



在使用order by时,经常出现Using filesort,因此对于此类sql语句需尽力优化,使其尽量使用Using index。
1.准备
1.1 创建test表。
-
drop table if exists test;
-
create table test(
-
id int primary key auto_increment,
-
c1 varchar(10),
-
c2 varchar(10),
-
c3 varchar(10),
-
c4 varchar(10),
-
c5 varchar(10)
-
) ENGINE=INNODB default CHARSET=utf8;
-
-
insert into test(c1,c2,c3,c4,c5) values('a1','a2','a3','a4','a5');
-
insert into test(c1,c2,c3,c4,c5) values('b1','b2','b3','b4','b5');
-
insert into test(c1,c2,c3,c4,c5) values('c1','c2','c3','c4','c5');
-
insert into test(c1,c2,c3,c4,c5) values('d1','d2','d3','d4','d5');
-
insert into test(c1,c2,c3,c4,c5) values('e1','e2','e3','e4','e5');

1.2 创建索引。
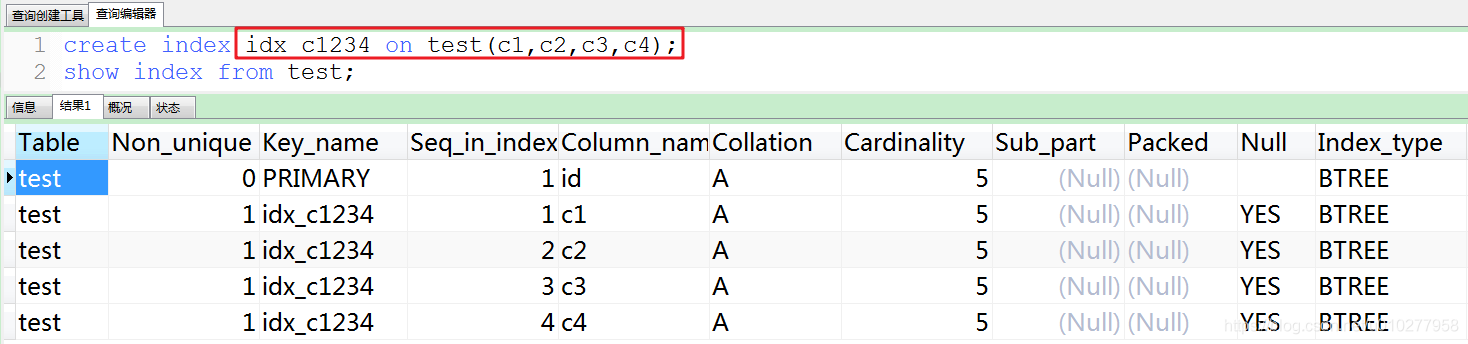
2.根据Case分析order by的使用情况
Case 1:

分析:
①在c1,c2,c3,c4上创建了索引,直接在c1上使用范围,导致了索引失效,全表扫描:type=ALL,ref=Null。因为此时c1主要用于排序,并不是查询。
②使用c1进行排序,出现了Using filesort。
③解决方法:使用覆盖索引。

Case 1.1:

分析:
排序时按照索引的顺序,所以不会出现Using filesort。
Case 1.2:
分析:

出现了Using filesort。原因:排序用的c2,与索引的创建顺序不一致,对比Case1.1可知,排序时少了c1(带头大哥),因此出现Using filesort。
Case 1.3:

分析:
出现了Using filesort。因为排序索引列与索引创建的顺序相反,从而产生了重排,也就出现了Using filesort。
Case 2:

 分析:
分析:
直接使用c2进行排序,出现Using filesort,因为不是从最左列索引开始排序的(没有带头大哥)。
Case 2.1:

分析:
排序使用了索引顺序(带头大哥在),因此不会出现Using filesort。
Case 2.2:

分析:
虽然排序的字段列与索引顺序一样,且order by默认升序,这里c2 desc变成了降序,导致与索引的排序方式不同,从而产生Using filesort。
3.总结
1.MySQL支持两种方式的排序filesort和index,Using index是指MySQL扫描索引本身完成排序。index效率高,filesort效率低。
2.order by满足两种情况会使用Using index。
- order by语句使用索引最左前列。
- 使用where子句与order by子句条件列组合满足索引最左前列。
3.尽量在索引列上完成排序,遵循索引建立(索引创建的顺序)时的最佳左前缀法则。
4.如果order by的条件不在索引列上,就会产生Using filesort。
5.提升order by速度的方式:
- 在使用order by时,不要用select *,只查询所需的字段。
- 尝试提高sort_buffer_size。
- 尝试提高max_length_for_sort_data。
6.附上一张从视频中截取出来的总结图。
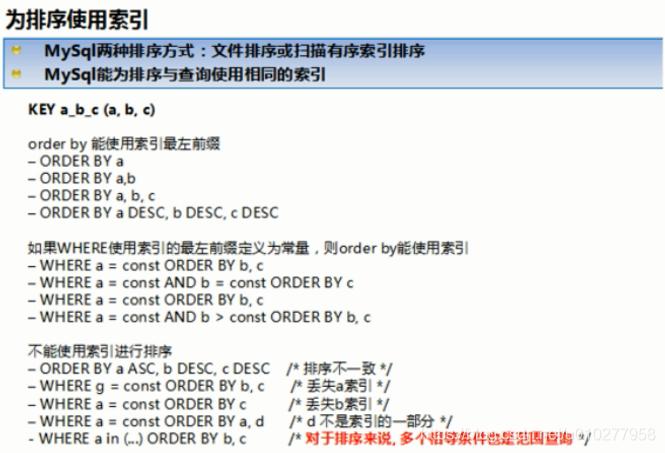
7.group by与order by很类似,其实质是先排序后分组,遵照索引创建顺序的最佳左前缀法则。当无法使用索引列的时候,也要对sort_buffer_size和max_length_for_sort_data参数进行调整。注意where高于having,能写在where中的限定条件就不要去having限定了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通