kafka实时数据流写入HDFS
一、摘要
impala作为实时数据分析引擎,其源数据时效性要求不同,主要分为离线数据分析和实时数据分析。离线数据分析应用场景下,可以利用hive离线加载数据。实时数据分析则依靠kafka(高吞吐量的消息发布订阅系统)。
二、kafka介绍
kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。
组件:
- producer:生产者。
- consumer:消费者。
- topic: 消息以topic为类别记录,Kafka将消息种子(Feed)分门别类,每一类的消息称之为一个主题(Topic)。
- broker:以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker;消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
每个消息(也叫作record记录,也被称为消息)是由一个key,一个value和时间戳构成。
主题和日志
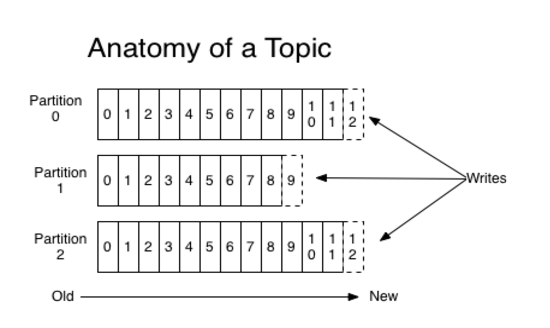
每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
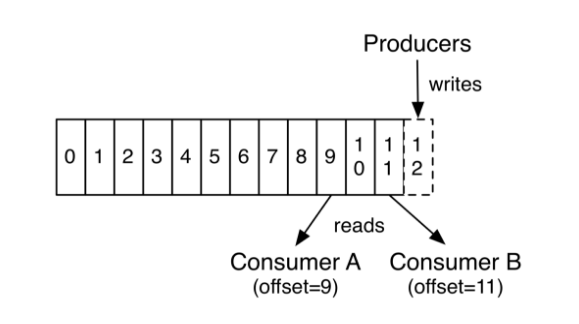
Kafka集群保持所有的消息,直到它们过期, 无论消息是否被消费了。 实际上消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。 这个偏移量由消费者控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。 可以看到这种设计对消费者来说操作自如, 一个消费者的操作不会影响其它消费者对此log的处理。 再说说分区。Kafka中采用分区的设计有几个目的。一是可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。第二,分区可以作为并行处理的单元
Geo-replication(异地数据同步技术)
geo-replication支持。借助MirrorMaker,消息可以跨多个数据中心或云区域进行复制。 您可以在active/passive场景中用于备份和恢复; 或者在active/passive方案中将数据置于更接近用户的位置,或数据本地化。生产者(producer)
消费者(consumer)
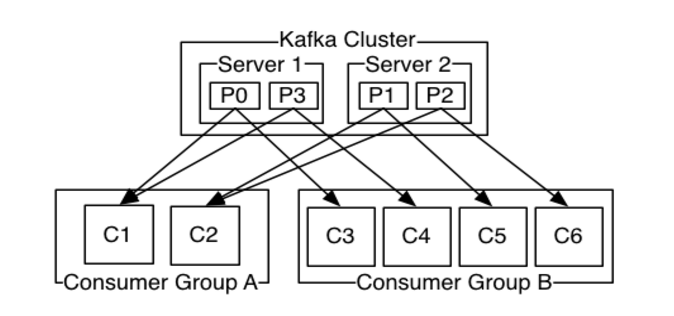
2个kafka集群托管4个分区(P0-P3),2个消费者组,消费组A有2个消费者实例,消费组B有4个。
正像传统的消息系统一样,Kafka保证消息的顺序不变。 再详细扯几句。传统的队列模型保持消息,并且保证它们的先后顺序不变。但是, 尽管服务器保证了消息的顺序,消息还是异步的发送给各个消费者,消费者收到消息的先后顺序不能保证了。这也意味着并行消费将不能保证消息的先后顺序。用过传统的消息系统的同学肯定清楚,消息的顺序处理很让人头痛。如果只让一个消费者处理消息,又违背了并行处理的初衷。 在这一点上Kafka做的更好,尽管并没有完全解决上述问题。 Kafka采用了一种分而治之的策略:分区。 因为Topic分区中消息只能由消费者组中的唯一一个消费者处理,所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。 所以,如果你想要顺序的处理Topic的所有消息,那就只提供一个分区。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号