点第X为0,红色节点第X为1,把链表拉平显示如下:

1、通过遍历链表,记录runBit和lastRun,分别为1和节点6,所以设置hn为节点6,ln为null;
2、重新遍历链表,以lastRun节点为终止条件,根据第X位的值分别构造ln链表和hn链表:
ln链:和原来链表相比,顺序已经不一样了

hn链:

通过CAS把ln链表设置到新数组的i位置,hn链表设置到i+n的位置;
7、如果该槽位是红黑树结构,则构造树节点lo和hi,遍历红黑树中的节点,同样根据hash&n算法,把节点分为两类,分别插入到lo和hi为头的链表中,根据lo和hi链表中的元素个数分别生成ln和hn节点,其中ln节点的生成逻辑如下:
(1)如果lo链表的元素个数小于等于UNTREEIFY_THRESHOLD,默认为6,则通过untreeify方法把树节点链表转化成普通节点链表;
(2)否则判断hi链表中的元素个数是否等于0:如果等于0,表示lo链表中包含了所有原始节点,则设置原始红黑树给ln,否则根据lo链表重新构造红黑树。

最后,同样的通过CAS把ln设置到新数组的i位置,hn设置到i+n位置。

