用mistune markdown来写回测报告
html示例报告的截图
代码
# -*- coding: utf-8 -*-
"""strat_sz100iw_report.py @ d:\db\ibs
"""
def write_report_md(py_fn='strat_sz100iw.py'):
'''借助markdown模块, 用md语法来写报告, 输出被解析为html文档
>>> write_report_md()
'''
#import markdown as markd
from mistune import Markdown
import pathlib, os
#html = markd.markdown(reports, extensions=['markdown.extensions.codehilite'])
#markd = Markdown(escape=False, hard_wrap=False)
markd = Markdown(escape=True, hard_wrap=True)
############ 文章标题和正文部分
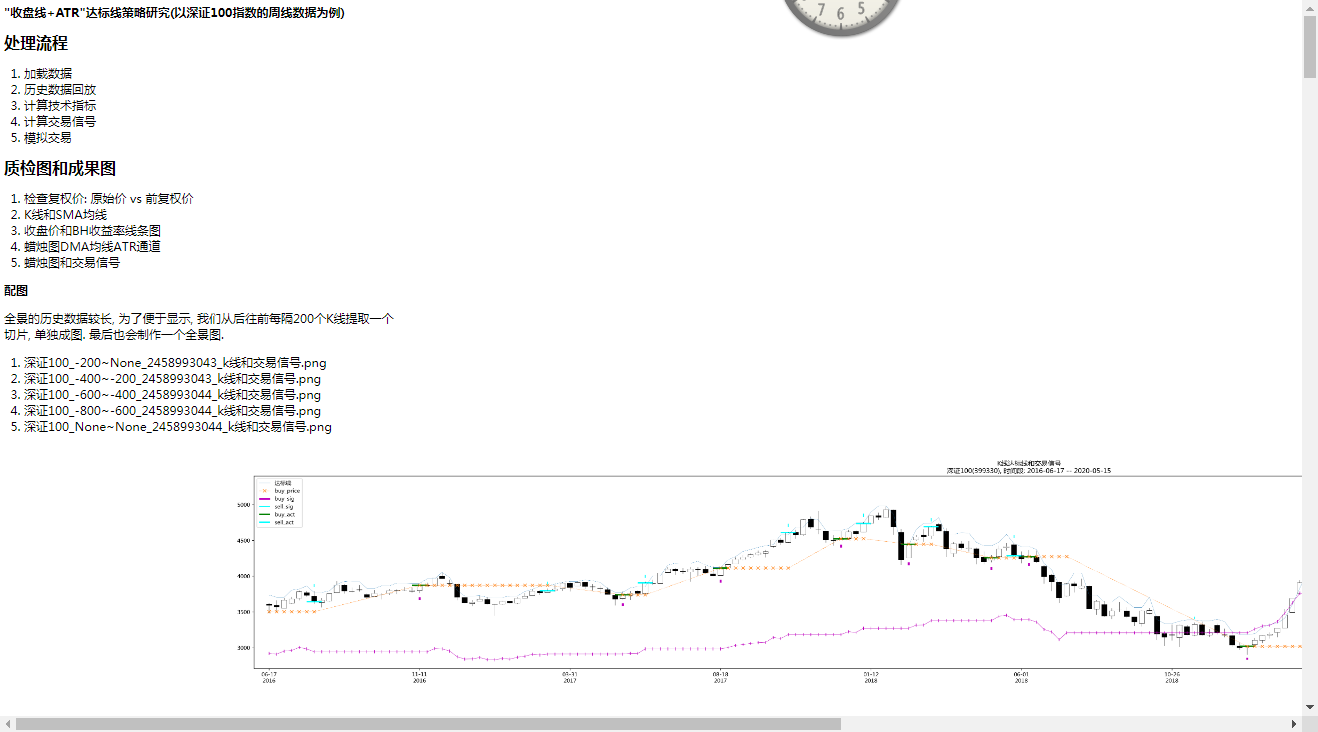
title = '"收盘线+ATR"达标线策略研究(以深证100指数的周线数据为例)'
img_name = [fn for fn in os.listdir() if fn.startswith('深证100')]
type(img_name)
############# 处理流程
md_text='''
### {title}
# 处理流程
1. 加载数据
1. 历史数据回放
1. 计算技术指标
1. 计算交易信号
1. 模拟交易
# 质检图和成果图
1. 检查复权价: 原始价 vs 前复权价
1. K线和SMA均线
1. 收盘价和BH收益率线条图
1. 蜡烛图DMA均线ATR通道
1. 蜡烛图和交易信号
'''.format(title=title)
html_1 = markd(md_text) #该类具有__call__方法, 所以才像个函数似的使用. 同.parse()方法
############### 图件部分:
md_text='''
## 配图
全景的历史数据较长, 为了便于显示, 我们从后往前每隔200个K线提取一个
切片, 单独成图. 最后也会制作一个全景图.
'''
for fn in img_name:
md_text+='1. {}\n'.format(fn)
html_img = markd(md_text)
for i in img_name:
html_img+='<p><img alt="" src="./{}" height="500" width="4000"/></p>\n'
html_img = html_img.format(*img_name)
#把所有的图片文件打包到一个python列表变量里, 通过(*args)方便生成"html的img标签"
#img_name_=['./华侨城A_20190901_175109_1_原始价与前复权价.png',
# './华侨城A_20190901_175121_2_k线均线.png',
# './华侨城A_20190901_175129_3_收盘价和BH收益率.png',
# './华侨城A_lday_20190901_180000_4_k线和指标线.png',
# './华侨城A_20190901_175134_5_k线指标线和交易信号.png',
# ];type(img_name_)
#<p><img src="{1}" alt="candle plot with signal" height="10%" width="10%"/ ></p>
#<p><img src="http://pp.myapp.com/ma_pic2/0/shot_42391053_1_1488499316/550" height="55" width="33" /></p>
#<p><img alt="" src="./深证100_-200~None_2458993043_k线和交易信号.png" height="450" width="4000"/></p>
################# 备注部分
md_text='''
# 备注
1. md里强制换行时, 需要在行尾写上2个空格.
1. md里写尖括号时, 需要用转义符. 因为不转义的话, 会被解析为html的标签.
1. md里写代码段: 用一对左单引号围起来.
1. 在Markdown中要生成一个代码块,只需要在代码块内容的每一行缩进至少四个空格或者一个TAB。
Markdown不会解析代码块中的Markdown标记。如代码块中的星号就是星号,
失去了它原来的Markdown含义.
直接markdown.markdown(text)生成的html文本,非常粗略,只是单纯的html内容。
而且在浏览器内查看的时候中文有乱码(在chrome中).
因为没有设置css样式文件, 外观也太丑了。
解决办法也很简单,在保存文件的时候,将
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> 和
`<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />` 和
css样式添加上。就这么简单解决了。
#markdown 文本里, 缩进后, 表示其内容不再具有markdown功能了. 就是普通文本了
#可以随便写注释, 或者是python源码.
#
<img width="200px" height="500px" />

# 用html语言的img标签来显示并控制显示图片的大小
#<img src="http://pp.myapp.com/ma_pic2/0/shot_42391053_1_1488499316/550" height="55" width="33" >
# 下面是python源码的另一种方案: ```python ... ```
```python
def slicing_forward(ohlc, length=200):
# =============================================================================
# 从后往前提取切片的左右位置, 为切片操作做准备
# 参数:
# ohlc: df对象,
# length: 切片的大小
# 返回:
# list of each slice at (left, right)
# Examples:
# >>> subsets = slicing_forward(c, 200)
# for sub in subsets:
# tmp=c[slice(*sub)]
# print(tmp.index[0], tmp.index[-1])
# =============================================================================
out=[]
for i in range(len(ohlc)//length+1):
start,end=[-length*(i+1), -length*i, ]
if end==0: end=None
out.append((start,end))
#print(out)
return out
```
'''
html_remark = markd(md_text)
############## 拼接起来, 然后装到<body> </body>标签里
body_html = '\n'.join([html_1, html_img, html_remark])
html = '''
<html lang="zh-cn">
<head>
<meta content="text/html; charset=utf-8" http-equiv="content-type" />
<link href="default.css" rel="stylesheet">
<link href="github.css" rel="stylesheet">
</head>
<body>
<title> {t} </title>
{b}
</body>
</html>
'''.format(t=title, b=body_html)
############# python 源代码部分:
fn = py_fn
fn = pathlib.Path(''.join([os.getcwd(), '\\', fn]))
if fn.exists():
with open(fn, mode='rt', encoding='utf') as f:
lines = f.read().splitlines()
big_code_str = '\n'.join(['>%5d %s'%(i,line) for i,line in enumerate(lines)])
html_code_block = """
<h1>python源代码</h1>
<div><pre>
<code><p>{bcs}</p>
</code>
</pre></div>
""".format(bcs=big_code_str)
merged_html = html + html_code_block
ofn = '{}.html'.format(py_fn[0:-3]) #去除py文件的扩展名(.py)
with open(ofn, "w",encoding="utf-8" ) as stream:
stream.write(merged_html)
#stream.write(css+html)
#####经常用到"<"和">"两个标签,索引总结一下。
#
#|显示结果|文字描述|实体名称|实体编号|
#:—😐:—😐:—:
# |空格| | 
#< |小于号|<|<
#> |大于号|>|>
#&|和号|&|&
#" |引号|"|"
#'|撇号|'(IE不支持)|'
css = '''
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<style type="text/css">
<!-- 此处省略掉markdown的css样式,因为太长了 -->
</style>
'''; type(css)
return
#write_report_md()
strat_sz100iw.html · duanqingshan/ipython notebook - 码云 - 开源中国
https://gitee.com/duanqsqh/ipython-notebook/blob/master/strat_sz100iw.html
strat_sz100iw.html
duanqs

 浙公网安备 33010602011771号
浙公网安备 33010602011771号