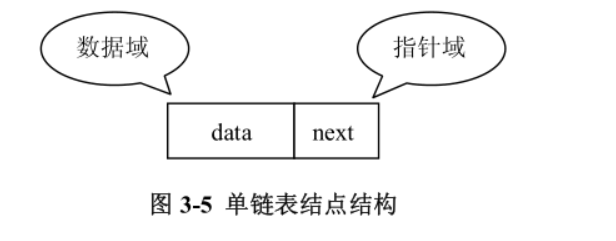
链表是一系列的存储数据元素的单元通过指针串接起来形成的,因此每个单元至少有两
个域,一个域用于数据元素的存储,另一个域是指向其他单元的指针。这里具有一个数据域
和多个指针域的存储单元通常称为 结点(node)在 Java 中没有显式的指针类型,然而实际上对象的访问就是使用指针来实现的,即在
Java 中是使用对象的引用来替代指针的。因此在使用 Java 实现该结点结构时,一个结点本
身就是一个对象。结点的数据域 data 可以使用一个 Object 类型的对象来实现,用于存储任
何类型的数据元素,并通过对象的引用指向该元素;而指针域 next 可以通过节点对象的引
用来实现。
由于数据域存储的也是对象引用,因此数据实际上和图 3-2 中一样,是通过指向数据的
物理存储地址来完成存储的,但是在后面叙述的方便,我们在图示中都将数据元素直接画到
了数据域中,请读者注意实际的状态与之是有区别的。
上面的单链表结点结构是结点的一种最简单的形式,除此之外还有其他不同的结点结
构,但是这些结点结构都有一个数据域,并均能完成数据元素的存取。为此在使用 Java 定
义单链表结点结构之前先给出一个结点接口,在接口中定义了所有结点均支持的操作,即对
结点中存储数据的存取。
节点接口
public interface Node { //获取结点数据域 public Object getData(); //设置结点数据域 public void setData(Object obj); }
单链表节点
public class SLNode implements Node { private Object element; private SLNode next; public SLNode() { this(null,null); } public SLNode(Object ele, SLNode next){ this.element = ele; this.next = next; } public SLNode getNext(){ return next; } public void setNext(SLNode next){ this.next = next; } /**************** Methods of Node Interface **************/ public Object getData() { return element; } public void setData(Object obj) { element = obj; } }
单链表实现
public class ListSLinked implements List{ private SLNode head; //单链表首结点引用 private int size; //线性表中数据元素的个数 public ListSLinked () { head = new SLNode(); size = 0; } //辅助方法:获取数据元素 e 所在结点的前驱结点 private SLNode getPreNode(Object e){ SLNode p = head; while (p.getNext()!=null) if (p.getNext().getData().equals(e)) return p; else p = p.getNext(); return null; } //辅助方法:获取序号为 0<=i<size 的元素所在结点的前驱结点 private SLNode getPreNode(int i){ SLNode p = head; for (; i>0; i--) p = p.getNext(); return p; } //获取序号为 0<=i<size 的元素所在结点 private SLNode getNode(int i){ SLNode p = head.getNext(); for (; i>0; i--) p = p.getNext(); return p; } //返回线性表的大小,即数据元素的个数。 public int getSize() { return size; } //如果线性表为空返回 true,否则返回 false。 public boolean isEmpty() { return size==0; } //判断线性表是否包含数据元素 e public boolean contains(Object e) { SLNode p = head.getNext(); while (p!=null) if (p.getData().equals(e)) return true; else p = p.getNext(); return false; } //返回数据元素 e 在线性表中的序号 public int indexOf(Object e) { SLNode p = head.getNext(); int index = 0; while (p!=null) if (p.getData().equals(e)) return index; else {index++; p = p.getNext();} return -1; } //将数据元素 e 插入到线性表中 i 号位置 public void insert(int i, Object e) throws IndexOutOfBoundsException { if (i<0||i>size) throw new IndexOutOfBoundsException("错误,指定的插入序号越界。"); SLNode p = getPreNode(i); SLNode q = new SLNode(e,p.getNext()); p.setNext(q); size++; return; } //删除线性表中序号为 i 的元素,并返回之 public Object remove(int i) throws IndexOutOfBoundsException { if (i<0||i>=size) throw new IndexOutOfBoundsException("错误,指定的删除序号越界。"); SLNode p = getPreNode(i); Object obj = p.getNext().getData(); p.setNext(p.getNext().getNext()); size--; return obj; } //删除线性表中第一个与 e 相同的元素 public boolean remove(Object e) { SLNode p = getPreNode(e); if (p!=null){ p.setNext(p.getNext().getNext()); size--; return true; } return false; } //返回线性表中序号为 i 的数据元素 public Object get(int i) throws IndexOutOfBoundsException { if (i<0||i>=size) throw new IndexOutOfBoundsException("错误,指定的序号越界。"); SLNode p = getNode(i); return p.getData(); } }
基于时间的比较
线性表的操作主要有查找、插入、删除三类操作。
对于查找操作有基于序号的查找,即存取线性表中 i 号数据元素。由于数组有随机存取
的特性,在线性表的顺序存储实现中可以在Θ(1)的时间内完成;而在链式存储中由于需要
从头结点开始顺着链表才能取得,无法在常数时间内完成,因此顺序存储优于链式存储。查
找操作还有基于元素的查找,即线性表是否包含某个元素、元素的序号是多少,这类操作线
性表的顺序存储与链式存储都需要从线性表中序号为 0 的元素开始依次查找,因此两种实现
的性能相同。综上所述,如果在线性表的使用中主要操作是查找,那么应当选用顺序存储实
现的线性表。
对于基于数据元素的插入、删除操作而言,当使用数组实现相应操作时,首先需要采用
顺序查找定位相应数据元素,然后才能插入、删除,并且在插入、删除过程又要移动大量元
素;相对而言链表的实现只需要在定位数据元素的基础上,简单的修改几个指针即可完成,
因此链式存储优于顺序存储。对于基于序号的插入、删除操作,因为在顺序存储中平均需要
移动一半元素;而在链式存储中不能直接定位,平均需要比较一半元素才能定位。因此顺序
存储与链式存储性能相当。综上所述,如果在线性表的使用中主要操作是插入、删除操作,
那么选用链式存储的线性表为佳。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号