C++语法基础
hello~这里是小段老师,非常欢迎大家来阅读我的文章,有好的建议或者有学习C++的需要可以添加VX15837193535交流哦 ^ _ ^
C++初识
头文件与命名空间
0.main 是程序的入口:这是程序真正开始执行的地方,先不用管每一个单词的含义,在后面的学习中自然会理解~
为什么从0开始呢?因为希望大家能养成习惯,编程绝大部分开头是从0开始查的🤭(●'◡'●)
示例:
int main() {
// 你的代码
return 0;
}
1.头文件的作用:每一个头文件里都包含了各种不同的功能函数,若不在代码开头添加头文件,那是无法使用对应的此类功能的!
例如在 cmath 文件中包含了和数学相关的功能,如绝对值,开方,取整等等;
在 iostream 文件中有最常用的输入语句cin和输出语句cout。
在 algorithm 文件中有大量比赛常用的算法小功能。
语法: #include<头文件名>
示例:
int main(){
std::cout<<"hello!"; //由于没有头文件,无法使用cout在屏幕上显示内容,会报错!
return 0;
}
#include<iostream> // 添加头文件
int main(){
std::cout<<"hello!"; // 成功显示hello!
return 0;
}
2.命名空间的作用:C++允许两个不同的头文件中包含相同的功能名字!那么就会出现一个问题,我们在使用时怎样区分它们呢?
这就需要每个头文件的作者给自己写的所有功能起一个统一的名字用来区分,于是诞生了命名空间,比如小段老师和小王老师分别写了一个变量表示自己的年龄:
// 文件aaa.h ,创建了命名空间 duan
namespace duan{
int age = 10; //创建了一个变量存储10
}
// 文件bbb.h ,创建了命名空间 wang
namespace wang{
int age = 100; //创建了一个变量存储100
}
当我们想引入两个人写的两个头文件并使用时,需要在前面加上他们自己起的命名空间的名字和 ::,这样就区分了age是谁的!
#include<aaa>
#include<bbb>
#include<iostream>
int main(){
std::cout<<age; // 出错,age是哪里来的???
std::cout<<duan::age; // 10
std::cout<<wang::age; // 100
return 0;
}
但是这样做的话,每次使用里面的变量都需要加特别麻烦,尤其是像cout这样频繁使用的输出语句,它是属于一个叫做std的命名空间的,那能不能偷一下懒少写几次呢?
答案是肯定的,我们可以在文件上方直接说明我们要使用的命名空间叫什么,但是注意这样就无法区分两个头文件里相同的名字的!
#include<iostream>
using namespace std; //统一宣布使用std空间
int main(){
cout<<"hello";
cout<<"哈哈哈我偷懒不用写std了";
return 0;
}
在比赛中,我们会用到大量的头文件,c++为了方便把很多头文件打包一起放到了一个叫bits/stdc++.h的头文件中;而且他们的功能大多都存在命名空间std中,所以我们以后的代码模板为:
#include<bits/stdc++.h>
using namespace std;
int main(){
// 你的代码
return 0;
}
注释
作用:在代码中加一些说明和解释,方便自己或其他程序员阅读代码、理解思路。
语法:
- 单行注释:
// 描述信息- 通常放在一行代码的上方,或者一条语句的末尾,对附近代码起到解释说明的作用
- 多行注释:
/* 描述信息 */- 通常放在一段代码的上方,对该段代码做整体说明
编译器在运行代码时,会忽略注释的内容,注释不会对程序有任何影响!
示例:
// 我是单行注释
/*
我是第一行注释
我是第二行注释
*/
变量
作用:给电脑中的一块内存空间起名,方便操作这块空间
语法:数据类型 变量名 = 初始值; 只有在创建变量时才需要带上数据类型,使用时是不需要的!!!
示例:
#include<iostream>
using namespace std;
int main() {
int a = 10;
double b = 1.5;
a = 9; // 正确
double b=0.5; // 错误!变量b已经被创建过了!
return 0;
}
常量
作用:用于记录程序中不可更改的数据 ,C++定义常量两种方式
语法:
-
#define 宏常量:
#define 常量名 常量值- 通常在文件上方定义,表示一个常量,注意没有 = 号!
-
const 修饰的变量
const 数据类型 常量名 = 常量值- 通常在定义变量的数据类型前加关键字
const,修饰该变量为常量,不可修改,若尝试修改会报错!
- 通常在定义变量的数据类型前加关键字
示例:
//1、宏常量
#define day 7
int main() {
cout << "一周里总共有 " << day << " 天" << endl;
day = 8; //会报错,因为常量不可修改
//2、const修饰变量
const int month = 12;
cout << "一年里总共有 " << month << " 个月份" << endl;
month = 24; //会报错,因为常量不可修改
return 0;
}
标识符命名规则
C++规定给标识符(变量、常量)命名时,有以下规则必须遵守:
- 标识符不能是C++本身存在有作特殊作用的关键字,例如 if 、while
- 标识符只能由字母、数字、下划线组成,且数字不能开头
- 标识符中的字母区分大小写
建议:给标识符命名时,争取做到见名知意的效果,方便自己和他人的阅读
数据类型
C++规定在创建一个变量或者常量时,必须要指定出相应的数据类型,否则无法给变量分配电脑的内存空间
sizeof关键字
作用:利用sizeof关键字可以==统计数据类型所占内存中几个字节,一个字节=8个bit位(8个二进制01)
语法: sizeof( 数据类型 / 变量)
示例:
int main() {
cout << "short 类型所占内存空间为: " << sizeof(short) << endl;
cout << "int 类型所占内存空间为: " << sizeof(int) << endl;
cout << "long long 类型所占内存空间为: " << sizeof(long long) << endl;
return 0;
}
整型 int
作用:整型变量表示的是整数类型的数据(不带小数点的),哪怕小数点后是0也不行!
C++中能够表示整型的类型有以下几种方式,区别在于所占内存空间不同,范围不同:
语法:int a = 1
| 数据类型 | 占用空间 | 取值范围 |
|---|---|---|
| short(短整型) | 2字节 | (-215 ~ 215-1) |
| int(整型) | 4字节 | (-231 ~ 231-1) |
| long long(长整形) | 8字节 | (-263 ~ 263-1) |
| unsigned int(无符号整数) | 4字节 | (0~232) |
取值范围的计算:以int类型为例,最高位0表示正1表示负,共有4x8=32个二进制数,除了正负还有31位。
最大值:0111111111...(31个1)= 231-1=2147483647 最小值:10000000...(31个0)= -231= -2147483648
浮点型 double
作用:用于表示小数
- 单精度
float - 双精度
double
两者的区别在于表示的有效数字范围不同,一般比赛时直接用 double 即可
语法:double a = 1.23456
| 数据类型 | 占用空间 | 有效数字范围 |
|---|---|---|
| float | 4字节 | 7位有效数字 |
| double | 8字节 | 15~16位有效数字 |
相同的数据类型在创建变量时可以用逗号隔开,省略类型:
#include<bits/stdc++.h>
using namespace std;
int main(){
int a=1,b=2;
double c=1.2,d=9.0;
}
字符型 char
作用:字符型变量用于显示单个字符
语法:char ch = 'a';
注意1:在显示字符型变量时,用单引号将字符括起来
注意2:单引号内只能有一个字符!!!空格也是一个字符!!!
- C++中字符型变量只占用1个字节。
- 字符型变量并不是把字符本身放到内存中存储,而是将对应的ASCII编码放入存储,比如 'a' 是 97
示例:
#include<iostream>
using namespace std;
int main() {
char ch = 'a';
//char ch = "abcde"; //错误,不可以用双引号
//char ch = 'ab'; //错误,单引号内只能引用一个字符
cout << (int)ch << endl; //查看字符a对应的ASCII码
ch = 97; //可以直接用ASCII给字符型变量赋值
cout << ch << endl; // 'a'
return 0;
}
字符串型 string
作用:用于表示0个或多个字符
C++风格字符串: string 变量名 = "字符串值"
示例:
#include<bits/stdc++.h>
using namespace std;
int main() {
string str = "hello world";
cout << str << endl;
return 0;
}
布尔类型 bool
作用:布尔型代表真或假的值 。
bool类型类型占1个字节大小,只有两个值:
- true --- 真(本质是1)
- false --- 假(本质是0)
示例:
#include<bits/stdc++.h>
using namespace std;
int main() {
bool flag = true;
cout << flag << endl; // 1
flag = false;
cout << flag << endl; // 0
return 0;
}
数据的输出与输入
cout
作用:把一些内容显示在屏幕上,可以在箭头的后面跟无数段内容。
语法: cout << 内容1 << 内容2 << endl
内容可以是变量,也可以是一个字符串或一个字符,endl 表示换到下一行。
示例:
#include<bits/stdc++.h>
using namespace std;
int main(){
int a=10;
cout<<a<<endl;
cout<<"我是第一行"<<endl<<"我是第二行"<<endl;
}
cin
作用:用于从键盘获取对应类型的数据,并传递给对应的变量,必须有数据输入才能使程序继续运行!
语法: cin >> 变量1 >> 变量2
示例:
#include<bits/stdc++.h>
using namespace std;
int main(){
int a;
cout<<"请输入a:"; // a是一个int整数,等待你输入整数
cin>>a;
cout<<"a的值是"<<a;
}
若不输入数据那么光标会一直闪烁等待输入

输入完数据后需要按下 Enter 回车键确定,才能继续运行下一行代码!

若有多个变量需要依次输入,每个输入的数据之间可以用 空格Space 或者 换行Enter 隔开,见下图:
#include<bits/stdc++.h>
using namespace std;
int main(){
int a,b;
cout<<"请输入a和b:";
cin>>a>>b; //直接用箭头摆好输入的顺序即可
cout<<"a的值是"<<a<<endl;
cout<<"b的值是"<<b<<endl;
}

运算符
算术运算符
作用:用于处理数学上的四则运算
| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| + | 加 | 10 + 3 | 13 |
| - | 减 | 10 - 3 | 7 |
| * | 乘 | 10 * 3 | 30 |
| / | 除 | 10 / 3 | 3 |
| % | 模(取余数) | 10 % 3 | 1 |
示例:
int main() {
int a = 10;
int b = 3;
cout << a + b << endl; // 加
cout << a - b << endl; // 减
cout << a * b << endl; // 乘
cout << a / b << endl; // 除
cout << a % b << endl; // a除以b的余数:如果余数==0 ,可以用来判断是否整除
}
计算时要注意符号两侧的数据类型,整数除整数只能得到整数,若想得到小数,可以把其中一个变量提前定义为小数double
自增、自减运算符
a = 1;
a++; // ++符号意味着在原来基础上+1并改变a的大小
a--; // --符号意味着在原来基础上-1并改变a的大小
逻辑运算符
作用:用于多个条件之间的逻辑判断,真就是对就是true就是1,假就是错就是false就是0
| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| ! (not) | 非,不是 | !a | 如果a为假,则!a为真; 如果a为真,则!a为假。 |
| && (and) | 与,并且,同时 | a && b | 如果a和b同时都为真,则结果为真,否则为假。 |
| || (or) | 或 | a || b | 如果a和b中有一个为真,则结果为真,二者都为假时,结果为假。 |
示例:
- 妈妈说:你必须写完作业并且天气是晴天才能出去玩 —— 写完作业 && 晴天
- 爸爸说:你要么考100分要么把地拖了才能看电视 —— 考100分 || 拖地
- 好的反义词是什么?—— ! 好
比较运算符
作用:用于表达式的比较,并返回一个真值(1)或假值(0)
| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| == | 相等 | 4 == 3 | 0 |
| != | 不相等 | 4 != 3 | 1 |
| < | 小于 | 4 < 3 | 0 |
| > | 大于 | 4 > 3 | 1 |
| <= | 小于或者等于 | 4 <= 3 | 0 |
| >= | 大于或者等于 | 4 >= 1 | 1 |
格式化输出 printf
作用:当题目要求的输出内容格式比较复杂,里面需要保留小数位数,或使用 cin 写起来很麻烦的时候,可以换成C语言的 printf
这个语句使用时,需要搭配各种不同的格式化占位符以满足变量的需要,具体见下图
语法: printf("xxx 格式化占位符 xxx",变量或数值)
示例:
#include<bits/stdc++.h>
using namespace std;
int main(){
// 1.整数占位 %d
printf("我今年%d岁了",10); // 我今年10岁了
// 2.保留2位小数占位 %.nf
printf("我有%.2f元",1.456); // 我有1.46元 不是四舍五入(比赛这样用就不会错)
// 3.单个字符 %c
printf("我的等级是%c",'A'); // 我的等级是A
// 4.多个内容和换行 \n
printf("我的等级是%c,我今年%d岁了\n",'S',100); // 我的等级是S,我今年100岁了
}
分支结构
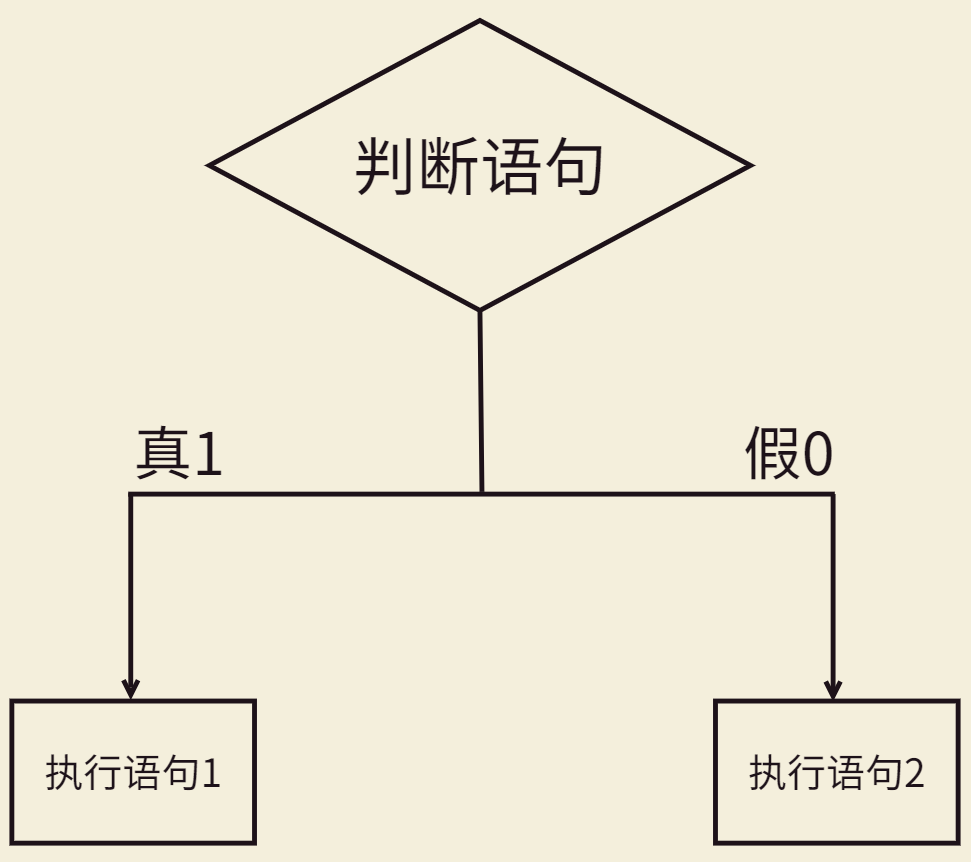
语法:
// 1.单分支
if(判断语句)
{
执行语句1
}
// 2.双分支
if(判断语句)
{
执行语句1
}
else
{
执行语句2
}
// 3.多重分支
if(判断语句1)
{
执行语句1
}
else if(判断语句2)
{
执行语句2
}
else
{
执行语句3
}
在分支结构中,我们只关注括号内的判断语句能否为真(1),若为真就运行花括号内的执行语句,若不为真那就尝试同组分支的下一个判断,直到走到 else(如果有else的话)
为什么叫分支结构?因为只能运行一组判断中的其中一个花括号!
示例:
int main() {
int score;
cin >> score;
// 3.if - else if - else多重分支结构:
if (score > 600){
cout << "我考上了一本大学!!!" << endl;
}
else if (score > 500){
cout << "我考上了二本大学!!!" << endl;
}
else if(score > 400){
cout << "我考上了三本大学!!!" << endl;
}
else{
cout << "我没考上大学T_T" << endl;
}
}
三元运算符
一种唯一作用是装比的写法 ~ 让人看起来很难理解且没什么用
语法:Exp1 ? Exp2 : Exp3; 若 Exp1 的判断为真,返回 Exp2 ,否则返回 Exp3
int a=1,b=2,c;
// 朴素写法
if(a<b)
{
c=10;
}
else
{
c=100;
}
// 装比写法
c = a<b?10:100;
// 上下是完全等价的!!!
循环结构
while
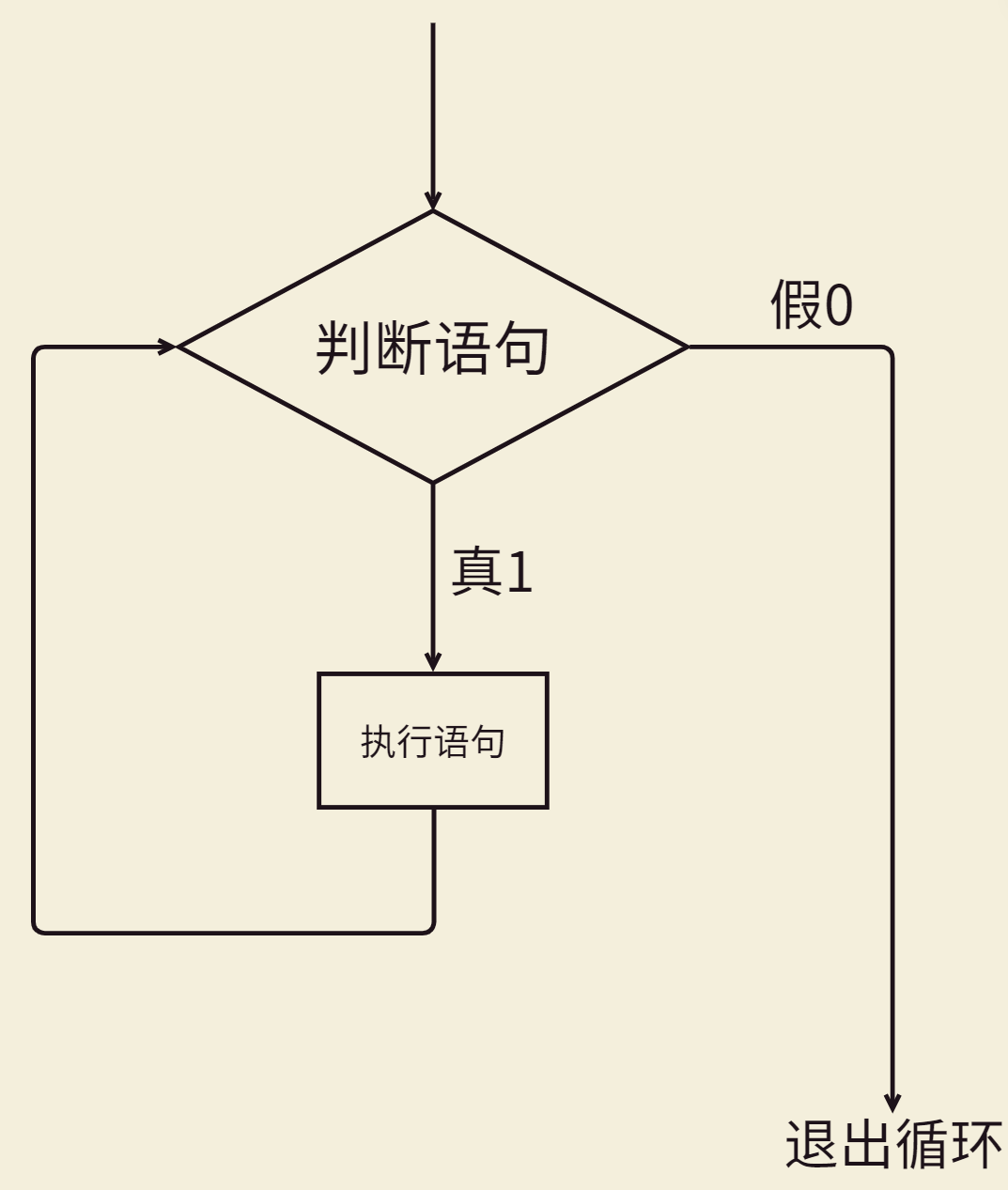
语法:
// 先判断,判断为true执行语句,继续判断,判断为false,退出循环
while(判断语句)
{
执行语句
}
当判断语句永远为真时,那么循环永远不会退出,也就形成了死循环,例如:
while(true)
{
cout<<"hhh"<<endl; // 会一直输出hhh停不下来
}
所以我们需要有一个变量在循环的过程中发生变化,当它满足某个条件时,借助它退出循环,例如:
int a=1;
while(a<=9) // 当a=9时是最后一次判断为true,输出并+1后a=10,判断为false退出循环
{
cout<<a<<' '; // 输出结果为 1 2 3 4 5 6 7 8 9
a=a+1;
}
do...while
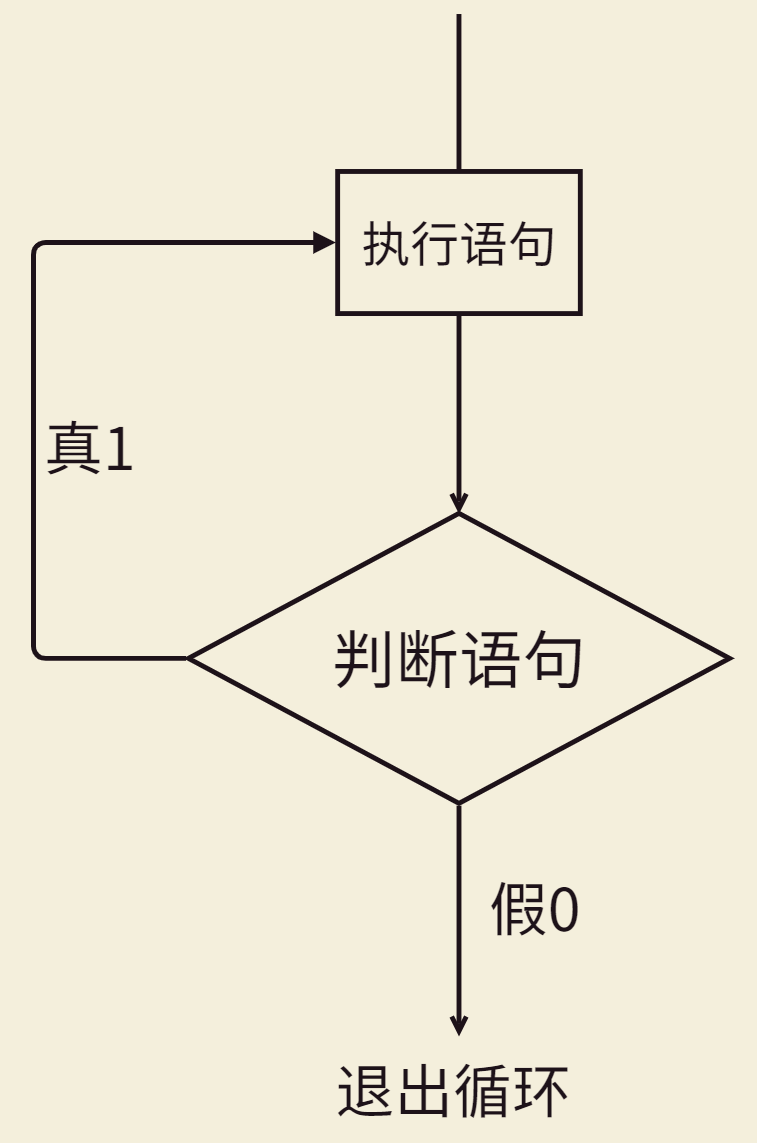
语法:
// 不常用:先执行,在判断,判断为true,继续执行,再判断,判断为false,退出循环
do
{
执行语句
}
while(判断语句)
for
for循环和while循环是没有什么孰优孰劣的,喜欢哪个用哪个,不过大多数时候还是比较喜欢用for的,写着方便🤭
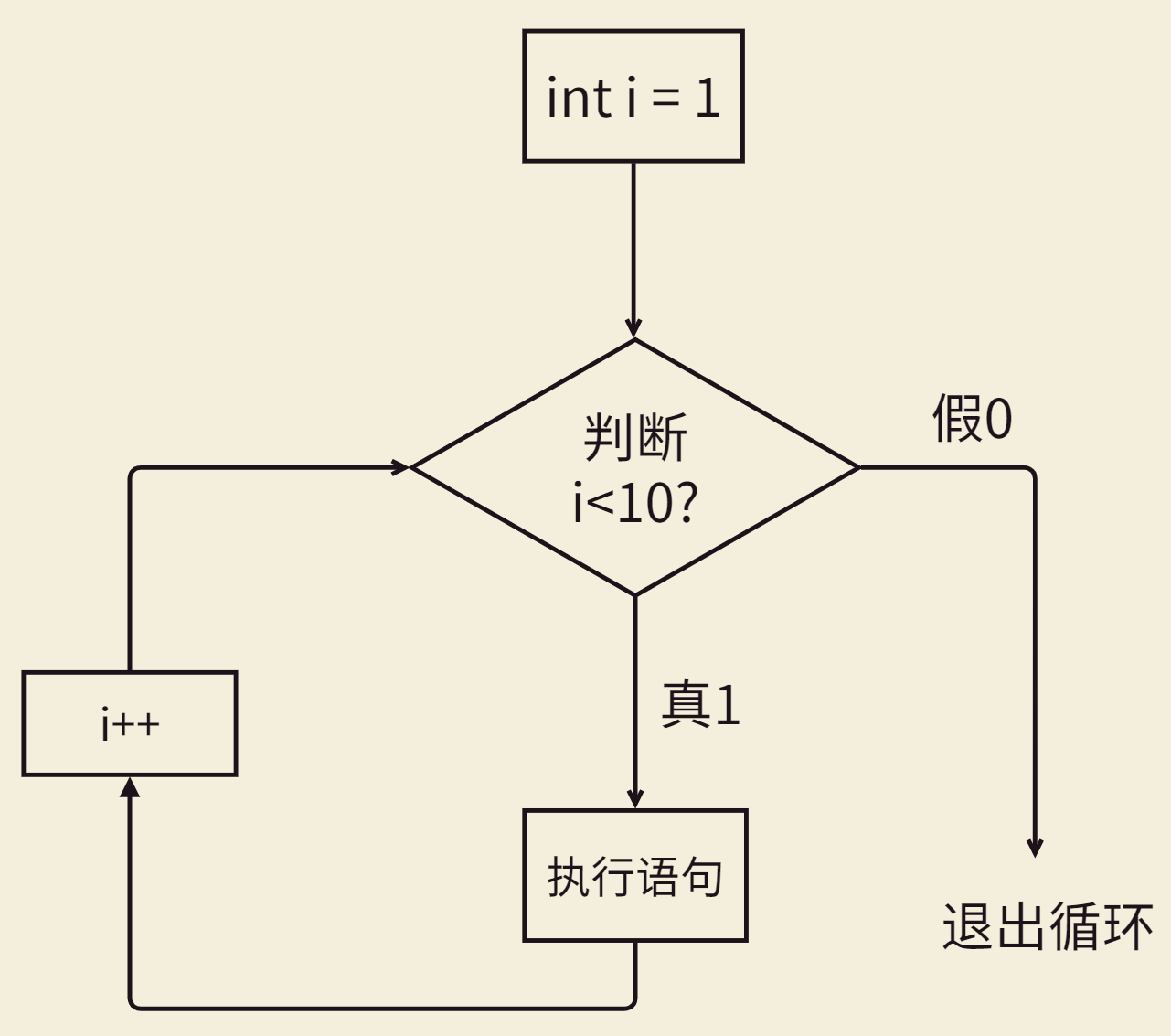
语法:
// 这里的循环变量定义在括号里,所以只能用于for部分!在for外面使用会报错!
for(定义循环变量;运行条件;变量变化)
{
执行语句
}
示例:
// 输出1~100
for(int i=1;i<=100;i++)
{
cout<<i<<endl;
}
// 输出100~1
for(int i=100;i>=1;i--)
{
cout<<i<<endl;
}
多重循环:可以借用钟表时间进行理解,钟表里的时针、分针、秒针本身就是一个三重循环,秒针转一圈-分针走一格,分针转一圈-时针走一格,只有循环的内部代码执行完才会开启下一轮循环。
for(int i=0;i<24;i++) // 时
{
for(int j=0;j<60;j++) // 分
{
for(int t=0;t<60;t++) // 秒
{
printf("当前时间是:%d时%d分%d秒\n",i,j,t);
}
}
}
// 首先开启第一个for循环i=0,然后开启第二个for循环j=0,再然后开启第三个for循环的第一轮t=0;
// 当t=59秒输出完后第三个for循环结束,此时第二个循环里的代码执行完毕,第二个for循环开始下一轮j=1
// 当j=59分&&t=59秒输出完后第一个for循环里的代码全部执行完毕,第一个for循环开始下一轮i=1

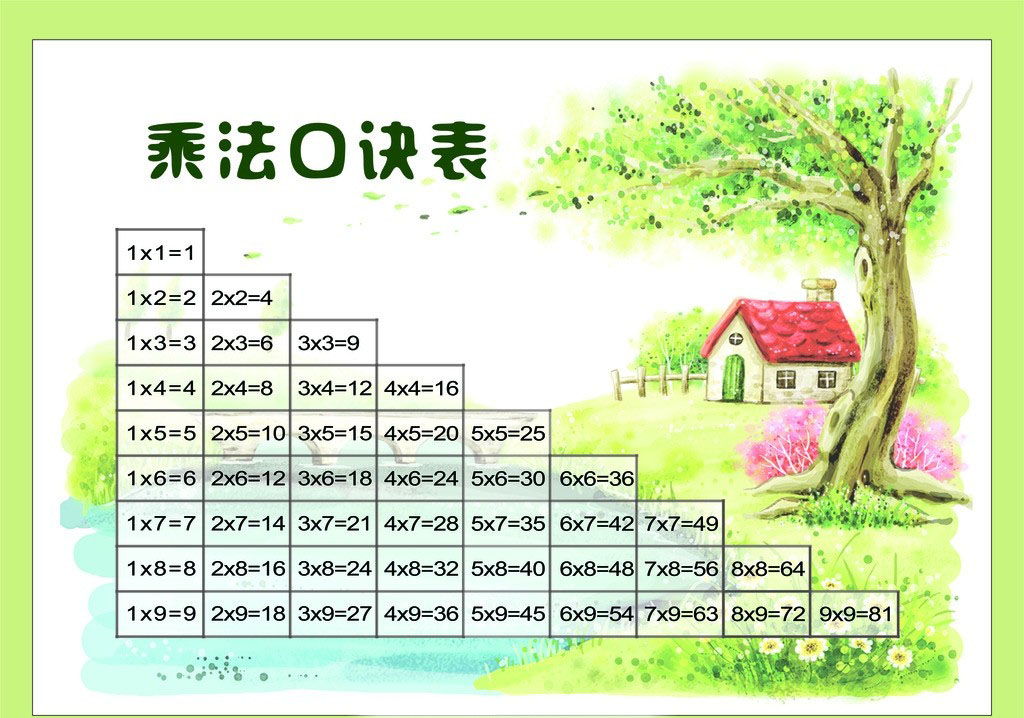
练习:打印乘法口诀表
-
难度1:打印完整版9行9列
#include<bits/stdc++.h> using namespace std; int main(){ for(int i=1;i<=9;i++) // 控制第几行,第一行都x1,所以i是第二个数 { for(int j=1;j<=9;j++) // 此循环表示一行算式,所以变化的j是第一个数 { printf("%dx%d=%d\t",j,i,j*i); // \t是Tab可以上下自动对齐空格 } cout<<endl; } }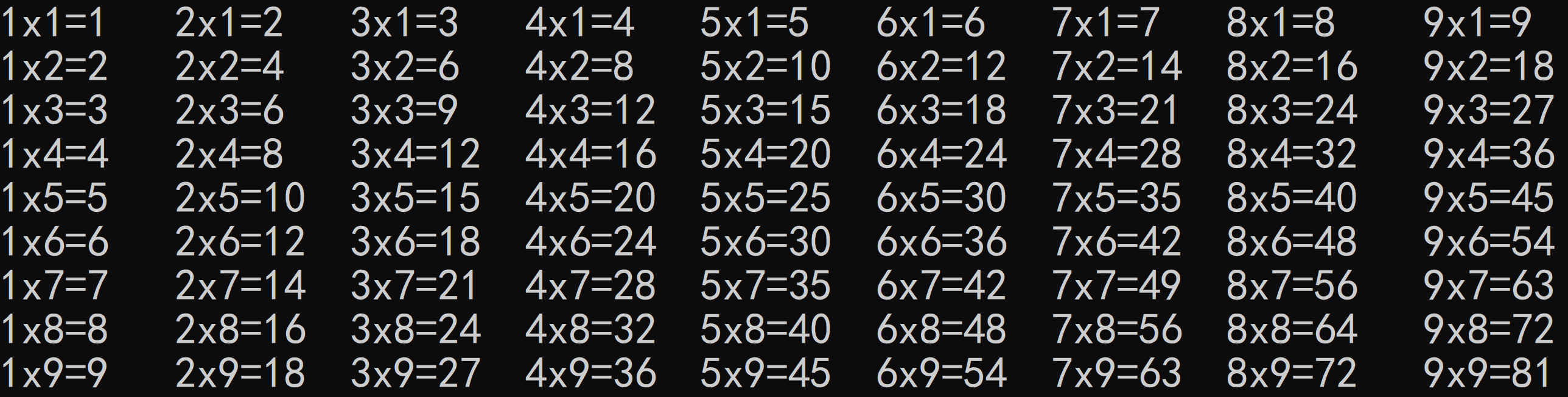
-
难度2:打印三角版
#include<bits/stdc++.h> using namespace std; int main(){ for(int i=1;i<=9;i++) { for(int j=1;j<=i;j++) // 只需控制每一行的第一个数j不超过i即可 { printf("%dx%d=%d\t",j,i,j*i); } cout<<endl; } }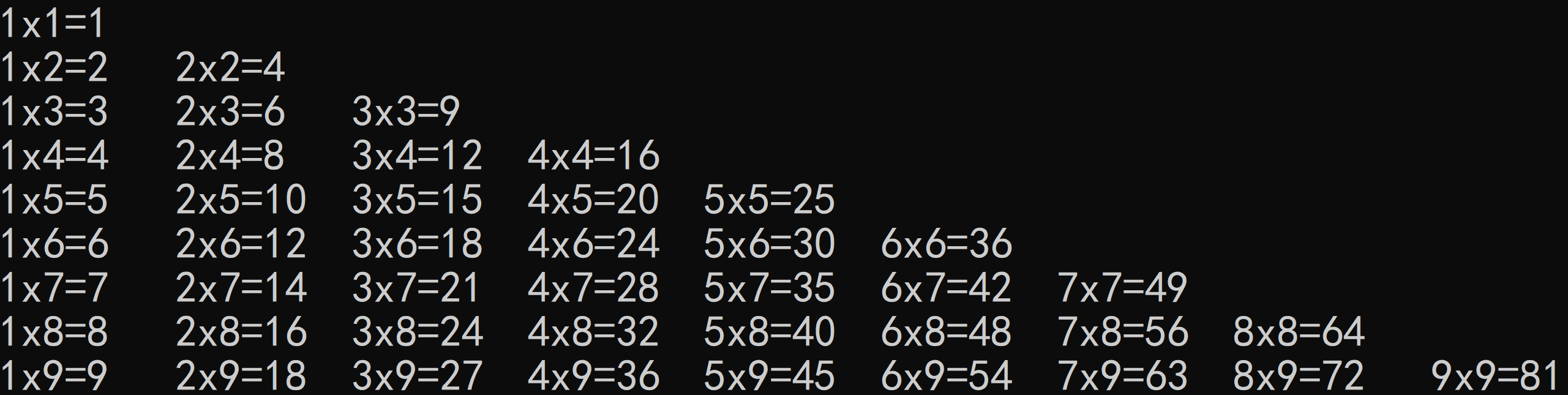
break和continue
作用:break的作用是结束循环,continue的作用跳过本轮循环
示例:
// 当i=1时,在输出1以后,遇到break,立即结束break所对应的循环
for(int i=1;i<=5;i++)
{
cout<<i<<endl;
break;
}
// 输出结果为 1 2 4 5 ,当i=3时,判断为true,执行continue,跳过剩余代码,直接开始i++
for(int i=1;i<=5;i++)
{
if(i==3)
{
continue;
}
cout<<i<<endl;
}
数组
一维数组
相比与之前学习的变量,每个变量只能存储一个数据,如果我们想短时间内存储大量数据,例如班级期末考试的分数,将会特别麻烦。所以我们要学习一种全新的存储数据的结构:数组。
-
特点1:数组内的每个元素都是相同的数据类型
-
特点2:数组内的每个元素的存储位置是在电脑中连续的,紧紧相邻的
多个整数的存储示意图:

创建一维数组
语法: 数据类型 数组名 [ 数组长度 ] ;
数组长度指的是创建数组时预先设定好的数组所占的空间,也可理解为数组有几个格子。
在程序编译(未运行)时必须确定数组的大小!!!填上一个整数!!!填多少看下面 👇
一般OI题的时空限制
时/空限制:1s/64MB 或 2s/128MB以1MB为例,单位进制转换为1024,1MB=1024KB=1048576B 字节
int类型占4个字节,所以1MB的空间可以开1048576÷4=262144个格子
有时候做题可能从1号格子开始放更加方便,所以创建时要比题目给的范围稍大一些
数组长度不能写变量!数组长度不能写变量!数组长度不能写变量!在自己的DEV编译器中可能会发现不报错,但是比赛时的环境往往版本比较低,写变量会出现 Compile Error
示例:
int main
{
// 创建能存储100个整数的数组,格子内为随机值
int a[100];
// 创建包含5个确定数据的数组
int b[5]={1,2,3,4,5};
// 若给的数据个数超出数组长度,会报错
int c[5]={1,2,3,4,5,6,7,8,9};
// 若给的数据少于数组长度,未填充的格子默认为0
int d[5]={1,2,3}; // 1 2 3 0 0
}
访问或修改数组元素
语法: 数组名 [ 下标 ]
下标相当于编号,但它并不是专属于数组的哦~凡是在电脑中连续存储的数据结构都是可以用下标访问滴。
数组第一个元素的下标从0开始!超出数组指向随机值!不能是负数!
int a[5]={10,20,30,40,50};
cout<<a[0]<<endl; // 10
cout<<a[1]<<endl; // 20
cout<<a[2]<<endl; // 30
cout<<a[3]<<endl; // 40
cout<<a[4]<<endl; // 50
cout<<a[5]<<endl; // 我也不知道是多少,随机的~
cout<<a[-1]<<endl; // 这是绝对不行滴!会报错!
// 修改下标为0的元素的值为999
a[0]=999;
遍历数组
遍历数组指的是扫描数组内的全部元素,扫描时需要知道每一个元素的下标是多少,借助 for循环 移动下标。
那怎么知道下标的最大值也就是最后一个元素的下标呢?有两个方法:
-
题目中往往在向数组输入元素前,都会提前输入一个整数
n,表示元素的个数,由于下标从0开始,所以最后一个元素的下标是n-1。for(int i=0;i<n;i++) // i是下标 { cout<<a[i]<<endl; // 下标会在循环内自动变化 } -
若在编写代码中有一个数组的长度未知,可以通过
sizeof得到数组所占字节数,从而计算得到数组长度。int a[]={1,2,3,4,5,6,7,8,9,10}; cout << sizeof(a); // 每个元素都是int类型占4个字节,4*10=40 int n = sizeof(a) / sizeof(int); // 10个
数组初始化
初始化基本分为两种情况:
-
把题目给的多个数据直接放入数组,题目一般用空格分开每个数据,可以直接
cin。
int n; cin>>n; int a[10000]; for(int i=0;i<n;i++) // i是下标 { cin>>a[i]; // 通过循环改变i,让数据自动放入每个下标对应的格子 } -
做题时可能需要自己创建一个全为0的数组。
int n; cin>>n; int a[10000]; for(int i=0;i<n;i++) // i是下标 { a[i]=0; // 改变 } -
数组创建在
main里时,只要没有用{ }进行过赋值,格子里就是随机值。创建在main上面时默认全0。#include<bits/stdc++.h> using namespace std; int a[100]; // 全部默认为0 int main() { int b[100]; // 随机值 }
数组极值求解
案例:N只小猪比体重:在第一行输入一个整数n(1<=n<=100),表示小猪的数量;第二行输入n个空格隔开的数据。输出最重的小猪体重。

#include<bits/stdc++.h>
using namespace std;
int main()
{
int n;
cin>>n;
int a[101];
for(int i=0;i<n;i++) // n次循环录入小猪体重进数组
{
cin>>a[i];
}
// 预设极值法:假设第一只小猪是最重的,遍历整个数组并判断,若发现比t更大的数字,就改变t,最后t存储的一定是最重的体重
int t = a[0];
for(int i=0;i<n;i++)
{
if(a[i]>t)
{
t=a[i];
}
}
cout<<t; // 输出答案
}
二维数组

如果把一维数组看作是一行数据的话,那么二维数组就是多行数据。你可以把它当作表格。
创建二维数组
int a[行数][列数];
// 列的含义和一维数组的数组长度一样
// 行的含义就是有几个一维数组
二维数组的格子总数为
行x列,一般行列不超过1000,注意观察题目数据范围!
// 10行10列二维数组,未赋值就是随机值
int a[10][10];
// 3行4列二维数组并赋值
int a[3][4] =
{
{1,2,3,4},
{5,6,7,8},
{9,10,11,12},
};
访问或修改数组元素
语法: 数组名 [行下标] [列下标]
行和列的下标都是0开始!以三行四列为准见下图每个元素的下标:
| 行 \ 列 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 0 | a[0] [0] | a[0] [1] | a[0] [2] | a[0] [3] |
| 1 | a[1] [0] | a[1] [1] | a[1] [2] | a[1] [3] |
| 2 | a[2] [0] | a[2] [1] | a[2] [2] | a[2] [3] |
int a[3][4] =
{
{1,2,3,4},
{5,6,7,8},
{9,10,11,12},
};
// 访问数组第一行第一个元素
cout<<a[0][0]<<endl;
// 修改数组第三行第四个元素
a[2][3]=999; // 12改为999
遍历数组
由于同时存在行和列两个下标,且遍历的顺序是从左往右,从上往下,所以需要双循环。
int n=3,m=4; // 3行4列
int a[3][4] =
{
{1,2,3,4},
{5,6,7,8},
{9,10,11,12},
};
for(int i=0;i<n;i++) // i是行下标,每一行遍历完才是下一行
{
for(int j=0;j<m;j++) // j是列下标
{
cout<<a[i][j];
}
}
数组初始化
int n,m;
cin>>n>>m;
int a[100][100];
for(int i=0;i<n;i++)
{
for(int j=0;j<m;j++)
{
cin>>a[i][j];
}
}
// 若n=3,m=10,则只有30个格子会被赋值。
// 剩下的格子维持原样,参考a创建的位置,若在main里则为随机,若在main上面则为0
二维数组坐标关系
例题1:将5行5列二维数组左上-右下对角线上的数据标为1,其余变成0
#include<bits/stdc++.h>
using namespace std;
int main()
{
int a[5][5];
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
if(i==j) a[i][j]=1; // 明显观察到对角线上的数行列坐标相等
else a[i][j]=0;
}
}
}
例题2:将5行5列二维数组右上-左下对角线上的数据标为1,其余变成0
#include<bits/stdc++.h>
using namespace std;
int main()
{
int a[5][5];
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
if(i+j==4) a[i][j]=1; // 明显观察到对角线上的数行列坐标相加值固定
else a[i][j]=0;
}
}
}
函数
函数就是把一部分 多次重复使用 且 具有相同功能 的代码打包起来!它不改变原有代码的作用,还能让它用起来更加灵活。
函数的组成结构
函数主要由5个部分组成:
-
返回值类型:根据
return后的数据类型去写,若没有返回值就写void表示无 -
函数名:和变量名的规则一致
-
参数:可以没有也可以有很多,是个临时变量,只存活在函数里
-
函数体语句:函数执行的功能代码
-
return 返回值:函数运行完成后得到的结果,运行到return会立即结束整个函数(有点像break)
返回值类型 函数名 (参数1,参数2...)
{
函数体语句
return 返回值
}
函数的创建与调用
一个函数就是一段独立的代码,相当于你制造了一台可以被重复使用的机器,若你创建完成后不去调用这个函数,那你跟没有创建函数是一模一样的~
无参数无返回值
void story() // 无返回值 无参数
{
cout<<"从前有座山"<<endl;
cout<<"山上有座庙"<<endl;
cout<<"庙里有和尚"<<endl;
cout<<"和尚对我说"<<endl;
}
int main()
{
story(); // 调用函数时需写上 函数名(); 括号不能省!!!
story();
story();
// 一共会输出3次故事
return 0;
}
有参数无返回值
// game函数调用时会输出游戏币的数量
void game(int x)
{
printf("本次投了%d个游戏币\n",x);
}
void add(int a,int b)
{
printf("%d+%d=%d\n",a,b,a+b);
}
int main()
{
game(); // 错误! 有参数的函数在调用时必须说明变量的值
game(5); // 本次投了5个游戏币
add(1); // 错误! 少了b变量的数值
add(1,2); // 1+2=3 数值和参数的顺序是一一对应的
add(1,2,3); // 错误! 多了一个数值3
return 0;
}
无参数有返回值
// 123写在return的后面表示返回值,返回值就是函数的结果,所以函数名前写int
int abc(){
return 123;
}
int main(){
// 运行后abc()=123 t=123
int t = abc(); // 用一个变量存储运行后的结果
return 0;
}
有参数有返回值
// abc函数可以把任何一个给它的数字扩大10倍作为结果返回
int abc(int x){
return x*10;
}
int main(){
int w = abc(); // 错误! 缺少参数的数值
// 有返回值的函数一般需要用变量存储运行结果,以便对结果做进一步处理
abc(10); // 正确! 但是返回值没有被保存下来就丢掉了,相当于白算了
int t = abc(10); // t=100
cout<<abc(t); // 再次调用函数abc(100),不用变量保存结果直接输出,相当于cout<<1000;
return 0;
}
★参数的特点
-
把一个变量的值传递到函数使用时,参数会复制数值,对原先的变量没有任何影响。
void fun(int x) { x = x+10; // x变化了跟我a有什么关系呢? } int main() { int a = 10; fun(a); // 这一步做了 int x = a = 10 cout<<a<<endl; // 还是10 return 0; } -
变量分为局部变量和全局变量,区分他们的方式主要看变量在哪里被创建:
局部变量一般被创建在某个大括号{ }内,它只能使用在特定的代码块中。
全局变量一般被创建在文件的开头顶头写,能在整个代码文件被随意使用。#include<bits/stdc++.h> using namespace std; // 写在开头的都是全局变量,不在任何一个大括号内 int a; // 全局变量默认为0 int b[100]; void fun(int x) // 局部x,只能在fun里用 { int t = x*10; // 局部t } int main() { int c = 5; // 局部c,只能在main函数中用 for(int i=0;i<10;i++) // 局部i,只能在for中用 { cout<<i<<endl; } return 0; } -
参数可以和其它变量重名(但是很不推荐,不写注释的同学容易搞混含义),重名时采取就近使用原则。
#include<bits/stdc++.h> using namespace std; int a = 10; void fun(int a) { a=a+10; cout<<"fun函数中的a="<<a<<endl; // fun函数能看到全局变量a和参数a,就近原则参数a更近,所以后面所有代码用的都是参数a } void abc() { a=a*10; cout<<"abc函数中的a="<<a<<endl; // abc自己没有a,所以就近原则用的是全局变量a,导致全局变量a被修改 cout<<"abc函数中的b="<<b<<endl; // 错误!b是main中的局部变量,abc无法使用 } int main() { int b=1; fun(a); // fun函数中的a=20 abc(); // abc函数中的a=100 return 0; }
递归函数
如果一个函数在它的内部又调用了自己,那么就称它为递归函数。
举个最简单的例子,一但启动就无法停止的程序,输出hello以后又会重新运行main函数,继续输出hello,最后会因为递归函数程序占了电脑太多内存而被强制退出。
#include<bits/stdc++.h>
using namespace std;
int main()
{
printf("hello\n");
main();
return 0;
}
一个不合格的递归函数就是像上面一样陷入无限嵌套当中,所以递归函数的终止条件尤为重要!
可以通过对变量进行判断限制递归函数:
#include<bits/stdc++.h>
using namespace std;
int n = 0;
void fun()
{
if(n>=3) return; // 函数运行到return一定会立即结束,后面没有返回值所以是void
n=n+1;
printf("hello\n");
fun();
}
int main()
{
// n=0,1,2时都会运行并输出hello,当n=3时判断成立执行return,结束函数
fun();
return 0;
}
例题:倒序输出整数每个数位上的数字,从个位到最高位,用空格隔开
#include<bits/stdc++.h>
using namespace std;
// 递归的核心就是设计一个通用的函数任务,并且该任务会随着参数的变化逐渐走向停止
// 函数的任务就是输出参数的个位数字
void fun(int x)
{
// 参数为0说明没有个位数字了
if(x==0) return;
cout<<x%10<<' '; // 输出个位数
fun(x/10); // 去掉个位数让参数缩小十倍,然后对剩下的数字重新调用函数处理
}
int main()
{
int n;
cin>>n;
fun(n); //比如输入123,调用函数fun(123),先输出3,在递归调用fun(12)
}
结构体
结构体是用户自己创建的一种全新的数据类型,它是由其它各种数据类型所组成。有时候一些变量绑定到一起对做题更加方便,比如需要对学生的分数进行排序,然后输出姓名,如果将分数和姓名分别保存到两个数组中,那么在排序时就需要保证两个数组里的姓名和分数对应关系不能乱;但是如果我们能把姓名和分数合体,让他们在排序时一起移动,写代码时就不需要考虑姓名和分数对不上的问题了~
创建与使用
定义一个结构体就好像是自己去创建一个C++中的数据类型,跟int double这些没什么区别,只不过这个数据类型比较大而已,它可能是多种类型的合体。
struct 结构体名{
属性1; // 每个属性都可以是任意的其它数据类型
属性2;
属性3;
...
}; // 结尾有分号!结尾有分号!结尾有分号!
创建结构体示例:
struct student{ // 这里的student就是结构体名字,也相当于类型名
string name; // name和age是属性名,随便取的
int age;
};
// 创建了一个学生类型的结构体,里面有2个属性,分别表示姓名年龄
// 就像从姓名和年龄两个方面来描述一个学生一样
创建结构体变量的语法:结构体名 变量名
操作结构体属性的语法:结构体变量.属性
切记不可直接对结构体做操作
cout<<s;必须要精确到它身上的某个属性
// 方式1:这样的学生s里面的姓名和年龄都是没有进行赋值的,需要手动赋值
student s;
s.name = "段锐"; // 结构体s的姓名是段锐
s.age = 10; // 结构体s的年龄是10
// 方式2:创建和赋值同时进行,必须按照结构体中的属性顺序进行赋值
student s2 = {"段锐",10};
student s3 = {100,"张三"}; // ❌ student中第一个是姓名 第二个是年龄
// 方式3:题目需要用cin录入数据
student s3;
cin>>s3.name>>s3.age;
结构体数组
与其它类型的数组创建与使用没有区别。
语法:
// 方式1:
struct 结构体{
属性;
}数组名[大小];
// 方式2:
结构体 数组[大小];
示例:
struct stu{
string name;
}p[100]; // 创建一个由100个stu类型组成的数组p
stu w[200]; // 创建一个由200个stu类型组成的数组w
使用:
struct stu{
string name;
}p[100];
// 和其它数组相似,想使用要先锁定下标
p[0].name = "李1";
p[1].name = "李2";
// 每个结构体不在具有名字,而是用下标替代
★结构体数组排序
前置知识:在头文件 #include<algorithm> 中(你要用的是万能头当我没说),有一个 sort() 函数,它能对数组自动进行排序操作。但是一般情况下只能对内置数据类型排序,如整数升序降序。但是大部分使用结构体的题目,都需要进行复杂的多规则排序,所以我们需要学习针对结构体的自定义排序函数。
sort() 函数支持编写自定义比较函数,根据函数的返回值是 true 或 false 来自动调整数组元素的顺序。
true 表示元素1的下标 < 元素2的下标,即元素1在元素2前面。
false 表示元素1的下标 > 元素2的下标,即元素1在元素2后面。
语法:
struct stu{
string name;
int age;
}p[10];
// 自定义比较函数,名字随便起
bool cmp(stu a,stu b) // 函数参数变量a和b,表示两个比较的类型
{
return a.age > b.age; // 若a的年龄>b的年龄,则返回值为true,a在前,否则为false,b在前
return a.age < b.name; // 错误的比较,整数和字符串比较没有任何意义
}
sort(开头下标,结尾下标+1,自定义函数);
编写技巧:在这个函数里对顺序有影响的其实只有 大小于号,我们可以固定每次写return的时候,先写a再写b,若想升序则是小的在前,所以写小于号< ,若想降序则是大的在前,所以是 大于号> 。
示例:假设10个结构体都已经填充好数据,并按年龄从小到大输出姓名
struct stu{
string name;
int age;
};
bool cmp(stu a,stu b)
{
return a.age < b.age;
}
int main(){
stu p[10];
sort(p,p+10,cmp); // 第一个元素下标是0,最后一个元素的下标是9
for(int i=0;i<10;i++)
{
cout<<p[i].name<<endl;
}
}
指针
概念
内存地址是指数据在电脑中真实存放的位置,一般用一个十六进制整数来表示。通过取地址符号 & 就可以查看数据所在的位置。
int main()
{
int a=10;
cout<<a<<endl; // 10
cout<<&a<<endl; // 0x24f23ffcfc (随机的)
}
指针也是一个变量,与传统变量的区别是:
- 传统变量直接存储数据(上面的10),而指针存储的是这个数据的内存地址(上面的16进制整数)。
- 比如有人来班级找小明,我们把班级当作一个变量
banji,传统变量banji存的就是小明本身,而指针banji存的是小明家的地址,我们想找到小明还需要根据家的地址再找一次。
创建与使用
创建指针语法: 数据类型 * 指针名 = &变量名 (*符号偏左、偏右、居中都可以)
指针变量的标志是* ,内存地址的标志是&
示例:
int main()
{
int a = 10;
// 声明一个保存int类型数据地址的指针
int* p = &a;
cout << p << endl; // 注意不要写&p ,p本身就存储了a的地址,&p表示p的地址
}
指针解引用:查看地址中保存的数据
解引用语法: *指针
示例:
int main()
{
int a = 20;
int* p = &a;
cout << *p << endl; // 20
*p = 100; // 修改p指向地址中的数据
cout << a << *p << endl; // 100 100
}
指针的大小
在32位操作系统下,所有类型的指针都占4个字节;在64位操作系统下,所有类型的指针都占8个字节。
示例:
int main()
{
int *p;
cout << sizeof p; // 8
}
空指针与野指针
空指针:指针指向内存编号为0的空间。
野指针:指针指向非法的内存空间编号(瞎写的编号)。
示例:
int main()
{
int* p = NULL; // NULL就是空就是0 0~255号内存为系统内存禁止访问!
cout << *p; // 无输出
}
指针和数组
首先我们知道数组内的元素应该是紧紧挨在一起的,因为我们提前在内存开辟了一段连续的空间用来存放数据。
当我们第一次学习数组时,相信大家都直接打印过数组名,见到了一个在当时很陌生,而现在很熟悉的数字,一个16进制整数表示的地址。
int main()
{
int a[10];
cout << a << endl; // 0x7fe6fffc90
// 数组名本身就是数组的地址,也是数组第一个元素的地址
// 查看数组第一个元素的地址
cout << &a[0] << endl; // 0x7fe6fffc90
// 第二个元素的地址
cout << &a[0] << endl; // 0x7fe6fffc94
// 为什么+4呢?因为一个int类型的元素占4个字节
}
当我们对指针进行加法的操作时,地址不是单纯的+1,而是移动一个对应类型的字节数
int main()
{
int a[5] = {1,2,3,4,5};
int* p = a; // p指向数组a的地址,也是第一个元素的地址
cout << p << p+1 << endl; // 0x9118fffa80 0x9118fffa84
// 移动了一个int大小,指向了第二个元素的地址,由于p和a都表示地址,所以都可以+1
cout << *(p+1) << *(a+1) << endl; // 2
// 意味着 *(a+i) == a[i]
}
虽然我们发现数组名和指针在使用时几乎一模一样,但是!不能把数组名叫做指针!
数组名是不能更改指向的!指针是能更改的!
指针和函数
//值传递
void swap1(int x ,int y) // x=a y=b 复制了一份不影响ab
{
int temp = x;
x = y;
y = temp;
}
//地址传递
void swap2(int* p1, int* p2) // p1=&a p2=&b
{
int temp = *p1;
*p1 = *p2; // 操作了内存空间中的数据
*p2 = temp;
}
int main() {
int a = 10;
int b = 20;
swap1(a, b); // 值传递不会改变ab
cout << a << b << endl; // 10 20
swap2(&a, &b); // 地址传递可能会改变ab
cout << a << b << endl; // 20 10
}
指针和结构体
若现在有一个结构体 stu ,结构体内有属性 name 和 age ,有一个指针 stu* p 指向创建出的结构体变量 ,我们想查看或修改指针指向的结构体属性时, 有两种方法:
语法1(朴素版):先解引用找到对应结构体,在用 . 访问属性,注意加小括号:(*指针).属性
示例:
struct stu{
string name;
int age;
};
int main()
{
// 创建结构体变量
stu s1 = {"段锐",20};
// 创建指针
stu* p = &s1;
// 访问指针内的数据方式1:
cout << (*p).name << (*p).age << endl;
cout << *p.name; // 错误!会先计算后面导致变成 *(p.name)
}
语法2(增强版):无需解引用,直接使用 -> 箭头操作符,这个符号由 - 和 > 两个符号组成:指针->属性
示例:
struct stu{
string name;
int age;
};
int main()
{
// 创建结构体变量
stu s1 = {"段锐",20};
// 创建指针
stu* p = &s1;
// 访问指针内的数据方式2:
cout << p->name << p->age << endl;
}
const 修饰指针
const 作为常量的标志,意味着被它修饰的符号是无法改变的,所以会有三种情况:
const修饰*const修饰 变量const同时修饰两个
int main() {
int a = 10;
int b = 10;
//const后面是指针int*,所以p可以用,*p1不可以用
const int* p1 = &a;
p1 = &b; // 正确,可以修改指向位置
*p1 = 100; // 报错,不能修改其中的数据
//const后面是变量p2,所以*p2可以用,p2不可以用
int* const p2 = &a;
p2 = &b; // 错误,不能改变指向
*p2 = 100; //正确,可以修改数据
//const既修饰指针又修饰变量,那就锁死了都不能改!
const int* const p3 = &a;
p3 = &b; //错误
*p3 = 100; //错误
}
总结:就是看 const 后面有什么,后面跟的符号不可以改!
引用
引用的本质其实就是一个被 const 修饰变量的指针!引用就是给变量再起第二个名字!
引用的特性:
- 引用生成时必须有指向
- 一个变量可以有多个引用
- 引用不可以更改指向
- 引用不会开辟新的内存空间
语法: 数据类型 & 引用名 = 引用体
示例:
int main()
{
int a = 10;
int& b = a;
cout << a << b << endl; // 10 10
// 直接改变b的值,会影响a,因为他俩地址相同
b = 100;
cout << a << b << endl; // 100 100
int c = 20;
int& b = c; // 错误,不可以换人!
}
引用作为函数参数时,有两个好处:
- 节省空间,不会再复制一份数据
- 直接影响传进来的实际参数
void swap1(int& x,int& y) // int& x=a int& y=b
{
int temp = x;
x=y;
y=temp;
}
int main()
{
int a=10,b=20;
swap1(a,b);
cout << a << b <<endl; // 20 10
}
文件操作
方法一:
切记读题,不要写错文件名,否则直接0000000000分!!!
// 将文件内的数据从终端导入,后续正常cin即可
freopen('文件名.in','r',stdin);
// 将输出的内容从终端放进文件中,后续正常cout即可
freopen('文件名.out','w',stdout);
本文来自博客园,作者:不尽人意的K,转载请注明原文链接:https://www.cnblogs.com/duan-rui/articles/yufajichu.html
