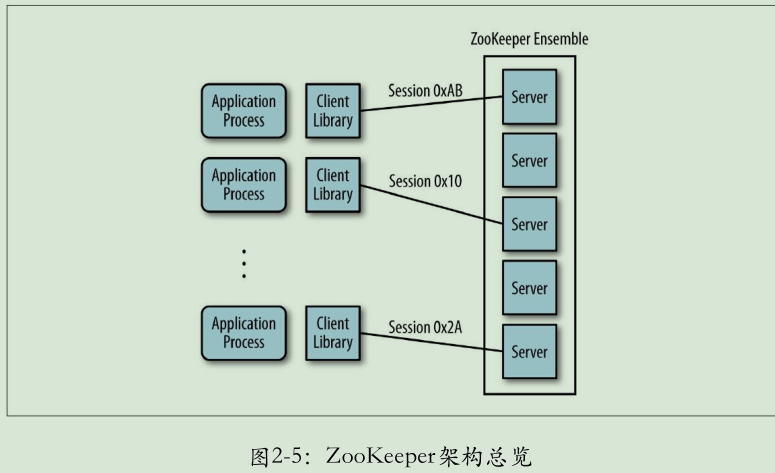
ZooKeeper服务器端运行于两种模式下:独立模式(standalone)和仲裁模式(quorum)。独立模式几乎与其术语所描述的一样:有一个单独的服务器,ZooKeeper状态无法复制。在仲裁模式下,具有一组ZooKeeper服务器,我们称为ZooKeeper集合(ZooKeeper ensemble),它们之前可以进行状态的复制,并同时为服务于客户端的请求。从这个角度出发,我们使用术语“ZooKeeper集合”来表示多个服务器设施,这个设施可以由独独模式的一个服务器组成,也可以仲裁模式下的多个服务器组成。
1.1.1 ZooKeeper仲裁
在仲裁模式下,ZooKeeper复制集群中的所有服务器的数据树。但如果让一个客户端等待每个服务器完成数据保存后再继续,延迟问题将无法接受。在公共管理领域,法定人数是指进行一项投票所需的立法者的最小数量。而在ZooKeeper中,则是指为了使ZooKeeper工作必须有效运行的服务器的最小数量。这个数字也是服务器告知客户端安全保存数据前,需要保存客户端数据的服务器的最小个数。例如,我们一共有5个ZooKeeper服务器,但法定个数为3个,这样,只要任何3个服务器保存了数据,客户端就可以继续,而其他两个服务器最终也将捕获到数据,并保存数据。
为了明白这到底是什么意思,让我们先来通过一个例子来看看,如果法定人数太小,会如何出错。假设有5个服务器并设置法定人数为2,现在服务器s 1 和s 2 确认它们需要对一个请求创建的znode/z进行复制,服务返回客户端,指出znode创建完成。现在假设在复制新的znode到其他服务器之前,服务器s 1 和s 2 与其他服务器和客户端发生了长时间的分区隔离,整个服务的状态仍然正常,因为基于我们的假设设定法定人数为2,而现在还有3个服务器,但这3个服务器将无法发现新的znode/z。因此,对创建节点/z的请求是非持久化的。
通过使用多数方案,我们就可以容许f个服务器的崩溃,在这里,f为小于集合中服务器数量的一半。例如,如果有5个服务器,可以容许最多f=2个崩溃。在集合中,服务器的个数并不是必须为奇数,只是使用偶数会使得系统更加脆弱。假设在集合中使用4个服务器,那么多数原则对应的数量为3个服务器。然而,这个系统仅能容许1个服务器崩溃,因为两个服务器崩溃就会导致系统失去多数原则的状态。因此,在4个服务器的情况下,我们仅能容许一个服务器崩溃,而法定人数现在却更大,这意味着对每个请求,我们需要更多的确认操作。底线是我们需要争取奇数个服务器
1.1.2会话
在对ZooKeeper集合执行任何请求前,一个客户端必须先与服务建立会话。会话的概念非常重要,对ZooKeeper的运行也非常关键。客户端提交给ZooKeeper的所有操作均关联在一个会话上。当一个会话因某种原因而中止时,在这个会话期间创建的临时节点将会消失。
当客户端通过某一个特定语言套件来创建一个ZooKeeper句柄时,它就会通过服务建立一个会话。客户端初始连接到集合中某一个服务器或一个独立的服务器。客户端通过TCP协议与服务器进行连接并通信,但当会话无法与当前连接的服务器继续通信时,会话就可能转移到另一个服务器上。ZooKeeper客户端库透明地转移一个会话到不同的服务器
1.1.3开始使用ZooKeeper
开始之前,需要下载ZooKeeper发行包。ZooKeeper作为Apache项目托管到http://zookeeper.apache.org。通过下载链接,你会下载到一个名字类似zookeepe-3.4.5.tar.gz的压缩TAR格式问件。在Linux、Mac OS X或任何其他类UNIX系统上,可以通过以下命令解压缩发行包:
tar -xvzf zookeeper-3.4.5.tar.gz
1.1.4第一个ZooKeeper会话
首先我们以独立模式运行ZooKeeper并创建一个会话。要做到这一点,使用ZooKeeper发行包中bin/录下的zkServer和zkCli工具。有经验的管理员常常使用这两个工具来进行调试和管理,同时也非常适合初学者熟悉和了解ZooKeeper
假设你已经下载并解压了ZooKeeper发行包,进入shell,变更目录cd)到项目根目录下,重命名配置文件:
mv conf/zoo_sample.cfg conf/zoo.cfg
最好把data目录移出/tmp目录,防止zookeeper填满了根分区。可以在zoo.cfg文件中修改这个目录的位置
dataDir=/user/me/zookeeper
启动服务器
bin/zkServer.sh start
这个服务器命令使得ZooKeeper服务器在后台中运行。如果在前台中运行以便查看服务器的输出,可以通过以下命令运行
bin/zkServer.sh start-foreground
这个选项提供了大量详细信息的输出,以便允许查看服务器发生了什么
启动客户端
在另一个shell中进入项目根目录,运行一下命令:
bin/zkCli.sh

为了更加了解ZooKeeper,让我们列出根(root)下的所有znode,然后创建一个znode。首先我们要确认此刻znode树为空,除了节点/zookeeper之
外,该节点内标记了ZooKeeper服务所需的元数据树。
ls /
创建节点
create /workers ""
当创建/workers节点后,我们指定了一个空字符串(""),说明我们此刻不希望在这个znode中保存数据。然而,该接口中的这个参数可以使我们保存任何字符串到ZooKeeper的节点中。比如,可以替换""为"workers"。
[zk: localhost:2181(CONNECTED) 3] delete /workers
[zk: localhost:2181(CONNECTED) 4] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 5] quit
Quitting...
2012-12-06 12:28:18,200 [myid:] - INFO [main-EventThread:ClientCnxn$
EventThread@509] - EventThread shut down
2012-12-06 12:28:18,200 [myid:] - INFO [main:ZooKeeper@684] - Session:
0x13b6fe376cd0000 closed
观察到znode/workers已经被删除,并且会话现在也关闭。为了完成最
后的清理,退出ZooKeeper服务器
# bin/zkServer.sh stop
JMX enabled by default
Using config: ../conf/zoo.cfg
Stopping zookeeper ... STOPPED
1.1.5会话的状态和声明周期
会话的生命周期(lifetime)是指会话从创建到结束的时期,无论会话正常关闭还是因超时导导致过期。为了讨论在会话中发生了什么,我们需要考虑会话可能的状态,以及可能导致会话状态改变的事件
一个会话的主要可能状态⼤多是简单明了的:CONNECTING、CONNECTED、CLOSED和NOT_CONNECTED。状态的转换依赖于发⽣在客户端与服务之间的各种事件(见图2-6)
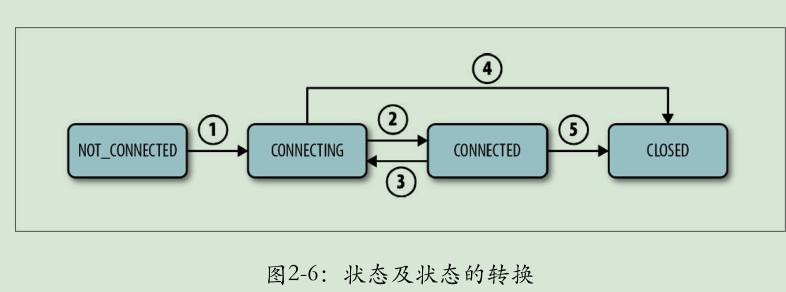
一个会话从NOT_CONNECTED状态开始,当ZooKeeper客户端初始化后转换到CONNECTING状态(图2-6中的箭头1)。正常情况下,成功与ZooKeeper服务器建立连接后,会话转换到CONNECTED状态(箭头2)。当客户端与ZooKeeper服务器断开连接或者无法收到服务器的响应时,它就会转换回CONNECTING状态(箭头3)并尝试发现其他ZooKeeper服务器。如果可以发现另一个服务器或重连到原来的服务器,当服务器确认会话有效后,状态又会转换回CONNECTED状态。否则,它将会声明会话过期然后转换到CLOSED状态(箭头4)。应用也可以显式地关闭会话(箭头4和箭头5)。
注意:发生网络分区时等待CONNECTING
如果一个客户端与服务器因超时断开连接,客户端仍然保持
CONNECTING状态。如果因网络分区问题导致客户端与ZooKeeper集合被
隔离而发生连接断开,那么其状态将会一直保持,直到显式地关闭这个会
话,或者分区问题修复后,客户端能够获悉ZooKeeper服务器发送的会话
已经过期。发生这种行为是因为ZooKeeper集合对声明会话超时负责,而
不是客户端负责。直到客户端获悉ZooKeeper会话过期,否则客户端不能
声明自己的会话过期。然而,客户端可以选择关闭会话。
创建一个会话时,你需要设置会话超时这个重要的参数,这个参数设置了ZooKeeper服务允许会话被声明为超时之前存在的时间。如果经过时间t之后服务接收不到这个会话的任何消息,服务就会声明会话过期。而在客户端侧,如果经过t/3的时间未收到任何消息,客户端将向服务器发送心跳消息。在经过2t/3时间后,ZooKeeper客户端开始寻找其他的服务器,而此时它还有t/3时间去寻找。
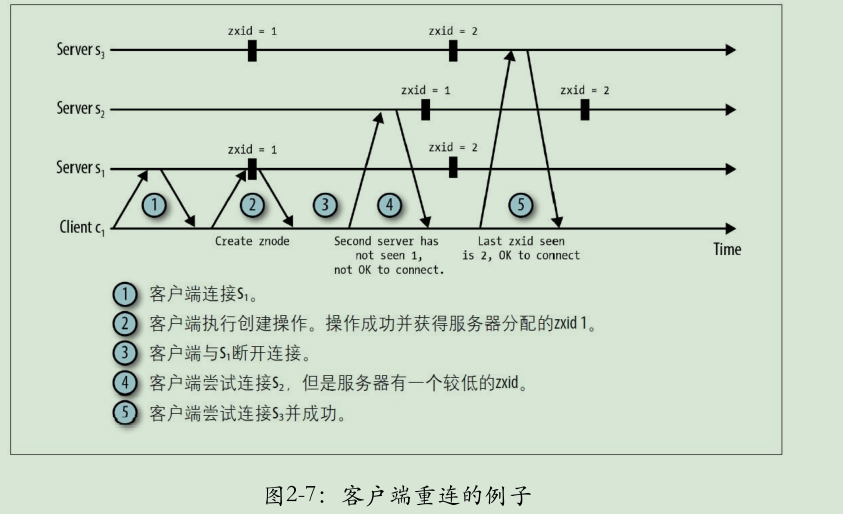
当尝试连接到一个不同的服务器时,非常重要的是,这个服务器的ZooKeeper状态要与最后连接的服务器的ZooKeeper状态保持最新。客户端不能连接到这样的服务器:它未发现更新而客户端却已经发现的更新。ZooKeeper通过在服务中排序更新操作来决定状态是否最新。ZooKeeper确保每一个变化相对于所有其他已执行的更新是完全有序的。因此,如果一个客户端在位置i观察到一个更新,它就不能连接到只观察到i'<i的服务器上。在ZooKeeper实现中,系统根据每一个更新建立的顺序来分配给事务标识符。 图2-7描述了在重连情况下事务标识符(zkid)的使用。当客户端因超时与s 1 断开连接后,客户端开始尝试连接s 2 ,但s 2 延迟于客户端所知的变化。然而,s 3 对这个变化的情况与客户端保持一致,所以s 3 可以安全连接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号