
MySQL4
MySQL数据库4
1 管理索引
-
创建索引帮助
help CREATE INDEX -
创建索引
- 指令
CREATE INDEX - 语法格式
CREATE INDEX index_name ON tbl_name(index_col_name,…); - 示例
示例1:在students表中的取name的前十个字符字段增加索引名为idx_classidMariaDB [hellodb]> CREATE INDEX idx_name ON students(name(10));- 1
MariaDB [hellodb]> CREATE INDEX idx_name_age ON students(name,age);- 1
CREATE UNIQUE INDEX,唯一键命名时最好加上前缀以区分例如uni_idxMariaDB [hellodb]> CREATE UNIQUE INDEX uni_idx_name ON students(name);- 1
- 指令
-
删除索引
- 语法格式
DROP INDEX index_name ON tbl_name; - 示例
删除在字段students上的索引MariaDB [hellodb]> DROP INDEX idx_classid ON students;- 1
MariaDB [hellodb]> ALTER TABLE students DROP KEY uni_idx_name;- 1
- 语法格式
-
查看索引
- 语法格式
SHOW INDEXES FROM [db_name.]tbl_name; - 示例
'不在表所在库,显示索引,需要指定库名' MariaDB [(none)]> SHOW INDEXES FROM hellodb.students; '进入表所在数据库后,可以省略' MariaDB [(none)]> use hellodb MariaDB [hellodb]> show index from students\G- 1
- 2
- 3
- 4
- 5
*************************** 4. row *************************** Table: students Non_unique: 1 Key_name: idx_name_age <==具有相同的键名 Seq_in_index: 1 <==表示Name在组合键的前面 Column_name: Name *************************** 5. row *************************** Table: students Non_unique: 1 Key_name: idx_name_age <==与4都属于复合键,相同的键名 Seq_in_index: 2 <==表示age在组合键的后面 Column_name: Age- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
MariaDB [hellodb]> show index from students\G *************************** 2. row *************************** Table: students Non_unique: 0 <==主键和唯一键与其他索引的区别在于,此项为0 Key_name: uni_idx_name- 1
- 2
- 3
- 4
- 5
- 语法格式
-
优化表空间:
数据库中表数据文件,在删除数据后,所占空间不会自动释放,需要进行表空间优化才可以释放- 语法格式
OPTIMIZE TABLE tb_name - 示例
MariaDB [hellodb]> OPTIMIZE TABLE students;- 1
- 语法格式
-
查看索引的使用
- 语法格式
SHOW INDEX_STATISTICS - 开启功能相关变量
userstat - 示例
需要修改变量userstat为启动状态'1. 查看变量状态' MariaDB [hellodb]> SHOW VARIABLES LIKE 'userstat'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | userstat | OFF | +---------------+-------+ '2. 修改状态' MariaDB [hellodb]> SET GLOBAL userstat=1; '3. 查看索引的使用情况' MariaDB [hellodb]> SHOW INDEX_STATISTICS; +--------------+------------+------------+-----------+ | Table_schema | Table_name | Index_name | Rows_read | +--------------+------------+------------+-----------+ | hellodb | students | index_age | 24 | +--------------+------------+------------+-----------+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 语法格式
-
EXPLAIN分析索引的有效性
- 关键字
EXPLAIN - 语法格式
EXPLAIN SELECT clause'查询优化器如何执行查询' MariaDB [hellodb]> EXPLAIN SELECT * FROM students WHERE age=20; +------+-------------+----------+------+-------- -------+-----------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+----------+------+---------------+-----------+---------+-------+------+-------+ | 1 | SIMPLE | students | ref | index_age | index_age | 1 | const | 2 | | +------+-------------+----------+------+---------------+-----------+---------+-------+------+-------+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 输出信息说明:
参考https://dev.mysql.com/doc/refman/5.7/en/explain-output.html- id
当前查询语句中,每个SELECT语句的编号,包括子句的编号
复杂类型的查询有三种:- 简单子查询
- 用于FROM中的子查询
- 联合查询:UNION,UNION查询的分析结果会出现一个额外匿名临时表
MariaDB [hellodb]> EXPLAIN SELECT name FROM students UNION SELECT name FROM teachers; +------+--------------+------------+-------+---------------+--------------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+--------------+------------+-------+---------------+--------------+---------+------+------+-------------+ | 1 | PRIMARY | students | index | NULL | idx_name_age | 153 | NULL | 25 | Using index | | 2 | UNION | teachers | ALL | NULL | NULL | NULL | NULL | 4 | | | NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | | +------+--------------+------------+-------+---------------+--------------+---------+------+------+------- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- id
- select_type
- 简单查询为SIMPLE
- 复杂查询select_type显示内容
- SUBQUERY:简单子查询
- PRIMARY:最外面的SELECT
- UNION:UNION语句的第一个之后的SELECT语句
- UNION RESULT: 匿名临时表
- DERIVED:用于FROM中的子查询
要显示FROM子查询的类型,需要设置变量optimizer_switch,其中的相关项’derived_mergMariaDB [hellodb]> SET optimizer_switch='derived_merge=off';- 1
- table:SELECT语句关联到的表
- type:关联类型或访问类型,即MySQL决定的如何去查询表中的行的方式,以下顺序,性能从低到高
- ALL:全表扫描,也就是没有利用索引
- index:根据索引的次序进行全表扫描;如果在Extra列出现“Using index”表示了使用覆盖索引,而非全表扫描
- range:有范围限制的根据索引实现范围扫描;扫描位置始于索引中的某一点,结束于另一点
- ref: 根据索引返回表中匹配某单个值的所有行
- eq_ref:仅返回一个行,但与需要额外与某个参考值做比较
- const, system: 直接返回单个行
- possible_keys:查询可能会用到的索引
- key:查询中使用到的索引
- key_len:在索引使用的字节数
- ref:在利用key字段所表示的索引完成查询时所用的列或某常量值
- rows:MySQL估计为找所有的目标行而需要读取的行数
- Extra:额外信息
- Using index:MySQL将会使用覆盖索引,以避免访问表
- Using where:MySQL服务器将在存储引擎检索后,再进行一次过滤
- Using temporary:MySQL对结果排序时会使用临时表
- Using filesort:对结果使用一个外部索引排序
- 关键字
- 示例
- 索引没有利用,在表数据不是很多时范围查询,查询结果占表数据的很大一部分,优化器认为直接搜索的速度比索引快:
'查看表students中以x开头的姓名,由下例可知,没有利用索引,因为此表一共只有25条记录,而x开头的行占了6条' MariaDB [hellodb]> EXPLAIN SELECT * FROM students WHERE name LIKE 'x%'; +------+-------------+----------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+----------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | students | ALL | index_name | NULL | NULL | NULL | 25 | Using where | +------+-------------+----------+------+---------------+------+---------+------+------+-------------+- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 冗余索引示例,前文中已经建立了idx_name和复合键idx_name_age索引,试着搜索名字以o开头的学员,得到可用索引如下所示,复合键的索引机制为左前缀,而复合键idx_name_age的name键在左边,属于重复现象:
MariaDB [hellodb]> EXPLAIN SELECT * FROM students WHERE name LIKE 'o%'; +------+-------------+----------+-------+-------------------------+------------+---------+------+------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+----------+-------+-------------------------+------------+---------+------+------+-----------------------+ | 1 | SIMPLE | students | range | index_name,idx_name_age | index_name | 152 | NULL | 1 | Using index condition | +------+-------------+----------+-------+-------------------------+------------+---------+------+------+-----------------------+- 1
- 2
- 3
- 4
- 5
- 6
- 索引没有利用,在表数据不是很多时范围查询,查询结果占表数据的很大一部分,优化器认为直接搜索的速度比索引快:
- 另一个查询优化SQL语句
如果查询命令是一个多表查询,想要知道具体哪个字查询拖慢了速度,explain显示的内容不够具体,需要另一个观察命令的执行过程变量profiling,默认是关闭的1. '启用变量' MariaDB [hellodb]> SET profiling=on; 2. '执行一个查询指令' MariaDB [hellodb]> SELECT a.stuid, a.name FROM (SELECT * FROM students) AS a; 3. '执行profiles观察查询过程' MariaDB [hellodb]> SHOW profiles; +----------+------------+--------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+-------------------------------------------------------------- | | 1 | 0.00120368 | SELECT a.stuid, a.name FROM (SELECT * FROM students) AS a | +----------+------------+--------------------------------------------------------------+ 4. '针对编号继续查询,就会列出详细执行过程所用时间' MariaDB [hellodb]> SHOW profile FOR query 1;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2. 并发控制
保证多个用户同时访问,互相不干扰
2.1 一些概念
-
锁分类
- 锁粒度
- 表级锁(MyISAM)
- 行级锁(InnoDB)
- 以独占性来分
- 读锁:共享锁,只读不可写,多个读互不阻塞,
- 写锁:独占锁,排它锁,一个写锁会阻塞其它读和它锁
- 按是否自动加锁分类:
- 隐式锁:由存储引擎自动施加锁
- 显式锁:用户手动请求
- 锁粒度
-
实现
- 存储引擎:自行实现其锁策略和锁粒度
- 服务器级:实现行锁,表级锁;用户可显式请求
-
锁策略
在锁粒度及数据安全性寻求的平衡机制,加锁的缺点为影响并发性,但是可以保证数据完整性,在两者之间寻求平衡
2.2 显式锁使用
- 加锁
- SQL语句关键字
LOCK TABLES - 语法格式
LOCK TABLES tbl_name[[AS] alias] lock_type [, tbl_name[[AS] alias] lock_type] ...- 1
- 说明
- tbl_name:将加锁的表名
- lock_type: READ |WRITE
加WRITE锁时,需要注意缓存是否开启,如果有缓存需要重启服务或者关闭缓存开关或者将缓存相关的服务器变量quer_cache_wlock_invalidate=on写入配置文件,不允许其他用户从缓存读取
- 示例
为表teachers加读锁MariaDB [hellodb]> LOCK TABLES teachers READ; 此时不能访问本数据库的其他表格,会报错,其他终端不影响 '试着访问同数据库的另一种表students' MariaDB [hellodb]> SELECT * FROM students; ERROR 1100 (HY000): Table 'students' was not locked with LOCK TABLES <==报错信息- 1
- 2
- 3
- 4
- 5
- SQL语句关键字
- 加全局锁
- 语法格式
FLUSH TABLES [tb_name[,…]] [WITH READ LOCK] - 说明
将表加锁,关闭正在打开的表(清除查询缓存),不指定表,将进行全局加锁(所有数据库),通常在备份前加全局读锁,FLUSH TABLES为温备份,加锁时会等待所有表格关闭 - 示例:使用FLUSH TABLES加锁时,有未关闭表等待状态示例
'在其他终端访问hellodb数据库表teachers,设置函数sleep(100)休眠100秒,保持访问状态' MariaDB [hellodb]> SELECT *,sleep(100) FROM teachers; '利用FLUSH TABLES 为teachers加只读锁' MariaDB [hellodb]> FLUSH TABLES teachers WITH READ LOCK; <==会卡在这里等待所有表关闭- 1
- 2
- 3
- 4
- 5
- 语法格式
- 查询时加锁
- 加写锁
SELECT clause FOR UPDATE - 加读锁
SELECT clause LOCK IN SHARE MODE
- 加写锁
- 解锁
UNLOCK TABLES
2.3 死锁
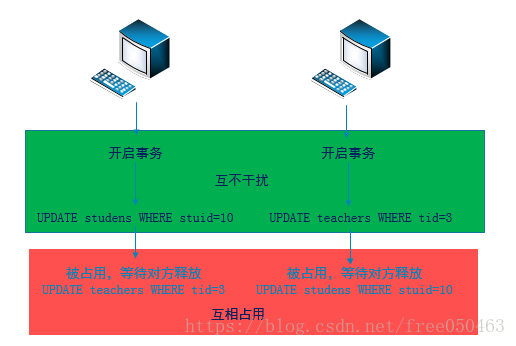
- 什么是死锁
两个或多个事务在相互占用彼此资源,并请求锁定对方占用的资源的状态
- 解决方法
回滚其中一个,被回滚的是代价小的,通常为执行时间短的哪个事务,系统主动解决 - 当多事务同时执行时,遇到行锁锁定,另一个用户处于等待状态的主动解决方案
- 查看事务列表
SHOW PROMCESSLIST - 结束等待事务
kill id - 示例
1. '查看事务列表,找出处于等待的' MariaDB [hellodb]> SHOW PROMCESSLIST\G *************************** 7. row *************************** Id: 23 <==kill命令后面的编号 User: root Host: localhost db: hellodb Command: Query Time: 21 State: updating Info: update teachers set age=70 where tid=3 <==处于等待的事务 Progress: 0.000 2. '主动将结束等待状态' MariaDB [hellodb]> kill 23 <==id为等待事务编号- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 查看事务列表
3. 事务
事务Transactions:一组原子性的SQL语句,或一个独立工作单元,有专门的事务日志记录操作过程,实现undo,redo等故障恢复功能,来保证数据的一致性
-
ACID特性:
- A(atomicity原子性)
整个事务中的所有操作要么全部成功执行,要么全部失败后回滚
数据库执行事务时,先读入数据到内存,在内存中修改后,放到日志文件中,全部事务执行完毕后会有一个标记,如果执行过程中掉电,恢复供电后,日志文件会根据标记判断事务是否全部执行完毕,全部执行完毕则写入磁盘(redo),没有执行完则舍弃以记录操作(undo),保证磁盘数据完整性 - C(consistency一致性)
数据库总是从一个一致性状态转换为另一个一致性状态 - I(Isolation隔离性)
一个事务所做出的操作在提交之前,是不能为其它事务所见;隔离有多种隔离级别,实现并发 - D(durability持久性)
一旦事务提交,其所做的修改会永久保存于数据库中
- A(atomicity原子性)
-
Transaction生命周期
- LNITIAL DB STATE :数据库初始一致性状态
- START TRANSACTION:开始事务,对数据库增删改
- COMMIT:确定无误,提交结果,结束事务
- NEW DB STATE:新的一致性状态
- ROLLBACK:只要事务没有提交,就可以回滚到数据库初始状态
-
使用事务
在数据库中执行增删改就是一个事务,回车执行就结束了此事务,这种系统后台自动开始,自动提交的事务叫做隐式提交事务,mysql和sql server默认使用自动提交,oracle默认使用的是手动提交需要输入(commit提交,rollback回滚)-
自动提交是否启动相关变量
set autocommit={1|0} 默认为1,设为0时为非自动提交'1. 在会话A中,将事务提交设置为非自动提交' MariaDB [(none)]> set autocommit=off; '2. 确认变量状态' MariaDB [(none)]> show variables like 'autocommit'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | autocommit | OFF | <==已经关掉,会话级的,不影响其他窗口 +--------------------------+-------+ 3. '修改数据' MariaDB [hellodb]> UPDATE students SET classid=10 SHERE stuid=15; MariaDB [hellodb]> SELECT * FROM students; <==在执行修改命令的终端查看修改 效果 | 15 | Duan Yu | 19 | M | 10 | NULL | <=可以看到已修改 4. '在B会话中查看' MariaDB [hellodb]> SELECT * FROM students; | 15 | Duan Yu | 19 | M | 4 | NULL | <=由于事务没有提交,属于脏数 据,其他会话不会显示 5. '回到A会话,不想修改执行rollback,回滚到最初状态' MariaDB [hellodb]> ROLLBACK; Query OK, 0 rows affected (0.00 sec) 6. '查看回滚后的结果,数据不变' MariaDB [hellodb]> select * from students; | 15 | Duan Yu | 19 | M | 4 | NULL | 7. '确认事务无误,提交事务关键字为`commit`,确认后数据就永久更改,不能回滚了' MariaDB [hellodb]> COMMIT;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
-
人为定义启动事务(以下3个命令都可以)
- BEGIN
- BEGIN WORK
- START TRANSACTION
-
结束事务:
- COMMIT:提交
- ROLLBACK: 回滚
注意:只有事务型存储引擎中的DML语句方能支持此类操作
-
事务保存点
- SQL关键字
SAVEPOINT identifier - 回滚到保存点语法格式
ROLLBACK [WORK] TO [SAVEPOINT] identifier - 删除保存点
RELEASE SAVEPOINT identifier - 示例:事务在执行增删改时增加保存点,当执行回滚操作时,可以只撤销一部分
'1. 开启事务' MariaDB [hellodb]> BEGIN; Query OK, 0 rows affected (0.00 sec) 2. '修改students表stuid为23的学员classid编号为15' MariaDB [hellodb]> UPDATE students SET classid=15 WHERE stuid=23; 3. '设置保存点,命名为sp23' MariaDB [hellodb]> savepoint sp23; 4. '修改同上' MariaDB [hellodb]> UPDATE students SET classid=16 WHERE stuid=24; 5. '设置保存点' MariaDB [hellodb]> savepoint sp24; 6. '修改同上' MariaDB [hellodb]> UPDATE students SET classid=17 WHERE stuid=25; 7. '查看修改后的数据,如下所示' MariaDB [hellodb]> SELECT * FROM students; | 23 | Ma Chao | 23 | M | 15 | NULL | | 24 | Xu Xian | 27 | M | 16 | NULL | | 25 | Sun Dasheng | 100 | M | 17 | NULL | 8. '回滚到保存点sp24,可以看到只有25号学员信息返回原状态' MariaDB [hellodb]> ROLLBACK TO sp24; | 23 | Ma Chao | 23 | M | 15 | NULL | | 24 | Xu Xian | 27 | M | 16 | NULL | | 25 | Sun Dasheng | 100 | M | NULL | NULL | 9. '回滚到保存点sp23,可以看到23号学员修改信息没有改变' MariaDB [hellodb]> ROLLBACK TO sp23 ; | 23 | Ma Chao | 23 | M | 15 | NULL | | 24 | Xu Xian | 27 | M | NULL | NULL | | 25 | Sun Dasheng | 100 | M | NULL | NULL |- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- SQL关键字
-
-
事务隔离级别
| 事务隔离级别 | 脏读可能性 | 不可重复读可能性 | 幻读可能性 | 加锁读 |
|---|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 | 否 |
| 不可重复读(read-committed) | 否 | 是 | 是 | 否 |
| 可重复读(repeatable-read) | 否 | 否 | 是 | 否 |
| 串行化(serializable) | 否 | 否 | 否 | 是 |
-
各级别说明,从上至下更加严格
- READ UNCOMMITTED
可读取到未提交数据,产生脏读(读到的数据是一个没有确定的结果,可能会产生误读) - READ COMMITTED
可读取到提交数据,但未提交数据不可读,产生不可重复读,即可读取到多个提交数据,导致每次读取数据不一致(例如A用户(执行修改)与B用户同时执行事务,B用户在事务生命期内(大于A用户事务生命期)可以读取到A用户修改提交前原始一致数据data1,A用户提交后新一致数据data2,中间的脏数据不能读取) - REPEATABLE READ
可重复读,多次读取数据都一致,产生幻读,即读取过程中,即使有其它提交的事务修改数据,仍只能读取到未修改前的旧数据。此为MySQL默认设置
(例如例如A用户(执行修改)与B用户同时执行事务,B用户在事务生命期(大于A用户事务生命期)内读取到的数据始终为data1,A用户修改后的数据在此事务生命期内不会显示) - SERIALIZABILE
可串行化,未提交的读事务阻塞修改事务,或者未提交的修改事务阻塞读事务,导致并发性能差。处于阻塞状态的操作会有一个等待时间(可通过变量修改),超过时间没有执行,就会撤销操作- 阻塞状态等待时间相关变量为
innodb_lock_wait_timeout - 显式加锁等待时间变量为
wait_timeout
- 阻塞状态等待时间相关变量为
- READ UNCOMMITTED
-
指定事务隔离级别:
服务器变量tx_isolation指定,默认为REPEATABLE-READ,可在GLOBAL和SESSION级进行设置- 官方tx_isolation选项说明
tx_isolation Description: The transaction isolation level. See also SET TRANSACTION ISOLATION LEVEL. Commandline: --transaction-isolation=name <==作为服务器选项名字不同 Scope: Global, Session Dynamic: Yes Type: enumeration Default Value: REPEATABLE-READ Valid Values: READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 当做变量临时修改
SET tx_isolation='READ-UNCOMMITTED|READ-COMMITTED|REPEATABLE-READ|SERIALIZABLE'- 1
- 服务器选项中指定
[root@hai7-8 ~]$vim /etc/my.cnf [mysqld] transaction-isolation=SERIALIZABLE- 1
- 2
- 3
- 官方tx_isolation选项说明
5 日志
没有特殊需求,劲量少的启用非默认设置,多少都会拖慢速度
- 事务日志 transaction log
- 中继日志 reley log
- 错误日志 error log
- 通用日志 general log
- 慢查询日志 slow query log
- 二进制日志 binary log
5.1 事务日志(transaction log)
保存事务在执行中的操作,事务型存储引擎自行管理和使用
-
特征
- 预写式日志 (write ahead logging)
事务日志的写入类型为“追加”,因此其操作为“顺序IO”,所以被称为预写式日志; - 写入速度快
当执行大量写操作时,速度会比直接写入数据库快
原因是,事务日志是追加写入,而数据库是随机写入,需要寻址。在事务提交时,由于是一次写入,速度要比写一条提交一条快很多,与BUFFER原理相同。缺点是事务执行时会加锁,有可能影响并发性。 - 日志的写入要早于写入数据库
- 预写式日志 (write ahead logging)
-
事务日志文件
- 默认存放在mysql的家目录下,文件名为ib_logfile0, ib_logfile1
- 事务日志默认固定大小为5M,写满就会覆盖之前的数据
- 修改存放路径
不支持动态更改,需要修改配置文件重启服务
需要注意的是新指定的存放目录权限问题,要保证mysql有写权限[root@hai7-8 ~]$vim /etc/my.cnf [mysqld] innodb_log_group_home_dir=/data/mysqllogs- 1
- 2
- 3
-
Innodb事务日志相关配置:
show variables like '%innodb_log%'; innodb_log_file_size 5242880 <==每个日志文件大小 innodb_log_files_in_group 2 <==日志组成员个数 innodb_log_group_home_dir ./ <==事务文件路径,表示在mysql的家目录下文件名为ib_logfile0|1默认大小为5M- 1
- 2
- 3
- 4
5.2 中继日志(relay log)
主从复制架构中,从服务器用于保存从主服务器的二进制日志中读取的事件
5.3 错误日志
- 记录内容
- mysqld启动和关闭过程中输出的事件信息
- mysqld运行中产生的错误信息
- event scheduler运行一个event时产生的日志信息
- 在主从复制架构中的从服务器上启动从服务器线程时产生的信息
- 错误日志相关配置
SHOW GLOBAL VARIABLES LIKE 'log_error' log_error=/PATH/TO/LOG_ERROR_FILE <==错误文件路径 log_warnings=1|0 <==是否记录警告信息至错误日志文件,默认值1- 1
- 2
- 3
5.4 通用日志
- 记录内容
记录对数据库的通用操作,包括错误的SQL语句,记录较频繁,按需开启 - 通用日志相关设置
- 启用禁用通用日志
general_log=ON|OFF - 通用数据库文件路径,默认在mysql家目录下文件为centoos7.log
general_log_file=HOSTNAME.log - 修改通用日志的保存类型
文本文件不好管理,可以考虑修改为table,修改后放在数据库系统库mysql内,之后可以通过-e选项导出为文本
log_output=TABLE|FILE|NONE
- 启用禁用通用日志
5.5 慢查询日志
- 功能
定义一个阈值,来触发慢查询日志,超过此阈值将记录在慢查询日志中 - 相关设置
- 开启或关闭慢查询(global),开启后自动在mysql家目录下生成centos7-slow.log文件
slow_query_log=ON|OFF - 慢查询的阀值,单位秒(global|session)
long_query_time=NMariaDB [hellodb]> SET long_query_time=5;- 1
- 重命名慢查询日志文件
slow_query_log_file=HOSTNAME-slow.log - 超过阈值,默认记录类型(查增删改都会记录)
log_slow_filter = admin,filesort,filesort_on_disk,full_join,full_scan,query_cache,query_cache_miss,tmp_table,tmp_table_on_disk- 1
- 不使用索引或使用全索引扫描,不论是否达到慢查询阀值的语句是否记录日志,默认OFF,即不记录
log_queries_not_using_indexes=ON - 多少次查询才记录,mariadb特有
log_slow_rate_limit = 1 - 记录内容
log_slow_verbosity= Query_plan(查询计划),explain(执行过程) - 同slow_query_log 新版已废弃,5.129为了兼容留着,mariadb10.0/mysql5.6.1已删除
log_slow_queries = OFF
- 开启或关闭慢查询(global),开启后自动在mysql家目录下生成centos7-slow.log文件
5.6 二进制日志
-
功能
记录导致数据改变或潜在导致数据改变的SQL语句,通过“重放”日志文件中的事件来生成数据副本,也就是将二进制文件中的SQL语句重新执行一次,将来可以用二进制日志来实现主从复制
-特征- 记录已提交的日志
- 不依赖于存储引擎类型
- 不断追加,不会覆盖之前记录
- 二进制日志属于归档日志,可以用来还原数据
-
优化建议
建议二进制日志和数据文件分开存放,不至于一起丢失,有还原机会 -
二进制日志记录格式
- 基于“语句”记录(statement),
- 记录SQL语句,默认模式
例如执行UPDATE students SET age=10;没有限定条件,实际修改的是全部记录比如25条,记录模式为语句记录,将只记录此条SQL语句 - 缺陷:如果SQL语言执行时使用的是变量,例如now(),后期还原时此记录将与原纪录不符
- 记录SQL语句,默认模式
- 基于“行”记录(row)
记录数据,日志量较大,承上所述,记录模式选择为行记录,将记录25条修改记录 - 混合模式(mixed)
让系统自行判定该基于哪种方式进行,建议选择mixed。10.2.4版本之后默认为mixed
- 基于“语句”记录(statement),
-
查看默认二进制记录格式
show variables like 'binlog_format'; -
二进制日志文件的构成
- 日志文件:
mysql|mariadb-bin.文件名后缀,二进制格式,初始值245字节大小
如: mariadb-bin.000001 - 索引文件:
mysql|mariadb-bin.index,文本格式,记录当前有效的二进制文件是谁
- 日志文件:
-
二进制日志相关的服务器变量:
- 开启二进制日志文件,两项都开启才可以开启二进制日志功能
- 是否记录二进制日志,默认ON,支持热修改
sql_log_bin=ON|OFF - (只读,只能在配置文件中设置)指定文件位置;默认OFF,表示不启用二进制日志功能
log_bin=/PATH/BIN_LOG_FILE[root@hai7-8 ~]$vim /etc/my.cnf [mysqld] log-bin '如果写成log-bin=on,表示启用并定义生成的二进制文件名前缀为on.,不写表示启用,文件名由系统自定义' log-bin=/data/mysqlbin/mysql-bin '可以指定路径,修改目录mysql要具有写权限,写一种就好'- 1
- 2
- 3
- 4
- 5
- 6
- 是否记录二进制日志,默认ON,支持热修改
- 二进制日志记录的格式,默认STATEMENT
binlog_format=STATEMENT|ROW|MIXED - 单个二进制日志文件的最大体积,到达最大值会自动滚动,默认为1G
max_binlog_size=1073741824
说明:文件达到上限时的大小未必为指定的精确值 - 设定是否启动二进制日志即时同步磁盘功能,默认0,由操作系统负责同步日志到磁盘,即时写入,或者缓存起来一起写入
sync_binlog=1|0 - 二进制日志可以自动删除的天数。 默认为0,即不自动删除
expire_logs_days=N
- 开启二进制日志文件,两项都开启才可以开启二进制日志功能
-
二进制日志管理
- 查看mariadb自行管理使用中的二进制日志文件列表,及大小
SHOW {BINARY | MASTER} LOGS - 查看使用中的二进制日志文件,与SHOW LOGS显示内容类似,更详细
SHOW MASTER STATUSMariaDB [hellodb]> SHOW MASTER STATUS; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000010 | 2185 | | | +------------------+----------+--------------+------------------+ `position`:表示位置,和数据大小一样,表示后续文件将从这个位置开始- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 查看mariadb自行管理使用中的二进制日志文件列表,及大小
-
查看二进制文件中的指定内容
- 语法格式
SHOW BINLOG EVENTS [IN ‘log_name’] [FROM pos] [LIMIT [offset,] row_count] - 说明
- LIMIT:限定查看后续的第几条记录
- FROM pos:从哪个位置开始,pos就是上例中的position
- 示例
SHOW BINLOG EVENTS IN 'mysql-bin.000001' from 2106 limit 2,3- 1
- 语法格式
-
二进制日志事件的格式:
# at 328 #151105 16:31:40 server id 1 end_log_pos 431 Query thread_id=1 exec_time=0 error_code=0 use `mydb`/*!*/; SET TIMESTAMP=1446712300/*!*/; CREATE TABLE tb1 (id int, name char(30)) <==事件内容 /*!*/;- 1
- 2
- 3
- 4
- 5
- 6
- 事件发生的日期和时间:151105 16:31:40 151105为年月日
- 事件发生的服务器标识:server id 1
- 事件的结束位置:end_log_pos 431
- 事件的类型:Query
- 事件发生时所在服务器执行此事件的线程的ID:thread_id=1
- 语句的时间戳与将其写入二进制文件中的时间差:exec_time=0
- 错误代码:error_code=0
- GTID:Global Transaction ID,mysql5.6以mariadb10以上版本专属属性,保证所有服务器上发生的日志都有唯一的编号
-
清除指定二进制日志:
- 语法格式
PURGE { BINARY | MASTER } LOGS { TO 'log_name' | BEFORE datetime_expr } - 示例
- 删除5之前的日志,5保留
MariaDB [hellodb]> PURGE BINARY LOGS TO 'mysql-bin.000005';- 1
- 删除2017-01-23之前的日志
PURGE BINARY LOGS BEFORE '2017-03-22 09:25:30';- 1
- 删除5之前的日志,5保留
- 语法格式
-
删除所有二进制日志,index文件重新记数
日志文件从#开始记数,默认从1开始,一般是master第一次启动时执行,MariaDB10.1.6开始支持TO #
RESET MASTER [TO #] -
切换日志文件,生成的日志和原日志文件都是有效的
- SQL语句
FLUSH LOGS - 应用场景
将旧文件备份后,生成新的日志文件,让之后的日志都存放在新的文件中
- SQL语句
6. 命令行专用二进制工具 mysqlbinlog
-
命令格式
mysqlbinlog [OPTIONS] log_file… -
OPTIONS
- –start-position=#:指定开始位置
- –stop-position=#:指定结束位置
- –start-datetime=:指定开始时间
- –stop-datetime=:指定结束时间
时间格式:YYYY-MM-DD hh:mm:ss - –base64-output[=name]:以base64编码显示
-
示例
- 设置起始位置和结束位置查看日志内容
mysqlbinlog --start-position=6787 --stop-position=7527 /var/lib/mysql/mariadb-bin.000003- 1
- 设置起始位置和结束位置查看日志内容
mysqlbinlog --start-datetime="2018-01-30 20:30:10" --stop-datetime="2018-01-30 20:35:22" /var/lib/mysql/mariadb-bin.000003- 1
- 以base64格式输出显示
mysqlbinlog /var/lib/mysql/mariadb-bin.000003 --start-datetime="2018-01-30 20:30:10" --stop-datetime="2018-01-30 20:35:22" --base64-output- 1
- 二进制日志以行格式保存日志,默认为base64显示,将其以文本格式显示
mysqlbinlog /var/lib/mysql/mariadb-bin.000003 -v- 1
- 设置起始位置和结束位置查看日志内容
-
利用二进制文件恢复数据
- 导出丢失数据对应的二进制文件,比如对应的二进制文件位置在2165,文本或者base64编码都可以识别的
[root@hai7-8 ~]$mysqlbinlog /var/lib/mysql/mariadb-bin.000003 --start-datetime=2165 > /data/text.sql- 1
- 记录的本身就是SQL语句,所以可以将其直接导入mysql丢失数据的数据库中
[root@hai7-8 ~]$mysql hellodb < /data/test.sql- 1
- 导出丢失数据对应的二进制文件,比如对应的二进制文件位置在2165,文本或者base64编码都可以识别的
</div>
<link href="https://csdnimg.cn/release/phoenix/mdeditor/markdown_views-7f770a53f2.css" rel="stylesheet">
</div>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号