
java传统集合的一些弊病以及解决办法
一、HashSet和HashMap有和联系?我们可以看看源码:
在HashSet的源码里,我们可以看到如下一些代码:
看到这里,便可知道:HashSet其实质也就是一个Map,只不过没有使用到其中的value值而已
二、传统集合的弊病
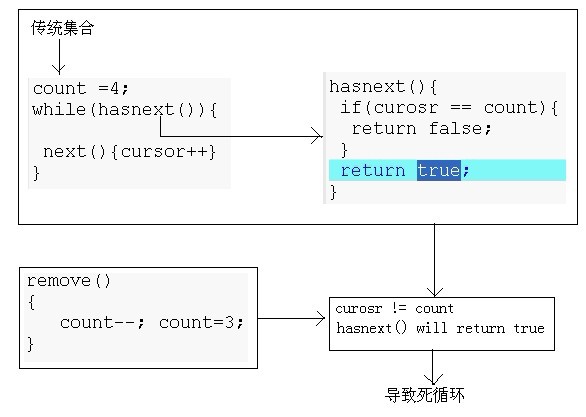
1、 容易导致死循环
2、 容易报异常,导致程序中断
看如下三段代码以及输出情况:
(1)、
输出:

(2)、
输出:

(3)、
打印:

观察上面三种情况,第一和第三都抛出异常,程序中断;第二程序没有抛出异常,却没有我们理想的运行结果。下面,我来仔细分析一下这三种情况的运行现象:
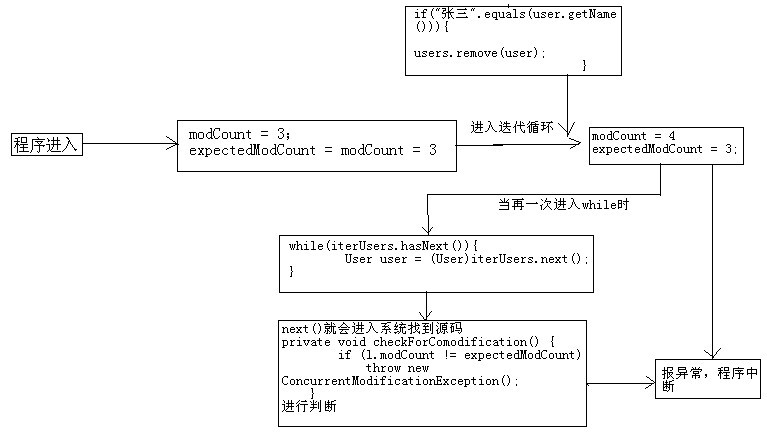
第一种:当我们删除张三的时候可以看到报异常的是:
这里报错,进入源码一看:
报错的是这里,这里表示的模块的计数与预期的计数不相等的时候,就会抛出这个异常,那这两个计数是怎么回事呢?接着看AbstractList.java源码:
可以发现预期的计数是内部类迭代器的一个成员变量,而模块的计数是外部类AbstractList.java的一个成员变量,接下来我们看看modCount是怎么赋值的。
modCount模块计数相当于一个版本号,只要一有与数据相关的操作,不论是增加还是删除,都会自增1。例如,我在程序中增加n条数据,又删除两条数据,则modCount为(n+2)。于是我们的第一种情况可以如下图所示:
第二种:当我们删除李四的时候为什么没报异常呢?
当我们循环到李四的时候,可以看到AbstractList源码的next()上面有一个hashNext方法:
其中size一开始等于3,cursor有三条数据,为0、1、2;当我们取到李四的时候,cursor=1,这个时候把李四删掉,于是size便为2,然后返回,这个时候cursor有自增1,便为2,又进入while进行循环,判断发现返回false,于是程序便由此完成了,于是只打印张三
第三种情况:
当我们循环到王五的时候,cursor=2;这个时候删掉王五,于是size便为2,然后返回,这个时候cursor有自增1,便为3,又进入while进行循环,判断发现返回true(形成了1中的死循环),于是又执行到while内部,于是执行next方法,比较版本,发现异常,于是报错,程序终止。
通过以上三种情况可以得知:在传统线程迭代的时候,不要对数据进行操作,否则会发生错误;在next()方法中,内部会对集合做一个版本的比较,然后来决定是否报出异常。
三、解决以上弊病的方法
通过二中可以知道传统集合的一些弊病,那么下面用两种方法来解决这个问题:
1、 传统的方法
造成上面的错误的原因,其根本就是我们在读数据的时候同时又对他进行了写的操作,并且没有做同步处理,于是出现了数据的混乱,于是加上同步处理,便能解决这个问题。使用Collections.synchorinizedMap(Map<K,V) m){}方法,便可以返回一个同步的集合,其中SynchorinizedMap内部实现的方法也非常的简单,实现Map接口,然后将Map中的所有的方法都放在一个同步块里面,使用相同的对象锁即可。
2、 使用同步集合
查看java.util.concurrent包下可以查看到一些常见的同步集合
l ConcurrentHashMap
l CopyOnWriteArrayList
l CopyOnWriteArraySet
后面两个类在写的时候将会有一份拷贝,防止出错。
于是我们只需要将前面的代码稍微修改:
posted on 2012-04-11 20:45 duancanmeng 阅读(198) 评论(0) 编辑 收藏 举报


