8行代码批量下载GitHub上的图片
【问题来源】
来打算写一个的小游戏,但是图片都在GitHub仓库中,GitHub网页版又没有批量下载图片的功能,只有单独一张一张的下载,所以自己就写了个爬虫脚本
模拟人的操作把整个页面上需要的图片爬取下来了。
图片网址: 点击此处跳转到图片仓库
下面截图比较多,可以点击图片查看高清截图!
[整体思路]
爬虫就是模拟人在网页上的操作,只是使用代码会比较快速,毕竟人点击鼠标的速度是有限的。
所以我们就先要看一下在GitHub上怎么下载一张图片,然后使用代码自动化去一张一张的下载全部内容。
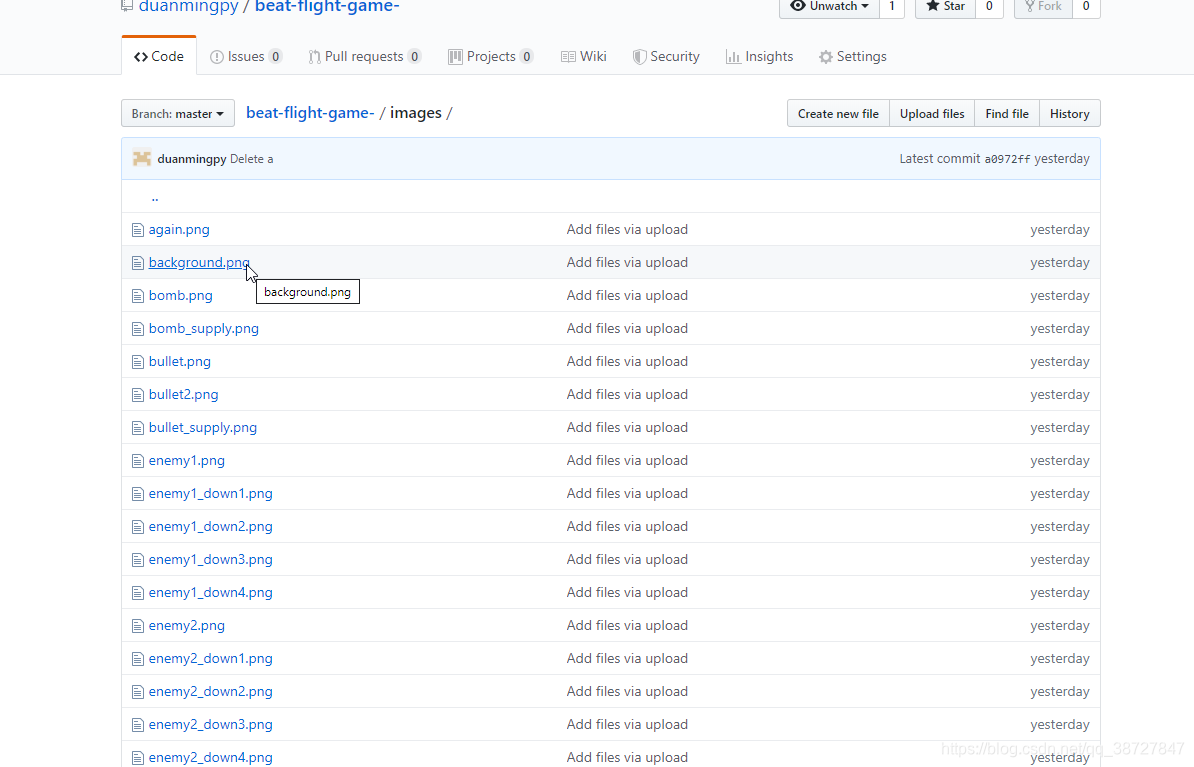
手动下载一张图片的操作就是进入图片仓库,点击一张图片名,然后点击Download按钮,操作步骤如下:
粘贴网址进入:
![在这里插入图片描述]()
点击想要下载的图片名:
![在这里插入图片描述]()
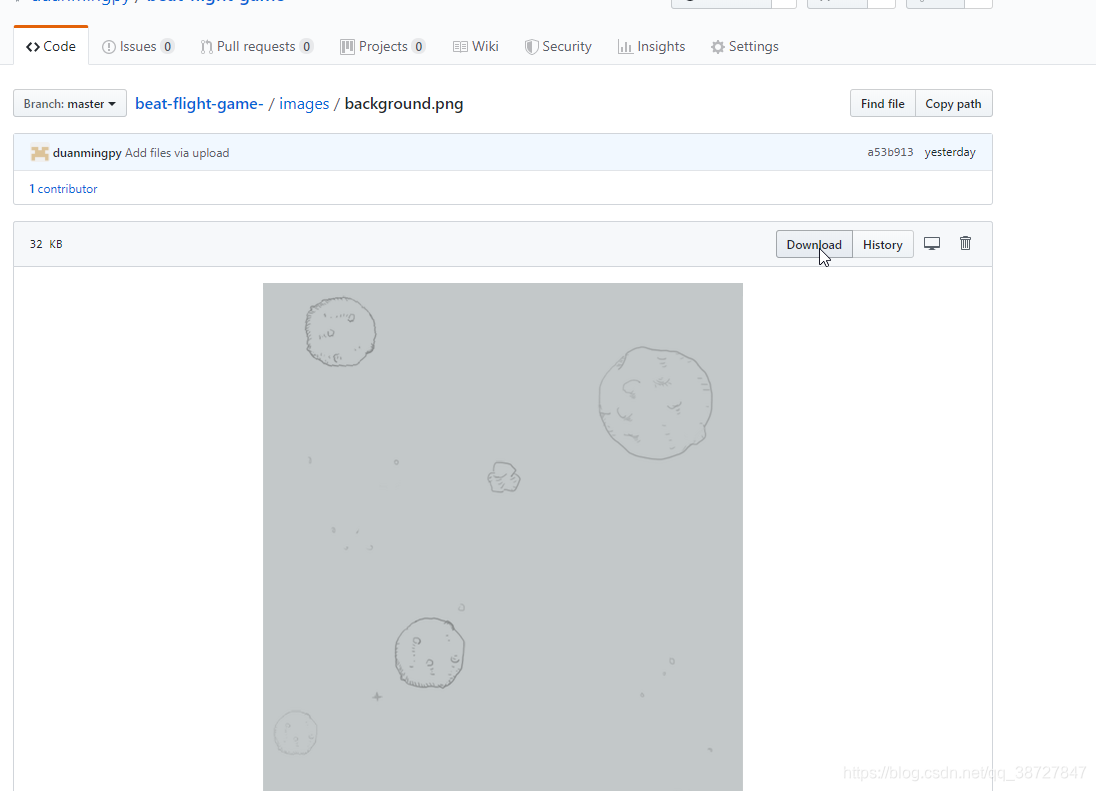
点击Download下载:
![在这里插入图片描述]()

下面我们要用代码模拟这个过程:
【图片仓库地址】
点击此处跳转到图片仓库,页面内总共有39张图片,我下面会详细介绍怎么去爬取这39张图片。
【所需工具】
chrome浏览器、pycharm
【前期准备】
1.首先第一步是打开这个网页,整体查看一下这个网页的概况,在一个图片名称上右键选择元素。这样会定位到在这个页面内,这个图片所代表的url地址。
2.接着第二步是通过检查我们把这个图片的点击链接复制下来,如下图,要选择复制HTML地址。

3.把刚刚复制的地址粘贴放在一个文本中,等下要分析这个东西。如下:
<a class=“js-navigation-open” title=“background.png” id=“9c1385517cbc8860981a2e72e3ad310f-24a041e8d54e0fff125a544ccd28616a44ecf226” href="/duanmingpy/beat-flight-game-/blob/master/images/background.png">background.png
我们把这段代码中的href后面的地址给分离出来(这个地址是不完整的), 我们等下要给它添加前面的网址文件,还要用代码自动替换后面的图片名,这样就可以进行批量自动化下载了,不完整的url地址如下:
“/duanmingpy/beat-flight-game-/blob/master/images/background.png”
4.我们再在页面中点击图片名进入到该图片的详细页面:
页面内图片链接地址:
5.点击之后会进入到下面这个界面,我们再右键点击Download选择检查:
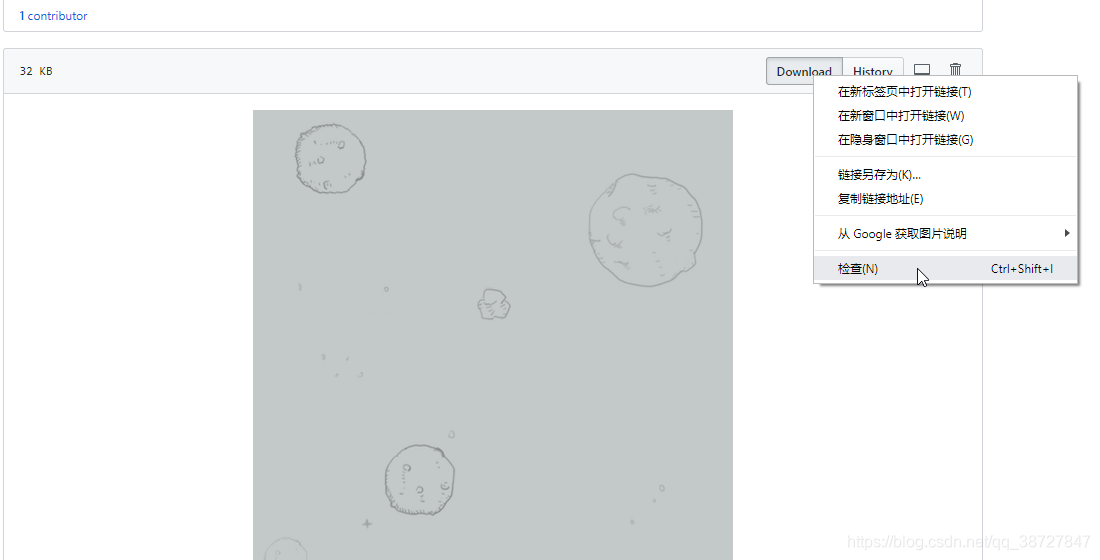
6.进入检查界面如下,复制对应这个下载按钮的url地址:
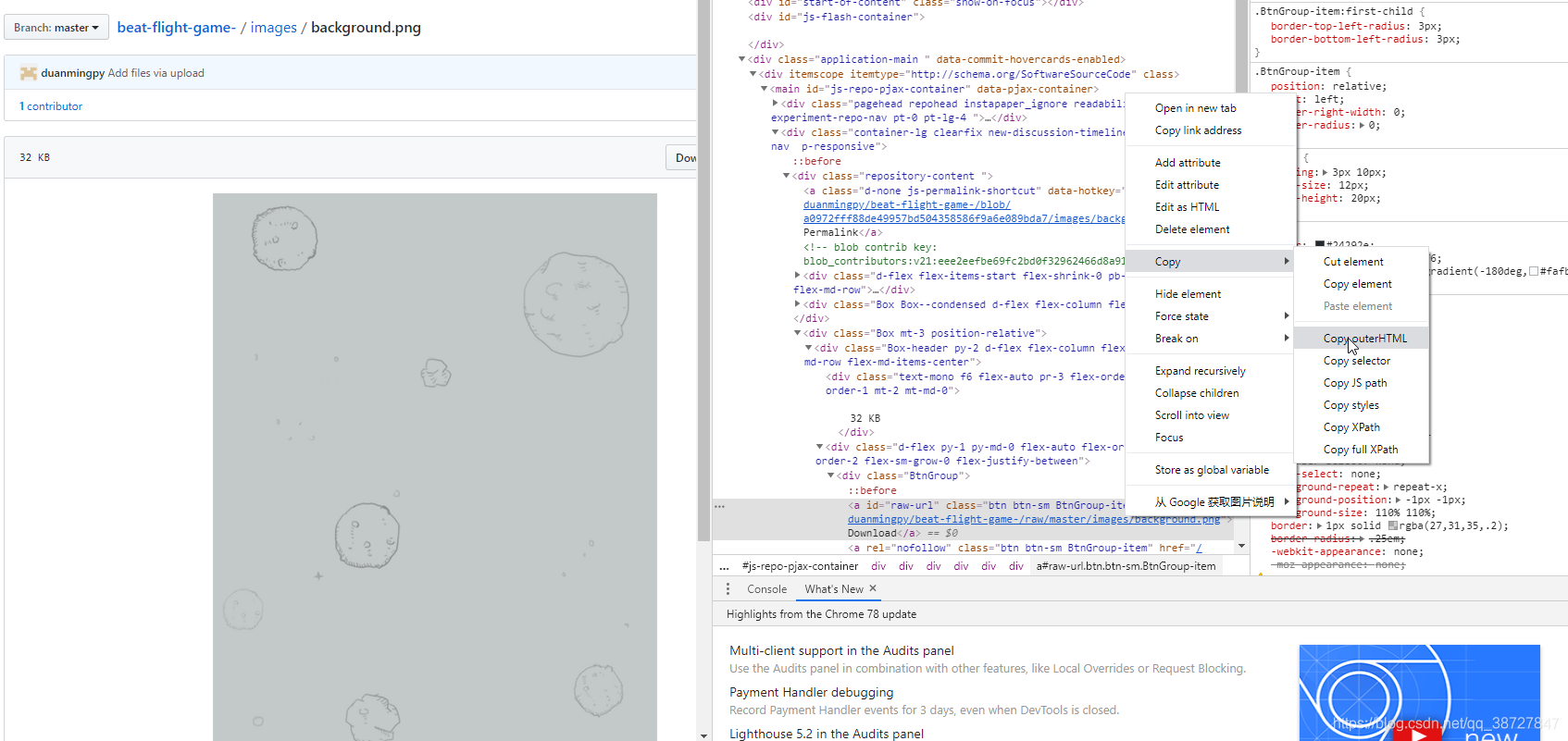
把复制的这段代码粘贴在同一个文本中:
<a id=“raw-url” class=“btn btn-sm BtnGroup-item” href="/duanmingpy/beat-flight-game-/raw/master/images/background.png">Download
我们要其中的href后面引号内的url地址:
“/duanmingpy/beat-flight-game-/raw/master/images/background.png”
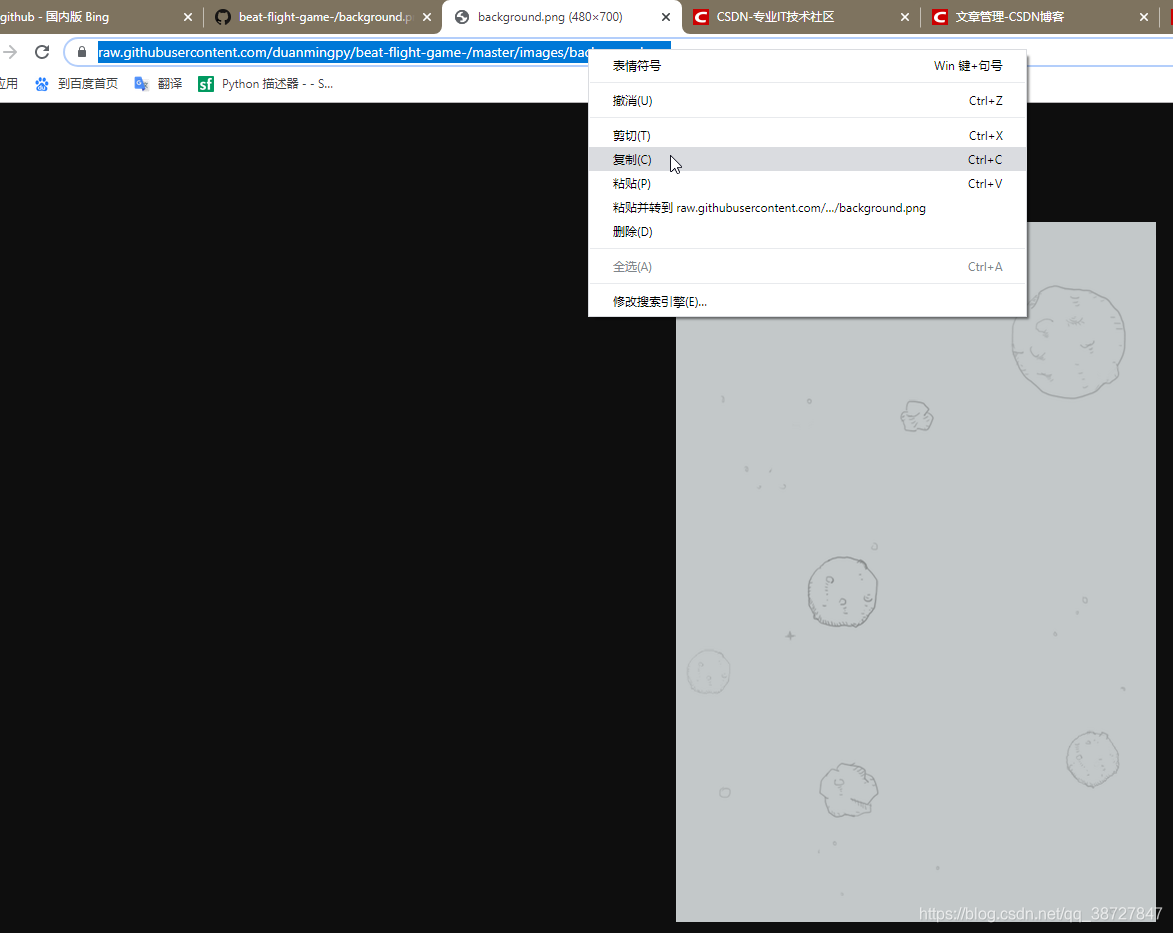
7.复制完之后,我们再点击一下这个url这时候会跳转一个新的网页,这里就称作是会把图片放大的网址吧,如下图, 我们把这个网址复制下来:
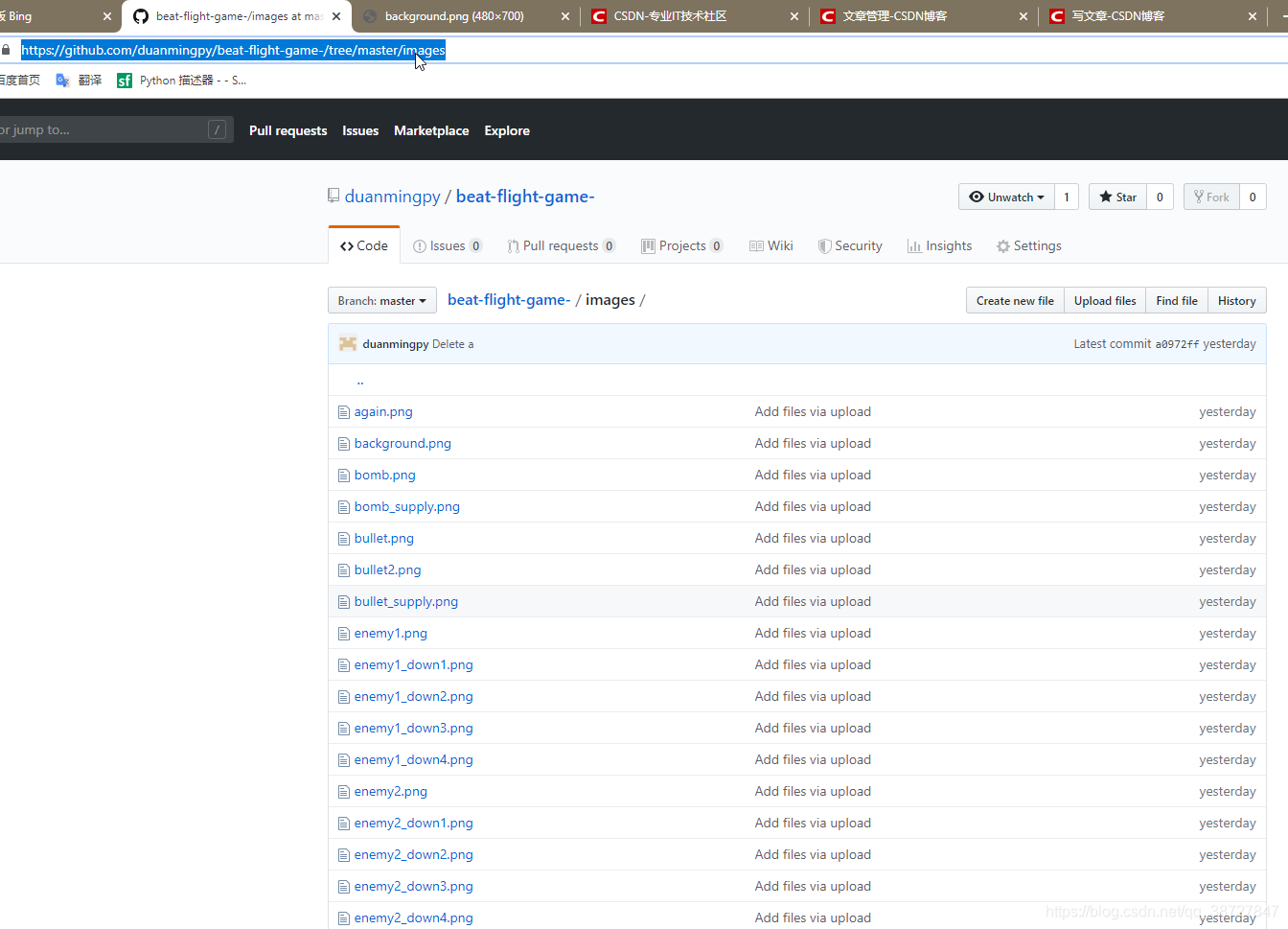
8. 我们接着回到最初的图片仓库点击此处跳转到图片仓库,复制这个图片仓库的地址:
- 然后我们把刚刚复制的
四个网址放在一起分析:
第一个网址是所有图片在一个页面内的时候的其中一张图片的url:
"/duanmingpy/beat-flight-game-/blob/master/images/background.png"
第二个是单独一张图片的Download按钮的url:
"/duanmingpy/beat-flight-game-/raw/master/images/background.png"
第三个是点击download对应的url会跳转出来的url网址:
https://raw.githubusercontent.com/duanmingpy/beat-flight-game-/master/images/background.png
第四个是图片仓库的地址:
https://github.com/duanmingpy/beat-flight-game-/tree/master/images
现在我们先把这四个网址放在这里,其中的相似之处想必已经明了。
[进入pycharm实验]
我们这里要用到的是python中的一个requests库,需要使用import requests 导入,这个库可以满足我们进行对指定网址的请求(访问)操作;
我们还需要一个re模块,这个是python的内置正则匹配的一个库,同样需要import re导入使用。
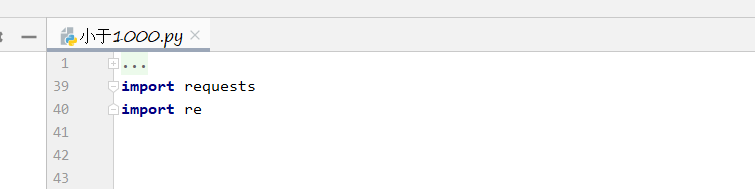
紧接着我们要使用requests库中的get进行请求网址,get可以请求到很多内容,但是我们需要的并不多,先看例子:
首先我们在get方法中填入图片仓库的url,即https://github.com/duanmingpy/beat-flight-game-/tree/master/images,然后把返回值赋值给results, 再通过text打印出来:

通过上图我们可以发现,我们拿到了图片仓库页面的所有源代码,这里面就有所有的图片的url,我们接着需要使用正则表达式把我们需要的url匹配出来。
这个时候我们可以回头看一下我们上面复制的url中的第一个,单独一张图片的url样式是:/duanmingpy/beat-flight-game-/blob/master/images/background.png, 每张图片只有.png前面的名字不同,我们可以使用这样一个正则表达式:"/duanmingpy/beat-flight-game-/blob/master/images/\w+\.png"来匹配results.txt中的所有图片的url,(其中的\w+表示的是出现至少一次字母数下划线,用来匹配图片名称,\.用来匹配一个.)。
代码如下,匹配到的url存在一个列表中:
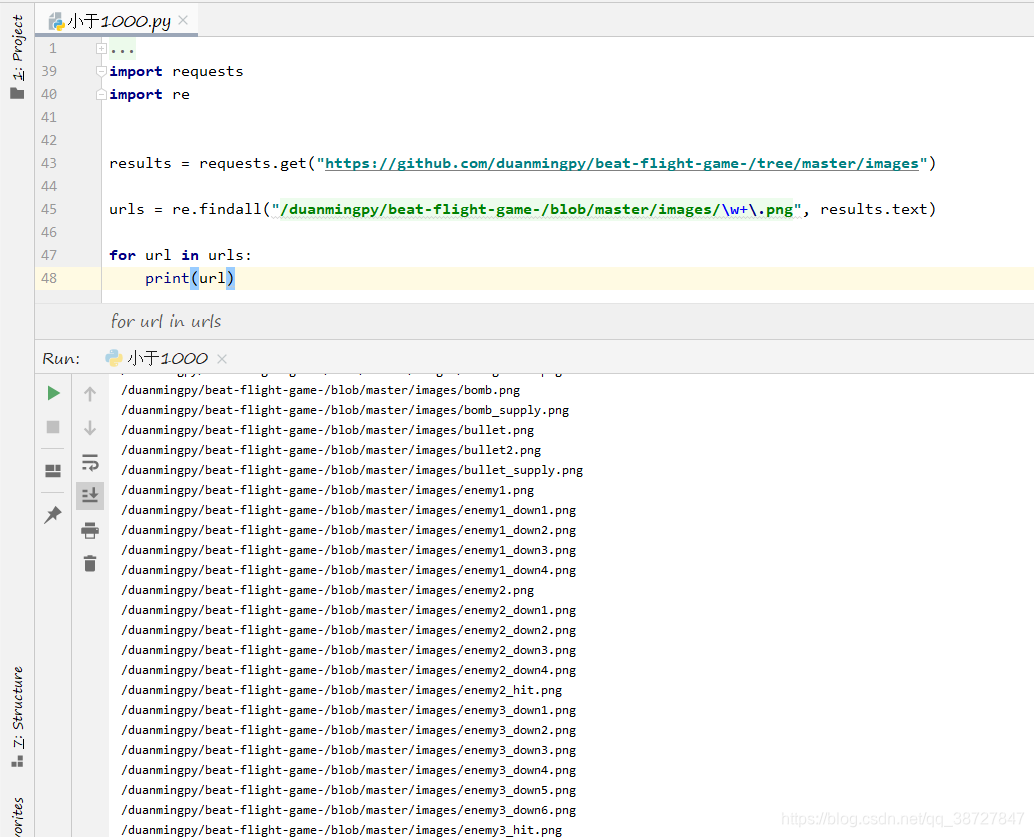
可以看到我们成功的拿到了每个图片的url。
然后我们测试一下刚刚复制的四个url中的第三个("https://raw.githubusercontent.com/duanmingpy/beat-flight-game-/master/images/background.png"),点击Download对应的url跳出的网页的地址,试试这个网址我们可以请求到什么:

我们可以看到,拿到的是一串bytes,其实这个就是一个图片的编码,我们只要把这串编码以二进制形式存入文件,并且设置文件的后缀为png就可以点开查看了:
我们把这个二进制串存入文件并打开查看:
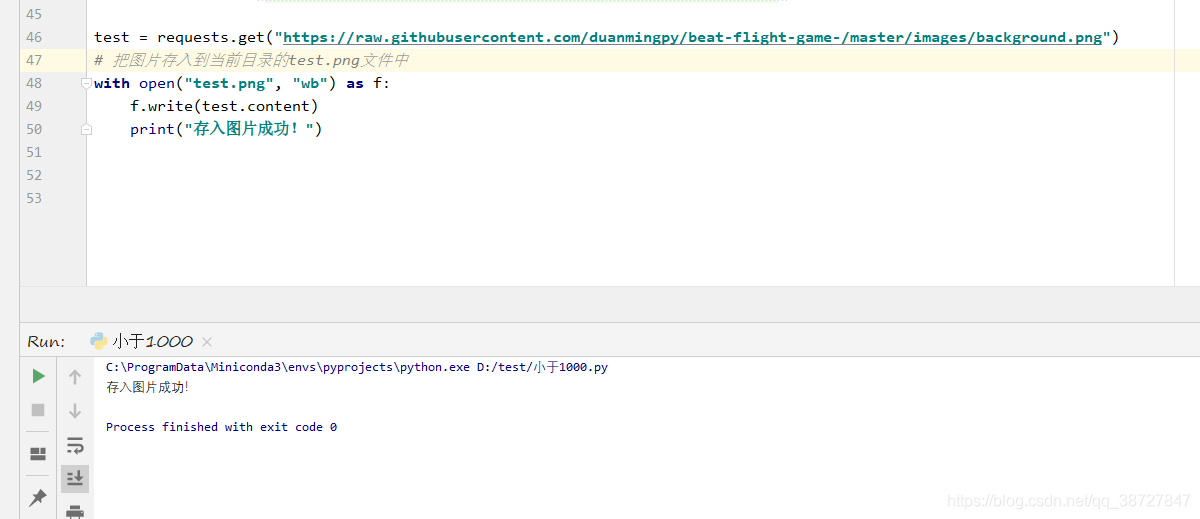
存入成功,查看一下:

到这里并没有结束,翻到上面,我们仔细看一下我们在text中匹配的每个url和当前这个能够保存图片的url(https://raw.githubusercontent.com/duanmingpy/beat-flight-game-/master/images/background.png)有什么区别:我们可以清楚的看到,我们需要为刚才匹配的各个url添加前缀网址,还要删除/blob这个字段, 使用循环处理每个网址:
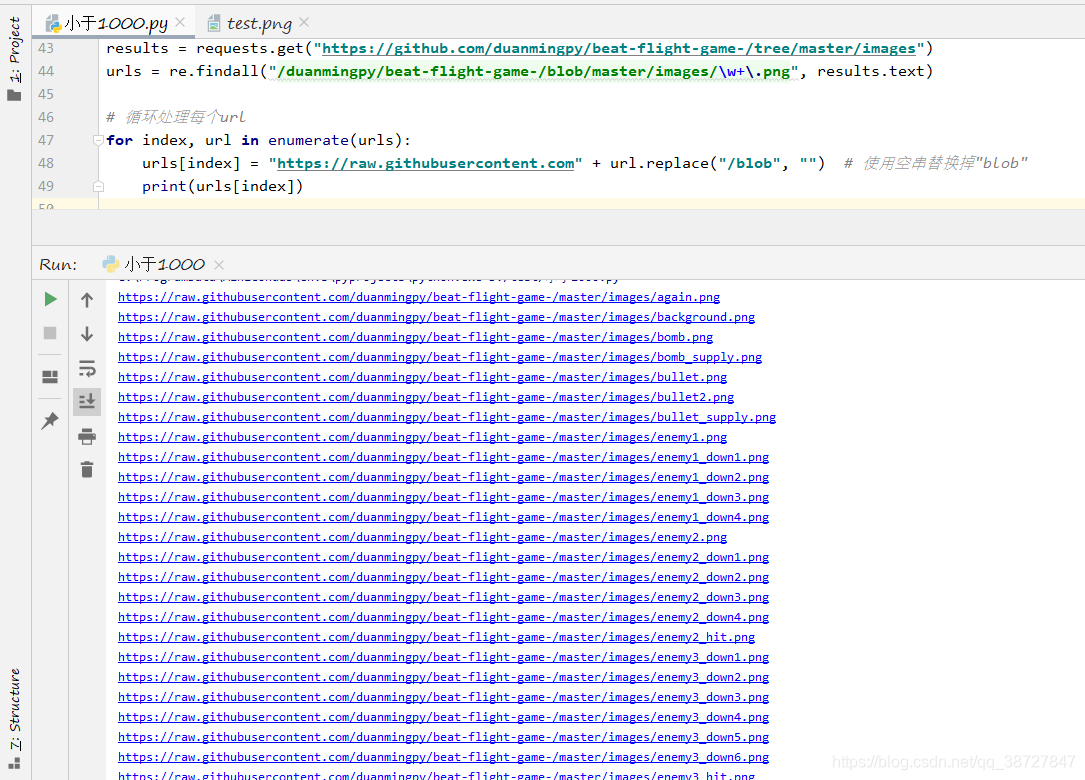
这时候我们看到,每个url都有了前缀并去掉了/blob,可以用作下载图片使用了,这时候我们循环遍历这个存放处理后的url,让它能够自动get图片并且自动存入到指定文件夹:
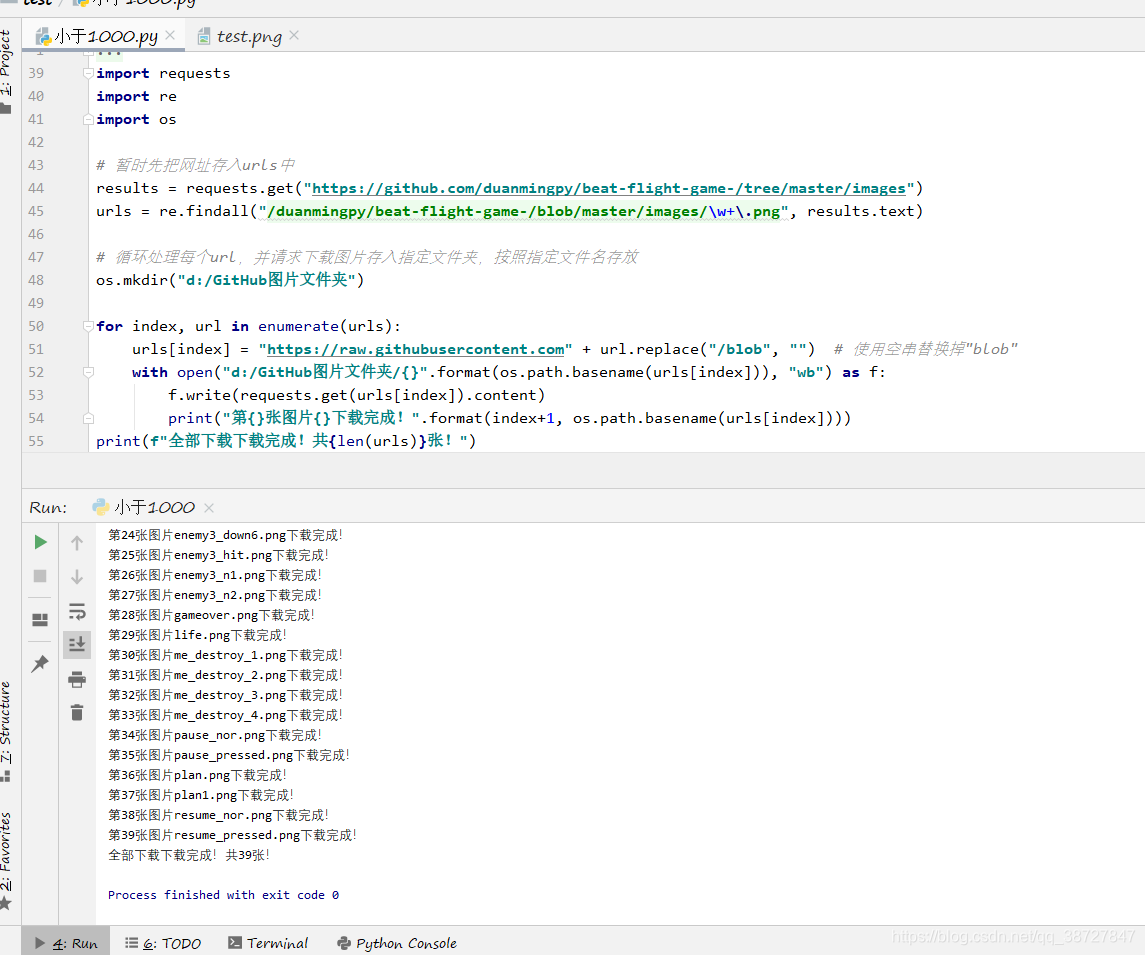
如上图,所有图片都已下载到d盘文件夹下,我们打开看一下:
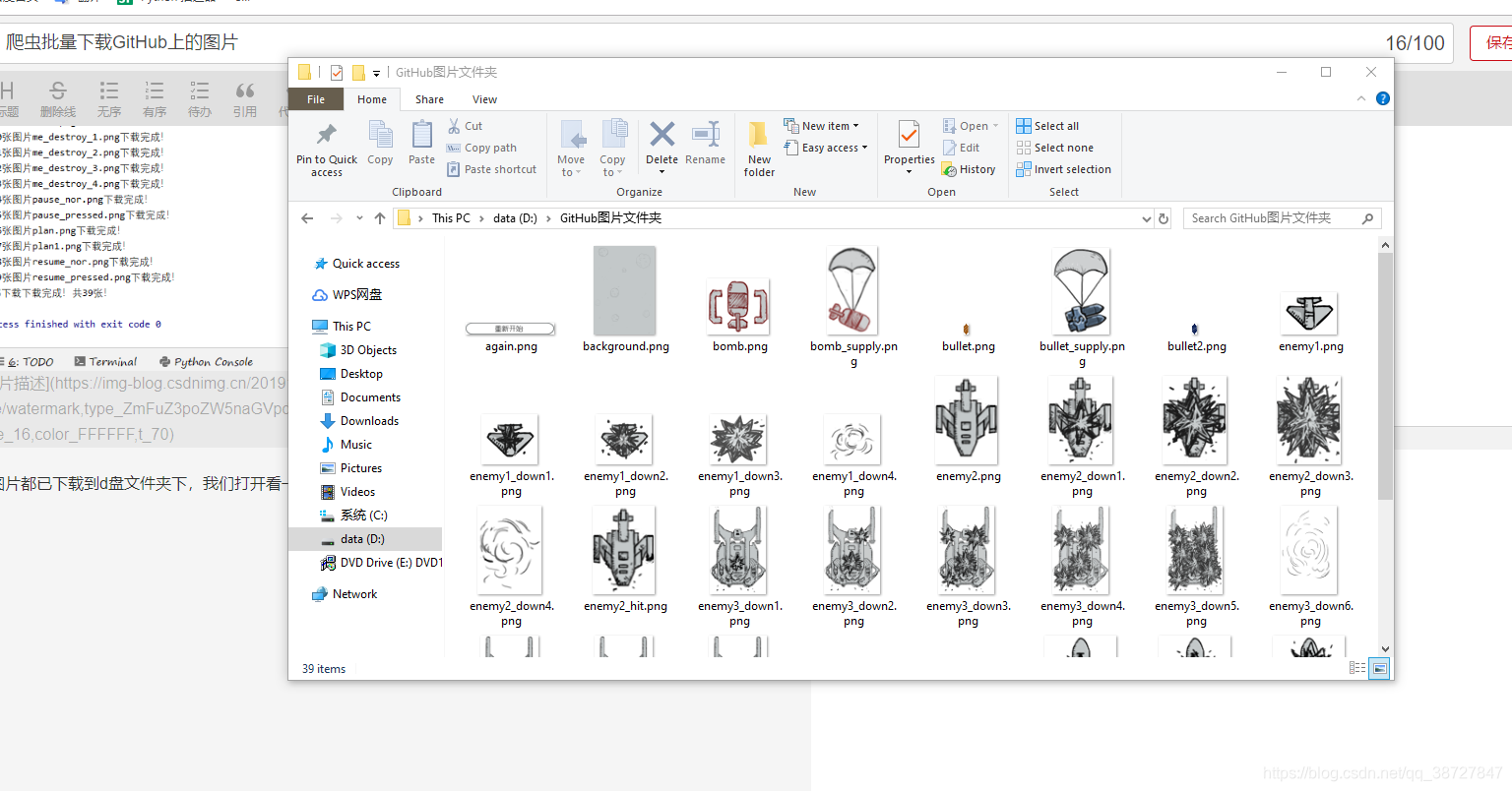
【完成!】用到的都是一些基础的知识。 总代码还不到十行,如果有看不懂的小伙伴可以加下面的群找我讲解,大家共同交流进步!
上面我们复制的四个地址中,只用到了两个,其实在分析的时候是需要四个进行比对的,这里我已经知道了规律所以没有进行比较分析,可以通过这个方式简单爬取一些其他网站的图片或者文字。
欢迎小伙伴们加入我创建的python交流群:625988679


 浙公网安备 33010602011771号
浙公网安备 33010602011771号