查询语句
一:单表查询完整的查询语句
格式:
select [distinct] {*|字段名|聚合函数|表达式} from 表名 [where 条件 group by 字段名 having 条件 order by 字段名 limit 显示的条数]
以上是书写顺序,必须按照这个顺序来书写sql语句。其中[]表示可选的,{}表示必选的。
关键字的执行顺序:关键字的执行顺序和关键字的书写顺序相同,都是从上至下。
第一步找到对应的文件from,
第二步读取并筛选数据,where条件读取每一行数据,判断是否满足条件,
group by将数据按照某个字段进行分组,having对分组后的数据进行筛选,
distinct对数据进行去重处理,order by对数据进行排序,limit选取一部分数据。
以上书写顺序中:
*:表示所有列都显示,也可以手动指定眼显示的列,可以是多个。
distinct:用于去除重复的记录,注意:只能去除完全相同的记录。
表达式:支持加减乘除四则运算。
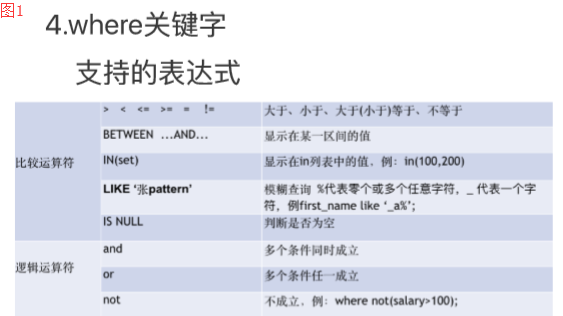
where:从硬盘上读取数据时的一个过滤条件。where支持的运算符见图1
group by:用于给数据分组,从而方便统计管理。
聚合函数:将一堆数据经过计算,得到一个数据。
如:求和 sum() 求平均数 avg() 求最大值/最小值 max()/min() 求个数 count()
having:用于对分组后的数据进行过滤。having一般不会单独出现,都是和group by一起出现。
having和where的区别:
相同点:都用于过滤数据
不同点:where是最先执行,用于读取硬盘数据,而having要等到数据读取完之后,才进行过滤;
where中不能使用聚合函数,而having中可以使用。
order by:用于对记录进行排序,默认为升序。修改为降序:select *from 表名 order by 标准 desc;
limit:用于限制显示的记录数。 语法:limit [起始位置,] count
例:查看表里的前三条数据:select *from 表名 limit 3;
查看表里的第三条到第五条数据:select * from 表名 limit 2,3;
二:多表查询:在多个表中查询需要的数据。
多表查询的方式:
1:笛卡尔积查询:用表中的一条记录,去链接另一张表中的所有记录。就像是把两张表的数据做了一个乘法,
这将导致产生大量的无用重复数据,然后可以使用where筛选出正确的数据。
语法:select *from 表1,表2 where 条件;
on关键字:用于多表查询时进行条件限制。但是on关键字无法替换上述的where,因为它只能用在专门多表
查询语句中。如内连接查询就可以使用on关键字。
2:内连接查询: inner join
语法:select *from 表1 inner join 表2 on 条件;
3:左外连接: left join 左边表中的数据完全显示,右边表中的数据匹配上才显示。
语法:select *from 左表 left join 右表 on 条件;
4:右外连接: right join 右边表中的数据完全显示,左边表中的数据匹配上才显示。
语法:select *from 左表 right join 右表 on 条件;
5:全外连接: full join 在mysql中不支持,但是在oracle中支持。可以通过union来间接实现全外连接。
union:表示合并查询,意思是把多个表的查询结果合并在一起显示,但是要求被合并的表之间,表结构
必须相同。union默认去除重复,如果想要合并但是不去除重复,可以使用union all来实现。
三:子查询
将上一次查询的结果作为本次查询的原始数据。
==========================================================================================
补充:记录详细操作:
[] 表示可选的;
增:
语法:insert [into] 表名[字段名] value|values(字段值....);
其中 [字段名] 如果写了,那么后面的值必须与写的字段匹配;如果不写,那么后面的值必须和表的结构完全匹配。
value 表示插入一条记录
values 表示插入多条记录
改:
语法:update 表名 set 字段名 = 新的值[,字段n = 新值n] [where 条件];
其中 where 是可选的,如果有就修改满足条件的记录;如果没有,就全部修改。
可以同时修改多个字段,用逗号进行隔开即可。
删:
语法:delete from 表名 [where 条件];
其中 where 是可选的,如果有就删除满足条件的记录;如果没有,就全部删除。
如果需要全部删除,建议使用 truncate table 表名;
因为 delete 是逐行比对,删除效率低,而且 delete 删除的行号会保留,不方便。
复制表:
语法:create table 表名副本 select *from 表名; 结构与数据全部拷贝。
create table 表名副本 select *from 表名 where 0 > 1; 仅拷贝结构。
总结:这种复制的索引(也就是主键)不能被拷贝,并且描述(也就是自增)也不能被拷贝。