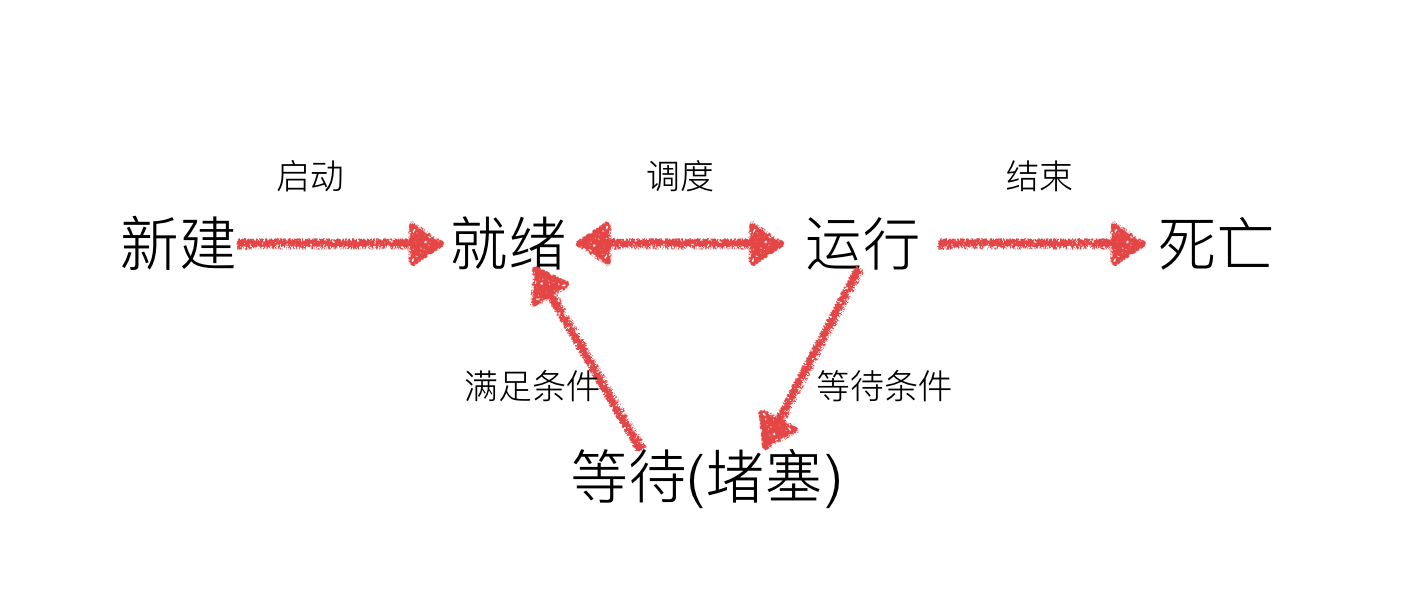
python笔记
段锐的Python日记
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than right now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
Python基础
基础语法
编码
默认情况下,Python 3 源码文件以 UTF-8 编码,所有字符串都是 unicode 字符串。
标识符
- 第一个字符必须是字母表中字母或下划线 _ 。
- 标识符的其他的部分由字母、数字和下划线组成。
- 标识符对大小写敏感。
- 在 Python 3 中,可以用中文作为变量名,非 ASCII 标识符也是允许的了
保留字
不能把它们用作任何标识符名称
import keyword
keyword.kwlist
#['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
数据操作
数据类型
int float str list tuple dict set None bool complex
可变数据类型:list dict set
不可变数据类型:int float str tuple
进制转换
使用print语句打印一个数字的时候默认使用十进制。
以0b开头的是二进制,以0o开头的是八进制,以0x开头的是十六进制。
十进制 → 二进制 八进制 十六进制
bin(12) #0b1100
oct(12) #0o14
hex(12) #0xc
把二进制 八进制 十六进制字符串 → 十进制
int('1a2c',16) #6700
int('12',8) #10
int('1101',2) #13
只有0,空字符串,空列表,空元组,空字典,空数据转换为布尔值是False,其他的都会被转换为True。
算术运算符
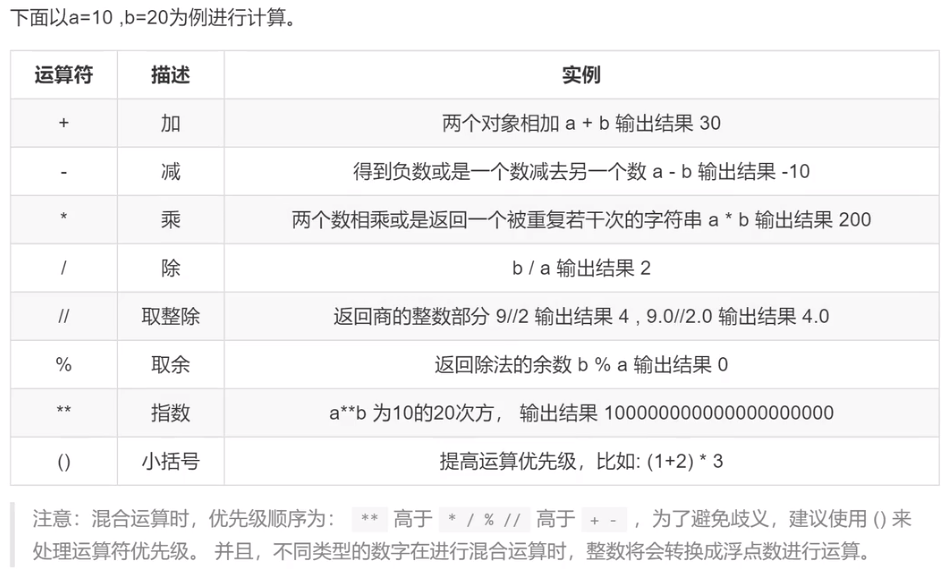
-5 // 2 # -3
赋值运算符
a = b = c = d = 'hello'
a,b = b,a #交换值
a,b = 1,2 #a=1,b=2
a,*b,c = 1,2,3,4,5 # a=1 b=[2,3,4] c=5
if (n:=len(a)) > 1:
print(f'{n}')
比较运算符
返回布尔值,字符串之间使用,会根据各个字符的编码值逐一进行比较。

逻辑运算符
and :只要有一个运算是False,结果就是False。取值时取第一个为False的值,否则取最后一个为True的值。
or :只要有一个运算是True,结果就是True。取值时取第一个为True的值,否则取最后一个为False的值。
位运算符
a=23 # 0001 0111
b=15 # 0000 1111
位与 &:同为1则为1,否则为0
a&b = 0000 0111 # 7
位或 |:有一个为1就是1,否则为0
a|b = 0001 1111 # 31
位异或 ^:相同为0,不同为1
a^b = 0001 1000 # 24
位左移<<:左移n位,右边补n个0。
0b0101<<2 = 0b10100 # 等于5 * 2**n
位右移>>:右移n位,左边补n个0。
0b1111>>2 = 0b11 # 等于15/2**n 取整
成员运算符
in not in 用来判断一个对象在指定可迭代对象中是否存在
身份运算符
is 是判断两个标识符是不是引用自一个对象(内存地址),是返回True,否则返回False
id()函数用于获取对象内存地址
流程控制
判断语句
if 判断条件:
条件成立时执行的代码
else:
条件不成立时执行的代码

三元表达式
x = exp if a > b else exp2
循环语句
while语句
while <expr>:
<statement(s)>
else:
<additional_statement(s)>

for语句
for <variable> in <sequence>:
<statements>
else:
<statements>
break
结束整个循环过程
continue
结束本次循环,并开始下次循环
嵌套循环
例子:打印九九乘法表
for i in range(1,10):
print('')
for t in range(1,i+1):
print(str(t)+'*'+str(i)+'='+str(i*t)+'\t',end='')
字符串
字符串的使用
-
python中 单引号和双引号使用完全相同。
-
使用三引号('''或""")可以指定一个多行字符串。
-
反斜杠可以用来转义,使用r可以让反斜杠不发生转义。
如 r"this is a line with \n" 则\n会显示,并不是换行。
-
按字面意义级联字符串,如"this " "is " "string"会被自动转换为
''this is string''
-
字符串可以用 + 运算符连接在一起,用 * 运算符重复。
转义字符
在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| \(行尾) | 续行符 |
| \\ | 反斜杠符号 |
| \' | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
字符串运算符
| 操作符 | 描述 |
|---|---|
| + | 字符串连接 |
| * | 重复输出字符串多次 |
| [ ] | 通过索引获取字符串中字符 |
| [ a:b:c] | 截取字符串中的一部分,遵循左闭右开原则,c是步长向量单位 |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True |
字符串格式化
| 格式化符号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
format
Python2.6 开始增加format,'{}'.foramt()方法通过字符串中的大括号{}识别替换字段,从而完成格式化。
-
根据数字顺序传入参数
'大家好,我是{1},今年{0}岁了'.format(20,'段锐') -
根据变量名传入参数
'大家好,我是{a},今年{b}岁了'.format(b=20,a='段锐') -
什么都不写,一一对应
'大家好,我是{},今年{}岁了'.format('段锐',20) -
传入对象
class AssignValue(object): def __init__(self, value): self.value = value my_value = AssignValue(6) print('value 为: {0.value}'.format(my_value)) # "0" 是可选的
f-string 是 python3.6 之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。f-string 格式化字符串以 f 开头,后面跟着字符串,字符串中的表达式用大括号 {} 包起来,它会将变量或表达式计算后的值替换进去。
name = 'duanrui'
f'Hello {name}' #'Hello duanrui'
f'{1+2}' #'3'
用了这种方式明显更简单了,不用再去判断使用 %s,还是 %d。
在 Python 3.8 的版本中可以使用 = 符号来拼接运算表达式与结果。
f'{1+2=}' #'1+2=3'
字符串下标和切片

name = 'hello world'
name[2:4] # 'll'
name[1:] # 'ello world'
name[:] # 'hello world'
name[::-1] # 'dlrow olleh'
字符串方法
| 方法 | 描述 |
|---|---|
| 大小写相关 | |
| capitalize() | 把字符串的第一个字符改为大写 |
| title() | 单词首字母大写,其余是小写 |
| upper() | 转换字符串中的所有小写字符为大写 |
| lower() | 转换字符串中所有大写字符为小写 |
| casefold() | 把整个字符串的所有字符改为小写 |
| swapcase() | 翻转字符串中的大小写 |
| 查询相关 | |
| find(sub,start,end) | 检测 sub 是否包含在字符串中,如果有则返回索引值,否则返回 -1,start 和 end 参数表示范围,可选。 |
| rfind(sub, start,end) | 从右边开始查找 |
| index() | 跟 find 方法一样,如果 sub 不在 string 中会产生异常 |
| rindex() | 从右边开始查找 |
| 判断相关 | |
| startswith(sub,start,end) | 检查字符串是否以 sub 开头,是返回 True,否则返回 False。start 和 end 参数可以指定范围检查,可选。 |
| endswith(sub, start,end) | 检查字符串是否以 sub 字符串结束,如果是返回 True,否则返回 False。start 和 end 参数表示范围 |
| isalnum() | 如果字符串至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False。 |
| isalpha() | 如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False。 |
| isdigit() | 如果字符串只包含数字则返回 True,否则返回 False。 |
| istitle() | 如果字符串是标题化(所有的单词都是以大写开始,其余字母均小写),则返回 True,否则返回 False。 |
| isupper() | 如果字符串中至少包含一个区分大小写的字符,并且这些字符都是大写,则返回 True,否则返回 False。 |
| islower() | 如果字符串中至少包含一个区分大小写的字符,并且这些字符都是小写,则返回 True,否则返回 False。 |
| isnumeric() | 如果字符串中只包含数字字符,则返回 True,否则返回 False。 这种方法是只针对unicode对象 |
| isspace() | 如果字符串中只包含空格,则返回 True,否则返回 False。 |
| isdecimal() | 如果字符串只包含十进制数字则返回 True,否则返回 False。 |
| 空格相关 | |
| strip([chars]) | 删除字符串前边和后边所有的空格,chars 参数可以定制删除的字符,可选。 |
| lstrip() | 去掉字符串左边的所有空格 |
| rstrip() | 删除字符串末尾的空格。 |
| ljust(width,[s]) | 返回一个左对齐的字符串,并使用空格填充至长度为 width 的新字符串。 填充的字符,可选 |
| rjust(width) | 返回一个右对齐的字符串,并使用空格填充至长度为 width 的新字符串。 |
| center(width) | 将字符串居中,并用空格填充至长度 width 的新字符串 |
| zfill(width) | 返回长度为 width 的字符串,原字符串右对齐,前边用 0 填充。 |
| 分隔相关 | |
| partition(sub) | 找到第一次出现的 sub,把字符串分成一个 3 元组 (pre_sub, sub, fol_sub),如果字符串中不包含 sub 则返回 ('原字符串', '' , '' ) |
| rpartition(sub) | 类似于 partition() 方法,不过是从右边开始查找。 |
| split(sep=None, maxsplit=-1) | 不带参数默认是以空格为分隔符切片字符串,如果 maxsplit 参数有设置,则仅分隔 maxsplit 个子字符串,返回切片后的列表,不包括分隔字符。 |
| splitlines(True) | 在输出结果里是否去掉换行符,默认为 False,不包含换行符;如果为 True,则保留换行符 |
| join(sub) | 以字符串作为分隔符,插入到 sub 中所有的字符之间。 |
| replace(old, new[, count]) | 把字符串中的 old 子字符串替换成 new 子字符串,如果 count 指定,则替换不超过 count 次。 |
| encode(encoding='utf8') | 以 encoding 指定的编码格式对字符串进行编码。 |
| count(sub[, start[, end]]) | 返回 sub 在字符串里边出现的次数,start 和 end 参数表示范围,可选。 |
| expandtabs([tabsize=8]) | 把字符串中的 tab 符号(\t)转换为空格,如不指定参数,默认的空格数是 tabsize=8。 |
| translate(table) | 根据 table 的规则(可以由 str.maketrans('a', 'b') 定制)转换字符串中的字符。 |
| len() | 获取字符串长度 |
字符集和编码
计算机只能处理数字(其实就是数字0和数字1),如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit) 作为一个字节(byte) 所以, 一个字节能表示的最大的整数就是255 (二进制11111111=十进制255),0-255被用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码。
ASCII码表使用7位二进制表示一个字符,它的区间范围时0~127, 一共只能表示128个字符,仅能支持英语。随着计算机科学的发展,西欧语言、希腊语、泰语、阿拉伯语、希伯来语等语言的字符也被添加到码表中,形成了一个新的码表IS08859-1 (又称为Latin1 )码表。IS08859-1使用8位二进制表示一个字符串,完全兼容ASCII码表。
Unicode (统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
字符和编码相互转化
ord('你') # 20320 获取字符对应的编码
chr(97) # 'a' 获取编码对应的字符
编码规则
使用Unicode为每种语言的每个字符都设定了唯一的二进制编码, 但是它还是存在一定的问题,不够完美。例如,汉字"你"转换成为一个字符结果是ex4f60,转换成为二进制就是01001111 0100000,此时就有两个问题:
- 1001111 1100000 到底是一个汉字"你",还是两个Latin1字符?
- 如果Unicode进行了规定,每个字符都使用n个八位来表示,对于Latin1字符来说,又会浪费很多存储空间。
- 为了解决这个问题,就出现了一些编码规则,按照一定的编码规则对Unicode数字进行计算, 得出新的编码。在中国常用的字符编码有GBK,Big5 和 utf8 这三种编码规则。
- 使用字符串的encode方法,可以将字符串按照指定的编码格式转换成为二进制,使用decode方法,可以将一个二进制数据按照指定的编码格式转换成为字符串。
# GBK utf-8 BIG5
#字符串转换成为指定编码集结果
#GBK编码,一个汉字占两个字节
print('你'.encode('gbk')) # b'\xc4\xe3’ 50403
#11000100 11100011
# utf8编码,一个汉字占三个字节
print('你'.encode('utf8')) # b'\xe4\xbd\xa0' 14990752
#11100100 10111101 10100000
列表
列表的格式
-
列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)
-
列表写在方括号之间,元素用逗号隔开。
-
和字符串一样,列表可以被索引和切片。
-
列表可以使用+操作符进行拼接。
-
列表中的元素是可以改变的。
创建列表
-
[元素1,元素2,元素3,元素4,元素5···] -
list(iterable)
列表下标和切片

列表的增删改查
-
添加元素的方法:
-
append(x)在列表末尾添加元素names = ['王二','张三','李四'] names.append('段锐') print(names) # ['王二','张三','李四','段锐'] -
insert(n,x)在指定位置插入元素names = ['王二','张三','李四'] names.insert(1,'段锐') print(names) # ['王二','段锐',张三','李四'] -
extend([x])合并两个列表names = ['王二','张三','李四'] names.extend(['李明','小红']) print(names) # ['王二',张三','李四','李明','小红']
-
-
删除元素的方法:
-
pop(n)默认删除列表里最后一个数据,并返回。还可以传入n参数,删除指定位置元素。
names = ['王二','张三','李四'] names.pop() # ['王二',张三'] '李四' names.pop(0) # ['张三'] -
remove(x)删除列表指定元素的第一个,如果不存在会报错names = ['王二','张三','李四'] names.remove('王二') # ['张三','李四'] names.remove('小红') #ValueError: list.remove(x): x not in list
-
clear()用来清空一个列表所有元素names = ['王二','张三','李四'] names.clear() print(names) # [ ] -
del list[n]删除列表第n+1个元素names = ['王二','张三','李四'] def names[0] #['张三','李四']
-
-
查询元素的方法:
-
index(x[,start[,end]])返回x第一次在列表出现的位置的索引,元素不存在就报错names = ['王二','张三','李四'] names.index('张三') # 1 -
count(x)返回x在列表中出现的次数[1,2,3,3,4].count(3) # 2 -
in列表是否存在某个元素names = ['王二','张三','李四'] '段锐' in names #False
-
-
修改元素的方法:
-
使用下标直接修改列表中元素的值
names = ['王二','张三','李四'] names[1] = '段锐' # ['王二','段锐','李四']
-
列表的操作
list.sort(key=None,reverse=False) key是排序作为根据的元素,reverse默认升序,True是降序。排序作用于原列表。
list.reverse() 翻转整个列表
len(list) 返回列表长度
max(list) 返回列表中元素的最大值
min(list) 返回列表中元素的最小值
列表的复制
用赋值运算符的话只是对内存地址的传递,为列表增加了一个引用,因为列表是可变数据类型,所以对列表进行修改,会改变被赋值对象的值。
list.copy() 浅拷贝一个新列表并返回,只会复制最外层的对象,里面的数据不会拷贝。切片也是一个浅拷贝。
a=[1,2,3,[1,2,3]]
b=a.copy() #浅拷贝 b=[1,2,3,[1,2,3]]
a[0]=0 # a [0,2,3,[1,2,3]] b [1,2,3,[1,2,3]]
a[3][0]=0 # a [0,2,3,[0,2,3]] b [1,2,3,[0,2,3]]
copy.deepcopy() 深拷贝,完全拷贝一个对象及其子对象。
import copy
c=copy.deepcopy(a) #深拷贝 # c [1,2,3,[1,2,3]]
a[3][0]=0 # a [1,2,3,[0,2,3]] c [1,2,3,[1,2,3]]

列表的遍历
enumerate(seq[,start=0]) 函数用于将一个可遍历的数据对象(如列表、元组或字符串)和它的数据下表组合为一个元组,一般用在 for 循环当中。
- sequence -- 一个序列、迭代器或其他支持迭代对象。
- start -- 下标起始位置
list1 = ['a','b','c']
for i,t in enumerate(list1,start=1):
print(f'第{i}个元素是:{t}')
#第1个元素是:a
#第2个元素是:b
#第3个元素是:c
列表推导式
语法:[表达式 for 变量 in 序列或可迭代对象 [if 表达式]]
[i*2 for i in range(5)]
# [0,2,4,6,8]
[i for i in range(10) if i%2!=0]
# [1,3,5,7,9]
[i if i%2!=0 else 0 for i in range(10)]
# [0, 1, 0, 3, 0, 5, 0, 7, 0, 9]
[i*t for i in 'abc' for t in range(1,3)]
# ['a', 'aa', 'b', 'bb', 'c', 'cc']
元组
元组的格式
- 与字符串一样,元组的元素不能修改。
- 元组也可以被索引和切片,方法一样。
- 只有一个元素的元组:(1,)
- 元组也可以使用+操作符进行拼接。
- 元组使用小括号,元素之间使用逗号隔开。
创建元组
-
(1,2,3,4,5) -
tuple(iterable)
访问元组
通过下标获取元素,但不能修改
a=(1,2,3,4,5)
print(a[0]) # 1
a[0] = 0
#TypeError:'tuple' object does not support item assignment
元组的操作
tuple.count() 统计一个元素在元组出现的次数
tuple.index() 返回某元素第一次出现在元组的位置,没有则报错
max(tuple) 返回元组中元素的最大值
min(tuple) 返回元组中元素的最小值
序列
共同点:
- 都可以通过索引得到每一个元素
- 默认索引值总是从0开始(当然python也支持负数索引)
- 可以通过分片的方法得到一个范围内的元素的集合
- 有很多共同的操作符(重复/拼接/成员关系操作符)
| 运算 | 描述 | 魔法方法 |
|---|---|---|
| x in s | 成员身份测试 | _contains_ |
| s1 + s2 | 返回新的合并序列 | _add_ |
| s * n | 重复序列n次 | _mul_ |
| s [ i ] | 偏移量索引 | _getitem_ |
| s[i:j:x] | 序列切片 | |
| len(s) | 序列长度 | _len_ |
| min(s) | 返回序列元素最小值 | |
| max(s) | 返回序列元素最大值 | |
| index(s) | 返回中第一次出现s元素的位置的索引 | |
| count(s) | 返回序列中s出现的总次数 |
字典
字典的格式
-
字典是另一种可变容器模型,且可存储任意类型对象。
-
字典的每个键值(key=>value)对用冒号(:)分割,每个键值对之间用逗号(,)分割,整个字典包括在花括号{ }中。
-
键必须是唯一的,但值则不必。
-
值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
-
如果创建时同一个键被赋值两次,后一个值会覆盖前一个
创建字典
{键1:值1,键2:值2,键3:值3, ... 键n:值n}dict(one=1,two=2,three=3)dict(zip(['one','two','three'],[1,2,3]))
字典的增删改查
-
查找数据:
-
使用
key获取对应的valuedict1={'a':1,'b':2,'c':3} print(dict1['a']) # 1 -
get(key[,default=None])返回键对应的value,如果key不存在返回defaultdict1={'a':1,'b':2,'c':3} print(dict1.get('a')) # 1 print(dict1.get('d')) # None -
setdefault(key[,default=None])如果key不存在,就会添加该键并将value设置为default并返回dict1={'a':1,'b':2,'c':3} print(dict1.setdefault('a')) # 1 print(dict1.setdefault('d',4)) # 4
-
-
修改数据:
-
使用
key修改对应的value,如果key在字典不存在,就添加该键值对。dict[key]=value
-
-
删除数据:
-
pop(key[,default])删除字典给定key的键值对,返回值为被删除的值。key值必须给出,如果key不存在则返回default值dict1={'a':1,'b':2,'c':3} dict1.pop('a') # 1 dict1.pop('d',4) # 4 -
popitem()随机删除并返回字典中的一个键值对(字典无序)dict1={'a':1,'b':2,'c':3} dict1.popitem() # ('c',3) -
clear()清空字典dict1={'a':1,'b':2,'c':3} dict1.clear() print(dict1) # { } -
del删除指定键值对dict1={'a':1,'b':2,'c':3} del dict1['a']
-
-
增加数据:
-
update把两个字典合并成为一个字典dict1.update(dict2)dict1={'a':1,'b':2,'c':3} dict1.updata({'d':4}) # {'a':1,'b':2,'c':3,'d':4}
-
字典的遍历
dict1 = {'a':1,'b':2,'c':3}
for i in dict1 #遍历的是键
dict1.keys() #获取所有键 dict_keys(['a', 'b', 'c'])
dict1.values() #获取所有值 dict_values([1, 2, 3])
dict1.items() # dict_items([('a', 1), ('b', 2), ('c', 3)])
for key,value in dict1.items()
字典成员运算符
in 判断某个值是否是字典的键
字典推导式
{v:k for k,v in dict.items()}
集合
集合的格式
- 集合(set)是一个无序的不重复元素序列。
- 可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建集合
{1,2,3,4,5}set(iterable)
集合的增删改查
-
增加元素:
-
add向集合添加指定元素set.add(x)set1={1,2,3} set1.add(4) # {1,2,3,4}
-
-
删除元素:
-
pop()随机删除一个元素并返回
set1={1,2,3}
set1.pop() # 1- `remove(x)` 删除指定元素 ```python set1={1,2,3} set1.remove(1) # {2,3}-
discard(x)删除指定元素,如果不存在,也不报错set1={1,2,3} set1.discard(4) -
clear清空集合set1={1,2,3} set1.clear() # set()
-
-
修改集合:
-
union(x)返回新的两个集合的并集(原集合不改变)set1={1,2,3} set2={4,5,6} set1.union(set2) # {1,2,3,4,5,6} set1 | set2 # {1,2,3,4,5,6} 等价 -
intersection(set1,set2..)返回新的多个集合的交集{1,2,3}.intersection({2,3,4}) # {2,3} {1,2,3} & {2,3,4} # {2,3} -
intersection_update(set1,set2..)原始集合变为交集{1,2,3}.intersection_update({3,4,5}) # {3} -
difference()返回A-B的集合{1,2,3,4}.difference({3,4,5,6}) # {1,2} {1,2,3,4} - {3,4,5,6} # {1,2} -
difference_update()原始集合变为差集{1,2,3}.difference_update({3,4,5}) # {1,2} -
isdisjoint(set)判断两个集合是否有交集,没有返回True{1,2,3}.isdisjoint({3,4,5}) # False -
issubset()判断集合的所有元素是否都包含在指定集合中{1,2}.issubset({1,2,3}) # True -
issuperset()和上面相反{1,2,3}.issuperset({1,2}) # True -
symmetric_difference()返回新的差集{1,2,3}.symmetric_difference({2,3,4})#{1,4} {1,2,3} ^ {2,3,4} # {1,4} -
symmetric_difference_update()原始集合变差集{1,2,3}.symmetric_difference({2,3,4})#{1,4}
-
集合推导式
{i for i in iterable}
函数
-
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
-
函数能提高应用的模块性,和代码的重复利用率。
函数的格式
-
函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
-
由数字字母下划线组成,不能以数字开头;严格区分大小写;不能使用关键字
-
任何传入参数和变量必须放在括号中间,括号之间可以用于定义参数。
-
函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
-
函数内容以冒号起始,并且缩进。
-
函数在执行过程中只要遇到return语句,就会停止执行并返回结果,如果未在函数中指定return,那这个函数的返回值为None。
-
函数重名时,后一个会覆盖前一个
函数的创建和使用
def 函数名(参数):
函数体 #用缩进控制代码块
return 返回值
函数名(参数) #调用函数 可以接受返回值
函数的参数
形参与实参
形参变量:只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参变量:可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
python 函数的参数传递:
-
不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
def ChangeInt( a ): a = 10 b = 2 ChangeInt(b) print( b ) # 结果是 2 -
可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(list),则是将 list 真正的传过去,修改后外部的list也会受影响。
def changeme( mylist ): "修改传入的列表" mylist.append([1,2,3,4]) print ("函数内取值: ", mylist) # 调用changeme函数 mylist = [10,20,30] changeme( mylist ) print ("函数外取值: ", mylist) #函数内取值: [10, 20, 30, [1, 2, 3, 4]] #函数外取值: [10, 20, 30, [1, 2, 3, 4]]
-
位置参数
必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
def fun(a,b) print(a+b) fun(1,2) # 3 -
关键字参数
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
传参时关键字参数必须在位置参数之后
def printme( str, s ): print (s,'の',str) # "打印任何传入的字符串" #调用printme函数 printme( s='段锐',str = "菜鸟教程") # 段锐の菜鸟教程 -
默认参数
调用函数时,默认参数可有可无,非必须传递,其他参数可以赋值。
默认参数必须放在位置参数后面! 默认参数必须指向不变对象!
def fun(a,b=1) print(a+b) fun(1,) # 2 -
不定长参数
一个星号 ***** 的
*args可变参数允许你传入任意个位置参数,这些关键字参数在函数调用时自动组装为一个tuple。def pf(*args): print (args) # "打印任何传入的参数" pf( 1,2,3 ) # (2, 3)两个星号的
**kwargs可变参数允许你传入任意个关键字参数,这些关键字参数在函数调用时自动组装为一个dict。def pf(**kwargs): kwargs.setdefault('d','dr') print (kwargs) # "打印任何传入的参数" pf(c=3,d=4) # {'c':3, 'd':4} d={'a':1,'b':2,'c':3} pr(**d) # {'a':1, 'b':2, 'c':3, 'd':'dr'}
当你在一个程序中使用变量名时,python创建、改变或查找变量名都是在所谓的命名空间中进行的,也就是我们要说的变量的作用域。在代码中给一个变量赋值的地方决定了这个变量将存在于哪一个命名空间,也就是他的可见范围。
def之中的变量名和def之外的变量名并不冲突,一个在def之外被赋值(例如,在另外一个def之中或者在模块文件的顶层)的变量X与在这个def之中赋值的变量X是完全不同的变量。
所以我们看出,变量的作用域完全是由变量在程序文件中源代码的位置而决定,而不是由函数调用决定。
函数的文档说明
def f(a:int,b:int):
'''
:params: a,建议是int
:params: b,建议是int
:return: 返回两个数字相加的结果
'''
return a+b
函数的返回值
一般情况下,一个函数只会执行一个return 语句,有finally 可能执行多个。
函数的返回值可以是任意类型,一般多个返回值时用元组
def f(a,b,c,d):
return a+b,c+d
x,y = f(1,2,3,4)
print(x,y) # 3 7
全局变量和局部变量
局部变量在函数内定义,只在函数内生效,这个函数就是这个变量的作用域。
如果局部变量和全局变量同名,那么会在函数内重新定义新的一个局部变量。
函数内部想要修改全局变量,使用global 对变量声明,通过函数修改值。
locals()查看局部变量 global 查看全局变量
递归函数
如果一个函数在内部调用自身本身,那么这个函数就是递归函数。
斐波那契数列:
def fb(n):
if n==1 or n==2:
return 1
return fb(n-1)+fb(n-2)
匿名函数
python 使用 lambda 来创建匿名函数。
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
sum = lambda arg1, arg2: arg1 + arg2
sum(1,2) # 3
内置函数
数学相关
abs() 返回数字的绝对值,如果参数是一个复数,则返回它的大小
divmod(a,b) 返回一个包含商和余数的元组(a // b, a % b)
max() 返回给定参数的最大值,参数为序列
min() 返回给定参数的最小值,参数为序列
pow(x,y,z) 返回 x**y % z 的值
round(x,n) 四舍五入到指定几位小数
sum(x,n) 对序列进行求和计算,最后加n
cmp(x,y) 需要import operator 比较2个对象,如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1
complex(r,n) 创建一个值为r+ni 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需 要指定第二个参数。
range() 创建一个整数列表
可迭代对象相关
all() 判断给定的 iterable 中的所有元素是否都为 True,如果是返回 True,否则返回 False
any() 判断给定的 iterable 如果有一个为 True,就返回 True,否则返回False
len() 返回可迭代对象长度
iter() 把可迭代对象转换为迭代器
next(iterator[, default]) 返回迭代器的下一个项目,defaule设置在没有下一个元素时返回的默认值,如果不设置,又没 有下一个元素则会触发 StopIteration 异常。
sorted(iterable, key=None, reverse=False) 对可迭代对象排序,key--指定函数的返回值是用来进行比较的元素
enumerate(seq, [start=0]) 同时列出数据和数据下标,可指定下标起始位置
filter(function, iterable) 序列的每个元素作为参数传递给函数进行判断,最后将返回 True 的元素放到迭代器中
frozenset() 返回一个不可变集合,冻结后集合不能再添加或删除任何元素
map(function, iterable) 根据提供的函数对指定序列做映射,返回一个迭代器
zip([iterable, ...]) 对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,list转换为列表查看
reversed() 颠倒序列元素
slice(start, stop[, step]) 实现一个切片对象
xrange() 和range 用法相同,返回一个生成器
转换相关
bin() 转换为二进制
oct() 转换为八进制
hex() 转换为十六进制
chr() 将字符编码换成对应的字符
ord() 把字符换成对应的字符编码
eval() 执行字符串里的表达式
list() 把可迭代对象转换为列表
tuple() 把可迭代对象转换为列表
dict() 生成字典dict(zip(['one', 'two', 'three'], [1, 2, 3])) dict(a='a', b='b', c='c')
set() 创建一个无序不重复元素集
bool() 将给定参数转换为布尔类型,bool 是 int 的子类
int() 将一个字符串或数字转换为整型
float() 将整数和字符串转换成浮点数
repr() 返回一个对象的 string 格式
str() 将对象转化为适于人阅读的形式
compile() 将一个字符串编译为字节代码
unichr() 返回 unicode 的字符
输入输出相关
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)
input() 一个标准输入数据,返回为 string 类型
format() 字符串格式化函数
类和对象相关
dir() 不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时返回参数的属性、方法列表
help() 查看函数或模块用途的详细说明
globals() 以字典类型返回当前位置的全部全局变量
locals() 以字典类型返回当前位置的全部局部变量
vars() 返回对象object的属性和属性值的字典对象
callable() 检查一个对象是否是可调用的。如果返回 True,object 仍然可能调用失败;但如果返回 False,调用对象 object 绝对不会成功。
classmethod(cls) 类方法修饰符
staticmethod() 静态方法修饰符
getattr(object, name[, default]) 返回对象属性值
setattr(object, name, value) 设置属性值,该属性不一定是存在的
delattr(x,y) 用于删除属性,delattr(x, 'foobar')相等于 del x.foobar
hasattr(object, name) 判断对象是否包含对应的属性
isinstance(object, classinfo) 判断一个对象是否是classinfo的实例,类似 type(),type不考虑继承
issubclass(object, classinfo) 判断参数 object 是否是类型参数 classinfo 的子类
property() 在新式类中返回属性值
super() 调用父类(超类)的一个方法 super().__init__()
其他
exec() 执行储存在字符串或文件中的Python语句
hash() 获取一个对象的哈希值
id() 返回对象的内存地址
open() 打开一个文件,创建一个 file 对象
exit() 以指定退出码结束程序
高阶函数
- 把一个函数当作另一个函数的返回值
- 把函数当作参数传入另一个函数
偏函数
当函数的参数个数太多,需要简化时,使用functools.partial可以创建一个新的函数,这个新函数可以固定住原函数的部分参数,从而在调用时更简单
闭包
- 内部函数总是可以访问其所在的外部函数中声明的参数和变量,即使在其外部函数被返回
- 让外部访问函数内部变量成为可能
- 局部变量会常驻在内存,会造成内存泄漏(有一块内存空间被长期占用,而不被释放)
- 可以避免使用全局变量,防止全局变量污染
- 内部函数修改外部函数的局部变量使用
nonlocal
装饰器
在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。
def log(func): # 接受一个函数作为参数,并返回一个函数
def wrapper():
print('call %s():' % func.__name__)
return wrapper
@log # @语法定义一个函数作为装饰器,把@log放到now()函数的定义处,相当于执行了语句
def now(): # now = log(now) = wrapper
print('now被调用了!')
now() # 调用 now函数其实相当于调用 wrapper()
# call now():
# now被调用了!
高级装饰器
给装饰器传参,需要在原有装饰器基础上再加一层函数
USER_PERMISSION =15 # 1111
DEL_PERMISSION = 8 # 1011 & 1000 ==> 1000
READ_PERMISSION = 4 # 1011 & 0100 ==> 0000
WRITE_PERMISSION = 2 # 1011 & 0010 ==> 0010
EXE_PERMISSION = 1 # 1011 & 0001 ==> 0001
def check_permission(x, y):
def handle_action(fn):
def do_action():
if x &y!=0: #有权限,可以执行,通过按位与运算检查权限
fn()
else:
print('对不起,您没有响应的权限')
return do_action
return handle_action
@check_permission(USER_PERMISSION,READ_PERMISSION)
def read():
print('正在读取')
@check_permission(USER_PERMISSION,WRITE_PERMISSION)
def write():
print('正在写入')
@check_permission(USER_PERMISSION,EXE_PERMISSION)
def exe():
print('正在执行')
@check_permission(USER_PERMISSION,DEL_PERMISSION)
def delete():
print('正在删除')
read()
write()
exe()
delete()
模块
- 模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py
- 一个模块只会被导入一次,不管你执行了多少次
import - 模块名必须遵守命名规则
导入模块的方法
import模块名 导入整个.py文件from包 \ 模块名import模块 \ 函数名from模块名import* 导入模块中所有的方法和变量import模块 as t 给模块起一个别名from包名import模块 as t
pip
-
pip install <package_name>用pip下载一个第三方模块 -
pip uninstall <package_name>用pip卸载一个第三方模块 -
pip list列出当前环境安装的所有包,包括无法卸载的 -
pip freeze列出当前环境安装的模块名和版本号 -
pip freeze > <file_ name>生成一个已安装模块的列表文件 -
pip install -r <file_ name>读取文件里模块名和版本号并安装 -
pip install <package_ name> -i <url>从指定的地址下载包除了临时修改pip的下载源以外,我们还能永久改变pip的默认下载路径。
在当前用户目录下创建一个pip的文件夹,然后再在文件夹里创建pip.ini文件并输入一下内容:[global] index-url=https://pypi.douban.com/simple [install] trusted-host=pypi.douban.com常见国内镜像
_all_
使用from 模块名 import * 时,如果模块存在一个叫做 __all__ 的列表变量,那么导入这个列表中所有的变量和函数。
如果模块里没有__all__ ,会导入所有不以_ 开头的变量和函数。
_main_
每个模块都有一个__name__属性,当其值是__main__时,表明该模块自身在运行,否则是被引入。
# useing.py
if __name__ == '__main__':
print('程序自身在运行')
else:
print('我来自另一模块')
python useing.py # 程序自身在运行
import useing # 我来自另一模块
包
在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包。一个模块就是一个 .py文件,在Python里为了对模块分类管理,就需要划分不同的文件夹。多个有联系的模块可以将其放到同一个文件夹下,为了称呼方便, 一般把Python里的一个代码文件夹称为一个包。
__init__.py文件为空时仅仅只是把包导入,不能使用其他模块
在__init__.py文件中,定义一个__all__变量, 它控制着 from 包名 import * 时能导入的模块。
注意当使用 from package import item 这种形式的时候,对应的 item 既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
import 语法会首先把 item 当作一个包定义的名称,如果没找到,再试图按照一个模块去导入。如果还没找到,抛出一个 ImportError异常。
反之,如果使用形如 import item.subitem.subsubitem 这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字
面向对象
面向对象技术简介
- 类(Class): 用来描述一类具有相同的属性和方法的对象的集合。它定义对象所共有的属性和方法。对象是类的实例。
- 方法:类中定义的函数。
- 类变量:类变量在类和对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 局部变量:定义在方法中的变量,只作用于当前实例的类。
- 实例变量:在类的声明中,属性是用变量来表示的,实例变量就是一个用 self 修饰的变量。
- 数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,这个过程叫方法的覆盖(override),也称为方法的重写。
- 继承:即一个派生类(derived class)继承基类(base class)的属性和方法。例如一个Dog类的对象派生自Animal类
- 实例化:创建一个类的实例,类的具体对象。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
Python中的类提供了面向对象编程的所有基本功能:类的继承机制允许继承多个基类,派生类可以覆盖基类中的任何方法,方法中可以调用基类中的同名方法。对象可以包含任意数量和类型的数据。
相比较函数,面向对象是更大的封装,根据职责在一个对象中封装多个方法
- 在完成某一个需求前,首先确定职责一要做的事情 (方法)
- 根据职责确定不同的对象,在对象内部封装不同的方法(多个)
- 最后完成的代码,就是顺序地调用不同对象的相应方法。
特点:
-
注重对象和职责,不同的对象承担不同的职责。
-
更加适合应对复杂的需求变化,是专门应对复杂项目开发,提供的固定套路。
类的定义
类名一般遵守大驼峰命名法,每一个单词的首字母大写。
class MyClass:
def __init__(self,a,b): #构造方法,初始化对象的属性,该方法会在类实例化时自动实现
self.a=a #self 代表类的实例
self.b=b
def add(self):
return self.a+self.b
# 实例化类
x = MyClass(1,2) # 把 1 传给 a 2 传给 b
# 访问类的属性和方法
print("MyClass 类的属性有:", x.a,x.b) #MyClass 类的属性有: 1 2
print("MyClass 类的方法add输出为:", x.add()) #MyClass 类的方法 f 输出为: 3
-
类实例化时首先调用
__new__方法,给对象申请一段内存空间 -
调用
__init__方法,传入参数,初始化对象,并将self指向申请好的内存空间,填充数据 -
让 X 也指向刚刚的内存空间
self的使用
-
给对象添加属性
python支持动态属性,当一个对象创建好了以后,直接使用对象.属性名=属性值就可以给对象添加一个属性。class Cat: pass tom = Cat() tom.name = 'Tom ' #可以直接给tom对象添加一个name 属性 -
self的概念
哪个对象调用了方法,方法里的self指的就是谁。通过self. 属性名可以访问到这个对象的属性;通过self.方法名()可以调用这个对象的方法。class Cat: def eat(self): print(f'{self.name}偷吃了小鱼干!') tom = Cat() tom.name = 'Tom' jerry = Cat() jerry.name = 'Jerry' tom.eat() # Tom偷吃了小鱼干! jerry.eat() # Jerry偷吃了小鱼干!
类属性
类属性就是类对象所拥有的属性,它被该类的所有实例对象所共有,类属性可以通过类对象或者实例对象访问。如果对象试图修改类属性,则会在对象的内存空间新生成一个同名的实例属性,下次访问时优先使用自己的属性。
类的方法
实例方法
使用 def 关键字来定义,类中的普通方法必须包含参数 self(可替换), 且为第一个参数,self 代表的是类的实例。
使用 对象.方法名(参数) 直接调用,不用向self 传值,调用时会自动将对象传给self
使用 类.方法名(对象,参数) 调用,需要手动将对象传给self
class MyClass:
def p(self):
print('Hello',self.name)
x = MyClass()
x.name = 'dr'
x.p() # 'Hello dr'
MyClass.p(x) # 'Hello dr'
类方法
如果一个方法里只用到了类属性,就可以在方法上面加上@classmethod 使它变成一个类方法。
class Dog:
s = 1
@classmethod
def ppp(cls):
cls.s+=10
print(cls.s)
Dog.ppp() # 11
tom = Dog()
tom.ppp() # 21
静态方法
如果一个方法里没有用到实例对象或者类里的任何属性,需在类成员函数前面加上@staticmethod标记符,以表示下面的成员函数是静态函数,不需要定义实例即可使用这个方法,多个实例共享此静态方法。
class Dog:
@staticmethod
def ppp():
print('ppp')
Dog.ppp() # ppp
tom = Dog()
tom.ppp() # ppp
私有属性和方法
在实际开发中,对象的某些属性或者方法可能只希望在对象的内部被使用,而不希望被外部访问到,这时就可以定义私有属性和私有方法。
定义方法
在定义属性或方法时,在属性名或者方法名前增加两个下划线 __ , 定义的就是私有属性或方法。
class Person:
def __init__ (self,name,age):
self.name = name
self.age = age
self.__money = 2000 # 使用__修饰的属性, 是私有属性
def __shopping(self,cost): # 使用__修饰的方法, 是私有方法
self.__money -= cost #__money 只能在对象内部使用
print( '还剩下%d元' % self.__money)
def test(self):
self.__shopping(500) #__shopping 方法也只能在对象内部使用
p = Person('dr',20)
p.__shopping(500) # AttributeError: 'Person' object has no attribute '__shopping'
p.test() # 还剩下1500元
print(p.__money) # AttributeError: 'Person' object has no attribute '__money'
print(p._Person__money) # 通过 _类名__属性名的方法间接访问
p._Person__shopping(200) # 通过 _类名__方法名的方法间接访问 还剩下1300元
被继承时,需要用对象.私有属性/方法所在的类名.私有属性/方法 调用
内置属性
_slots_ 限制类可以动态添加的属性
class Student:
__slots__ = ['name','age']
pass
xiaoming.name = 'xiaoming'
xiaoming.age = 20
xiaoming.foot = 40 # AttributeError: 'Student' object has no attribute 'foot'
_doc_ 显示类的描述信息,文档说明
_dict_ 以字典形式显示对象所有的属性和方法
_module_ 显示模块名, 在本模块为 _main_,被导入时为 xxx.py 的文件名
_class_ 显示是哪个类的实例
魔法方法
Python 的类里提供的,以两个下划线开始,两个下划线结束的方法就是魔法方法,魔法方法在恰当的时候就会被激活,自动执行
-
_init_
构造方法,在实例化一个对象时默认被调用,不需要手动调用。在开发中,如果希望在创建对象的同
时,就设置对象的属性,可以对__init__方法进行改造。class Cat: def __init__(self,name): print('init 方法被调用了') self.name = name tom = Cat('tom') # 'init 方法被调用了' print(tom.name) # 'tom' -
_del_
对象被销毁或删除引用时自动调用。
class Dog: def __del__(self): print('del 方法被调用了!') dog = Dog() del dog # 'del 方法被调用了!' -
_str_ \ \ _repr_
返回对象的描述信息,使用
print()函数打印对象时,其实调用的就是这个对象的_str_ 方法或者__repr__方法。 如果不做任何的修改,直接打印一个对象,是对象的类型以及内存地址。class Person: def __init__(self,name,age): self.name = name self.age = age def __str__(self): return self.name def __repr__(self): return str(self.age) p = Person('dr',20) print(p) # 修改前:<__main__.Person object at 0x000001E5FC9FCCF8> 修改后:'dr' p # '20' -
_call_
重写该方法后可以让对象像函数一样被调用,也可以传入参数。
class Person: def __call__(self,*args,**kwargs): print('call 方法被调用了') fn = kwargs['fn'] return list(filter(fn,args)) p = Person() print(p(*range(10),fn=lambda x:x%2==0)) #call 方法被调用了 [0, 2, 4, 6, 8] -
_eq_
==运算符会调用__eq__方法,如果没有重写,默认比较的是两个对象的内存地址。class Person(object): def __init__(self, name): self.name = name def __eq__(self, other): print('__eq__方法被调用了,other=', other) return self.name == other.name p1 = Person('zhangsan') p2 = Person('zhangsan') print(p1 is p2) #False is 比较的是内存地址 print(p1 == p2) #__eq__方法被调用了,other= <__main__.Person object at0x000002089C62EF28> True -
_ne_
!=运算符会调用 _ne_ 方法或者 _eq_ 方法取反 -
_gt_ \ \ _ge_ \ \ _lt_ \ \ _le_
>运算符会调用__gt__ 方法>=运算符会调用 _ge_ 方法<运算符会调用__lt__ 方法<=运算符会调用 __le__ 方法class Person(object): def __init__(self, age): self.age = age def __gt__(self, other): return self.age > other.age p1 = Person(20) p2 = Person(25) print(p1 is p2) # False print(p1 > p2) # False -
_add_
+运算符会调用__add__方法 -
_sub_
—运算符会调用__sub__方法 -
_mul_
*运算符会调用__mul__方法 -
_getitem_
对象 [ 属性名 ] 语法会调用 _getitem_ 方法
-
_setitem_
对象 [ 属性名 ] = xxx 语法会调用对象的 _setitem_ 方法
-
_delitem_
del 对象 [ 属性名 ] 语法会调用对象的 _delitem_ 方法
class Person(object): def __init__(self,name,age): self.name = name self.age = age def __setitem__(self,key,value): self.__dict__[key] = value def __getitem__(self,key): return self.__dict__[key] def __delitem__(self,key): print('delitem 被调用了') p = Person('dr',20) print(p.__dict__) # {'name': 'dr', 'age': 20} print(p['name']) # 'dr' p['phone'] = 111111 print(p['phone']) # 111111 del p['age'] # 'delitem 被调用了'
单例设计模式
- 确保一个类只有一个实例,单例类只能有一个实例。
- 单例类必须自己创建自己的唯一实例。
- 单例类必须给所有其他对象提供这一实例。
基于__new__方法实现的单例模式(推荐使用)
-
一个对象的实例化过程是先执行类的
__new__方法,如果没有重写,默认会调用object的__new__方法,返回一个实例化对象内存地址,然后再调用__init__方法,对这个对象进行初始化,我们可以根据这个实现单例. -
在一个类的
__new__方法中,先判断是不是存在实例,如果存在实例,就直接返回,如果不存在实例再创建. -
_new_ 至少要有一个参数cls,代表要实例化的类,此参数在实例化时由Python解释器自动提供
__new__ 必须要有返回值, 返回实例化出来的实例,这点在自己实现__ new__ 时要特别注意, 可以 return父类 __ new__ 出来的实例, 或者直接是object.__new__(cls) 出来的实例
class Singleton(object):
__instance = None # 判断是否单例的条件
__isset = True # 判断是否修改初始化属性的条件
def __new__(cls, *args,**kwargs): #申请内存,创建一个对象,并把对象的类型设置为cls
if not cls.__instance:
cls.__instance = object.__new__(cls)
return cls.__instance # 返回对象类型和开辟好的内存地址
def __init__ (self, a, b):
if self.__isset :
self.a = a
self.b = b
self.__isset = False
s1 = Singleton(1,2) #设置单例前: <__main__.Singleton object at 0x000001415A8CCCF8>
s2 = Singleton(3,4) # <__main__.Singleton object at 0x000001415A8DA208>
print(s1 is s2) # False
print(s1 is s2) #加判断后: <__main__.Singleton object at 0x000002A7463AEF28> True
print(s1.a,s1.b,s2.a,s2.b) #设置属性判断条件前 3 4 3 4
print(s1.a,s1.b,s2.a,s2.b) #设置属性判断条件后 1 2 1 2
继承
继承允许我们定义一个类然后继承另一个类的所有方法和属性。父类是被继承的类,也称为基类。子类是从另一个类继承下来的类,也称为派生类。Python允许多继承。
-
super()函数用于调用父类(超类)或兄弟类的一个方法。class A: def x(self): print('run A.x') super().x() print(self) class B: def x(self): print('run B.x') print(self) class C(A,B): def x(self): print('run C.x') super().x() print(self) C().x() #run C.x #run A.x #run B.x #<__main__.C object at 0x000002B5041BB710> #<__main__.C object at 0x000002B5041BB710> #<__main__.C object at 0x000002B5041BB710>super()是super(type, obj)的简写,在调用super()时,type参数传入的是当前的类,而obj参数则是默认传入当前的实例对象,在super()的后续调用中,obj一直未变,而实际传入的class是动态变化,不过,在首次调用时,MRO就已经被确定,是obj所属类(即C)的MRO,因此class参数的作用就是从已确定的MRO中找到位于其后紧邻的类,作为再次调用super()时查找该方法的下一个类。 -
__mro__方法查看多继承时方法的调用顺序(深度优先)
多态
让具有不同功能的函数可以使用相同的函数名,这样就可以通过传递不同的参数使一个函数实现不同功能。
多态的特点:
- 只关心对象的实例方法是否同名,不关心对象所属的类型;
- 对象所属的类之间,继承关系可有可无;
- 多态的好处可以增加代码的外部调用灵活度,让代码更加通用,兼容性比较强;
- 多态是调用方法的技巧,不会影响到类的内部设计。
文件处理
open方法
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True)
-
file: 必需,文件路径(相对或者绝对路径)
-
mode: 可选,文件打开模式
-
buffering: 设置缓冲
-
encoding: 一般使用utf8,默认GBK
-
errors: 报错级别
-
newline: 区分换行符
-
closefd: 传入的file参数类型
| 模 式 | 描 述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。文件不存在则报错。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件并清除原有内容。 如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加写入。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
文件操作方法
| 方 法 | 描 述 |
|---|---|
| file.close() | 关闭文件。关闭后文件不能再进行读写操作。 |
| file.flush() | 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| file.fileno() | 返回一个整型的文件描述符, 可以用在如os模块的read方法等一些底层操作上。 |
| file.isatty() | 如果文件连接到一个终端设备返回 True,否则返回 False。 |
| file.read([size]) | 从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| file.readline([size]) | 读取整行,包括 "\n" 字符。 |
| file.readlines([sizeint]) | 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| file.seek(offset[,whence]) | 移动文件读取指针到指定位置 |
| file.tell() | 返回文件当前位置。 |
| file.truncate([size]) | 从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 windows 系统下的换行代表2个字符大小。 |
| file.write(str) | 将字符串写入文件,返回的是写入的字符长度。 |
| file.writelines(sequence) | 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
CSV文件读写
CSV文件: Comma-Separated Values,中文叫逗号分隔值或者字符分割值,其文件以纯文本的形式存储表
格数据。可以把它理解为一个表格,只不过这个表格是以纯文本的形式显示的,单元格与单元格之间,默认
使用逗号进行分隔;每行数据之间,使用换行进行分隔。
要对csv文件进行写操作,首先要创建一个writer对象,调用writer对象的前提是:需要传入一个文件对象,然后才能在这个文件对象的基础上调用csv的写入方法writerow(写入一行)writerrow(写入多行)
import csv
headers = ['class','name','sex','height','year'] #表头
rows = [ # 嵌套列表,每个列表是一行
[1,'xiaoming','male',168,23],
[1,'xiaohong','female',162,22],
[2,'xiaozhang','female',163,21],
[2,'xiaoli','male',158,21]
]
with open('test.csv','w')as f:
f_csv = csv.writer(f) # f_csv = csv.DictWriter(f,headers)
f_csv.writerow(headers) # f_csv.writeheader()
f_csv.writerows(rows) # f_csv.writerows(rows)

在写入字典序列类型数据的时候,需要传入两个参数,一个是文件对象——f,一个是字段名称——fieldnames,到时候要写入表头的时候,只需要调用writerheader方法,写入一行字典系列数据调用writerrow方法,并传入相应字典参数,写入多行调用writerows
读取csv时需要使用reader,并传如一个文件对象,而且reader返回的是一个可迭代的对象,需要使用for循环遍历
import csv
with open('test.csv')as f:
f_csv = csv.reader(f)
for row in f_csv:
print(row)
#['class', 'name', 'sex', 'height', 'year']
#['1', 'xiaoming', 'male', '168', '23']..
sys输入输出
向内存中写入数据
除了将数据写入到一个文件以外,我们还可以使用代码将数据暂时写入到内存里,可以理解为数据缓冲区。Python中提供了StringIO和BytesIO这两个类将字符串数据和二进制数据写入到内存里。
StringIO可以将字符串写入到内存中,像操作文件一下操作字符串。
from io import StringIO
f = StringIO() #创建一个StringIO对象
f.write('hello') #可以像操作文件一样,将字符串写入到内存中
f.write('good')
print(f.getvalue()) # hellogood
print('hello',file =open('sss.txt','w')) # 把打印内容写入文件
标准输入 / 输出 / 错误输出
import sys
f = sys.stdin()
while True: #In: 'hello'
content = f.readline() #Out: 'hello'
print(content)
sys.stdout \ sys.stderr = open('sss.txt','w',encoding='utf8')
print('hello') #'hello'不显示在控制台,被写入到文件
print(1/0) # 错误也写入文件
上下文管理器
使用with处理的对象必须有 _enter__() 和 __exit_() 这两个方法。
其中 __enter__() 方法在语句体(with语句包裹起来的代码块)执行之前进入运行, _exit_() 方法在语句体执行完毕退出后运行。
with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后自动关闭、线程中锁的自动获取和释放等。
class Demo(object):
def __enter__(self):
print('__enter__方法被执行了')
return self
def __exit__ (self,exc_type, exc_val, exc_tb):
print('__exit__方法被调用了')
with Demo() as d: # as 变量名
print(d) #变量d不是Demo()的返回结果,它是创建的对象Demo()调用__enter__ 之后的返回结果self
#__enter__方法被执行了
#<__main__.Demo object at 0x000001B3D3A5EF28>
#__exit__方法被调用了
序列化和反序列化
通过文件操作。我们可以将字符串写入到一个本地文件。但是,如果是一个对象(例如列表、字典、元组等),就无法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里。
设计一套协议,按照某种规则,把内存中的数据转换为字节序列,保存到文件,这就是序列化,反之,从文件的字节序列恢复到内存中,就是反序列化。Python中提供了JSON和pickle两个模块用来实现数据的序列化和反序列化。
JSON
JSON(JavaScriptObjectNotation, JS对象简谱)是一种轻量级的数据交换格式, 它基于ECMAScript的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。JSON的本质是字符串!
json.dumps([x]) 方法的作用是把对象转换成为字符串,它本身不具备将数据写入到文件的功能。
json.dump([x],file) 把对象转换成为字符串的同时写入文件
json.loads(x) 将json字符串转换为Python对象
json.load(file) 从文件读取json字符串转换成Python对象
Python 编码为 JSON 类型转换对应表:
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float | number |
| True | true |
| False | false |
| None | null |
pickle
将Python中任意一种对象转换为二进制保存。
pickle.dumps([x]) 方法的作用是把对象转换成为二进制,它本身不具备将数据写入到文件的功能。
pickle.dump([x],file) 把对象转换成为二进制的同时写入文件
pickle.loads(x) 将二进制数据转换为Python对象
pickle.load(file) 从文件读取二进制数据转换成Python对象
异常处理
try
程序在运行过程中,由于我们的编码不规范,或者其他原因一些客观原因,导致我们的程序无法继续运行,
此时,程序就会出现异常。如果我们不对异常进行处理,程序可能会由于异常直接中断掉。为了保证程序的
健壮性,我们在程序设计里提出了异常处理这个概念。
try:
except:
else:
- 首先,执行 try 子句(在关键字 try 和关键字 except 之间的语句)。
- 如果没有异常发生,忽略 except 子句,try 子句执行后结束。
- 如果在执行 try 子句的过程中发生了异常,那么 try 子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的 except 子句将被执行。
- 如果一个异常没有与任何的 excep 匹配,那么这个异常将会传递给上层的 try 中
- else 子句将在 try 子句没有发生任何异常的时候执行
- finally 子句一定会被执行
- finally 里的返回值会覆盖之前的返回值
def demo(a, b):
try:
x=a/b
except ZeroDivisionError:
return '除数不能为0'
else:
return x
finally:
return ' good' # 如果函数里有finally, finally里的返回值会覆盖之前的返回值
print(demo(1, 2)) # good
print(demo(1, 0)) # good
自定义异常
class LengthError(Exception):
def __init__ (self,x,y):
self.x = x
self.y = y
def __str__ (self):
return '长度必须要在{}至{}之间'.format(self.x, self.y)
password = input( '请输入您的密码:')
m=6
n=12
if m <= len( password) <= n:
print('密码正确:')
else:
raise LengthError(m, n) #使用raise关键字可以抛出一个异常
'请输入您的密码:' 11
#__main__.LengthError: 长度必须要在6至12之间
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况
assert False # 条件为 false 触发异常
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AssertionError
迭代器和生成器
迭代器
- 迭代是Python最强大的功能之一,是访问集合元素的一种方式。
- 迭代器是一个可以记住遍历的位置的对象。
- 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
- 把一个类作为一个迭代器使用需要在类中实现两个方法
__iter__()与__next__()。 __iter__()方法返回一个特殊的迭代器对象, 这个迭代器对象实现了__next__()方法并通过 StopIteration 异常标识迭代的完成。
class MyNumbers:
def __iter__(self):
self.a = 0
return self
def __next__(self):
self.a += 1
if self.a>=5:
raise StopIteration
return self.a
w = MyNumbers()
for i in w:
print(i) # 1 2 3 4 5 6 ……
可迭代对象通过__iter__() 方法返回一个迭代器,当我们使用迭代器的next() 方法时,调用的就是__next__() 方法,它会返回所记录位置的下一个位置的数据。所以,我们要想构造一个迭代器,就要实现它的__next__() 方法。但这还不够,python要求迭代器本身也是可迭代的,所以我们还要为迭代器实现__iter__() 方法,为了方便,我们就可以让迭代器的__iter__() 方法返回自身。
for...in...循环的本质
for item in Iterable 循环的本质就是先通过iter()函数获取可迭代对象Iterable的迭代器,然后对获取到的迭代器不断调用next()方法来获取下一个值并将其赋值给item, 当遇到Stoplteration的异常后循环结束。
生成器
利用迭代器,我们可以在每次迭代获取数据(通过next()方法) 时按照特定的规律进行生成。但是我们在实现一个迭代器时,关于当前迭代到的状态需要我们自己记录,进而才能根据当前状态生成下一个数据。为了达到记录当前状态,并配合next()函数进行迭代使用,我们可以采用更简便的语法,即生成器(generator)。生成器是一类特殊的迭代器。
创建生成器的方法:
-
g = (x for x in range(10)) #<generator object <genexpr> at 0x00000216C356E678> -
def f(n): count = 1 a,b = 0,1 while count <= n: a,b=b,a+b count += 1 yield a for i in f(10): print(i)- 使用了yield关键字的函数不再是函数,而是生成器。(使用了yield的函数就是生成器)
- yield关键字有两点作用:
- 保存当前运行状态(断点),然后暂停执行,即将生成器(函数)挂起
- 将yield关键字后面表达式的值作为返回值返回,此时可以理解为起到了return的作用
- 可以使用next()函数让生成器从断点处继续执行,即唤醒生成器(函数)
- Python3中的生成器可以使用return返回最终运行的返回值,而Python2中的生成器不允许使用return返
回一个返回值( 即可以使用return从生成器中退出,但return后不能有任何表达式)。
正则表达式
正则表达式是一个特殊的字符序列,计算机科学的一个概念。通常被用来检索、替换那些符合某个模式(规则)的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。在Python中需要通过正则表达式对字符串进行匹配的时候,可以使用 re模块。re 模块使Python语言拥有全部的正则表达式功能。
正则表达式语法
| 模式 | 描 述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re | 匹配n个前面表达式。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。 |
| re | 精确匹配n个前面表达式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。 |
| re | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a | b | 匹配a或b |
| (re) | 匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功。 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配数字字母下划线 |
| \W | 匹配非数字字母下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]。 |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t,等。 | 匹配一个换行符。匹配一个制表符, 等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
查找方法
-
re.match(pattern, string, flags=0) 从字符串开始位置匹配成功就返回第一个匹配的对象,否则返回None。
-
re.search(pattern, string, flags=0) 扫描整个字符串并返回第一个成功的匹配。
-
re.findall(string[, pos[, endpos]]) 在字符串中找到正则表达式所匹配的所有字符,并返回结果组成的列表,
如果没有找到匹配的,则返回空列表。 -
re.finditer(pattern, string, flags=0) 在字符串中找到正则表达式所匹配的所有字符,返回结果组成的迭代器。
-
re.fullmatch() 完整匹配整个字符串成功才会返回匹配对象。
-
re.compile(pattern[, flags]) 编译正则表达式,生成一个 Pattern 对象,供 match() 和 search() 这两个函数使用
re.Match() 方法:
| 属性和方法 | 描述 |
|---|---|
| pos | 搜索的开始位置 |
| endpos | 搜索的结束位置 |
| string | 搜索的字符串 |
| re | 当前使用的正则表达式对象 |
| lastindex | 最后匹配的组索引 |
| lastgroup | 最后匹配的组名 |
| group(index) | 某个组匹配的结果 |
| groups() | 所有分组的匹配结果,每个分组组成的结果以列表返回 |
| groupdict() | 返回组名作为key,每个分组的匹配结果作为value的字典 |
| start([group]) | 获取组的开始位置 |
| end([group]) | 获取组的结束位置 |
| span([group]) | 获取组的开始和结束位置 |
| expand(template) | 使用组的匹配结果来替换template中的内容,并把替换后的字符串返回 |
正则表达式修饰符 (flags)
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
分离方法
- re.split(string[, maxsplit=0]) 通过正则表达式匹配来分割字符串
替换方法
- re.sub(pattern, new, old, count=0, flags=0) 替换字符串中的匹配项 new:可以是函数或者字符串,返回新对象
贪婪模式
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能匹配成功的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
IO操作
IO也就是我们说的 Input/Output,也就是输入和输出。我们的程序在运行过程中所有的数据都是驻留在内存当中,有的时候我们需要将内存的数据写到磁盘中,这时候就要用到磁盘IO,有的时候我们需要网络和其他应用程序或者服务进行数据交换,这时候就要用到网络IO。
IO无处不在,比如你要访问一个网页,首先你要打开浏览器,输入www.baidu.com 这样的域名地址,然后浏览器会发起一个请求到服务器,这个请求就是网络IO,服务器同样通过网络IO收到请求,然后解释你的请求,然后把你要的网页从磁盘上读出来也就是磁盘IO,然后把文件的内容再通过网络IO返回到用户的浏览器,浏览器通过网络IO接受数据然后展现在我们的页面上。从上面来看IO无处不在。所以我们就来讲讲IO操作。
IO编程中,Stream(流)是一个很重要的概念,可以把流想象成一个水管,数据就是水管里的水,但是只能单向流动。Input Stream就是数据从外面(磁盘、网络)流进内存,Output Stream就是数据从内存流到外面去。对于浏览网页来说,浏览器和新浪服务器之间至少需要建立两根水管,才可以既能发数据,又能收数据。
另外IO有两种模式,一种是同步IO,一种是异步IO。同步IO和异步IO的区别在于是否等待IO操作的结果,因为IO操作由于受到硬件的瓶颈,相比于CPU和内存的处理速度要慢的多,这时候CPU干什么,无非是两种,一种是CPU等着,程序暂停执行我们称之为阻塞,直到IO操作结束,然后再继续执行。另外一种是CPU和程序不等着,继续处理其他的内容,IO操作结束通知CPU,CPU再来处理这部分内容。这时候就是不阻塞。
打个比方就是好比你去餐厅点餐,你说“来个包子”,服务员告诉你,对不起,包子要现做,需要等5分钟,于是你站在收银台前面等了5分钟,拿到汉堡再去逛商场,这是同步IO。你说“来个包子”,服务员告诉你,包子需要等5分钟,你可以先去逛商场,等做好了,我们再通知你,这样你可以立刻去干别的事情(逛商场),这是异步IO。
很明显使用异步IO效率上要比同步IO的效率要高。
异步IO我们又分为两种,还拿买包子来说,包子好了,服务员来通知你包子好了,这是回调模式,如果服务员发短信通知你,你需要不停地检查手机来知道包子是否做好啦,这就是轮训模式。这里我们先讲讲几种常用的IO操作。
真正意义上的 异步IO 是说内核直接将数据拷贝至用户态的内存单元,再通知程序直接去读取数据。
select / poll / epoll 都是同步IO的多路复用模式
1.同步和异步
同步和异步关注的是消息通信机制
所谓同步,就是在发出一个*调用*时,没得到结果之前,该*调用*就不返回。但是一旦调用返回就得到返回值了,*调用者*主动等待这个*调用*的结果
所谓异步,就是在发出一个*调用*时,这个*调用*就直接返回了,不管返回有没有结果。当一个异步过程调用发出后,*被调用者*通过状态,通知来通知*调用者*,或者通过回调函数处理这个调用
2.阻塞和非阻塞
阻塞和非阻塞关注的是程序在等待调用结果时的状态
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才返回
非阻塞调用是指在不能立即得到结果之前,该调用不会阻塞当前线程
网络上的例子老张爱喝茶,废话不说,煮开水。
出场人物:老张,水壶两把(普通水壶,简称水壶;会响的水壶,简称响水壶)。
#1 老张把水壶放到火上,站着等水开。(同步阻塞);站着等就是阻塞了老张去干别的事,老张得一直主动的看着水开没,这就是同步
#2 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞);老张去看电视了,这就是非阻塞了,但是老张还是得关注着水开没,这也就是同步了
#3 老张把响水壶放到火上,立等水开。(异步阻塞);立等就是阻塞了老张去干别的事,但是老张不用时刻关注水开没,因为水开了,响水壶会提醒他,这就是异步了
#4 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞);老张去看电视了,这就是非阻塞了,而且,等水开了,响水壶会提醒他,这就是异步了
#所谓同步异步,只是对于水壶而言。普通水壶,同步;响水壶,异步。对应的也就是消息通信机制
#虽然都能干活,但响水壶可以在自己完工之后,提示老张水开了。这是普通水壶所不能及的。同步只能让调用者去轮询自己(情况2中),造成老张效率的低下。
#所谓阻塞非阻塞,仅仅对于老张而言。立等的老张,阻塞;对应的也就是程序等待结果时的状态
#看电视的老张,非阻塞。
#情况1和情况3中老张就是阻塞的,媳妇喊他都不知道。虽然3中响水壶是异步的,可对于立等的老张没有太大的意义。所以一般异步是配合非阻塞使用的,这样才能发挥异步的效用。
多任务
进程
- 与线程不同,进程没有任何共享状态,进程修改的数据,改动仅限于该进程内。
- 充分地使用多核CPU的资源
- 进程之间数据不共享,但是共享同一套文件系统
创建进程
multiprocessing.Process( target [, name [, args [, kwarg]]])
target:如果传递了函数的引用,可以认为这个子进程就执行这里的代码
args: 给target指定的函数传递的参数,以元组的方式传递
kwargs: 给target指定的函数传递命名参数
name:给进程设定一个名字,可以不设定.
import time
import multiprocessing
def sing():
while True:
print("-----sing-----")
time.sleep(1)
def dance():
while True:
print("-----dance-----")
time.sleep(1)
if __name__ == "__main__":
p1 = multiprocessing.Process(target=sing)
p2 = multiprocessing.Process(target=dance)
p1.start()
p2.start()
守护进程
1.守护进程会在主进程代码运行结束的情况下,立即挂掉。
2.守护进程本身就是一个子进程。
3.主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束。
4.当该子进程执行的任务生命周期伴随着主进程的生命周期时,就需要将该子进程做成守护进程。
from multiprocessing import Process
import os
import time
def task(x):
print('%s is running ' %x)
time.sleep(3)
print('%s is done' %x)
if __name__ == '__main__':
p1=Process(target=task,args=('守护进程',))
p2=Process(target=task,args=('子进程',))
p1.daemon=True # 设置p1为守护进程
p1.start()
p2.start()
print('主')
#主
#子进程 is running
#子进程 is done
进程间通信
from multiprocessing import Queue
import multiprocessing
def download_data(q):
"""模拟这是从网上下载数据"""
data = [11, 22, 33]
for i in data:
q.put(i)
print("数据下载完成")
def deal_data(q):
"""模拟处理从网上下载下来的数据"""
data_list = []
while True:
data = q.get()
data_list.append(data)
if q.empty():
break
print("处理数据结束,数据为:", data_list)
def main():
q = Queue(3)
p1 = multiprocessing.Process(target=download_data, args=(q,))
p2 = multiprocessing.Process(target=deal_data, args=(q,))
p1.start()
time.sleep(1)
p2.start()
if __name__ == '__main__':
main()
进程池
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态生成多个进程, 但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程来执行该请求,但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务。
from multiprocessing import Pool
import os, time, random
def worker(msg):
t_start = time.time()
print("%s开始执行,进程号为%d" % (msg, os.getpid()))
# random.random()随机生成0~1之间的浮点数
time.sleep(random.random() * 2)
t_stop = time.time()
print(msg, "执行完毕, 耗时%0.2f" % (t_stop - t_start))
if __name__ == '__main__':
po = Pool(3) # 定义一个进程池,最大进程数3
for i in range(0, 10):
# Pool().apply_async(要调用的目标,(传递给目标的参数元祖,))
# 每次循环将会用空闲出来的子进程去调用目标
po.apply_async(worker, (i,))
print("----start----")
po.close() # 关闭进程池,关闭后po不再接收新的请求
po.join() # 主进程阻塞等待子进程的退出
print('----end----')
----start----
0开始执行,进程号为2444
1开始执行,进程号为10824
2开始执行,进程号为12824
1 执行完毕, 耗时0.45
3开始执行,进程号为10824
0 执行完毕, 耗时1.19
4开始执行,进程号为2444
4 执行完毕, 耗时0.12
5开始执行,进程号为2444
2 执行完毕, 耗时1.87
6开始执行,进程号为12824
3 执行完毕, 耗时1.42
7开始执行,进程号为10824
6 执行完毕, 耗时0.10
8开始执行,进程号为12824
5 执行完毕, 耗时1.26
9开始执行,进程号为2444
8 执行完毕, 耗时1.69
7 执行完毕, 耗时1.85
9 执行完毕, 耗时1.67
----end----
多参数 并发 阻塞 有序结果
map no yes yes yes
apply yes no yes no
map_async no yes no yes
apply_async yes yes no no
线程
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度。
- 程序的运行速度可能加快。在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
- 共享全局变量
创建线程
threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
通过 thread.current_thread() 方法可以返回线程本身,然后就可以访问它的 ident 属性(线程号)。
from threading import Thread
import time
def foo():
for i in range(100):
print('111')
time.sleep(0.5)
def bar():
for i in range(100):
print('222')
time.sleep(0.5)
t1=Thread(target=foo)
t2=Thread(target=bar)
t1.start()
t2.start()
print("---main---")
守护线程
所谓’线程守护’,就是主线程不管该线程的执行情况,只要是其他子线程结束且主线程执行完毕,主线程都会关闭。也就是说:主线程不等待该守护线程的执行完再去关闭。
from threading import Thread
import os
import time
def task(x):
print('%s is running ' %x)
time.sleep(3)
print('%s is done' %x)
if __name__ == '__main__':
t1=Thread(target=task,args=('守护线程',))
t1.daemon=True # 设置p1为守护进程
t1.start()
print('主')
#守护线程 is running
#主
例子2:当有多个子线程时,守护线程就会等待所有的子线程运行完毕后,守护线程才会挂掉(这一点和主线程是一样的,都是等待所有的子线程运行完毕后才会挂掉)。
from threading import Thread
import time
def foo():
print(123)
time.sleep(3)
print("end123")
def bar():
print(456)
time.sleep(1)
print("end456")
t1=Thread(target=foo)
t2=Thread(target=bar)
t1.daemon=True
t1.start()
t2.start()
print("main-------")
#123
#456
#main-------
#end456
互斥锁
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制。同步就是协同步调,按预定的先后次序进行运行。线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁为资源引入时的一个状态:锁定/非锁定
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定",其他线程不能更改,直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行读写操作,从而保证了多线程情况下数据的正确性。
threading模块中定义了Lock类,可以方便的处理锁定:
from threading import Lock
lock = threading.Lock()
lock.acquire()
lock.release()
注意:
- 如果这个锁之前是没有上锁的,那么acquire不会堵塞
- 如果在调用acquire对这个锁上锁之前它已经被其他线程上了锁,那么此时acquire会堵塞,直到这个锁被解锁为止。
- 和文件操作一样,Lock也可以使用with语句快速的实现打开和关闭操作。
上锁过程:
- 当一个线程调用锁的acquire()方法获得锁时,锁就进入"locked"状态。
- 每次只有一个线程可以获得锁。如果此时另一个线程试图获得这个锁,该线程就会变为"blocked"状态,称为“阻塞”,直到拥有锁的线程调用锁的release()方法释放锁之后,锁进入“unlocked"状态。
- 线程调度程序从处于同步阻塞状态的线程中选择一个来获得锁,并使得该线程进入运行(running) 状态。
锁的好处:
确保了某段关键代码只能由一个线程从头到尾完整地执行
锁的坏处:
阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。
由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁。
递归锁
from threading import Thread,RLock
def foo(i,lock):
lock.acquire()
lock.acquire()
print(i)
lock.release()
lock.release()
lock=RLock()
for i in range(10):
Thread(target=foo,args=(i,lock)).start()
死锁
import threading
import time
lock_apple = threading.Lock()
lock_banana = threading.Lock()
class MyThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
self.fun1()
self.fun2()
def fun1(self):
lock_apple.acquire() # 如果锁被占用,则阻塞在这里,等待锁的释放
print ("线程 %s , 想拿: %s" %(self.name, "苹果"))
lock_banana.acquire()
print ("线程 %s , 想拿: %s" %(self.name, "香蕉"))
lock_banana.release()
lock_apple.release()
def fun2(self):
lock_banana.acquire()
print ("线程 %s , 想拿: %s" %(self.name, "香蕉"))
time.sleep(0.1)
lock_apple.acquire()
print ("线程 %s , 想拿: %s" %(self.name,'苹果'))
lock_apple.release()
lock_banana.release()
if __name__ == "__main__":
for i in range(0, 10): #建立10个线程
my_thread = MyThread() #类继承法是python多线程的另外一种实现方式
my_thread.start()
#线程 Thread-1 , 想拿: 苹果
#线程 Thread-1 , 想拿: 香蕉
#线程 Thread-1 , 想拿: 香蕉
#线程 Thread-2 , 想拿: 苹果 卡住了……
线程间通信
Queue的原理
Queue是一个先进先出 (First In First Out)的队列,主进程中创建一个Queue对象, 并作为参数传入子进
程,两者之间通过put( )放入数据,通过get( )取出数据,执行了get( )函数之后队列中的数据会被同时删除。
q.put 和 q.get 两个都是阻塞的方法
import threading,time,queue
q=queue.Queue()
def p():
for i in range(10):
time.sleep(0.3)
q.put(f'面包{i}')
print(f'生产了面包{i}')
def b():
for i in range(10):
time.sleep(1)
print(f'购买{q.get()}')
t1=threading.Thread(target=p)
t2=threading.Thread(target=b)
t1.start()
t2.start()
生产了面包0
生产了面包1
生产了面包2
购买面包0
生产了面包3
生产了面包4
生产了面包5
购买面包1
生产了面包6
生产了面包7
生产了面包8
购买面包2
生产了面包9
购买面包3
购买面包4
购买面包5
购买面包6
购买面包7
购买面包8
购买面包9
线程和进程的区别
定义的不同:
-
进程是系统进行资源分配和调度的一一个独立单位。
-
线程是进程的一个实体是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可以与同属一个进程的其他线程共享进程所拥有的全部资源。
区别:
-
一个程序至少有一一个进程,一个进程至少有一个线程。
-
线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。
-
进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
-
线线程不能够独立执行,必须依存在进程中
-
可以将进程理解为工厂中的一条流水线,而其中的线程就是这个流水线上的工人
Python多进程和多线程哪个快?
由于GIL的存在,很多人认为Python多进程编程更快,针对多核CPU,理论上来说也是采用多进程更能有效利用资源。网上很多人已做过比较,我直接告诉你结论吧。
- 对CPU密集型代码(比如循环计算) - 多进程效率更高
- 对IO密集型代码(比如文件操作,网络爬虫) - 多线程效率更高。
对于IO密集型操作,大部分消耗时间其实是等待时间,在等待时间中CPU是不需要工作的,那你在此期间提供双CPU资源也是利用不上的,相反对于CPU密集型代码,2个CPU干活肯定比一个CPU快很多。那么为什么多线程会对IO密集型代码有用呢?这是因为python碰到等待会释放GIL供新的线程使用,实现了线程间的切换。
协程
Queue队列
Queue 模块中的常用方法:
| 方法 | 描述 |
|---|---|
| Queue.qsize() | 返回队列的大小 |
| Queue.empty() | 如果队列为空,返回True,反之False |
| Queue.full() | 如果队列满了,返回True,反之False,与 maxsize 大小对应 |
| Queue.get([block[, timeout]]) | 获取队列,timeout等待时间 |
| Queue.get_nowait() | 相当Queue.get(block=False) |
| Queue.put(item) | 写入队列,timeout等待时间 |
| Queue.put_nowait(item) | 相当Queue.put(item, False) |
| Queue.task_done() | 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号 |
| Queue.join() | 实际上意味着等到队列为空,再执行别的操作 |
第三方库
random
random.random() # 生成 [0,1)的随机浮点数
random.uniform(20, 30) # 生成[20,30]的随机浮点数
random.randint(10, 30) # 生成[10,30]的随机整数
random.randrange(20, 30) # 生成[20,30)的随机整数
random.choice('abcdefg') # 从列表里随机取出一个元素
random.sample('abcdefghij', 3) # 从列表里随机取出指定个数的元素
OS
os.getcwd() # 获取当前的工作目录,即当前python脚本工作的目录
os.chdir('test') # 改变当前脚本工作目录,相当于shell下的cd命令
os.rename('毕业论文.txt','毕业论文-最终版.txt') # 文件重命名
os.remove('毕业论文.txt') # 删除文件
os.rmdir('demo') # 删除空文件夹
os.removedirs('demo') # 删除空文件夹
os.mkdir('demo') # 创建一个文件夹
os.chdir('C:\\') # 切换工作目录
os.listdir('C:\\') # 列出指定目录里的所有文件和文件夹
os.name # nt->widonws posix->Linux/Unix或者MacOS
os.environ # 获取到环境配置
os.environ.get('PATH') # 获取指定的环境配置
os.path.abspath(path) # 获取Path规范会的绝对路径
os.path.exists(path) # 如果Path存在,则返回True
os.path.isdir(path) # 如果path是一个存在的目录,返回True。否则返回False
os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False
os.path.splitext(path) # 用来将指定路径进行分隔,可以获取到文件的后缀名
hashlib
str = '这是一个测试'
# 创建md5对象
hl = hashlib.md5('hello'.encode())
print('MD5加密后为 :' + hl.hexdigest())
h1.update(b'123') == hashlib.md5(b'hello123')
h1 = hashlib.sha1('123456'.encode())
h2 = hashlib.sha224('123456'.encode())
h3 = hashlib.sha256('123456'.encode())
h4 = hashlib.sha384('123456'.encode())
time
time.time() # 获取从1970-01-01 00:00:00 UTC 到现在时间的秒数
time.strftime("%Y-%m-%d %H:%M:%S") # 按照指定格式输出时间
time.asctime() #Mon Apr 15 20:03:23 2019
time.ctime() # Mon Apr 15 20:03:23 2019
#时间格式化
%a 星期几的简写
%A 星期几的全称
%b 月分的简写
%B 月份的全称
%c 标准的日期的时间串
%C 年份的前两位数字
%d 十进制表示的每月的第几天
%D 月/日/年
%e 在两字符域中,十进制表示的每月的第几天
%F 年-月-日
%g 年份的后两位数字,使用基于周的年
%G 年分,使用基于周的年
%h 简写的月份名
%H 24小时制的小时
%I 12小时制的小时
%j 十进制表示的每年的第几天
%m 十进制表示的月份
%M 十时制表示的分钟数
%n 新行符
%p 本地的AM或PM的等价显示
%r 12小时的时间
%R 显示小时和分钟:hh:mm
%S 十进制的秒数
%t 水平制表符
%T 显示时分秒:hh:mm:ss
%u 每周的第几天,星期一为第一天 (值从0到6,星期一为0)
%U 第年的第几周,把星期日做为第一天(值从0到53)
%V 每年的第几周,使用基于周的年
%w 十进制表示的星期几(值从0到6,星期天为0)
%W 每年的第几周,把星期一做为第一天(值从0到53)
%x 标准的日期串
%X 标准的时间串
%y 不带世纪的十进制年份(值从0到99)
%Y 带世纪部分的十制年份
%z,%Z 时区名称,如果不能得到时区名称则返回空字符。
%% 百分号
datetime
datetime.date(2020, 1, 1) # 创建一个日期
datetime.time(18, 23, 45) # 创建一个时间
datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)
datetime.datetime.now() # 获取当前的日期时间
datetime.datetime.timestamp(t) # 返回对应时间的时间戳
datetime.datetime.isoweekday(t) # 返回星期几
datetime.datetime.strptime("时间字符串",'%Y.%M.%d %H.%m.%S') #将格式时间字符串转换为datetime对象
datetime.datetime.strftime('%Y-%M-%d-%H-%m-%S') #将datetime对象转换为格式时间字符串
datetime.datetime.fromtimestamp(timestamp) #给定一个时间戳,返回指定时区的datetime.datetime类的对象
Counter
from collections import Counter
s = "hello pinsily"
d = Counter(s)
#Counter({'l': 3, 'i': 2, 'h': 1, 'e': 1, 'o': 1, ' ': 1, 'p': 1, 'n': 1, 's': 1, 'y': 1})
d.elements() #返回一个包含所有元素的迭代器
d.most_common(n) #返回数量最多的前 n 个元素
d.subtract(x) #可以看成两个元组之间的加减运算,将各个元素对应的个数进行加减,加减后会更新原数组
tkinter
基础
import tkinter as tk
from PIL import ImageTk #在组件插入图片
from tkinter import filedialog,messagebox #弹出选文件目录框和消息提示警告框
#创建窗口对象
window = tk.Tk()
#窗口标题
window.title('xxx')
#窗口尺寸,中间是字母x
window.geometry('600x400')
#指定窗口不可拉伸
window.resizable(0,0)
#窗口进入消息循环
window.mainloop()

Label
- 标签控件(Label)指定的窗口中显示的文本和图像。
- 你如果需要显示一行或多行文本且不允许用户修改,你可以使用 Label 组件。
如果你没有指定 Label 的大小,那么 Label 的尺寸是正好可以容纳其内容而已,如下:
当然你可以通过 height 和 width 选项来明确设置 Label 的大小:
如果你显示的是文本,那么这两个选项是以文本单元为单位定义 Label 的大小;
如果你显示的是位图或者图像,那么它们以像素为单位(或者其他屏幕单元)定义 Label 大小。
你可以通过 foreground(或 fg)和 background(或 bg)选项来设置 Label 的前景色和背景色。你也可以选择 Label 中的文本用哪种字体来显示。指定颜色和字体时需谨慎,除非你有一个很好的理由,否则建议使用默认值(主要是考虑到不同平台的兼容性)
t1 = tk.Label(window,image = bg,text='我是段锐',font=('微软雅黑',30),
foreground='black',background='orange',compound='center')
| 选项 | 含义 |
|---|---|
| activebackground | 1. 设置当 Label 处于活动状态(通过 state 选项设置状态)的背景色 2. 默认值由系统指定 |
| activeforeground | 1. 设置当 Label 处于活动状态(通过 state 选项设置状态)的前景色 2. 默认值由系统指定 |
| anchor | 1. 控制文本(或图像)在 Label 中显示的位置 2. "n", "ne", "e", "se", "s", "sw", "w", "nw", 或者 "center" 来定位(ewsn 代表东西南北,上北下南左西右东) 3. 默认值是 "center" |
| background | 1. 设置背景颜色 2. 默认值由系统指定 |
| bg | 跟 background 一样 |
| bitmap | 1. 指定显示到 Label 上的位图 2. 如果指定了 image 选项,则该选项被忽略 |
| borderwidth | 1. 指定 Label 的边框宽度 2. 默认值由系统指定,通常是 1 或 2 像素 |
| bd | 跟 borderwidth 一样 |
| compound | 1. 控制 Label 中文本和图像的混合模式 2. 默认情况下,如果有指定位图或图片,则不显示文本 3. 如果该选项设置为 "center",文本显示在图像上(文本重叠图像) 4. 如果该选项设置为 "bottom","left","right" 或 "top",那么图像显示在文本的旁边(如 "bottom",则图像在文本的下方) 5. 默认值是 NONE |
| cursor | 1. 指定当鼠标在 Label 上飘过的时候的鼠标样式 2. 默认值由系统指定 |
| disabledforeground | 1. 指定当 Label 不可用的时候前景色的颜色 2. 默认值由系统指定 |
| font | 1. 指定 Label 中文本的字体(注:如果同时设置字体和大小应该用元组,如("楷体", 20) 2. 一个 Label 只能设置一种字体 3. 默认值由系统指定 |
| foreground | 1. 设置 Label 的文本和位图的颜色 2. 默认值由系统指定 |
| fg | 跟 foreground 一样 |
| height | 1. 设置 Label 的高度 2. 如果 Label 显示的是文本,那么单位是文本单元 3. 如果 Label 显示的是图像,那么单位是像素(或屏幕单元) 4. 如果设置为 0 或者干脆不设置,那么会自动根据 Label 的内容计算出高度 |
| highlightbackground | 1. 指定当 Label 没有获得焦点时高亮边框的颜色 2. 默认值由系统指定,通常是标准背景颜色 |
| highlightcolor | 1. 指定当 Label 获得焦点的时候高亮边框的颜色 2. 默认值由系统指定 |
| highlightthickness | 1. 指定高亮边框的宽度 2. 默认值是 0(不带高亮边框) |
| image | 1. 指定 Label 显示的图片 2. 该值应该是 PhotoImage,BitmapImage,或者能兼容的对象 3. 该选项优先于 text 和 bitmap 选项 |
| justify | 1. 定义如何对齐多行文本 2. 使用 "left","right" 或 "center" 3. 注意,文本的位置取决于 anchor 选项 4. 默认值是 "center" |
| padx | 1. 指定 Label 水平方向上的额外间距(内容和边框间) 2. 单位是像素 |
| pady | 1. 指定 Label 垂直方向上的额外间距(内容和边框间) 2. 单位是像素 |
| relief | 1. 指定边框样式 2. 默认值是 "flat" 3. 另外你还可以设置 "groove", "raised", "ridge", "solid" 或者 "sunken" |
| state | 1. 指定 Label 的状态 2. 这个标签控制 Label 如何显示 3. 默认值是 "normal 4. 另外你还可以设置 "active" 或 "disabled" |
| takefocus | 1. 如果是 True,该 Label 接受输入焦点 2. 默认值是 False |
| text | 1. 指定 Label 显示的文本 2. 文本可以包含换行符 3. 如果设置了 bitmap 或 image 选项,该选项则被忽略 |
| textvariable | 1. Label 显示 Tkinter 变量(通常是一个 StringVar 变量)的内容 2. 如果变量被修改,Label 的文本会自动更新 |
| underline | 1. 跟 text 选项一起使用,用于指定哪一个字符画下划线(例如用于表示键盘快捷键) 2. 默认值是 -1 3. 例如设置为 1,则说明在 Button 的第 2 个字符处画下划线 |
| width | 1. 设置 Label 的宽度 2. 如果 Label 显示的是文本,那么单位是文本单元 3. 如果 Label 显示的是图像,那么单位是像素(或屏幕单元) 4. 如果设置为 0 或者干脆不设置,那么会自动根据 Label 的内容计算出宽度 |
| wraplength | 1. 决定 Label 的文本应该被分成多少行 2. 该选项指定每行的长度,单位是屏幕单元 3. 默认值是 0 |
Button
按钮组件用于在 Python 应用程序中添加按钮,按钮上可以放上文本或图像,按钮可用于监听用户行为,能够与一个 Python 函数关联,当按钮被按下时,自动调用该函数。
| 选项 | 含义 |
|---|---|
| activebackground | 1. 设置当 Button 处于活动状态(通过 state 选项设置状态)的背景色 2. 默认值由系统指定 |
| activeforeground | 1. 设置当 Button 处于活动状态(通过 state 选项设置状态)的前景色 2. 默认值由系统指定 |
| anchor | 1. 控制文本(或图像)在 Button 中显示的位置 2. "n", "ne", "e", "se", "s", "sw", "w", "nw", 或者 "center" 来定位(ewsn 代表东西南北,上北下南左西右东) 3. 默认值是 "center" |
| background | 1. 设置背景颜色 2. 默认值由系统指定 |
| bg | 跟 background 一样 |
| bitmap | 1. 指定显示到 Button 上的位图 2. 如果指定了 image 选项,则该选项被忽略 |
| borderwidth | 1. 指定 Button 的边框宽度 2. 默认值由系统指定,通常是 1 或 2 像素 |
| bd | 跟 borderwidth 一样 |
| compound | 1. 控制 Button 中文本和图像的混合模式 2. 默认情况下,如果有指定位图或图片,则不显示文本 3. 如果该选项设置为 "center",文本显示在图像上(文本重叠图像) 4. 如果该选项设置为 "bottom","left","right" 或 "top",那么图像显示在文本的旁边(如 "bottom",则图像在文本的下方) 5. 默认值是 NONE |
| cursor | 1. 指定当鼠标在 Button 上飘过的时候的鼠标样式 2. 默认值由系统指定 |
| default | 1. 如果设置该选项("normal"),该按钮会被绘制成默认按钮 2. Tkinter 会根据平台的具体指标来绘制(通常就是绘制一个额外的边框) 3. 默认值是 "disable" |
| disabledforeground | 1. 指定当 Button 不可用的时候前景色的颜色 2. 默认值由系统指定 |
| font | 1. 指定 Button 中文本的字体 2. 一个 Button 只能设置一种字体 3. 默认值由系统指定 |
| foreground | 1. 设置 Button 的文本和位图的颜色 2. 默认值由系统指定 |
| fg | 跟 foreground 一样 |
| height | 1. 设置 Button 的高度 2. 如果 Button 显示的是文本,那么单位是文本单元 3. 如果 Button 显示的是图像,那么单位是像素(或屏幕单元) 4. 如果设置为 0 或者干脆不设置,那么会自动根据 Button 的内容计算出高度 |
| highlightbackground | 1. 指定当 Button 没有获得焦点的时候高亮边框的颜色 2. 默认值由系统指定 |
| highlightcolor | 1. 指定当 Button 获得焦点的时候高亮边框的颜色 2. 默认值由系统指定 |
| highlightthickness | 1. 指定高亮边框的宽度 2. 默认值是 0(不带高亮边框) |
| image | 1. 指定 Button 显示的图片 2. 该值应该是 PhotoImage,BitmapImage,或者能兼容的对象 3. 该选项优先于 text 和 bitmap 选项 |
| justify | 1. 定义如何对齐多行文本 2. 使用 "left","right" 或 "center" 3. 注意,文本的位置取决于 anchor 选项 4. 默认值是 "center" |
| overrelief | 1. 定义当鼠标飘过时 Button 的样式 2. 如果不设置,那么总是使用 relief 选项指定的样式 |
| padx | 指定 Button 水平方向上的额外间距(内容和边框间) |
| pady | 指定 Button 垂直方向上的额外间距(内容和边框间) |
| relief | 1. 指定边框样式 2. 通常当按钮被按下时是 "sunken",其他时候是 "raised" 3. 另外你还可以设置 "groove"、"ridge" 或 "flat" 4. 默认值是 "raised" |
| repeatdelay | 见下方 repeatinterval 选项的描述 |
| repeatinterval | 1. 通常当用户鼠标按下按钮并释放的时候系统认为是一次点击动作。如果你希望当用户持续按下按钮的时候(没有松开),根据一定的间隔多次触发按钮,那么你可以设置这个选项。 2. 当用户持续按下按钮的时候,经过 repeatdelay 时间后,每 repeatinterval 间隔就触发一次按钮事件。 3. 例如设置 repeatdelay=1000,repeatinterval=300,则当用户持续按下按钮,在 1 秒的延迟后开始每 300 毫秒触发一次按钮事件,直到用户释放鼠标。 |
| state | 1. 指定 Button 的状态 2. 默认值是 "normal" 3. 另外你还可以设置 "active" 或 "disabled" |
| takefocus | 1. 指定使用 Tab 键可以将焦点移到该 Button 组件上(这样按下空格键也相当于触发按钮事件) 2. 默认是开启的,可以将该选项设置为 False 避免焦点在此 Button 上 |
| text | 1. 指定 Button 显示的文本 2. 文本可以包含换行符 3. 如果设置了 bitmap 或 image 选项,该选项则被忽略 |
| textvariable | 1. Button 显示 Tkinter 变量(通常是一个 StringVar 变量)的内容 2. 如果变量被修改,Button 的文本会自动更新 |
| underline | 1. 跟 text 选项一起使用,用于指定哪一个字符画下划线(例如用于表示键盘快捷键) 2. 默认值是 -1 3. 例如设置为 1,则说明在 Button 的第 2 个字符处画下划线 |
| width | 1. 设置 Button 的宽度 2. 如果 Button 显示的是文本,那么单位是文本单元 3. 如果 Button 显示的是图像,那么单位是像素(或屏幕单元) 4. 如果设置为 0 或者干脆不设置,那么会自动根据 Button 的内容计算出宽度 |
| wraplength | 1. 决定 Button 的文本应该被分成多少行 2. 该选项指定每行的长度,单位是屏幕单元 3. 默认值是 0 |
flash()
-- 刷新 Button 组件,该方法将重绘 Button 组件若干次(在 "active" 和 "normal" 状态间切换)。
invoke()
-- 调用 Button 中 command 选项指定的函数或方法,并返回函数的返回值。
-- 如果 Button 的state(状态)是 "disabled"(不可用)或没有指定 command 选项,则该方法无效。
Checkbutton
多选按钮 组件用于实现确定是否选择的按钮。Checkbutton 组件可以包含文本或图像,你可以将一个 Python 的函数或方法与之相关联,当按钮被按下时,对应的函数或方法将被自动执行。
Checkbutton 组件被用于作为二选一的按钮(通常为选择“开”或“关”的状态),当你希望表达“多选多”选项的时候,可以将一系列 Checkbutton 组合起来使用。
但是处理“多选一”的问题,还是交给 Radiobutton 和 Listbox 组件来实现吧。
Radiobutton
Frame
Linux

文件系统
操作系统中,用来管理和存储文件信息的软件机构称为文件管理系统,简称文件系统。具体来说,这部分系统就是负责为用户建立、读取、修改和转储文件,控制文件的存取,当用户不再使用时撤销文件等。常见的文件系统介绍:
FAT16
MS-DOS6.X及以下版本使用。每个磁盘的分区最大只能达到2G,并且会浪费很多空间。在FAT16里有簇的概念,就相当于是图书馆里一格-格的书架,每个要存到磁盘的文件都必须配置足够数量的簇,才能存放到磁盘中,每个文件,无论大小,都至少要使用一个簇在保存。
FAT32
Windows95以后的系统都支持。
FAT32具有一个最大的优点:在一个不超过8GB的分区中,FAT32分区格式的每个簇容量都固定为4KB,与FAT16相比,可以大大地减少磁盘的浪费,提高磁盘利用率。突破了FAT16对每一个分区的容量只有2GB的限制,可以将一整个大硬盘定义成一个分区而不必分为几个分区使用,方便了对磁盘的管理。但是,FAT32里,无法存放大于4GB的单个文件,而且容易产生磁盘碎片,性能不佳。另外,FAT不支持长文件名,只能支持8个字符,而且后缀名最多只支持3个字符。
NTFS
WindowsNT系列设计,用来取代FAT系统。每个簇的空间更小,磁盘的利用率更高,并且可以共享资源、文件夹以及对文件设置访问许可权限。
RAW
RAW文件系统是一种磁盘未经处理或者未格式化产生的文件系统。一般来说有这几种可能造成正常文件系统变成RAW文件系统:
- 没有格式化
- 格式化中途取消
- 硬盘出现坏道
- 硬盘出现不可预知的错误
EXT
EXT是扩展文件系统,目前最新的版本是5.0.
HFS+
苹果电脑上的文件系统。
Linux
| 目录 | 描述 |
|---|---|
| / (root 文件系统) | root 文件系统是文件系统的顶级目录。它必须包含在挂载其它文件系统前需要用来启动 Linux 系统的全部文件。它必须包含需要用来启动剩余文件系统的全部可执行文件和库。文件系统启动以后,所有其他文件系统作为 root 文件系统的子目录挂载到标准的、预定义好的挂载点上。 |
| /bin | 包含用户的可执行文件。一些执行命令 |
| /boot | 包含启动 Linux 系统所需要的静态引导程序和内核可执行文件以及配置文件。 |
| /dev | 该目录包含每一个连接到系统的硬件设备的设备文件。这些文件不是设备驱动,而是代表计算机上的每一个计算机能够访问的设备。 |
| /etc | 包含主机计算机的本地系统配置文件。 |
| /etc/passwd | 系统中的用户信息 |
| /etc/shadow | 用户密码 |
| /etc/group | 用户组信息 |
| /home | 主目录存储用户文件,每一个用户都有一个位于 /home 目录中的子目录(作为其主目录)。 |
| /lib | 包含启动系统所需要的共享库文件。 |
| /media | 一个挂载外部可移动设备的地方,比如主机可能连接了一个 USB 驱动器。 |
| /mnt | 一个普通文件系统的临时挂载点(如不可移动的介质),当管理员对一个文件系统进行修复或在其上工作时可以使用。 |
| /opt | 可选文件,比如供应商提供的应用程序应该安装在这儿。 |
| /root | 这不是 root(/)文件系统。它是 root 用户的主目录。 |
| /sbin | 系统二进制文件。这些是用于系统管理的可执行文件。 |
| /tmp | 临时目录。被操作系统和许多程序用来存储临时文件。用户也可能临时在这儿存储文件。注意,存储在这儿的文件可能在任何时候在没有通知的情况下被删除。 |
| /usr | 该目录里面包含可共享的、只读的文件,包括可执行二进制文件和库、man 文件以及其他类型的文档。 |
| /var | 可变数据文件存储在这儿。这些文件包括日志文件、MySQL 和其他数据库的文件、Web 服务器的数据文件、邮件以及更多。 |

文件类型
| 符号 | 类型 |
|---|---|
| - | 普通文件。包括纯文本文件(ASCII);二进制文件(binary); 数据格式的文件(data);各种压缩文件 |
| d | 目录文件。 |
| l | 链接文件。类似于Windows里的快捷方式。 |
| c | 字符设备文件。即串行端口的接口设备,例如键盘、鼠标等等。 |
| b | 块设备文件。就是存储数据以供系统存取的接口设备,简单而言就是硬盘 |
| s | 套接字文件。这类文件通常用在网络数据连接,最常在Ivar/run目录中看到这种文件类型。 |
| p | 管道文件。它主要的目的是,解决多个程序同时存取\一个文件所造成的错误 |
文件权限

目录操作指令
-
ls: 列出目录,不指定目标就是当前路径
-
-a :全部的文件,连同隐藏文件( 开头为 . 的文件) 一起列出来
-
-d :仅列出目录本身,而不是列出目录内的文件数据
-
-l :长数据串列出,包含文件的属性与权限等等数据:
类型及权限 | 连接数 | 用户 | 用户组 | 大小 | 月 | 日 | 年 | 时间 | 名称
-
-
cd:切换目录,不指定目标就是家目录
-
pwd:显示目前的目录
- -P :显示出确实的路径,而非使用连结 (link) 路径。
-
mkdir:创建一个新的目录
-
-m :配置文件的权限喔!直接配置,不需要看默认权限 (umask) 的脸色~
-
-p :帮助你直接将所需要的目录(包含上一级目录)递归创建起来!
-
-
rmdir:删除一个空的目录
- -p :连同上一级空的目录也一起删除
-
rm: 移除文件或目录
- -f :就是 force 的意思,忽略不存在的文件,不会出现警告信息;
- -i :互动模式,在删除前会询问使用者是否动作
- -r :递归删除目录所有文件,这是非常危险的选项!
-
cp: 复制文件或目录
-
-a:相当於 -pdr 的意思,至於 pdr 请参考下列说明;
-
-d:若来源档为连结档的属性(link file),则复制连结档属性而非文件本身;
-
-f:为强制(force)的意思,若目标文件已经存在且无法开启,则移除后再尝试一次;
-
-i:若目标档(destination)已经存在时,在覆盖时会先询问动作的进行
-
-l:进行硬式连结(hard link)的连结档创建,而非复制文件本身;
-
-p:连同文件的属性一起复制过去,而非使用默认属性(备份常用);
-
-r:递归持续复制,用於目录的复制行为;
-
-s:复制成为符号连结档 (symbolic link),亦即『捷径』文件;
-
-u:若 destination 比 source 旧才升级 destination !
-
-
mv: 移动文件与目录,或修改文件与目录的名称
-
-f :如果目标文件已经存在,不会询问而直接覆盖;
-
-i :若目标文件已经存在时,就会询问是否覆盖!
-
-
touch: 创建一个空文件
-
. : 当前目录
-
.. : 上一级目录
-
~ : 当前用户的家目录
-
- : 表示上次切换前的目录
-
/ : 表示根目录
-
alias :给命令起别名
-
执行命令
- cmd1; cmd2 执行完cmd1后,无论cmd1指令是否执行成功,执行cmd2
- cmd1 || cmd2 先执行cmd1 ,cmd1执行失败以后,才会执行cmd2
- cmd1 && cmd2 先执行cmd1 ,cmd1执行成功以后,才会执行cmd2
文件查看指令
-
cat:从上到下查看文件内容
- -A :相当於 -vET 的整合选项,可列出一些特殊字符而不是空白而已;
- -b :列出行号,仅针对非空白行做行号显示,空白行不标行号!
- -n :列印出行号,连同空白行也会有行号,与 -b 的选项不同
-
tac:从下到上查看文件内容
-
nl :显示的时候,顺道输出行号!
-
-n ln :行号在荧幕的最左方显示;
-
-n rn :行号在自己栏位的最右方显示,且不加 0 ;
-
-n rz :行号在自己栏位的最右方显示,且加 0
-
-
more: 一页一页的显示文件内容,空格翻页,回车下一行,查看完毕自动退出
-
less :与 more 类似,但是比 more 更好的是可以上下翻页不会退出,按q退出
-
head :只看头几行 默认10行
-
tail :只看尾几行 默认10行
-
umask :查看文件(夹)默认权限,对返回数字取反
软件安装指令
ubuntu 20.04
dpkg
dpkg -i package.deb 安装/更新一个 deb 包
dpkg -r package_name 从系统删除一个 deb 包
dpkg -l 显示系统中所有已经安装的 deb 包
dpkg -l | grep httpd 显示所有名称中包含 "httpd" 字样的deb包
dpkg -s package_name 获得已经安装在系统中一个特殊包的信息
dpkg -L package_name 显示系统中已经安装的一个deb包所提供的文件列表
dpkg --contents package.deb 显示尚未安装的一个包所提供的文件列表
dpkg -S /bin/ping 确认所给的文件由哪个deb包提供
apt
apt-get install package_name 安装/更新一个 deb 包
apt-cdrom install package_name 从光盘安装/更新一个 deb 包
apt-get update 升级列表中的软件包
apt-get upgrade 升级所有已安装的软件
apt-get remove package_name 从系统删除一个deb包
apt-get check 确认依赖的软件仓库正确
apt-get clean 从下载的软件包中清理缓存
apt-cache search searched-package 返回包含所要搜索字符串的软件包名称
apt换源
Ubuntu 的软件源配置文件是 /etc/apt/sources.list 。将系统自带的该文件做个备份,将该文件替换为下面内容,即可使用 TUNA 的软件源镜像:
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse
安装pip
- 先更新软件源
sudo apt update sudo apt install python3-pip安装pip3sudo apt install python3-distutilsget-pip.py 的依赖库wget https://bootstrap.pypa.io/get-pip.pysudo python3 get-pip.py安装pip
CentOS
rpm
rpm是‘"Red-Hat Package Manager”的简写,为Red Hat专门开发的套件管理系统,方便软件的安装、更新及移除。所有源自Red Hat的"Linux "发行版都可以使用rpm.
| 命令行 | 作用 | 示例 |
|---|---|---|
| rpm -ivh <.rpm filename> | 安装.rpm后缀名的软件并显示安装详情 | rpm -ivh google-chrome-stable_ current_ x86_ 64.rpm |
| rpm -e |
删除指定的软件 | rpm -r google-chrome-stable |
| rpm -qa | 列出电脑上安装的所有包 | rpm -qa |
yum
yum (全称为Yellow dog Updater Modified)是一个在Fedora和RedHat以及 CentOS中的Shell前端软件包管理器。基于RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装。
| 命令行 | 作用 | 示例 |
|---|---|---|
| yum search |
搜索软件包 | yum search python |
| yum list installed | 列出已经安装的软件包 | yum list installed |
| yum install |
用来安装指定的软件包 | yum install vim |
| yum remove | 用来移除软件包 | yum remove vim |
| yum update |
更新软件包 | yum updat tar |
| yum check-update | 检查更新 | yum check-update |
| yum info |
列出指定软件包详情 | yum info python |
用户管理指令
用户
-
useradd:添加一位用户
-
-c :comment 指定一段注释性描述。
-
-d:目录 指定用户主目录,如果此目录不存在,则同时使用-m选项,可以创建主目录。
-
-g :用户组 指定用户所属的用户组。
-
-G :用户组,用户组 指定用户所属的附加组。
-
-s: Shell文件 指定用户的登录Shell。
-
-u :用户号 指定用户的用户号,如果同时有-o选项,则可以重复使用其他用户的标识号。
-
-
userdel:删除用户
- -r :把用户的主目录一起删除
-
usermod:修改用户属性
-
su
:切换用户,不指定就切换到root -
passwd:设置密码,不指定用户则是更改当前用户密码
- -f :强迫用户下次登录时修改口令。
-
sudo:使用root权限执行命令,如果不能使用:
- 需要先用root把用户添加到/etc/sudoers文件中
- 把用户添加到有权限的组中 (sudo)
用户组
-
groups:查看指定用户所在分组
-
gpasswd:将指定用户从指定组中添加删除
- -a : <用户名> <组名>:将用户添加到指定分组
- -d :<用户名> <组名>:将用户从指定分组删除
-
groupadd:添加用户组
-
groupdel:删除用户组
-
groupmod:修改用户组属性
密码文件
/etc/shadow
dr : $6$B3YAHg9DLiB/8nX5$spQtEz.DIm.pXhCmnoGHsHUp4cepz1qm4jiw.YOzmwgjCVDpq59GgxM1bSIw8Cl7F jQqG2LgkjC.31NFvhtnq.:18378:0:99999:7:::
账户名:账户名与/etc/passwd里面的账户名是一一对应的关系。
密码:空表示密码为空,不需要输入密码即登录;星号代表帐号被锁定;单叹号表示未设置密码;双叹号表示这个密码已经过期了; $1$表明是用MD5加密的; $2$是用Blowfish加密的;$5$是用SHA-256加密的;$6$是用SHA-512加密的。
修改日期:这个是表明上一次修改密码的日期与1970-1-1相距的天数
密码不可改的天数:假如这个数字是8,则8天内不可改密码,如果是0,则随时可以改。
密码需要修改的期限:如果是99999则永远不用改。如果是其其他数字比如12345,那么必须.在距离1970-1-1的12345天内修改密码,否则密码失效。
修改期限前N天发出警告。
密码过期的宽限:假设这个数字被设定为M,那么帐号过期的M天内修改密码是可以修改的,
改了之后账户可以继续使用。
帐号失效日期:假设这个日期为X,与第三条-样,X表示的日期依然是1970-1-1相距的天数,
过了X之后,帐号失效。
保留:被保留项,暂时还没有被用上。
文件权限指令
Linux文件的基本权限就有九个,分别是user/group/others三种身份各有自己的read/write/execute权限
文件的权限字符为:『-rwx rwx rwx』
-
chmod [身份] [操作] [权限] 文件:更改文件权限属性
chmod o+W / o=rwx demo.txt : 给demo.txt文件的其他用户添加写入权限
chmod U+X demo.txt :给demo.txt文件的拥有者添加执行权限
chmod g-W demo.txt :给demo.txt文件的所属组取消写入权限
chmod a-r demo.txt :给demo.txt文件的所有用户取消只读权限
chmod 777 demo.txt :给每个数字对应的身份对应的权限
- r:4 w:2 x:1
-
chgrp [组名] [文件名]:更改文件所属组
- -R :递归更改文件属组
-
chown [属主名] [:属组名] [文件名]:更改文件所有者
压缩文件指令
-
zip / unzip :压缩文件后缀名改为zip
-
zip a.zip demo.txt
-
zip -r a.zip demo 压缩demo文件夹
-r :递归处理,将指定目录下的所有文件和子目录一并处理。
-
-
gzip / gunzip :压缩文件后缀名改为gz
-
gzip demo.txt :把原来的文件替换为demo.txt.gz
-k :保留原有文件
-r :递归压缩文件夹中的每一个文件都变成 .gz
-
-
tar:建立,还原备份文件的工具程序,它可以加入,解开备份文件内的文件
- -c :建立一个压缩包或者tar包。
- -x :解包或者解压缩
- -f :指定备份文件
- -v :显示指令执行过程。
- -t :列出备份文件的内容
- -z :通过gzip指令处理备份文件
- -j :通过bzip2指令处理备份文件
- -p :保留原文件属性
- -r :新增文件到已存在的备份文件的结尾部分
VIM
命令模式
用户刚刚启动 vi/vim,便进入了命令模式。此状态下敲击键盘动作会被Vim识别为命令,而非输入字符。比如我们此时按下i,并不会输入一个字符,i被当作了一个命令。以下是常用的几个命令:
| 光标移动 | |
|---|---|
| h 或 向左箭头键(←) | 光标向左移动一个字符 |
| j 或 向下箭头键(↓) | 光标向下移动一个字符 |
| k 或 向上箭头键(↑) | 光标向上移动一个字符 |
| l 或 向右箭头键(→) | 光标向右移动一个字符,例如向下移动 30 行,可以使用 "30j" 或 "30↓" 的组合按键 |
| [Ctrl] + [f] | 屏幕『向下』移动一页,相当于 [Page Down]按键 (常用) |
| [Ctrl] + [b] | 屏幕『向上』移动一页,相当于 [Page Up] 按键 (常用) |
| [Ctrl] + [d] | 屏幕『向下』移动半页 |
| [Ctrl] + [u] | 屏幕『向上』移动半页 |
| + | 光标移动到非空格符的下一行 |
| - | 光标移动到非空格符的上一行 |
| n |
那个 n 表示『数字』,例如 20 。按下数字后再按空格键,光标会向右移动这一行的 n 个字符。例如 20 |
| 0 或功能键[Home] | 这是数字『 0 』:移动到这一行的最前面字符处 (常用) |
| $ 或功能键[End] | 移动到这一行的最后面字符处(常用) |
| H | 光标移动到这个屏幕的最上方那一行的第一个字符 |
| M | 光标移动到这个屏幕的中央那一行的第一个字符 |
| L | 光标移动到这个屏幕的最下方那一行的第一个字符 |
| G | 移动到这个档案的最后一行(常用) |
| nG | n 为数字。移动到这个档案的第 n 行。例如 20G 则会移动到这个档案的第 20 行(可配合 :set nu) |
| gg | 移动到这个档案的第一行,相当于 1G 啊! (常用) |
| n |
n 为数字。光标向下移动 n 行(常用) |
| 搜索替换 | |
| /word | 向光标之下寻找一个名称为 word 的字符串。例如要在档案内搜寻 vbird 这个字符串,就输入 /vbird 即可! (常用) |
| ?word | 向光标之上寻找一个字符串名称为 word 的字符串。 |
| n | 这个 n 是英文按键。代表重复前一个搜寻的动作。举例来说, 如果刚刚我们执行 /vbird 去向下搜寻 vbird 这个字符串,则按下 n 后,会向下继续搜寻下一个名称为 vbird 的字符串。如果是执行 ?vbird 的话,那么按下 n 则会向上继续搜寻名称为 vbird 的字符串! |
| N | 这个 N 是英文按键。与 n 刚好相反,为『反向』进行前一个搜寻动作。 例如 /vbird 后,按下 N 则表示『向上』搜寻 vbird 。 |
| :n1,n2s/word1/word2/g | n1 与 n2 为数字。在第 n1 与 n2 行之间寻找 word1 这个字符串,并将该字符串取代为 word2 !举例来说,在 100 到 200 行之间搜寻 vbird 并取代为 VBIRD 则: 『:100,200s/vbird/VBIRD/g』。(常用) |
| :1,$s/word1/word2/g 或 :%s/word1/word2/g | 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !(常用) |
| :1,$s/word1/word2/gc或:%s/word1/word2/gc | 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !且在取代前显示提示字符给用户确认 (confirm) 是否需要取代!(常用) |
| 删除、复制与粘贴 | |
| x, X | 在一行字当中,x 为向后删除一个字符 (相当于 [del] 按键), X 为向前删除一个字符(相当于 [backspace] 亦即是退格键) (常用) |
| nx | n 为数字,连续向后删除 n 个字符。举例来说,我要连续删除 10 个字符, 『10x』。 |
| dd | 删除游标所在的那一整行(常用) |
| ndd | n 为数字。删除光标所在的向下 n 行,例如 20dd 则是删除 20 行 (常用) |
| d1G | 删除光标所在到第一行的所有数据 |
| dG | 删除光标所在到最后一行的所有数据 |
| d$ | 删除游标所在处,到该行的最后一个字符 |
| d0 | 那个是数字的 0 ,删除游标所在处,到该行的最前面一个字符 |
| yy | 复制游标所在的那一行(常用) |
| nyy | n 为数字。复制光标所在的向下 n 行,例如 20yy 则是复制 20 行(常用) |
| y1G | 复制游标所在行到第一行的所有数据 |
| yG | 复制游标所在行到最后一行的所有数据 |
| y0 | 复制光标所在的那个字符到该行行首的所有数据 |
| y$ | 复制光标所在的那个字符到该行行尾的所有数据 |
| p, P | p 为将已复制的数据在光标下一行贴上,P 则为贴在游标上一行! 举例来说,我目前光标在第 20 行,且已经复制了 10 行数据。则按下 p 后, 那 10 行数据会贴在原本的 20 行之后,亦即由 21 行开始贴。但如果是按下 P 呢? 那么原本的第 20 行会被推到变成 30 行。 (常用) |
| J | 将光标所在行与下一行的数据结合成同一行 |
| c | 重复删除多个数据,例如向下删除 10 行,[ 10cj ] |
| u | 复原前一个动作。(常用) |
| [Ctrl]+r | 重做上一个动作。(常用) |
| . | 不要怀疑!这就是小数点!意思是重复前一个动作的意思。 如果你想要重复删除、重复贴上等等动作,按下小数点『.』就好了! (常用) |
输入模式
在命令模式之中,只要按下 i, o, a 等字符就可以进入输入模式了
底线命令模式
| 指令 | 描述 |
|---|---|
| :w | 将编辑的数据写入硬盘档案中(常用) |
| :w! | 若文件属性为『只读』时,强制写入该档案。不过,到底能不能写入, 还是跟你对该档案的档案权限有关啊! |
| :q | 离开 vi (常用) |
| :q! | 若曾修改过档案,又不想储存,使用 ! 为强制离开不储存档案。 |
| :wq | 储存后离开,若为 :wq! 则为强制储存后离开 (常用) |
| :e! | 取消修改恢复到文件打开时的状态 |
| :set nu | 显示行号,设定之后,会在每一行的前缀显示该行的行号 |
| :w [filename] | 将编辑的数据储存成另一个档案(类似另存新档) |
| :r [filename] | 在编辑的数据中,读入另一个档案的数据。亦即将 『filename』 这个档案内容加到游标所在行后面 |
| :n1,n2 w [filename] | 将 n1 到 n2 的内容储存成 filename 这个档案。 |
| :! command | 暂时离开 vi 到指令行模式下执行 command 的显示结果!例如 『:! ls /home』即可在 vi 当中察看 /home 底下以 ls 输出的档案信息! |
| :n | 跳转到第n行 |
nginx
Nginx是一款自由的、开源的、高性能的HTTP服务器和反向代理服务器;同时也是一个IMAP、POP3、SMTP代理服务器;Nginx可以作为一个HTTP服务器进行网站的发布处理,另外Nginx可以作为反向代理进行负载均衡的实现。
- 进入到
/usr/local/nginx/sbin安装目录,使用./nginx命令启动nginx - html:默认站点目录
- 测试:在浏览器中输入localhost,看到welcome to nginx即表示成功
服务监听
- ps -ef / -aux:查看进程
- | grep xxx 过滤进程
- pstree:树形结构查看进程
- kill:杀死进程
- netstat:监听网络链接状态
- -a:显示所有socket,包括正在监听的。
- -n:以网络IP地址代替名称,显示出网络连接情形。
- -o:显示与与网络计时器相关的信息
- -t:显示TCP协议的连接情况
- -u:显示UDP协议的连接情况
- -p:显示建立相关连接的程序名和PID。
管道
管道的操作符是"|",它只能处理经由前面一个指令传出的正确输出信息,然后传递给下一个命令,作为下一个命令的标准输入。例如ps -ef | more
注意: 管道命令只能处理前一个命令的正确输出,不能处理错误输出。
- 管道命令的右边命令,必须要能够接收标准的输入流才行。
- 有些命令无法接受输入流,需要通过xargs来将输入流转换成为命令行参数。
如: find -name 2.txt | xargs rm -rf
重定向
标准输入(stdin)、标准输出(stdout)、 标准错误(stderr)
- 在linux中,创建任意进程,系统会自动创建上面三个数据流,其实就是三个文件
- 三个文件的描述符分别是: 0、1、2.其中,0默认指向键盘,1和2默认指向终端窗口。
- 重定向就是改变原来默认的表现位置。
> : 把执行结果重定向到一个指定的文件。如果文件已经存在,会覆盖。也可以写作 1>
ls . 1> demo.txt
>> :把执行结果追加到一个文件
ls . >> demo.txt
错误输出: 2> 将命令执行出错的结果重定向
lx . 2> demo.txt
全部输出: &> 把所有的输出都重定向
ls &> demo.txt lx &> demo.txt
shell编程
通过Shell中的各种命令,开发者和运维人员可以对服务器进行维护工作。但每次都手动输入命令,工作效率太低,而且很容易出错,尤其是需要维护大量服务器时。为了能够对服务器批量执行操作,我们可以将需要执行的命令写入文件,批量执行,这种文件便是Shell脚本。Shell脚本一般是以.sh 结尾的文本文件,当然,也可以省略扩展名。
脚本首行
脚本文件第一行通过注释的方式指明执行脚本的程序。
在Shell脚本中,# 开头的文本是注释,但第一句 #! 开头的这句话比较特殊,他会告诉Shell应该使用哪个程序来执行当前脚本。常见方式有:
-
!/bin/sh
-
!/bin/bash
-
!/usr/bin/env python
脚本运行
- bash xxx.sh
- source xxx.sh
- ./xxx.sh 以这种方式运行,文件必须有可执行权限 chmod a+x xxx.sh
数据库
数据库相关术语和概念
- 数据库:数据库是一 些关联表的集合。
- 数据表:表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列:一列(数据元素)包含了相同类型的数据,例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存诸两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键, 一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书的目录。
- 参照完整性:参照的完整性要求关系中不允许弓|用不存在的实体。 与实体完整性是关系模型必须满足的完整性
约束条件,目的是保证数据的一致性。
mysql
基本设置
配置文件: /etc/mysql/mysql.conf.d/mysqld.cnf /usr/local/lib/python3.8/dist-packages/mycli/myclirc
安装数据库
基于Debian平台的Linux系统,可以直接使用 apt 命令安装mysql
sudo apt install -y mysql-server mysql-client
开启数据库
Ubuntu : service mysql start|stop|restart|status
Deepin : systemctl start|stop|restart|status mysqld
CentOS7 : systemctl start|stop|restart|status mysqld
CentOS6 : service mysqld start|stop|restart|status
连接数据库
mysql -hloaclhost -uroot -p123456 -P3306
- -h : host(ip地址) localhost = 127.0.0.1
- -u : username(用户账户)
- -p : password(密码)
- -P : port(端口, 默认端口3306)
在其他版本的Linux里,root用户的默认密码是空,可以不使用密码直接登录。但是在CentOS7里,
mysql安装完成以后,会生成一个临时密码,我们需要通过命令查看到这个默认密码。
cat /var/log/mysqld.log |grep password
退出数据库
-
exit
-
quit
-
\q
-
ctrl + d
创建账户
CREATE USER "用户名"@"主机" IDENTIFIED BY "密码";
授予权限
GRANT ALL ON *.* TO "用户名"@"主机" WITH GRANT OPTION;
-
ALL PRIVILEGES : 授予全部权限, 也可以指定
select , insert , update , delete , create , drop , index , alter , grant , references ,reload , shutdown , process , file 十四个权限。
-
*.* : 允许操作的数据库和表。
-
主机名:表示允许用户从哪个主机登录, % 表示允许从任意主机登录
查看权限
show grants; -- 查看当前用户的权限
show grants for 'abc'@'localhost'; -- 查看用户 abc 的权限
回收权限
revoke all privileges on *.* from 'abc'@'localhost'; -- 回收用户 abc 的所有权限
revoke grant option on *.* from 'abc'@'localhost'; -- 回收权限的传递
删除用户
drop user "用户名"@"主机";
改密码
update user set authentication_string=password('你的密码') where user="root"
alter user root@localhost identified with mysql_native_password by '你的密码';
忘记密码
- 修改mysql配置文件(不同操作系统,不同MySql版本,配置文件存储不同,ubuntu18.04配置文
件保存在 /etc/mysql/mysql.conf.d/mysqld.cnf ; Centos7.7 配合文件保存在 /etc/my.cnf) - 添加这么一段:
如果文件中已存在 [mysqld] , 则直接将skip-grant-tables写到其下方即可。 - 修改完成后,保存退出,重启服务:
sudo systemctl restart mysql.service - 使用命令
sudo mysql -uroot重新连接MySql服务器,此时可以不使用密码直接登录用户。 - 执行
update mysql.user set authentication_string=password('你的密码') where user="root";修改root用户密码。 - 执行
flush privileges刷新策略,使策略立刻生效,并退出mysql客户端。 - 修改 /etc/msyql/mysql.cnf 文件,注释掉第二步添加的两段内容。
- 运行
sudo systemctl restart mysql.service重启mysql服务器。 - 此时可以使用新密码登录mysql服务器
MySQL 登录的两个阶段
- 第一阶段为连接验证,主要限制用户连接 mysql-server 时使用的 ip 及密码。
- 第二阶段为操作检查,主要检查用户执行的指令是否允许,一般非管理员账户不被允许执行drop,delete等危险操作。
权限控制安全准则
- 只授予能满足需要的最小权限,防止用户执行危险操作。
- 限制用户的登录主机,防止不速之客登录数据库。
- 禁止或删除没有密码的用户。
- 禁止用户使用弱密码。
- 定期清理无效的用户,回收权限或者删除用户。
数据库操作
新建数据库
create database [if not exists] `数据库名` charset=字符编码(utf8mb4);
#1. 如果多次创建会报错
#2. 如果不指定字符编码,默认为 utf8mb4 (一个汉字占用 4 个字节)
#3. 给数据库命名一定要习惯性加上反引号, 防止和关键字冲突
查看数据库
show databases;
选择数据库
use `数据库名`;
修改数据库
alter database `数据库名` charset=字符集;
删除数据库
drop database [if exists] `数据库名`;
表操作
新建表
create table [if not exists] `表的名字`(
id int not null auto_increment primary key comment '主键',
account char(255) comment '用户名' default 'admin',
pwd text(16383) comment '密码' not null)charset=utf8mb4; #不指定字符集默认继承数据库的
查看表
show tables;
删除表
drop table [if exists] `表名`
显示建表结构
desc `表名`;
describe `表名`;
show create table `表名`; #显示建表语句
修改表名
alter table `old_name` rename `new_name`;
移动表到指定的数据库
alter table `表名` rename to `数据库名.表名`;
增加一个字段
alter table `表名` add `字段名` 数据类型 [属性];
alter table `表名` add `字段名` 数据类型 [属性] first;
alter table `表名` add `字段名` 数据类型 [属性] after 指定字段;
修改字段类型
alter table `表名` modify `字段名` 数据类型 [属性];
修改字段名字
alter table `表名` change `原字段名` `新的字段名` 数据类型 [属性];
删除字段
alter table `表名` drop `字段名`
复制表
create table `新表名` like `原表名`
#特点: 复制后的表结构与原表完全相同,字段的属性与原表也完全一致。但是里面没有数据,
#为空表增加数据
insert into `新表名` select * from `原表名`;
create table `新表名` select * from `原表名`
#完整的复制一个表,既有原表的结构,又有原表的数据
#表内字段的属性会丢失,主键的自增等特性不复存在,新插入数据时会有问题
#最好不要使用这种方式复制
数据的增删改查
新增数据
#一次插入一行
insert into `表名` set `字段`=值, `字段`=值;
#按照指定字段, 一次插入多行
insert into `表名` (字段1, 字段2 ...) values (值1, 值2, ...), (值1, 值2, ...);
#指定全部字段, 一次插入多行
insert into `表名` values (null, 值1, 值2, ...), (null, 值1, 值2, ...);
更新数据
#修改全表数据
update `表名` set `字段1`=值, `字段2`=值;
#使用 where 修改满足条件的行
#where 类似于 if 条件, 只执行返回结果为 True 的语句
update `表名` set `字段1`=值, `字段2`=值 where `字段`=值;
update `表名` set `字段1`=值, `字段2`=值 where `字段`=值 and `字段`=值;
查找数据
#通过 * 获取全部字段的数据
select * from `表名`;
#获取指定字段的数据
select `字段1`, `字段2` from `表名`;
删除数据
#删除表中的所有数据 (逐行删除)
delete from `表名`;
#清空全表 (一次性整表删除)
truncate `表名`
#使用 where 修改满足条件的行
delete from `表名` where `字段` = 值;
delete from `表名` where `字段` in (1, 2, 3, 4);
编码
字符集
ASCII: 基于罗马字母表的一套字符集, 它采用1个字节的低7位表示字符, 高位始终为0。
LATIN1: 相对于ASCII字符集做了扩展, 仍然使用一个字节表示字符, 但启用了高位, 扩展了字
符集的表示范围。
GB2312: 简体中文字符, 一个汉字最多占用2个字节
GBK: 只是所有的中文字符, 一个汉字最多占用2个字节
UTF8: 国际通用编码, 一个汉字最多占用3个字节
UTF8MB4: 国际通用编码, 在utf8的基础上加强了对新文字识别, 一个汉字最多占用4个字节
校对集
在某一种字符集下, 为了使字符之间可以互相比较, 让字符和字符形成一种关系的集合, 称之为校对集。
比如说 ASCII 中的 a 和 B, 如果区分大小写 a > B, 如果不区分 a < B;不同字符集有不同的校对规则, 命名约定:以其相关的字符集名开始, 通常包括一个语言名, 并且以_ci 、_cs 或 _bin 结束。
_ci : 大小写不敏感
_cs : 大小写敏感
_bin : binary collation 二元法, 直接比较字符的编码, 可以认为是区分大小写的, 因为字符集中'A'和'a'的编码显然不同。
Linux中Mysql是区分大小的需要自己去配置
vim /etc/mysql/mysql.conf.d/mysqld.cnf
找到[mysqld] 然后添加 lower_case_table_names=1 1是不区分大小写,0是区分大小写
#查看是否区分大小写
show variables like '%case_table%';
数据类型
整型
显示宽度 (zerofill) 无符号(unsigned)
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 byte | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 bytes | (-32768,32767) | (0,65535) | 大整数值 |
| MEDIUMINT | 3 bytes | (-8388608,8388607) | (0,16777215) | 大整数值 |
| INT或INTEGER | 4 bytes | (-2147483648,2147483647) | (0,4294967295) | 大整数值 |
| BIGINT | 8 bytes | (-9223372036854775808,9223372036854775807) | (0,18446744073709551615) | 极大整数值 |
浮点型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| FLOAT | 4 bytes | (-3.402823466E+38,-1.175494351E-38),0,(1.175494351E-38,3.402823466351E+38) | 0,(1.175494351E-38,3.402823466E+38) | 单精度 浮点数值 |
| DOUBLE | 8 bytes | (-1.7976931348623157E+308,-2.225073858 5072014E-308),0,(2.2250738585072014E-308,1.7976931348623157E+308) | 0,(2.225073858507 2014E-308,1.797693 1348623157E+308) | 双精度 浮点数值 |
| DECIMAL | DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
字符型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16777215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16777215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294967295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294967295 bytes | 极大文本数据 |
布尔型
create table `bool`(cond boolean);
insert into `bool` set cond=True; #成功
insert into `bool` set cond=False; #成功
insert into `bool` set cond= 1; #成功
insert into `bool` set cond=-1; #成功
时间
| 类型 | 大小 ( bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
枚举
多选一的时候使用的一种数据类型
在前端使用单选框的时候, 枚举类型可以发挥作用
create table t6(name varchar(32),sex enum('男','女','保密') default '保密');
#枚举类型的计数默认从1开始
insert into t6 set name='王宝强',sex=1;
集合
SET最多可以有64个不同的成员。类似于复选框, 有多少可以选多少。
create table t7 (name varchar(32),hobby set('吃','睡','玩','喝','抽'));
insert into t7 values('张三','睡,抽,玩,吃,喝'); #集合用一个单引号括起来
insert into t7 values('李四','睡,抽');
属性
not null #不可以为空,如果插入的时候,摸个字段的值为空,则报错
default #默认值一般是和not null做搭配的
auto_increment #自动增长的列,默认从 1 开始,常配合主键使用的
primary key #主键一般是唯一的标识 特性:不能为空,也不能重复,一张表当中只可以拥有一个主键
unique #唯一键,保证列当中的每一个数据都不重复
comment #字段说明: 给开发者看的, 一般用来对相应字段进行说明,show create table xxx;
注释
SQL注释
单行注释: -- 你好
多行注释: /* 巴拉巴拉 */
MySQL 独有的单行注释: # 哈哈哈哈
运算符
算术运算符
select 123 + 543, 321 * 5, -456 / 2, 10 % 3, 2 / 0, 3 % 0;
+-----------+---------+-----------+--------+--------+--------+
| 123 + 543 | 321 * 5 | -456 / 2 | 10 % 3 | 2 / 0 | 3 % 0 |
+-----------+---------+-----------+--------+--------+--------+
| 666 | 1605 | -228.0000 | 1 | <null> | <null> |
+-----------+---------+-----------+--------+--------+--------+
逻辑运算符
select 2 and 0;
+---------+
| 2 and 0 |
+---------+
| 0 |
+---------+
select 2 or 0;
+--------+
| 2 or 0 |
+--------+
| 1 |
+--------+
select not 1;
+-------+
| not 1 |
+-------+
| 0 |
+-------+
比较运算符
select 1=2, 2<3, 3<=4, 4>5, 5>=3, 8!=9, 8<>9, 'abc' = 'Abc', 'z' > 'a';
+-----+-----+------+-----+------+------+------+---------------+-----------+
| 1=2 | 2<3 | 3<=4 | 4>5 | 5>=3 | 8!=9 | 8<>9 | 'abc' = 'Abc' | 'z' > 'a' |
+-----+-----+------+-----+------+------+------+---------------+-----------+
| 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
+-----+-----+------+-----+------+------+------+---------------+-----------+
select 123 between 100 and 200, 'b' in ('a', 'b', 'c'); #范围比较
+-------------------------+------------------------+
| 123 between 100 and 200 | 'b' in ('a', 'b', 'c') |
+-------------------------+------------------------+
| 1 | 1 |
+-------------------------+------------------------+
select 12 is null, 23 = null, null = null, null <=> null, null is null, 32 is not null; #null比较
+------------+-----------+-------------+---------------+--------------+---------------+
| 12 is null | 23 = null | null = null | null <=> null | null is null | 32 is not null|
| | | | | | |
+------------+-----------+-------------+---------------+--------------+---------------+
| 0 | <null> | <null> | 1 | 1 | 1 |
+------------+-----------+-------------+---------------+--------------+---------------+
select 'HelloWorld' like 'hello%'; #模糊比较
+----------------------------+
| 'HelloWorld' like 'hello%' |
+----------------------------+
| 1 |
+----------------------------+
查询属性
where
语法: select 字段 from 表名 where 条件;
WHERE 是做条件查询, 只返回结果为 True 的数据
having
HAVING 和WHERE 功能类似,having的搜索条件的字段必须出现在 select 的字段里,否则会报错
只能用where:
select `name`, `birthday` from `student` where id > 2;
select `name`, `birthday` from `student` having id > 2; #报错 id 不在前面的字段中
只能用having:
select name as n,birthday as b,id as i from student having i > 2;
select name as n,birthday as b,id as i from student where i > 2; #报错,i不存在,where只识别存在的字段
select city,min(birthday) from student group by city having min(year(birthday))>1996; #使用聚合函数
+------+---------------+
| city | min(birthday) |
+------+---------------+
| 台北 | 1998-03-28 |
+------+---------------+
分组查询
按照某一字段进行分组, 会把该字段中值相同的归为一组, 将查询的结果分类显示, 方便统计。
如果有 WHERE 要放在 WHERE 的后面
语法: select 字段 from 表名 group by 分组字段;
select city, group_concat(name) from student group by city;
+------+------------------------------------+
| city | group_concat(name) |
+------+------------------------------------+
| 上海 | 陈乔恩,张学友,陈意涵,张柏芝,马化腾 |
| 北京 | 郭德纲,赵丽颖,鹿晗,关晓彤, |
| 南京 | 赵本山,吴亦凡,马云 |
| 台北 | 周杰伦 |
| 重庆 | 王宝强,赵雅芝 |
+------+------------------------------------+
按字段排序
语法: select 字段 from 表名 order by 排序字段 asc|desc;
分为升序 asc 降序 desc, 默认 asc (可以不写)
select * from student order by money;
限制查询数量
select 字段 from 表名 limit m; -- 从第 1 行到第 m 行
select 字段 from 表名 limit m, n; -- 从第 m 行开始,往下取 n 行
select 字段 from 表名 limit m offset n; -- 跳过前 n 行, 取后面的 m 行
select * from student order by money desc limit 3;
+----+--------+-----+------+--------------+------------+-------+------------+
| id | name | sex | city | description | birthday | money | only_child |
+----+--------+-----+------+--------------+------------+-------+------------+
| 12 | 关晓彤 | 女 | 北京 | <null> | 1995-07-12 | 99.61 | 1 |
| 3 | 赵丽颖 | 女 | 北京 | 班花, 不骄傲 | 1995-04-04 | 96.07 | 0 |
| 7 | 陈意涵 | 女 | 上海 | <null> | 1994-08-30 | 91.33 | 1 |
+----+--------+-----+------+--------------+------------+-------+------------+
去重
select distinct city from student;
+------+
| city |
+------+
| 北京 |
| 上海 |
| 重庆 |
| 南京 |
| 台北 |
+------+
函数
聚合
| Name | Description |
|---|---|
| avg() | 返回平均值 |
| count() | 返回参数的行数 |
| max() | 返回最大值 |
| min() | 返回最小值 |
| sum() | 返回总和 |
| group_concat() | 返回连接的字符串 |
| std() | 返回样本标准差 |
| var_samp() | 返回样本方差 |
数值
| Name | Description |
|---|---|
| abs() | 返回绝对值 |
| ceil() | 向上取整 |
| floor() | 向下取整 |
| mod() | 取模 |
| rand() | 返回0-1的随机小数 |
| round(x,y) | 返回 x 四舍五入保留 y 位小数 |
| truncate() | 返回 x 截断为 y 位小数的值 |
时间
| Name | Description |
|---|---|
| curdate() | 返回当前日期 |
| curtime() | 返回当前时间 |
| now() | 返回当前日期和时间 |
| week(date) | 返回date为一年中的第几周 |
| year(date) | 返回date的年份 |
| monthname(date) | 返回月份名 |
| hour(date) | 返回date 的小时值 |
| minute(date) | 返回date 的分钟值 |
| from_unixtime(date) | 返回unix时间戳对应的日期 |
| unix_timestamp(date) | 返回unix时间戳 |
| datadiff(t1,t2) | 两个日期差的天数 |
字符串
| Name | Description |
|---|---|
| length() | 返回字符串长度 |
| concat(s1,s2..) | 连接s1,s2 |
| insert(s,x,y,str) | 将s从第x位置开始y个字符长的子串替换为str |
| lower() | 将字符串变小写 |
| upper() | 将字符串变大写 |
| left(str,x) | 返回字符串左边x个字符 |
| lpad(str,n,pad) | 用pad对str从左边开始填充至n个字符长度 |
| ltrim() | 去掉字符串左边的空格 |
| repeat(str,x) | 重复字符串x次 |
| replace(str,a,b) | 用 b 替换 str 中所有的 a |
| strcmp(s1,s2) | 比较字符串s1,s2 |
| substring(str,x,y) | 返回str从x起y个字符的字符串 |
系统
| Name | Description |
|---|---|
| database() | 返回当前数据库名 |
| version() | 返回当前数据库版本 |
| user() | 返回当前登录用户名 |
| password() | 返回字符串加密版本 |
| MD5() | 返回字符串MD5值 |
多表查询
UNION
- 两边 select 语句的字段数必须一样
- 两边可以具有不同数据类型的字段
- 字段名默认按照左边的表来设置
select id,name,sex from student union select * from score;
+----+--------+------+
| id | name | sex |
+----+--------+------+
| 1 | 郭德纲 | 男 |
| 2 | 陈乔恩 | 女 |
| 3 | 赵丽颖 | 女 |
| 4 | 王宝强 | 男 |
| 5 | 赵雅芝 | 女 |
| 6 | 张学友 | 男 |
| 7 | 陈意涵 | 女 |
| 8 | 赵本山 | 男 |
| 9 | 张柏芝 | 女 |
| 10 | 吴亦凡 | 男 |
| 11 | 鹿晗 | 男 |
| 12 | 关晓彤 | 女 |
| 13 | 周杰伦 | 男 |
| 14 | 马云 | 男 |
| 15 | 马化腾 | 男 |
| 1 | 49 | 71 |
| 2 | 62 | 66.7 |
| 3 | 44 | 86 |
| 4 | 77.5 | 74 |
| 5 | 41 | 75 |
| 6 | 82 | 59.5 |
| 7 | 64.5 | 85 |
| 8 | 62 | 98 |
| 9 | 44 | 36 |
| 10 | 67 | 56 |
| 11 | 81 | 90 |
| 12 | 78 | 70 |
| 13 | 83 | 66 |
| 14 | 40 | 90 |
| 15 | 90 | 90 |
+----+--------+------+
INNER JOIN
在表中存在至少一个匹配时返回对应行的数据。
select name,sex,score.* from student inner join score on student.id=score.id;
+--------+-----+----+------+---------+
| name | sex | id | math | english |
+--------+-----+----+------+---------+
| 郭德纲 | 男 | 1 | 49.0 | 71.0 |
| 陈乔恩 | 女 | 2 | 62.0 | 66.7 |
| 赵丽颖 | 女 | 3 | 44.0 | 86.0 |
| 王宝强 | 男 | 4 | 77.5 | 74.0 |
| 赵雅芝 | 女 | 5 | 41.0 | 75.0 |
| 张学友 | 男 | 6 | 82.0 | 59.5 |
| 陈意涵 | 女 | 7 | 64.5 | 85.0 |
| 赵本山 | 男 | 8 | 62.0 | 98.0 |
| 张柏芝 | 女 | 9 | 44.0 | 36.0 |
| 吴亦凡 | 男 | 10 | 67.0 | 56.0 |
| 鹿晗 | 男 | 11 | 81.0 | 90.0 |
| 关晓彤 | 女 | 12 | 78.0 | 70.0 |
| 周杰伦 | 男 | 13 | 83.0 | 66.0 |
| 马云 | 男 | 14 | 40.0 | 90.0 |
| 马化腾 | 男 | 15 | 90.0 | 90.0 |
+--------+-----+----+------+---------+
LEFT JOIN
从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
select student.id,name,sex,math,english from student left join score on student.id=score.id;
+----+-------+-----+--------+---------+
| id | name | sex | math | english |
+----+-------+-----+--------+---------+
| 1 | 郭德纲 | 男 | 49.0 | 71.0 |
| 2 | 陈乔恩 | 女 | 62.0 | 66.7 |
| 3 | 赵丽颖 | 女 | 44.0 | 86.0 |
| 4 | 王宝强 | 男 | 77.5 | 74.0 |
| 5 | 赵雅芝 | 女 | 41.0 | 75.0 |
| 6 | 张学友 | 男 | 82.0 | 59.5 |
| 7 | 陈意涵 | 女 | 64.5 | 85.0 |
| 8 | 赵本山 | 男 | 62.0 | 98.0 |
| 9 | 张柏芝 | 女 | 44.0 | 36.0 |
| 10 | 吴亦凡 | 男 | 67.0 | 56.0 |
| 11 | 鹿晗 | 男 | <null> | <null> |
| 12 | 关晓彤 | 女 | 78.0 | 70.0 |
| 13 | 周杰伦 | 男 | <null> | <null> |
+----+--------+-----+--------+--------+
RIGHT JOIN
从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。
select score.*, name,sex from student right join score on student.id=score.id;
+----+------+---------+--------+--------+
| id | math | english | name | sex |
+----+------+---------+--------+--------+
| 1 | 49.0 | 71.0 | 郭德纲 | 男 |
| 2 | 62.0 | 66.7 | 陈乔恩 | 女 |
| 3 | 44.0 | 86.0 | 赵丽颖 | 女 |
| 4 | 77.5 | 74.0 | 王宝强 | 男 |
| 5 | 41.0 | 75.0 | 赵雅芝 | 女 |
| 6 | 82.0 | 59.5 | 张学友 | 男 |
| 7 | 64.5 | 85.0 | 陈意涵 | 女 |
| 8 | 62.0 | 98.0 | 赵本山 | 男 |
| 9 | 44.0 | 36.0 | 张柏芝 | 女 |
| 10 | 67.0 | 56.0 | 吴亦凡 | 男 |
| 12 | 78.0 | 70.0 | 关晓彤 | 女 |
| 14 | 60.0 | 70.0 | <null> | <null> |
+----+------+---------+--------+--------+
FULL JOIN
FULL JOIN 的连接方式是只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回
行。相当于结合了 LEFT JOIN 和 RIGHT JOIN 的结果。
特别注意: MySQL 并不支持 full join
视图表
- 视图是数据的特定子集,是从其他表里提取出数据而形成的虚拟表,或者说临时表。
- 创建视图表依赖一个查询。
- 视图是永远不会自己消失的除非手动删除它。
- 视图有时会对提高效率有帮助。临时表不会对性能有帮助,是资源消耗者。
- 视图一般随该数据库存放在一起,临时表永远都是在 tempdb 里的。
- 视图适合于多表连接浏览时使用;不适合增、删、改,这样可以提高执行效率。
- 一般视图表的名称以 v_ 为前缀,用来与正常表进行区分。
- 对原表的修改会影响到视图中的数据。
create view 视图名 as 查询语句
存储引擎
存储引擎就是如何存储数据、如何为数据建立索引和如何更新、查询数据等技术的实现方法。MySQL 默认支持多种存储引擎,以适用于不同领域 的数据库应用需要,用户可以通过选择使用不同的存储引擎提高应用的效率,提供灵活的存储。
#查看当前存储引擎
show variables like '%storage_engine';
show engines;
InnoDB
事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键,InnoDB是默认的MySQL引擎。
InnoDB主要特性有:
- InnoDB 给 MySQL 提供了具有提交、回滚、崩溃恢复能力的事务安全存储引擎。
- InnoDB 是为处理巨大数据量的最大性能设计。它的 CPU 效率比其他基于磁盘的关系型数据库引擎高。
- InnoDB 存储引擎自带缓冲池,可以将数据和索引缓存在内存中。
- InnoDB 支持外键完整性约束。
- InnoDB 被用在众多需要高性能的大型数据库站点上
- InnoDB 支持行级锁
MyISAM
MyISAM 基于 ISAM 存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM 拥有较高的插入、查询速度,但不支持事物。
MyISAM主要特性有:
-
大文件支持更好
-
当删除、更新、插入混用时,产生更少碎片。
-
每个 MyISAM 表最大索引数是64,这可以通过重新编译来改变。每个索引最大的列数是16
-
最大的键长度是1000字节。
-
BLOB和TEXT列可以被索引
-
NULL 被允许在索引的列中,这个值占每个键的0~1个字节
-
所有数字键值以高字节优先被存储以允许一个更高的索引压缩
-
MyISAM 类型表的 AUTO_INCREMENT 列更新比 InnoDB 类型的 AUTO_INCREMENT 更快
-
可以把数据文件和索引文件放在不同目录
-
每个字符列可以有不同的字符集
-
有 VARCHAR 的表可以固定或动态记录长度
-
VARCHAR 和 CHAR 列可以多达 64KB
-
只支持表锁
Memory
MEMORY 存储引擎将表中的数据存储到内存中,为查询和引用其他表数据提供快速访问。
FULL JOIN
InnoDB 和 MyISAM 的区别
-
InnoDB 将一张表存储为两个文件
-
demo.frm -> 存储表的结构和索引
-
demo.ibd -> 存储数据,ibd 存储是有限的, 存储不足自动创建 ibd1, ibd2
-
InnoDB 的文件创建在对应的数据库中, 不能任意的移动
-
-
MyISAM 将一张表存储为三个文件
- demo.frm -> 存储表的结构
- demo.myd -> 存储数据
- demo.myi -> 存储表的索引
- MyISAM 的文件可以任意的移动
关系与外键
关系
-
一对一
- 在 A 表中有一条记录,在 B 表中同样有唯一条记录相匹配,比如: 学生表和成绩表
-
一对多 / 多对一
- 在 A 表中有一条记录,在 B 表中有多条记录一直对应,比如: 博客中的用户表和文章表
-
多对多
- A 表中的一条记录有多条 B 表数据对应, 同样 B 表中一条数据在 A 表中也有多条与之对应,比如: 博客的收藏表
外键
外键是一种约束。他只是保证数据的一致性,并不能给系统性能带来任何好处。建立外键时,都会在外键列上建立对应的索引。外键的存在会在每一次数据插入、修改时进行约束检查,如果不满足外键约束,则禁止数据的插入或修改,这必然带来一个问题,就是在数据量特别大的情况下,每一次约束检查必然导致性能的下降。出于性能的考虑,如果我们的系统对性能要求较高,那么可以考虑在生产环境中不使用外键。
索引
MyISAM和InnoDB存储引擎:只支持BTREE索引
-
单列索引:一个索引只包含单个列,但一个表中可以有多个单列索引。 这里不要搞混淆了。
- 普通索引:MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点。
- 唯一索引:索引列中的值必须是唯一的,但是允许为空值,
- 主键索引:是一种特殊的唯一索引,不允许有空值。
-
组合索引
在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀集合
-
全文索引
全文索引,只有在MyISAM引擎上才能使用,只能在CHAR,VARCHAR,TEXT类型字段上使用全文索引,介绍了要求,说说什么是全文索引,就是在一堆文字中,通过其中的某个关键字等,就能找到该字段所属的记录行,比如有"你是个靓仔,靓女 ..." 通过靓仔,可能就可以找到该条记录。
-
空间索引
空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有四种,GEOMETRY、POINT、LINESTRING、POLYGON。在创建空间索引时,使用SPATIAL关键字。要求,引擎为MyISAM,创建空间索引的列,必须将其声明为NOT NULL。
建立索引
CREATE INDEX indexName ON mytable(username(length));
ALTER table tableName ADD INDEX indexName(columnName)
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
删除索引
DROP INDEX [indexName] ON mytable;
事务
简介
事务主要用于处理操作量大、复杂度高、并且关联性强的数据。
比如说, 在人员管理系统中, 你删除一个人员, 你即需要删除人员的基本资料, 也要删除和该人员相关的信息, 如信箱, 文章等等, 这样, 这些数据库操作语句就构成一个事务!
在 MySQL 中只有 Innodb 存储引擎支持事务。
事务处理可以用来维护数据库的完整性, 保证成批的 SQL 语句要么全部执行, 要么全部不执行。主要针对 insert, update, delete 语句而设置。
特性
在写入或更新资料的过程中, 为保证事务 (transaction) 是正确可靠的, 所必须具备的四个特性 (ACID):
-
原子性 (Atomicity) :
- 事务中的所有操作, 要么全部完成, 要么全部不完成, 不会结束在中间某个环节。
- 事务在执行过程中发生错误, 会被回滚 (Rollback) 到事务开始前的状态, 就像这个事务从来没有执行过一样。
-
一致性 (Consistency):
在事务开始之前和事务结束以后, 数据库的完整性没有被破坏。 这表示写入的资料必须完全符合所有的预设规则, 这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
-
隔离性 (Isolation):
并发事务之间互相影响的程度,比如一个事务会不会读取到另一个未提交的事务修改的数据。在事务并发操作时,可能出现的问题有: 脏读:事务A修改了一个数据,但未提交,事务B读到了事务A未提交的更新结果,如果事务A提交失败,事务B读到的就是脏数据。 不可重复读:在同一个事务中,对于同一份数据读取到的结果不一致。比如,事务B在事务A提交前读到的结果,和提交后读到的结果可能不同。不可重复读出现的原因就是事务并发修改记录,要避免这种情况,最简单的方法就是对要修改的记录加锁,这回导致锁竞争加剧,影响性能。另一种方法是通过MVCC可以在无锁的情况下,避免不可重复读。 幻读:在同一个事务中,同一个查询多次返回的结果不一致。事务A新增了一条记录,事务B在事务A提交前后各执行了一次查询操作,发现后一次比前一次多了一条记录。幻读是由于并发事务增加记录导致的,这个不能像不可重复读通过记录加锁解决,因为对于新增的记录根本无法加锁。需要将事务串行化,才能避免幻读。
事务的隔离级别从低到高有:
-
读取未提交 (Read uncommitted)
- 所有事务都可以看到其他未提交事务的执行结果
- 本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少
- 该级别引发的问题是——脏读(Dirty Read):读取到了未提交的数据
-
读提交 (read committed)
-
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)
-
它满足了隔离的简单定义:一个事务只能看见已经提交事务做的改变
-
这种隔离级别出现的问题是: 不可重复读(Nonrepeatable Read):
不可重复读意味着我们在同一个事务中执行完全相同的 select 语句时可能看到不一样的结果。
导致这种情况的原因可能有:
- 有一个交叉的事务有新的commit,导致了数据的改变;
- 一个数据库被多个实例操作时,同一事务的其他实例在该实例处理其间可能会有新的commit
-
-
可重复读 (repeatable read)
- 这是MySQL的默认事务隔离级别
- 它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行
- 此级别可能出现的问题: 幻读(Phantom Read):当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行
- InnoDB 通过多版本并发控制 (MVCC,Multiversion Concurrency Control) 机制解决幻读问题;
- InnoDB 还通过间隙锁解决幻读问题
-
串行化 (Serializable)
- 这是最高的隔离级别
- 它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。MySQL锁总结
- 在这个级别,可能导致大量的超时现象和锁竞争
-
-
持久性 (Durability):
事务处理结束后, 对数据的修改就是永久的, 即便系统故障也不会丢失。
语法与使用
-
开启事务:
BEGIN或START TRANSACTION -
提交事务:
COMMIT, 提交会让所有修改生效 -
回滚:
ROLLBACK, 撤销正在进行的所有未提交的修改 -
创建保存点:
SAVEPOINT identifier -
删除保存点:
RELEASE SAVEPOINT identifier -
把事务回滚到保存点:
ROLLBACK TO identifier -
查询事务的隔离级别:
show variables like '%isolation%'; -
设置事务的隔离级别:
SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE}InnoDB 提供的隔离级别有
READUNCOMMITTEDREAD COMMITTEDREPEATABLE READSERIALIZABLE
存储过程
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。
存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
- 优点
- 存储过程可封装,并隐藏复杂的商业逻辑。
- 存储过程可以回传值,并可以接受参数。
- 存储过程无法使用 SELECT 指令来运行,因为它是子程序,与查看表,数据表或用户定义函数不同。
- 存储过程可以用在数据检验,强制实行商业逻辑等。
- 缺点
- 存储过程,往往定制化于特定的数据库上,因为支持的编程语言不同。当切换到其他厂商的数据库系统时,需要重写原有的存储过程。
- 存储过程的性能调校与撰写,受限于各种数据库系统。
语法
-
声明语句结束符,可以自定义:
存储过程中有很多的SQL语句,SQL语句的后面为了保证语法结构必须要有分号(;),但是默认情况下分号表示客户端代码发送到服务器执行。必须更改结束符
DELIMITER $$ -
声明存储过程:
CREATE PROCEDURE demo_in_parameter(IN p_in int) -
存储过程开始和结束符号:
BEGIN .... END -
变量赋值:
SET @p_in=1 -
变量定义:
DECLARE l_int int unsigned default 4000000; -
创建mysql存储过程、存储函数:
create procedure 存储过程名(参数) -
存储过程体:
create function 存储函数名(参数)
使用
-
简单用法
#定义,如果存储过程中就一条SQL语句,begin…end两个关键字可以省略 create procedure get_info() select * from student; call get_info(); #调用 -
复杂一点的 (备注:只能在标准 mysql 客户端中执行,mycli 无法识别)
delimiter // #定义前,将分隔符改成 // create procedure foo(in uid int) begin select * from student where `id`=uid; update student set `city`='北京' where `id`=uid; end// delimiter ; -- 定义完以后可以将分隔符改回 分号 call foo(3); -
查看存储过程
show create procedure foo; show procedure status like "%foo%"; -
删除存储过程
drop procedure foo;
python操作
import pymysql
db = pymysql.connect(host='192.168.133.128',user='DR',password='961101',
database='python',port=3306,charset='utf8')
cursor = db.cursor() #创建游标对象
cursor.execute('select * from ss') #执行mysql语句
cursor.close()
db.commit()
print(cursor.fetchall()) #获取所有结果
db.close() #关闭数据库连接
#((1, '郭德纲', '男', '北京', '班长', datetime.date(1997, 10, 1), 31.37, 1, 67.0, 71.0), (2,'陈乔恩',)
sql注入
SQL注入(SQLi)是一种注入攻击,可以执行恶意SQL语句。它通过将任意SQL代码插入数据库查询,使攻击者能够完全控制Web应用程序后面的数据库服务器。攻击者可以使用SQL注入漏洞绕过应用程序安全措施;可以绕过网页或Web应用程序的身份验证和授权,并检索整个SQL数据库的内容;还可以使用SQL注入来添加,修改和删除数据库中的记录。
数据备份与恢复
-
备份
mysqldump -h localhost -u root -p dbname > dbname.sql -
恢复
mysql -h localhost -u root -p123456 dbname < ./dbname.sql
redis
Redis 是一种基于键值对的NoSQL数据库,它提供了对多种数据类型(字符串、哈希、列表、集合、有序集合、位图等)的支持,能够满足很多应用场景的需求。Redis将数据放在内存中,因此读写性能是非常惊人的。与此同时,Redis也提供了持久化机制,能够将内存中的数据保存到硬盘上,在发生意外状况时数据也不会丢掉。此外,Redis还支持键过期、地理信息运算、发布订阅、事务、管道、Lua脚本扩展等功能,总而言之,Redis的功能和性能都非常强大,如果项目中要实现高速缓存和消息队列这样的服务,直接交给Redis就可以了。目前,国内外很多著名的企业和商业项目都使用了Redis,包括:Twitter、Github、StackOverflow、新浪微博、百度、优酷土豆、美团、小米、唯品会等。
基本设置
配置文件: /etc/redis/redis.conf
安装数据库
基于Debian平台的Linux系统,可以直接使用 apt 命令安装redis
sudo apt install -y redis-server
启动数据库
redis-server [redis.conf]
redis-cli [-h localhost -p 6379]
特点
- Redis的读写性能极高,并且有丰富的特性(发布/订阅、事务、通知等)。
- Redis支持数据的持久化(RDB和AOF两种方式),可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis支持多种数据类型,包括:string、hash、list、set,zset、bitmap、hyperloglog等。
- Redis支持主从复制(实现读写分离)以及哨兵模式(监控master是否宕机并自动调整配置)。
- Redis支持分布式集群,可以很容易的通过水平扩展来提升系统的整体性能。
- Redis基于TCP提供的可靠传输服务进行通信,很多编程语言都提供了Redis客户端支持。
应用场景
-
高速缓存 - 将不常变化但又经常被访问的热点数据放到Redis数据库中,可以大大降低关系型数据库的压力,从而提升系统的响应性能。
-
排行榜 - 很多网站都有排行榜功能,利用Redis中的列表和有序集合可以非常方便的构造各种排行榜系统。
-
商品秒杀/投票点赞 - Redis提供了对计数操作的支持,网站上常见的秒杀、点赞等功能都可以利用Redis的计数器通过+1或-1的操作来实现,从而避免了使用关系型数据的
update操作。 -
分布式锁 - 利用Redis可以跨多台服务器实现分布式锁(类似于线程锁,但是能够被多台机器上的多个线程或进程共享)的功能,用于实现一个阻塞式操作。
-
消息队列 - 消息队列和高速缓存一样,是一个大型网站不可缺少的基础服务,可以实现业务解耦和非实时业务削峰等特性,这些我们都会在后面的项目中为大家展示。
持久化存储
Redis在运行时,所有的数据都保存在内存里,进程结束以后,会将数据写入到硬盘中。启动时,会读取硬盘里的内容,并将内容全部加载到内存中(会大量的占用内存)。
RDB
默认的持久化方式,是对内存中的数据进行镜像,并以二进制的形式保存到dump.rdb文件中。会根据配置文件的时间节点对文件进行持久化。
save 900 1
save 300 10
save 60 10000
rdbcompression yes # 压缩 RDB 文件
rdbchecksum yes # 对 RDB 文件进行校验
dbfilename dump.rdb # RDB 数据库文件的文件名
dir /var/lib/redis # RDB 文件保存的目录
优点:速度快,直接镜像内存里的数据,文件小。
缺点:数据有可能会丢失,在两次保存间隔内的数据,有可能会丢失。
AOF
AOF(Append only file)持久化,将修改的每一条指令记录进appendonly.aof中,需要修改配置文件,来打开aof功能。
appendonly always:每次有新命令追加到aof文件时就执行一个持久化,非常慢但是安全
appendonly everysec:每秒执行一次持久化,足够快(和使用rdb持久化差不多)并且在故障时只会丢失1秒钟的数据
appendonly no:从不持久化,将数据交给操作系统来处理。redis处理命令速度加快但是不安全。
优点:适合保存增量数据,数据不丢失。
缺点:文件体积大,恢复时间长
数据库操作
键
keys *
查看所有键。
del key
删除key。
dump key
返回序列化key的值。
exists key
key是否存在。
ttl key
key 的过期时间。
type key
返回key 的类型。
字符串
set key value [expiration EX seconds|PX milliseconds] [NX|XX]
如果 key 已经持有其他值, SET 就覆写旧值, 无视类型。
EX seconds: 将键的过期时间设置为seconds秒。PX milliseconds: 将键的过期时间设置为milliseconds毫秒。NX: 只在键不存在时, 才对键进行设置操作。 执行SET key value NX的效果等同于执行SETNX key value。XX: 只在键已经存在时, 才对键进行设置操作。
get key
如果键 key 不存在, 那么返回特殊值 nil ; 否则, 返回键 key 的值。
getset key value
将键 key 的值设为 value , 并返回键 key 在被设置之前的旧值。
如果键 key 没有旧值, 也即是说, 键 key 在被设置之前并不存在, 那么命令返回 nil 。
当键 key 存在但不是字符串类型时, 命令返回一个错误。
mset key1 value1 key2 value2 ...
同时为多个键设置值。如果某个给定键已经存在, 那么 MSET 将使用新值去覆盖旧值, 如果这不是你所希望的效果, 请考虑使用 MSETNX 命令
mget key1 key2 key3...
返回给定的多个字符串键的值。如果给定的字符串键里面, 有某个键不存在, 那么这个键的值将以特殊值 nil 表示。
incr key
为键 key 储存的数字值加上一。
如果键 key 不存在, 那么它的值会先被初始化为 0 , 然后再执行 INCR 命令。
如果键 key 储存的值不能被解释为数字, 那么 INCR 命令将返回一个错误。
incrby key x
为键 key 储存的数字值加上 x 。
decr key
为键 key 储存的数字值减去一。
decrby key x
为键 key 储存的数字值减去 x 。
strlen key
返回键 key 储存的字符串值的长度。
append key value
如果键 key 已经存在并且它的值是一个字符串, APPEND 命令将把 value 追加到键 key 现有值的末尾。
如果 key 不存在, APPEND 就简单地将键 key 的值设为 value , 就像执行 SET key value 一样。
setrange key offset value
从偏移量 offset 开始, 用 value 参数覆写键 key 储存的字符串值。
不存在的键 key 当作空白字符串处理。
getrange key start end
返回键 key 的指定部分, 字符串的截取范围由 start 和 end 两个偏移量决定 (包括 start 和 end 在内)。
哈希表
hset hash field value
将哈希表 hash 中域 field 的值设置为 value 。
hget hash field
返回哈希表中给定域的值。
hexists hash field
检查给定 field 是否存在于哈希表 hash 当中.
hdel hash field1 field2
删除哈希表 hash 中的一个或多个指定域,不存在的域将被忽略。
hlen hash
返回哈希表 key 中域的数量。
hstrlen hash field
返回哈希表 hash 中, 与给定域 field 相关联的值的字符串长度(string length)。
hincrby hash field increment
为哈希表 hash 中的域 field 的值加上增量 increment 。
hmset hash field1 value1 field2 value2
同时将多个 field-value (域-值)对设置到哈希表 hash 中。
hmget hash field1 field2
返回哈希表 hash 中,一个或多个给定域的值。
hkeys hash
返回哈希表 key 中的所有域。
hvals hash
返回哈希表 key 中所有域的值。
hgetall dog
返回哈希表 key 中,所有的域和值。
列表
lpush key value1 value2 value3
将一个或多个值 value 从左边插入到列表 key 。
rpush key value1 value2 value3
将一个或多个值 value 从右边插入到列表 key 。
lpop key
从左边移除并返回列表 key 的头元素。
rpop key
从右边移除并返回列表 key 的头元素。
rpoplpush key1 key2
把 key1 中右边的元素弹出并从左边放入key2,如果两个列表一样,那相当于逐渐旋转列表.
lrem key count value
从key 中移除 count 数量的value,count>0,从左到右,count<0,从右到左,count = 0,移除所有。
llen key
返回列表长度。
lindex key index
返回列表中, 下标为 index 的元素。
linsert key before|after pivot value
将值 value 插入到列表 key 当中,位于值 pivot 之前或之后。
lset key index value
将列表 key 下标为 index 的元素的值设置为 value
lrange key start stop
返回列表 key 中指定区间内的元素,区间以偏移量 start 和 stop 指定。
ltrim key start stop
对一个列表进行修剪(trim),让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
集合
sadd key member1 member2
将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略。
sidmember key member
判断 member 元素是否集合 key 的成员。
spop key
移除并返回集合中的一个随机元素。
srandmember key
如果命令执行时,只提供了 key 参数,那么返回集合中的一个随机元素。
srem key member
移除集合 key 中的一个或多个 member 元素,不存在的 member 元素会被忽略。
smove source destination member
将 member 元素从 source 集合移动到 destination 集合。
scard key
返回集合长度。
smembers key
返回集合 key 中的所有成员。
sinter key1 key2
返回一个交集。
sinterstore source key1 key2
将交集保存到source
sunion key1 key2
返回并集。
sdiff key1 key2
返回差集。
有序集合
zadd key value1 member1 value2 member2
将一个或多个 member 元素及其值加入到有序集合 key 当中。
zsocre key member
返回有序集 key 中,成员 member 的 score 值。
zincrby key increment member
为有序集 key 的成员 member 的 score 值加上增量 increment 。
zcard key
返回有序集 key 的长度。
zcount key min max
返回有序集 key 中, score 值在 min 和 max 之间(默认包括 score 值等于 min 或 max )的成员的数量。
zrange key start stop [withscores]
返回有序集 key 中,指定区间内的成员,升序。
zrevrange key start stop
降序。
zrangebyscores key min max [WITHSCORES] [LIMIT offset count]
返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
zrangebyscores key min max [WITHSCORES] [LIMIT offset count]
降序。
zrank key member
返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递增(从小到大)顺序排列。
zrem key member
移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。
zremrangebyrank key start stop
移除有序集 key 中,指定排名(rank)区间内的所有成员。
zremrangebyscores key min max
移除有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。
python操作
import redis
client = redis.Redis(host='localhost', port=6379, password='1qaz2wsx')
client.set('username', 'admin')
#True
client.hset('student', 'name', 'hao')
#1
client.hset('student', 'age', 38)
#1
client.keys('*')
#[b'username', b'student']
client.get('username')
#b'admin'
client.hgetall('student')
#{b'name': b'hao', b'age': b'38'}
mongodb
MongoDB将数据存储为一个文档,一个文档由一系列的“键值对”组成,其文档类似于JSON对象,但是MongoDB对JSON进行了二进制处理(能够更快的定位key和value),因此其文档的存储格式称为BSON。
基本设置
配置文件: /etc/mongdb.conf
数据库操作
新建数据库
show datasbases #显示所有数据库
use python01 #创建并切换操作的数据库
删除数据库
db.dropDatabase() #删除当前数据库
新建表
db.createCollection('student')
删除表
db.student.drop()
数据的增删改查
新增数据
db.student.insert({'name':'dr','age':1})
db.test.insert({'name':'dr','age':1}) #如果输错表名则会创建一个新的存放数据
db.test.insertMany([{},{},{}]) #插入多条数据
更新数据
db.collection.update(<query>,<update>,[upsert,multi,writeConcern])
db.students.update({'name':'dr'},{'name':'www'})
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
- upsert : 这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
查找数据
db.student.find(<query>, <projection>).pretty().limit(1).skip(1)
- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。不设置则查询时返回文档中所有键值。
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|
| 等于 | {key:value} |
db.col.find({"by":"菜鸟教程"}).pretty() |
where by = '菜鸟教程' |
| 小于 | {key:{$lt:value}} |
db.col.find({"likes":{$lt:50}}).pretty() |
where likes < 50 |
| 小于或等于 | {key:{$lte:value}} |
db.col.find({"likes":{$lte:50}}).pretty() |
where likes <= 50 |
| 大于 | {key:{$gt:value}} |
db.col.find({"likes":{$gt:50}}).pretty() |
where likes > 50 |
| 大于或等于 | {key:{$gte:value}} |
db.col.find({"likes":{$gte:50}}).pretty() |
where likes >= 50 |
| 不等于 | {key:{$ne:value}} |
db.col.find({"likes":{$ne:50}}).pretty() |
where likes != 50 |
删除数据
db.collection.remove(<query>,[justOne,writeConcern])
db.student.remove({}) #删除表中全部数据
- query :删除的文档的条件。
- justOne : 如果设为 true 或 1,则只删除一个文档,不设置则默认值 false,则删除所有匹配条件的文档。
- writeConcern :抛出异常的级别。
聚合与管道
聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
db.mycol.aggregate( [ { $group : {_id : "$by_user", num_tutorial : {$sum : 1}} } ] )
{ #结果
"result" : [
{
"_id" : "runoob.com",
"num_tutorial" : 2
},
{
"_id" : "Neo4j",
"num_tutorial" : 1
}
],
"ok" : 1
}
select by_user, count(*) as num_tutorial from mycol group by by_user #类似sql语句
聚合函数:
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{\(group : {_id : "\)by_user", num_tutorial : {\(sum : "\)likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{\(group : {_id : "\)by_user", num_tutorial : {\(avg : "\)likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{\(group : {_id : "\)by_user", num_tutorial : {\(min : "\)likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{\(group : {_id : "\)by_user", num_tutorial : {\(max : "\)likes"}}}]) |
| $push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{\(group : {_id : "\)by_user", url : {\(push: "\)url"}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{\(group : {_id : "\)by_user", url : {\(addToSet : "\)url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{\(group : {_id : "\)by_user", first_url : {\(first : "\)url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{\(group : {_id : "\)by_user", last_url : {\(last : "\)url"}}}]) |
管道
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
python操作
from pymongo import MongoClient
client = MongoClient('mongodb://127.0.0.1:27017')
db = client.school
for student in db.students.find():
print('学号:', student['stuid'])
print('姓名:', student['name'])
print('电话:', student['tel'])
'''
学号: 1001.0
姓名: 张三
电话: 13566778899
学号: 1002.0
姓名: 王大锤
电话: 13012345678
学号: 1003.0
姓名: 白元芳
电话: 13022223333
'''
db.students.find().count()
#3
db.students.remove()
#{'n': 3, 'ok': 1.0}
db.students.find().count()
#0
from pymongo import ASCENDING
coll = db.students
coll.create_index([('name', ASCENDING)], unique=True)
#'name_1'
coll.insert_one({'stuid': int(1001), 'name': '张三', 'gender': True})
#<pymongo.results.InsertOneResult object at 0x1050cc6c8>
coll.insert_many([{'stuid': int(1002), 'name': '王大锤', 'gender': False}, {'stuid': int(1003), 'name': '白元芳', 'gender': True}])
#<pymongo.results.InsertManyResult object at 0x1050cc8c8>
for student in coll.find({'gender': True}):
print('学号:', student['stuid'])
print('姓名:', student['name'])
print('性别:', '男' if student['gender'] else '女')
'''
学号: 1001
姓名: 张三
性别: 男
学号: 1003
姓名: 白元芳
性别: 男
'''
数据分析
numpy
创建数组
import numpy as np
np.array([1,2,3,4,5],dtype=float) # array([1., 2., 3., 4., 5.])
np.array([[1,2,3,4],[5,6,7,8]]) # 创建2维数组
np.
| 方法 | 描述 |
|---|---|
| array(list/tuple) | 将输入数据(列表、元组、数组或其它序列类型)转换为ndarray。要么推断出dtype,要么特别指定dtype |
| asarray(x) | 将输入对象转换为ndarray,不会产生新对象 |
| arange(s,e,l) | 类似于内置的range,但返回的是一个ndarray而不是列表 |
| ones(shape) | 根据指定的形状和dtype创建一个全 1 数组。 |
| ones_like(shape) | 以另一个数组形状为参照,创建一个全 1 数组。 |
| zeros(shape) | 根据指定的形状和dtype创建一个全 0 数组。 |
| zeros_like(shape) | 以另一个数组形状为参照,创建一个全 0 数组。 |
| full(shape,val) | 用 val 的值,根据指定的形状和dtype创建一个数组。 |
| full_like | 以另一个数组形状为参照,用 val 的值创建数组。 |
| empty | 创建新数组,只分配内存空间但不填充任何值 |
| eye(n) | 创建一个正方的NxN单位矩阵(对角线为1,其余为0) |
| diag([a,b,c]) | 创建一个对角线为a,b,c的正方形矩阵,其余为0 |
| linspace(s,e,n) | 创建从s开始到e一共n个的等差数列 |
| logspace(s,e,n) | 创建从s开始到e一共n个的等比数列 |
属性
| 属性 | 描述 |
|---|---|
| shape | 对象的形状 |
| ndim | 对象的秩,即轴或维度的数量 |
| size | 对象拥有的元素个数 |
| dtype | 对象的元素类型 |
| itemsize | 对象中每个元素的大小,以字节为单位 |
数据类型
| 类型 | 简写 | 说明 |
|---|---|---|
| int8,uint8 | i1,u1 | 有符号和无符号的8位整型 |
| int16,uint16 | i2,u2 | 有符号和无符号的16位整型 |
| int32,uint32 | i4,u4,int | 有符号和无符号的32位整型 |
| int64,uint64 | i8,u8 | 有符号和无符号的64位整型 |
| float16 | f2 | 半精度浮点数 |
| float32 | f4,f | 标准单精度浮点数 |
| float64 | f8,float,d | 标准双精度浮点数 |
| float128 | f16,g | 扩展精度浮点数 |
| complex64,128,256 | c8,c16,c32 | 分别用两个32,64,128位浮点数表示的复数 |
| bool | ? | True或者False |
nan(NAN,Nan):not a number表示不是一个数字
什么时候numpy中会出现nan:
当我们读取本地的文件为float的时候,如果有缺失,就会出现nan
当做了一个不合适的计算的时候(比如无穷大(inf)减去无穷大)
- np.nan != np.nan
- nan和任何值计算结果都为nan
t=np.array([1.,2.,nan])
np.count_nonzero(t!=t) #1
np.isnan(t) == t!=t
inf(-inf,inf):infinity,inf表示正无穷,-inf表示负无穷
什么时候会出现inf包括(-inf,+inf)
比如一个数字除以0,(python中直接会报错,numpy中是一个inf或者-inf)
索引和切片
跟列表最重要的区别在于,数组切⽚是原始数组的视图。这意味着数据不会被复制,视图上的任何修改都会直接反映到源数组上
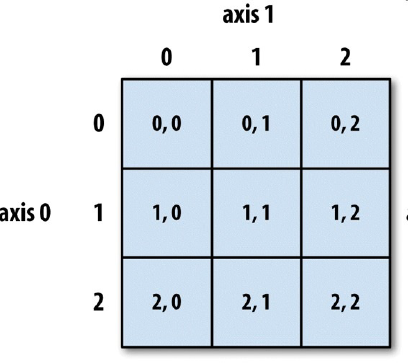
arr = np.arange(24).reshape(2,3,4)
b1 = arr[0]
'''array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])'''
b2 = arr[0,1]
#array([4, 5, 6, 7])
b3 = arr[0,1,2]
# 6
布尔型索引
布尔型数组的⻓度必须跟被索引的轴⻓度⼀致。通过布尔型索引选取数组中的数据,将总是创建数据的副本,即使返回⼀模⼀样的数组也是如此。
data=np.arange(24).reshape(6,4)
a=np.array([1,2,3,1,2,1])
data
#array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11],
# [12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23]])
data[a==1]
#array([[ 0, 1, 2, 3],
# [12, 13, 14, 15],
# [20, 21, 22, 23]])
data[data>10]=0
#array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 0],
# [ 0, 0, 0, 0],
# [ 0, 0, 0, 0],
# [ 0, 0, 0, 0]])
花式索引
为了以特定顺序选取行子集,只需传入⼀个用于指定顺序的整数列表或ndarray即可:
data[[3,1,5]]
#array([[12, 13, 14, 15],
# [ 4, 5, 6, 7],
# [20, 21, 22, 23]])
⼀次传入多个索引数组会有⼀点特别。它返回的是⼀个⼀维数组,其中的元素对应各个索引元组:
data[[3,1,5],[2,0,1]]
#array([14, 4, 21]) (3,2)(1,0)(5,1)
#想选取第2,0,1行只能用切片方式:
data[[3,1,5]][:,[2,0,1]]
广播
- 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加 1 补齐。
- 输出数组的形状是输入数组形状的各个维度上的最大值。
- 如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错。
- 当输入数组的某个维度的长度为 1 时,沿着此维度运算时都用此维度上的第一组值。
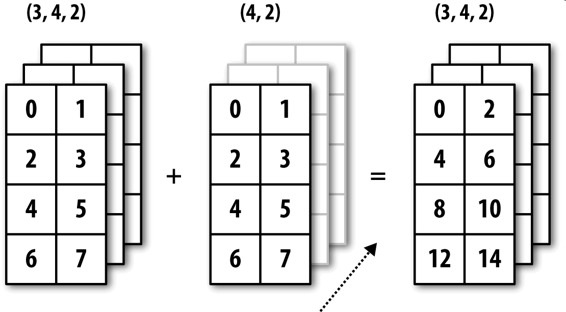
内置函数
一元函数
| 函数 | 说明 |
|---|---|
| abs(),fabs() | 计算整数、浮点数或复数的绝对值。针对于非复数值,可以使用更快的fabs() |
| sqrt() | 计算机各元素的平方根,相当于arr**0.5 |
| square() | 计算各元素的平方,相当于arr**2 |
| exp() | 计算各元素的e的x次方 |
| log,log10,log2,log1p | 分别自然对数(底数为e)、底数为10的log、底数为2的log,log(1+x) |
| sign | 计算各元素的正负号:1(正数)、0(零)、-1(负数) |
| ceil | 计算各元素的ceiling值,即大于等于该值的最小正数 |
| floor | 计算各元素的floor值,即小于等于该值的最大正数 |
| rint | 将各元素值四舍五入到最接近的整数,保留dtype |
| modf | 将数组的小数和整数部分以两个独立数组的形式返回 |
| isnan | 返回一个表示“哪些值是NaN(这不是一个数字)”的布尔型数组 |
| isfinite,isinf | 分别返回一个表示“哪些元素是有穷的(非inf,非NaN)或哪些元素是无穷的”的布尔型数组 |
| cos,cosh,sin,sinh,tan,tanh | 普通型和双曲型三角函数 |
| arccos,arccosh,arcsin,arcsinh,arctan,arctanh | 反三角函数 |
| logical_not | 计算各元素notx的真值。相当于-arr |
二元函数
| 函数 | 说明 |
|---|---|
| add(arr1,arr2) | 将数组中对应的元素想加 |
| subtract(arr1,arr2) | 从第一个数组中减去第二个数组中对应元素 |
| multiply(arr1,arr2) | 数组元素对应相乘 |
| divide(arr1,arr2),floor_divide(arr1,arr2) | 除法或向下圆整除法(丢弃余数) |
| power(arr1,arr2) | 对第一个数组中的元素A,根据第二个数组中的相应元素B,计算A的B次方 |
| maximum(arr1,arr2),fmax(arr1,arr2) | 元素级的最大值计算。fmax将忽略NaN |
| minimum(arr1,arr2),fmin(arr1,arr2) | 元素级的最小值计算。fmin将忽略NaN |
| mod(arr1,arr2) | 元素级的求模计算(除法取余) |
| copysign(arr1,arr2) | 将第2个数组中的值的符号复制给第一个数组中的值 |
| greater(arr1,arr2),greater_equal(arr1,arr2),(less(arr1,arr2),less_equal(arr1,arr2) | 或者(equal(arr1,arr2),not_equal(arr1,arr2))执行元素级的比较运算,最终产生布尔型数组,相当于中缀运算符>,>=,<,<=,==,!= |
| logical_and,logical_or,logical_xor | 执行元素级的真值逻辑运算,相当于运算符&、|、^ |
统计函数
| 函数 | 说明 | 例子 |
|---|---|---|
| sum | 对数组中全部或者某轴方向的元素求和,选择的轴是最后结果的方向,如选择行,就是将表压缩为一行 | np.sum(a) 或 a.sum() |
| mean | 算术平均数,零长度的数组的mean为NaN | np.mean(a) 或 a.mean() |
| average | 加权平均,权重相同时,也可看作时算术平均 | np.average(a) |
| median | 中位数,一组有序数列的中间数,偶数时,取平均 | np.median(a) |
| std、var | 分别求标准差和方差,自由度可调(默认为n) | a.std()、a.var() |
| min、max | 最小值和最大值 | a.max() |
| argmin、argmax | 分别为最小元素和最大元素的索引 | a.argmin()、a.argmax() |
| diff | diff(a, n=1, axis=-1),后一个与前一个的差值,参数n表示进行n轮运算,多维数组中,可通过axis控制方向 | np.diff(a) |
| cumsum | 所有元素和累计和(数组) | a.cumsum() |
| cumprod | 所有元素的累计积(数组) | np.cumprod() |
集合运算
| 函数 | 说明 | 例子 |
|---|---|---|
| unique(x) | 计算x中唯一元素,并返回有序的结果 | np.unique(s0) |
| intersect1d(x,y) | 交集,并返回有序结果 | np.intersect1d(s1,s2) |
| union1d(x,y) | 并集,并返回有序结果 | np.union1d(s1,s2) |
| setdiff1d(x,y) | 集合差,即元素在x中且不再y中 | np.setdiff1d(s1,s2) |
| setxor1d(x,y) | 集合对称差,只存在x和y中的元素集合 | np.setxor1d(s1,s2) |
| in1d(x,y) | 得到一个x的元素是否包含于y”的布尔行数组 | np.in1d(s2,s1) |
三元运算符
np.where(data>10,10,0) #大于10的等于10,否则等于0
#array([[ 0, 0, 0, 0],
# [ 0, 0, 0, 0],
# [ 0, 0, 0, 10],
# [10, 10, 10, 10],
# [10, 10, 10, 10],
# [10, 10, 10, 10]])
data.clip(10,18) #小于10的等于10,大于18的等于18
#array([[10, 10, 10, 10],
# [10, 10, 10, 10],
# [10, 10, 10, 11],
# [12, 13, 14, 15],
# [16, 17, 18, 18],
# [18, 18, 18, 18]])
数组拼接
t1
#array([[ 0, 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10, 11]])
t2
#array([[12, 13, 14, 15, 16, 17],
# [18, 19, 20, 21, 22, 23]])
np.vstack((t1,t2)) #竖直拼接
#array([[ 0, 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10, 11],
# [12, 13, 14, 15, 16, 17],
# [18, 19, 20, 21, 22, 23]])
np.hstack((t1,t2)) #水平拼接
#array([[ 0, 1, 2, 3, 4, 5, 12, 13, 14, 15, 16, 17],
# [ 6, 7, 8, 9, 10, 11, 18, 19, 20, 21, 22, 23]])
读写文件
NumPy能够读写磁盘上的⽂本数据或⼆进制数据。默认情况下,数组是以未压缩的原始⼆进制格式保存在扩展名为.npy的文件中的:
arr=np.arange(10)
np.save(r'arr1',arr)
np.load(r'arr1.npy')
np.savez(r'some_arr',a=arr1,b=arr2,..)
s=np.load(r'some_arr')
s['a'] s['b']
高级应用
数组重塑
a=np.arange(12).resize(3,4) #和reshape一样但不产生副本
a1=np.arange(12).reshape(3,4) #将数组产生一个3行4列的新副本
#作为参数的形状的其中⼀维可以是-1,它表示该维度的⼤⼩由数据本身推断
a2=np.arange(15).reshape(3,-1)
a1.ravel()
#array([0,1,2,3..11])
#ravel不会产⽣源数据的副本。
#flatten⽅法的⾏为类似于ravel,只不过它总是返回数据的副本
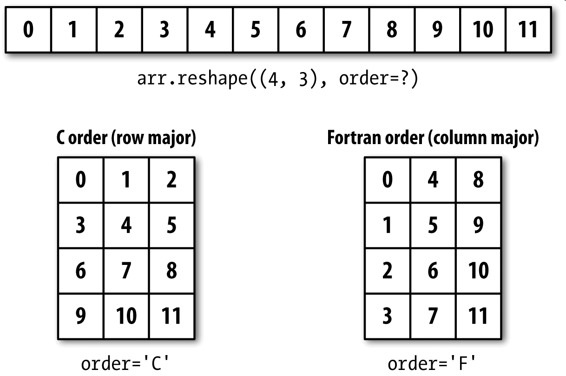
split用于将一个数组沿指定轴拆分为多个数组
c=np.arange(12),reshape(6,2)
f1,f2,f3 = np.split(c,[2,4])
#array([[0, 1], array([[4, 5], array([[ 8, 9],
# [2, 3]]) [6, 7]]) [10, 11]])
元素的重复
a=np.arange(3)
a.repeat(2)
#array([0, 0, 1, 1, 2, 2])
a.repeat([1,2,3])
#array([0, 1, 1, 2, 2, 2])
d=np.arange(4).reshape(2,2)
d.repeat(2,0)
#array([[0, 1],
# [0, 1],
# [2, 3],
# [2, 3]])
np.tile(d,3)
#array([[0, 1, 0, 1, 0, 1],
# [2, 3, 2, 3, 2, 3]])
#第⼆个参数是瓷砖的数量。对于标量,瓷砖是⽔平铺设的,⽽不是垂直铺设。它可以是⼀个表示“铺设”布局的元组
转置
arr=np.arange(12).reshape(6,2)
#array([[ 0, 1, 2, 3, 4],
# [ 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14]])
arr.T
#array([[ 0, 5, 10],
# [ 1, 6, 11],
# [ 2, 7, 12],
# [ 3, 8, 13],
# [ 4, 9, 14]])
#对于⾼维数组,transpose需要得到⼀个由轴编号组成的元组才能对这些轴进⾏转置
arr=np.arange(24).reshape(2,3,4)
arr.transpose((1, 0, 2)) # 3,2,4
#array([[[ 0, 1, 2, 3],
# [12, 13, 14, 15]],
# [[ 4, 5, 6, 7],
# [16, 17, 18, 19]],
# [[ 8, 9, 10, 11],
# [20, 21, 22, 23]]])
pandas
Series
Series是⼀种类似于⼀维数组的对象,它由⼀组数据(各种NumPy数据类型)以及⼀组与之相关的数据标签(即索引)组成。
创建
import pandas as pd
a=pd.Series([0,1,2,3,4],index=['a','b','c','d','e'])
a=pd.Series({'a':0,'b':1,'c':2,'d':3,'e':4})
# a 0
# b 1
# c 2
# d 3
# e 4
# dtype: int64
属性
a.name='sss'
a.index.name='sy'
# sy
# a 0
# b 1
# c 2
# d 3
# e 4
# Name:sss, dtype: int64
a.index
# Index(['a', 'b', 'c', 'd', 'e'], dtype='object',name='sy')
a.values
# array([0, 1, 2, 3, 4], dtype=int64)
索引和切片
a['a'] # 0
a[0] # 0
a[['b','e','c']]
# b 2
# e 5
# c 3
# dtype: int64
#利⽤标签的切⽚运算与普通的Python切⽚运算不同,其末端是包含的:
a['b':'d']
# b 1
# c 2
# d 3
# dtype: int64
a[1:3] #如果索引为整数,切片的时候会有歧义
重新索引
obj=pd.Series([4.5, 7.2, -5.3, 3.6], index=list('dbac'))
# d 4.5
# b 7.2
# a -5.3
# c 3.6
# dtype: float64
obj.reindex(list('abcde'))
# a -5.3
# b 7.2
# c 3.6
# d 4.5
# e NaN
# dtype: float64
增删改查
b=pd.Series([1,2],index=['a','b'])
b['age']=10
# a 1
# b 2
# age 10
# dtype: int64
b.drop('a') #返回的是⼀个在指定轴上删除了指定值的新对象
# b 2
# age 10
# dtype: int64
del b['a'] #删除原数据的索引行
b['b']=1
# b 1
# age 10
# dtype: int64
缺失值
pd.isnull()
pd.notnull()
a.isnull()
运算
根据运算的索引标签⾃动对⻬数据
a
# a 0
# b 1
# c 2
#dtype: int64
b
# b 3
# c 4
# e 5
# dtype: int64
a+b
# a NaN
# b 5.0
# c 7.0
# e NaN
# dtype: float64
排序
根据条件对数据集排序(sorting)也是⼀种重要的内置运算。要对行或列索引进⾏排序(按字典顺序),可使⽤sort_index方法,它将返回⼀个已排序的新对象。对于DataFrame需要选择排序的轴。
ser.sort_index(ascending=False) 降序排序
要按值对Series进行排序,可使⽤其sort_values方法。在排序时,任何缺失值默认都会被放到Series的末尾。(na_position='first)' 能让NaN在首位.
排名
obj = pd.Series([7, -5, 7, 4, 2, 0, 4])
obj.rank() #两个4分别是第4和第5,所以是4.5。同理两个7是6.5
0 6.5
1 1.0
2 6.5
3 4.5
4 3.0
5 2.0
6 4.5
obj.rank(method='first') #根据原数据中出现顺序的排名
0 6.0
1 1.0
2 7.0
3 4.0
4 3.0
5 2.0
6 5.0
obj.rank(ascending=False, method='max') #降序
0 2.0
1 7.0
2 2.0
3 4.0
4 5.0
5 6.0
6 4.0
DataFrame
DataFrame是⼀个表格型的数据结构,它含有⼀组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有⾏索引也有列索引,它可以被看做由Series组成的字典(共用同⼀个索引)。DataFrame中的数据是以⼀个或多个⼆维块存放的(而不是列表、字典或别的⼀维数据结构)。
创建
DataFrame会⾃动加上索引(跟Series⼀样),且全部列会被有序排列
x={'name':['a','b','c'],'age':[1,2,3]}
data=pd.DataFrame(x)
# name age
# 0 a 1
# 1 b 2
# 2 c 3
data=pd.DataFrame(x,columns=['age','name'])
#如果指定了列序列,则DataFrame的列就会按照指定顺序进⾏排列
data=pd.DataFrame(x,columns=['age','name','phone'])
#如果传⼊的列在数据中找不到,就会在结果中产⽣缺失值
# age name phone
# 0 1 a NaN
# 1 2 b NaN
# 2 3 c NaN
pop = {'Nevada': {2001: 2.4, 2002: 2.9},
'Ohio': {2000:1.5,2001: 1.7, 2002: 3.6}}
data2=pd.DataFrame(pop)
# Nevada Ohio
# 2001 2.4 1.7
# 2002 2.9 3.6
# 2000 NaN 1.5
data3=pd.DataFrame([[1,2,3,4],[5,6,7,8]])
0 1 2 3
0 1 2 3 4
1 5 6 7 8
属性
data.columns
# Index(['age', 'name'], dtype='object')
data.values
# array([[1, 'a'],
# [2, 'b'],
# [3, 'c']], dtype=object)
data.index
# RangeIndex(start=0, stop=3, step=1) index对象不可变
data.columns.name
data.index.name
data.shape
data.dtypes
data.ndim
data.head()
data.tail()
data.info()
data.describe()
索引对象
pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series或DataFrame时,所⽤到的任何数组或其他序列的标签都会被转换成⼀个Index对象.Index对象是不可变的,因此用户不能对其进⾏修改
index1=data.index
index1[1:]
#RangeIndex(start=1, stop=3, step=1)
frame = pd.Series([4,5,6],index=index1)
Index对象的方法
| 方法 | 说明 |
|---|---|
| append | 连接另一个Index对象,产生一个新的Index |
| difference | 计算差集 |
| intersection | 计算交集 |
| union | 计算并集 |
| isin | 计算一个指示各值是否都包含在参数集合中的布尔型数组 |
| delete | 删除指定索引处的元素 |
| drop | 删除传入的值 |
| insert | 将元素插入到指定索引处 |
| is_monotonic | 当各元素均大于等于前一个元素时,返回True |
| is_unique | 当Index没有重复值时,返回True |
| unique | 计算Index中唯一值的数组 |
重新索引
frame=pd.DataFrame(np.arange(9).reshape((3, 3)),
index=['a', 'c', 'd'],
columns=['Ohio', 'Texas','zz'])
Ohio Texas zz
a 0 1 2
c 3 4 5
d 6 7 8
frame.reindex(list('abcd'),[fill_value=0]) #替换NaN的值
Ohio Texas zz
a 0.0 1.0 2.0
b NaN NaN NaN
c 3.0 4.0 5.0
d 6.0 7.0 8.0
frame.reindex(columns=['Texas', 'Utah', 'California'])
Texas Utah California
a 1 NaN NaN
c 4 NaN NaN
d 7 NaN NaN
reindex参数
| 参数 | 说明 |
|---|---|
| index | 用作索引的新序列,可以是Index对象,可换成columns |
| method | 缺失值填充方式 |
| fill_value | 替代缺失值的值 |
| limit | 前向或后向填充时的最大填充量 |
| tolerance | 前向或后向填充时,填充不准确匹配项的最大间距 |
| level | 在MultiIndex的指定级别上匹配简单索引,否则选取其子集 |
| copy | 默认为True,产生新副本 |
索引和切片
s=pd.DataFrame(np.arange(12).reshape(3,4),
index=['a','b','c'],columns=['q','w','e','r'])
q w e r
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
s[['q','r']]
q r
a 0 3
b 4 7
c 8 11
s[:2]
q w e r
a 0 1 2 3
b 4 5 6 7
loc
通过标签索引行数据
s.loc['a','q'] # 0
s.loc[['a','b'],'w']
# a 1
# b 5
# Name: w, dtype: int32
s.loc[['a','c'],['q','r']]
q r
a 0 3
c 8 11
iloc
通过位置索引行数据
s.iloc[0,0] # 0
s.loc[[0,1],]
# a 1
# b 5
s.loc[[0,2],[0,3]]
q r
a 0 3
c 8 11
增删改查
#通过类似字典的方式或属性,可以将DataFrame的列获取为⼀个Series
data['age']
# 0 1
# 1 2
# 2 3
# Name: age, dtype: int64#
data.name
# 0 a
# 1 b
# 2 c
# Name: name, dtype: object
data['phone']=np.arange(3)
# age name phone
# 0 1 a 0
# 1 2 b 1
# 2 3 c 2
#将列表或数组赋值给某个列时,为不存在的列赋值会创建出⼀个新列。其⻓度必须跟DataFrame的⻓度相匹配。如果赋值的是⼀个Series,就会精确匹配DataFrame的索引,所有的空位都将被填上缺失值
t=pd.DataFrame(np.arange(12).reshape(3,4))
t.drop(1)
0 1 2 3
0 0 1 2 3
2 8 9 10 11
t.drop(1,axis=1) #选取轴
0 2 3
0 0 2 3
1 4 6 7
2 8 10 11
t.drop([1,2],inplace=True) #原地修改
0 1 2 3
0 0 1 2 3
del data['phone'] #删除某列
转置
data2.T
2000 2001 2002
Nevada NaN 2.4 2.9
Ohio 1.5 1.7 3.6
运算
df1
a b c d
0 0.0 1.0 2.0 3.0
1 4.0 5.0 6.0 7.0
2 8.0 9.0 10.0 11.0
df2
a b c d e
0 0.0 1.0 2.0 3.0 4.0
1 5.0 NaN 7.0 8.0 9.0
2 10.0 11.0 12.0 13.0 14.0
3 15.0 16.0 17.0 18.0 19.0
df1+df2
a b c d e
0 0.0 2.0 4.0 6.0 NaN
1 9.0 NaN 13.0 15.0 NaN
2 18.0 20.0 22.0 24.0 NaN
3 NaN NaN NaN NaN NaN
df1.add(df2,fill_value=0)
a b c d e
0 0.0 2.0 4.0 6.0 4.0
1 9.0 5.0 13.0 15.0 9.0
2 18.0 20.0 22.0 24.0 14.0
3 15.0 16.0 17.0 18.0 19.0
df1.sub(df2)
df1.mul(df2)
df1.div(df2)
df1.pow(df2)
df1.radd(df2) # r代表公式反转
#默认情况下,DataFrame和Series之间的算术运算会将Series的索引匹配到DataFrame的列,然后沿着⾏⼀直向下⼴播,需要指定轴号才能匹配行
s
q w e r
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
p=s['q']
a 0
b 4
c 8
s-p
a b c e q r w
a NaN NaN NaN NaN NaN NaN NaN
b NaN NaN NaN NaN NaN NaN NaN
c NaN NaN NaN NaN NaN NaN NaN
s.sub(q,axis='index')
q w e r
a 0 1 2 3
b 0 1 2 3
c 0 1 2 3
自定义函数
f = lambda x: x.max() - x.min()
a=pd.DataFrame(np.arange(12).reshape(3,4),
columns=['a','b','c','d'])
a b c d
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
a.apply(f) #apply是应用于轴级别的函数,applymap应用于元素级, Series是map
a 8
b 8
c 8
d 8
a.apply(f,1)
0 3
1 3
2 3
def f(x):
return pd.Series([x.min(), x.max()], index=['min','max'])
a.apply(f)
a b c d
min 0 1 2 3
max 8 9 10 11
排序
根据条件对数据集排序(sorting)也是⼀种重要的内置运算。要对行或列索引进⾏排序(按字典顺序),可使⽤sort_index方法,它将返回⼀个已排序的新对象。对于DataFrame需要选择排序的轴。
framae.sort_index(axis=1,ascending=False) 对columns降序排序
要按值对Series进行排序,可使⽤其sort_values方法。在排序时,任何缺失值默认都会被放到Series的末尾。(na_position='first)' 能让NaN在首位
当排序⼀个DataFrame时,你可能希望根据⼀个或多个列中的值进行排序。将⼀个或多个列的名字传递给sort_values(by=)
frame=pd.DataFrame({'a':[4,7,-3,2],'b':[0,1,2,-1]})
a b
0 4 0
1 7 1
2 -3 2
3 2 -1
frame.sort_values(by='b')
a b
3 2 -1
0 4 0
1 7 1
2 -3 2
frame.sort_values(by=0,axis=1)
b a
0 0 4
1 1 7
2 2 -3
3 -1 2
排名
frame = pd.DataFrame({'b': [4.3, 7, -3, 2],
'a': [0,1,0,1],'c': [-2, 5, 8, -2.5]})
a b c
0 0 4.3 -2.0
1 1 7.0 5.0
2 0 -3.0 8.0
3 1 2.0 -2.5
frame.rank(axis='columns')
a b c
0 2.0 3.0 1.0
1 1.0 3.0 2.0
2 2.0 1.0 3.0
排名相等时的方法
| 方法 | 说明 |
|---|---|
| average | 默认,使用平均排名 |
| min | 使用最小排名 |
| max | 使用最大排名 |
| first | 按原值的出现顺序 |
| dense | 相同元素不占排名位置 |
统计函数
| Function | 描述 |
|---|---|
| count | 值的个数 |
| sum | 求和 |
| mean | 求平均值 |
| mad | 平均绝对方差 |
| median | 中位数 |
| min | 最小值 |
| max | 最大值 |
| argmin | 计算能够获取到最小值的索引位置(整数) |
| argmax | 计算能够获取到最大值的索引位置 |
| idxmin | 每列最小值的行索引 |
| idxmax | 每列最大值的行索引 |
| mode | 众数 |
| abs | 绝对值 |
| prod | 乘积 |
| std | 标准差 |
| var | 方差 |
| sem | 标准误 |
| skew | 偏度系数 |
| kurt | 峰度 |
| quantile | 分位数 |
| cumsum | 累加 |
| cumprod | 累乘 |
| cummax | 累最大值 |
| cummin | 累最小值 |
| cov() | 协方差 |
| corr() | 相关系数 |
| rank() | 排名 |
| pct_change() | 时间序列变化 |
| value_counts | Series中各值出现的频率 |
读取文件
read_csv
从文件、URL、文件新对象中加载带有分隔符的数据,默认分隔符是逗号。
data.txt
a,b,c,d,name
1,2,3,4,python
5,6,7,8,java
9,10,11,12,c++
#有标题行
data = pd.read_csv("data.txt")
print(data)
a b c d name
0 1 2 3 4 python
1 5 6 7 8 java
2 9 10 11 12 c++
data2.txt
1,2,3,4,python
5,6,7,8,java
9,10,11,12,c++
#无标题行,默认将第一行作为标题
data = pd.read_csv("data2.txt")
print(data)
1 2 3 4 python
0 5 6 7 8 java
1 9 10 11 12 c++
data = pd.read_csv("data2.txt",header=None) #设置无标题
print(data)
0 1 2 3 4
0 1 2 3 4 python
1 5 6 7 8 java
2 9 10 11 12 c++
data = pd.read_csv("data2.txt",names=["a","b","c","d","name"],index_col='name')
#names设置标题索引,index_col设置行索引
print(data)
a b c d
name
python 1 2 3 4
java 5 6 7 8
c++ 9 10 11 12
data3.txt
key1,key2,value1,value2
a,a,1,2
a,b,3,4
b,c,5,6
b,d,7,8
c,e,9,10
c,f,11,12
#指定多个列为列索引产生一个层次化索引
data = pd.read_csv("data3.txt",index_col=["key1","key2"])
print(data)
value1 value2
key1 key2
a a 1 2
b 3 4
b c 5 6
d 7 8
c e 9 10
f 11 12
data4.txt
name a b c d
python 1 2 3 4
java 5 6 7 8
c++ 9 10 11 12
#对于不规则分隔符,使用正则表达式读取文件
data = pd.read_csv("data4.txt",sep=" ")
print(data)
name a Unnamed: 2 Unnamed: 3 b Unnamed: 5 c Unnamed: 7 \
python NaN NaN 1.0 NaN 2 3.0 NaN NaN
java 5.0 6.0 NaN 7.0 8 NaN NaN NaN
c++ NaN 9.0 NaN NaN 10 NaN NaN 11.0
Unnamed: 8 Unnamed: 9 d
python NaN NaN 4.0
java NaN NaN NaN
c++ NaN 12.0 NaN #没有选对分隔符让数据失去意义
data = pd.read_csv("data4.txt",sep="\s+")
print(data)
name a b c d
0 python 1 2 3 4
1 java 5 6 7 8
2 c++ 9 10 11 12
data5.txt
data.txt
name,a,b,c,d
python,1,2,3,4hello
java,5,6,7,8
word
c++,9,10,11,12
#跳行读取文件,通过skiprows参数来设置跳过行,从0开始
data = pd.read_csv("data5.txt",skiprows=[0,3,5])
print(data)
name a b c d
0 python 1 2 3 4
1 java 5 6 7 8
2 c++ 9 10 11 12
data6.txt
name,a,b,c,d
python,1,NA,3,4
java,5,6,python,NULL
c++,-1.#IND,10,,c++
使用pandas在读取文件的时候,pandas会默认将NA、-1.#IND、NULL等当作是缺失值,pandas默认使用NaN进行代替。
data = pd.read_csv("data6.txt")
print(data)
name a b c d
0 python 1.0 NaN 3.0 4.0
1 java 5.0 6.0 python NaN
2 c++ NaN 10.0 NaN c++
#我们可以通过设置na_values,将指定的值替换成为NaN值
data1 = pd.read_csv("data.txt",na_values=["java","c++",'python'])
print(data1)
name a b c d
0 NaN 1.0 NaN 3.0 4.0
1 NaN 5.0 6.0 NaN NaN
2 NaN NaN 10.0 NaN NaN
#只将第一列的python和c++替换为NaN
dic = {"name":["python","c++"]}
data1 = pd.read_csv("data.txt",na_values=dic)
print(data1)
name a b c d
0 NaN 1.0 NaN 3 4
1 java 5.0 6.0 python NaN
2 NaN NaN 10.0 NaN c++
read_csv/table 参数
| 参数 | 说明 |
|---|---|
| path | 文件位置 |
| sep | 选择对字段进行拆分的字符串或者正则表达式 |
| header | 用作列名的行号,默认为0 |
| index_col | 用作行索引的列名 |
| names | 用于结果的列名列表 |
| skiprows | 需要忽略的行数或需要跳过的行号列表 |
| na_values | 一组用于变成NaN的值 |
| comment | 用于将注释信息从行尾拆分出去的字符 |
| parse_dates | 尝试将数据解析为日期,默认为False,可以指定需要解析的一组列号或列名。如果列表的元素为列表或元组,就会将多个列组合到一起在进行解析工作。 |
| keep_date_col | 如果连接多列解析日期,则保持参与连接的列,默认为False |
| converters | 由列号或列名跟函数之间的映射关系组成的字典。 |
| dayfirst | 当解析有歧义的日期时,将其看成国际格式。 |
| date_parser | 用于解析日期的函数 |
| nrows | 需要读取的行数 |
| iterator | 返回一个 TextParser以便逐块读取文件 |
| chunksize | 文件块的大小,并返回一个 TextParser以便逐块读取文件 |
| skip_footer | 需要忽略的行数(从文件末尾算起) |
| verbose | 打印各种解析器输出信息 |
| encoding | 文本编码 |
| squeeze | 如果数据经解析后仅含一列,则返回Series |
| thousands | 千分位分隔符 |
本文来自博客园,作者:不尽人意的K,转载请注明原文链接:https://www.cnblogs.com/duan-rui/articles/17272704.html
